关于yolov5的一些简单说明(txt文件、训练结果分析等)
目录
- 一、yolo中txt文件的说明:
- 二、yolo跑视频、图片文件的格式:
- 三、yolov5训练结果不好的原因:
- 四、yolov5训练结果(train文件)分析
- 总结
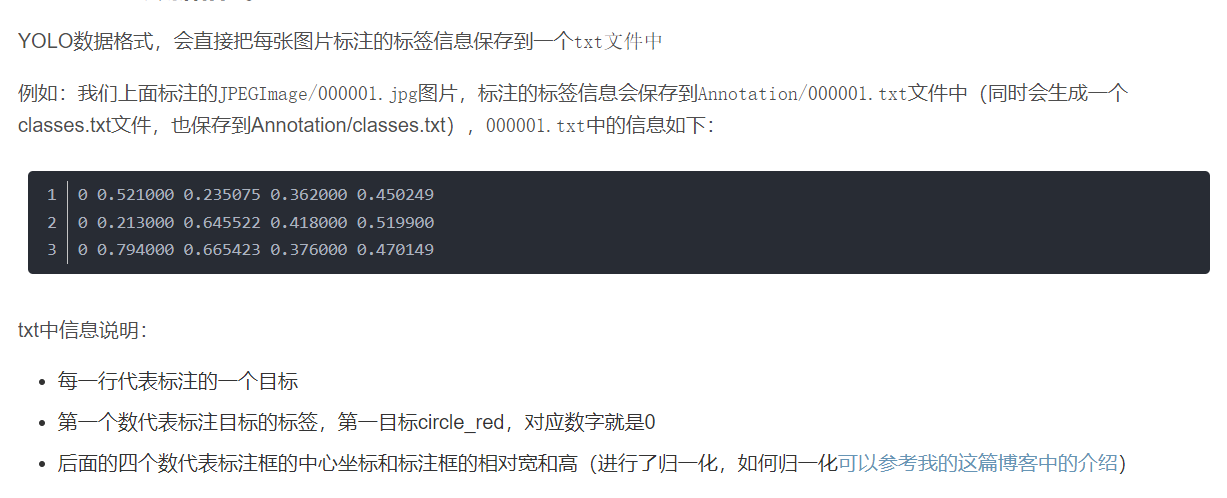
一、yolo中txt文件的说明:
二、yolo跑视频、图片文件的格式:

三、yolov5训练结果不好的原因:
1. 欠拟合:
在训练集上表现很差,测试集上表现也很差的现象可能是欠拟合导致的,是因为泛化能力太强,误识别率较高解决办法:
1)增加数据集的正样本数, 增加主要特征的样本数量
2)增加训练次数
3)减小正则化参数
2. 过拟合:
在训练集上表现很好,在测试集上表现很差(模型太复杂)解决办法:
1)增加其他的特征的样本数, 重新训练网络.
2)训练数据占总数据的比例过小,增加数据的训练量
3. loss值不再变小就说明训练好了
四、yolov5训练结果(train文件)分析
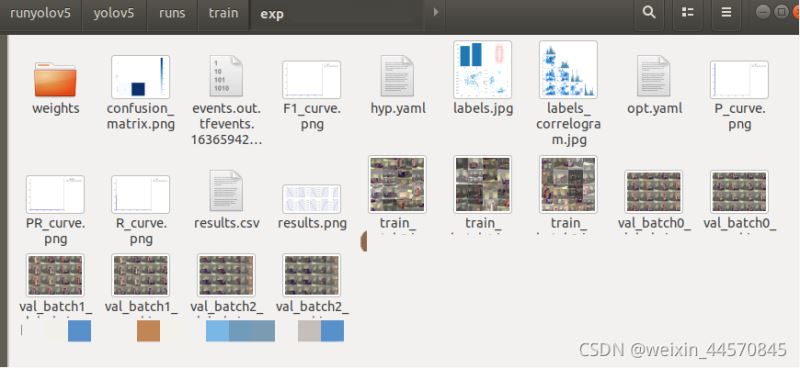
1. confusion_matrix.png(混淆矩阵)
混淆矩阵能对分类问题的预测结果进行总结,显示了分类模型的在进行预测时会对哪一部分产生混淆。
2. F1_curve:
F1分数与置信度之间的关系。F1分数(F1-score)是分类问题的一个衡量指标,是精确率precision和召回率recall的调和平均数,最大为1,最小为0, 1是最好,0是最差
3. labels.jpg
第一个图 classes:每个类别的数据量
第二个图 labels:标签
第三个图 center xy
第四个图 labels 标签的长和宽
4. labels_corrrelogram.jpg 目前不知道
5. P_curve.png :
准确率precision和置信度confidence的关系图
6. PR_curve.png:
PR曲线中的P代表的是precision(精准率),R代表的是recall(召回率),其代表的是精准率与召回率的关系,一般情况下,将recall设置为横坐标,precision设置为纵坐标。PR曲线下围成的面积即AP,所有类别AP平均值即Map.
