Python爬虫实现selenium处理iframe作用域问题
项目场景:
在使用selenium模块进行数据爬取时,通常会遇到爬取iframe中的内容。会因为定位的作用域问题爬取不到数据。
问题描述:
我们以菜鸟教程的运行实例为案例。
按照正常的定位
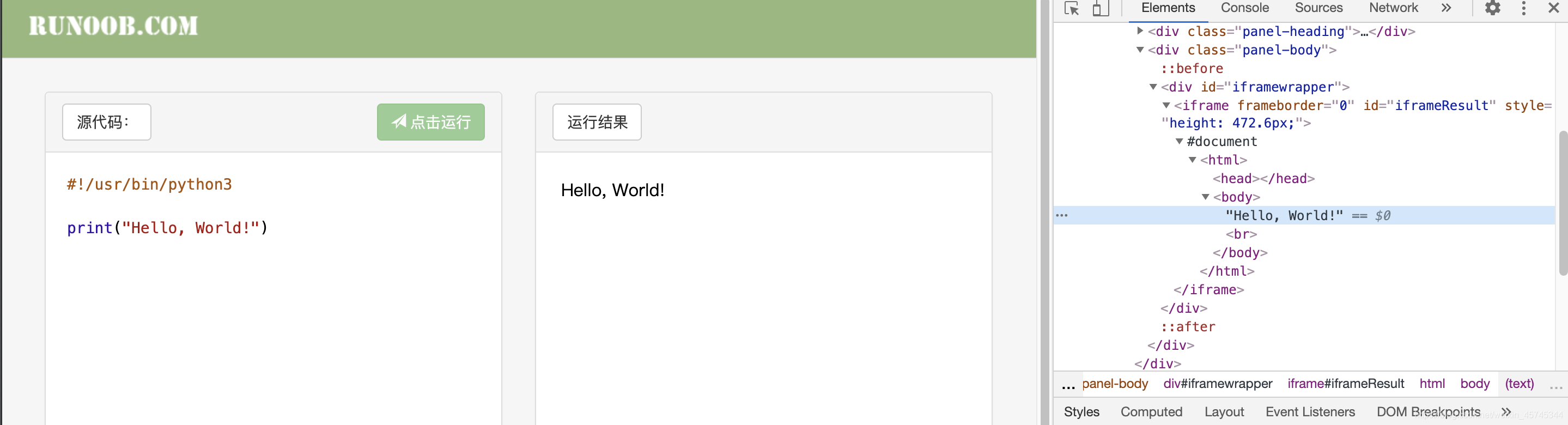
会以文本块生成xpath为/html/body/text()。这样的话根据xpath进行如下代码编写。
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3')
time.sleep(2)
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()
执行结果:

很明显这并不是想要的结果。
原因分析:
当我们打开抓包工具定位到Hello, World!文本的时候会发现,该文本是在一个iframe中。这样的话我们xpath所定位到的内容则是大的html中的路径。我们需要的内容则是在iframe中的小的html中。
解决方案:
通过分析发现,想要解决问题的实质就是改变作用域。通过switch_to.frame(‘id')方法来改变作用域就可以了。
重新编写代码:
#!/user/bin/
# -*- coding:UTF-8 -*-
# Author:Master
from selenium import webdriver
import time
driver = webdriver.Chrome(executable_path="./chromedriver")
driver.get('https://www.runoob.com/try/runcode.php?filename=HelloWorld&type=python3')
time.sleep(2)
driver.switch_to.frame('iframeResult')
text = driver.find_element_by_xpath('/html/body').text
print(text)
time.sleep(5)
driver.quit()
查看运行结果:

到此这篇关于Python爬虫实现selenium处理iframe作用域问题的文章就介绍到这了,更多相关selenium iframe作用域内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫之Selenium中frame/iframe表单嵌套页面
在Web应用中经常会遇到frame/iframe表单嵌套页面的应用,WebDriver只能在一个页面上对元素识别与定位,对于frame/iframe表单内嵌页面上的元素无法直接定位.这时就需要通过switch_to.frame()方法将当前定位的主体切换为frame/iframe表单的内嵌页面中. 本章中用到的关键方法如下: switch_to.frame():切换为frame/iframe表单的内嵌页面中 switch_to.parent_frame():退出内嵌页面 以ip138网站为例 f
-
Selenium向iframe富文本框输入内容过程图解
前言 在使用Selenium测试一些CMS后台系统时,有时会遇到一些富文本框,如下图所示: 整个富文本编辑器是通过iframe嵌入到网页中的,手动尝试输入内容,发现内容是输入到iframe页面的body中的, 这种富文本框怎么输入呢? 我们也可以直接在body的源码上点击右键选择Edit HTML,输入相应的html代码,达到向富文本框输入的目的,如下下图: 以下是使用Selenium的操作方法 只输入纯文本 如果只输入不带格式的纯文本,可以先切换到这个iframe,然后定位到body,send
-
selenium学习教程之定位以及切换frame(iframe)
总有人看不明白,以防万一,先在开头大写加粗说明一下: frameset不用切,frame需层层切! 很多人在用selenium定位页面元素的时候会遇到定位不到的问题,明明元素就在那儿,用firebug也可以看到,就是定位不到,这种情况很有可能是frame在搞鬼(原因之一,改天专门说说定位不到元素,可能的一些原因及处理办法). frame标签有frameset.frame.iframe三种,frameset跟其他普通标签没有区别,不会影响到正常的定位,而frame与iframe对selenium定
-
java selenium处理Iframe中的元素示例
java selenium 处理Iframe 中的元素 有时候我们定位元素的时候,发现怎么都定位不了. 这时候你需要查一查你要定位的元素是否在iframe里面 阅读目录 什么是iframe iframe 就是HTML 中,用于网页嵌套网页的. 一个网页可以嵌套到另一个网页中,可以嵌套很多层. selenium 中提供了进入iframe 的方法 // 进入 id 叫frameA 的 iframe dr.switchTo().frame("frameA"); // 回到主窗口 dr.sw
-
Python爬虫实现selenium处理iframe作用域问题