如果PR图的其中的一个曲线A完全包住另一个学习器的曲线B,则可断言A的性能优于B,当A和B发生交叉时,可以根据曲线下方的面积大小来进行比较。一般训练结果主要观察精度和召回率波动情况(波动不是很大则训练效果较好)
- Precision和Recall往往是一对矛盾的性能度量指标;
- 提高Precision == 提高二分类器预测正例门槛 == 使得二分类器预测的正例尽可能是真实正例;
- 提高Recall == 降低二分类器预测正例门槛 == 使得二分类器尽可能将真实的正例挑选
7. R_curve.png :召回率和置信度之间的关系
8. results.png:
- Box_loss:YOLO V5使用 GIOU Loss作为bounding box的损失,Box推测为GIoU损失函数均值,越小方框越准;
- Objectness_loss:推测为目标检测loss均值,越小目标检测越准;
- Classification_loss:推测为分类loss均值,越小分类越准;
- Precision:精度(找对的正类/所有找到的正类);
- Recall:真实为positive的准确率,即正样本有多少被找出来了(召回了多少).Recall从真实结果角度出发,描述了测试集中的真实正例有多少被二分类器挑选了出来,即真实的正例有多少被该二分类器召回。
- val Box_loss: 验证集bounding box损失;
- val Objectness_loss:验证集目标检测loss均值;
- val classification_loss:验证集分类loss均值;
- mAP@.5:.95(mAP@[.5:.95]): 表示在不同IoU阈值(从0.5到0.95,步长0.05)(0.5、0.55、0.6、0.65、0.7、0.75、0.8、0.85、0.9、0.95)上的平均mAP。mAP@.5:表示阈值大于0.5的平均mAP。然后观察mAP@0.5 & mAP@0.5:0.95 评价训练结果。mAP是用Precision和Recall作为两轴作图后围成的面积,m表示平均,@后面的数表示判定iou为正负样本的阈值,@0.5:0.95表示阈值取0.5:0.05:0.95后取均值
注:以上资料、图片来自于YOLOV5官网,CSDN优秀作者以及自己训练的数据集,侵权删除。
本人正在学习事件相机检测等内容(小白),希望能与学习事件相机的众多大佬一起学习,共同交流!
总结
到此这篇关于关于yolov5的一些简单说明的文章就介绍到这了,更多相关yolov5 txt文件、训练结果分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Yolov5训练意外中断后如何接续训练详解
目录 1.配置环境 2.问题描述 3.解决方法 3.1设置需要接续训练的结果 3.2设置训练代码 4.原理 5.结束语 1.配置环境 操作系统:Ubuntu20.04 CUDA版本:11.4 Pytorch版本:1.9.0 TorchVision版本:0.7.0 IDE:PyCharm 硬件:RTX2070S*2 2.问题描述 在训练YOLOv5时由于数据集很大导致训练时间十分漫长,这期间Python.主机等可能遇到死机的情况,如果需要训练300个epoch但是训练一晚后发现在200epoch时
-
yolov5训练时参数workers与batch-size的深入理解
目录 yolov5训练命令 workers和batch-size参数的理解 workers batch-size 两个参数的调优 总结 yolov5训练命令 python .\train.py --data my.yaml --workers 8 --batch-size 32 --epochs 100 yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了.这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字. worke
-
关于yolov5的一些简单说明(txt文件、训练结果分析等)
目录 一.yolo中txt文件的说明: 二.yolo跑视频.图片文件的格式: 三.yolov5训练结果不好的原因: 四.yolov5训练结果(train文件)分析 总结 一.yolo中txt文件的说明: 二.yolo跑视频.图片文件的格式: 三.yolov5训练结果不好的原因: 1. 欠拟合: 在训练集上表现很差,测试集上表现也很差的现象可能是欠拟合导致的,是因为泛化能力太强,误识别率较高解决办法: 1)增加数据集的正样本数, 增加主要特征的样本数量 2)增加训练次数 3)减小正则化参数 2.
-
C#简单读写txt文件的方法
本文实例讲述了C#简单读写txt文件的方法.分享给大家供大家参考,具体如下: //write txt StringBuilder builder = new StringBuilder(); FileStream fs = new FileStream(saveFileName, FileMode.Create); StreamWriter sw = new StreamWriter(fs, Encoding.Default); for (int i = 0; i < ds.Tables[0].
-
JavaScript代码实现txt文件的上传预览功能
今天做项目刚好碰到这个记录一下.因为是简单的txt文件,只涉及文本,如果需要涉及图片预览就需要使用papaparse和jschardet,此处不多叙述. 表单按钮使用js的onchange="uploadfile()" 事件,function函数代码如下所示: //此处为txt文件上传预览的js代码 function uploadfile(){ var file=$("#txt")[0].files[0]; //判断上传文件是不是txt格式,判断后缀是不是.txt
-
PHP简单实现生成txt文件到指定目录的方法
本文实例讲述了PHP简单实现生成txt文件到指定目录的方法.分享给大家供大家参考,具体如下: <?php //fopen第二个参数可以是以下四个,区别就是是清空内容再写还是在后面累加内容 //"w" 写入方式打开,将文件指针指向文件头并将文件大小截为零.如果文件不存在则尝试创建之. //"w+" 读写方式打开,将文件指针指向文件头并将文件大小截为零.如果文件不存在则尝试创建之. //"a" 写入方式打开,将文件指针指向文件末尾.如果文件不存
-
Java读取txt文件和写入txt文件的简单实例
写Java程序时经常碰到要读如txt或写入txt文件的情况,但是由于要定义好多变量,经常记不住,每次都要查,特此整理一下,简单易用,方便好懂! package edu.thu.keyword.test; import java.io.File; import java.io.InputStreamReader; import java.io.BufferedReader; import java.io.BufferedWriter; import java.io.FileInputStream;
-
Python实现读取txt文件并画三维图简单代码示例
记忆力差的孩子得勤做笔记! 刚接触python,最近又需要画一个三维图,然后就找了一大堆资料,看的人头昏脑胀的,今天终于解决了!好了,废话不多说,直接上代码! #由三个一维坐标画三维散点 #coding:utf-8 import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d.axes3d import Axes3D x = [] y = [] z = [] f = open("data\\record.
-
c语言读取txt文件内容简单实例
在C语言中,文件操作都是由库函数来完成的. 要读取一个txt文件,首先要使用文件打开函数fopen(). fopen函数用来打开一个文件,其调用的一般形式为: 文件指针名=fopen(文件名,使用文件方式) 其中,"文件指针名"必须是被说明为FILE 类型的指针变量,"文件名"是被打开文件的文件名. "使用文件方式"是指文件的类型和操作要求."文件名"是字符串常量或字符串数组. 其次,使用文件读写函数读取文件. 在C语言中提供
-
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件. 项目内容: 用Python写的百度贴吧的网络爬虫. 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行. 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地. 原理解释: 首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了: http://tieba.baidu.com/p/2296712428?see_lz=1&pn=
-
Python实现简单拆分PDF文件的方法
本文实例讲述了Python实现简单拆分PDF文件的方法.分享给大家供大家参考.具体如下: 依赖pyPdf处理PDF文件 切分pdf文件 使用方法: 1)将要切分的文件放在input_dir目录下 2)在configure.txt文件中设置要切分的份数(如要切分4份,则设置part_num=4) 3)执行程序 4)切分后的文件保存在output_dir目录下 5)运行日志写在pp_log.txt中 P.S. 本程序可以批量切割多个pdf文件 from pyPdf import PdfFileWri
-
Python 逐行分割大txt文件的方法
代码如下所示: # -*- coding: <encoding name> -*- import io LIMIT = 150000 file_count = 0 url_list = [] with io.open('D:\DB_NEW_bak\DB_NEW_20171009_bak.sql','r',encoding='utf-16') as f: for line in f: url_list.append(line) if len(url_list) < LIMIT: conti