项目场景: 在使用selenium模块进行数据爬取时,通常会遇到爬取iframe中的内容.会因为定位的作用域问题爬取不到数据. 问题描述: 我们以菜鸟教程的运行实例为案例. 按照正常的定位 会以文本块生成xpath为/html/body/text().这样的话根据xpath进行如下代码编写. #!/user/bin/ # -*- coding:UTF-8 -*- # Author:Master from selenium import webdriver import time driver =
-
Python爬虫之Selenium实现关闭浏览器
前言:WebDriver提供了两个关闭浏览器的方法,一个是前边使用quit()方法,另一个是close()方法 close():关闭当前窗口 quit():关闭所有窗口 quit()是关闭所有窗口,就不过多说了,测试一下close() from selenium import webdriver from selenium.webdriver.common.keys import Keys import time driver = webdriver.Chrome() driver.get("h
-
Python爬虫之Selenium实现窗口截图
前言:由程序去执行的操作不允许有任何误差,有些时候在测试的时候未出现问题,但是放到服务器上就会报错,而且打印的错误信息并不十分明确.这时,我在想如果在脚本执行出错的时候能对当前窗口截图保存,那么通过图片就可以非常直观地看出出错的原因.WebDriver提供了截图函数get_screenshot_as_file()来截取当前窗口. 本章中用到的关键方法如下: get_screenshot_as_file():截图 from selenium import webdriver driver = we
-
Python爬虫之Selenium设置元素等待的方法
一.显式等待 WebDriverWait类是由WebDirver 提供的等待方法.在设置时间内,默认每隔一段时间检测一次当前页面元素是否存在,如果超过设置时间检测不到则抛出异常(TimeoutException) from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from seleniu
-
Python爬虫中Selenium实现文件上传
前言:大部分的文件上传功能都是用input标签实现,这样就完全可以把它看作一个输入框,可以通过send_keys()指定文件进行上传了. 本章中用到的关键方法如下: send_keys():上传文件或者输入文本 from selenium import webdriver import time driver = webdriver.Chrome() driver.get('http://file.yiyuen.com/file/') # 定位上传按钮,添加本地文件 driver.find_el
-
Python爬虫之Selenium下拉框处理的实现
在我们浏览网页的时候经常会碰到下拉框,WebDriver提供了Select类来处理下拉框,详情请往下看: 本章中用到的关键方法如下: select_by_value():设置下拉框的值 switch_to.alert.accept():定位并接受现有警告框(详情请参考Python爬虫 - Selenium(9)警告框(弹窗)处理) click():鼠标点击事件(其他鼠标事件请参考Python爬虫 - Selenium(5)鼠标事件) move_to_element():鼠标悬停(详情请参考Pyt
-
Python爬虫之Selenium警告框(弹窗)处理
JavaScript 有三种弹窗 Alert (只有确定按钮), Confirmation (确定,取消等按钮), Prompt (有输入对话框),而且弹出的窗口是不能通过前端工具对其进行定位的,这个时候就可以通过switch_to.alert方法来定位这个弹窗,并进行一系列的操作. 本章中用到的关键方法如下: switch_to.alert:定位到警告框 text:获取警告框中的文字信息 accept():接受现有警告框(相当于确认) dismiss():解散现有警告框(相当于取消) send
-
Python爬虫之Selenium多窗口切换的实现
前言:在页面操作过程中有时候点击某个链接会弹出新的窗口,但由于Selenium的所有操作都是在第一个打开的页面进行的,这时就需要主机切换到新打开的窗口上进行操作.WebDriver提供了switch_to.window()方法,可以实现在不同的窗口之间切换. 以百度首页和百度注册页为例,在两个窗口之间的切换. 本章中用到的关键方法如下: current_window_handle:获得当前窗口句柄 window_handles:返回所有窗口的句柄到当前会话 switch_to.window():
-
Python爬虫之Selenium实现键盘事件
一.常用按键 按键 说明 Keys.BACK_SPACE 回退键(BackSpace) Keys.TAB 制表键(Tab) Keys.ENTER 回车键(Enter) Keys.SHIFT 大小写转换键(Shift) Keys.CONTROL Control键(Ctrl) Keys.ALT ALT键(Alt) Keys.ESCAPE 返回键(Esc) Keys.SPACE 空格键(Space) Keys.PAGE_UP 翻页键上(Page Up) Keys.PAGE_DOWN 翻页键下(Page