python 如何把classification_report输出到csv文件
今天想把classification_report的统计结果输出到文件中,我这里分享一下一个简洁的方式:
我的pandas版本:
pandas 1.0.3
代码:
from sklearn.metrics import classification_report
report = classification_report(y_test, y_pred, output_dict=True)
df = pd.DataFrame(report).transpose()
df.to_csv("result.csv", index= True)
是不是很简单,下面是我导出来的一个结果:
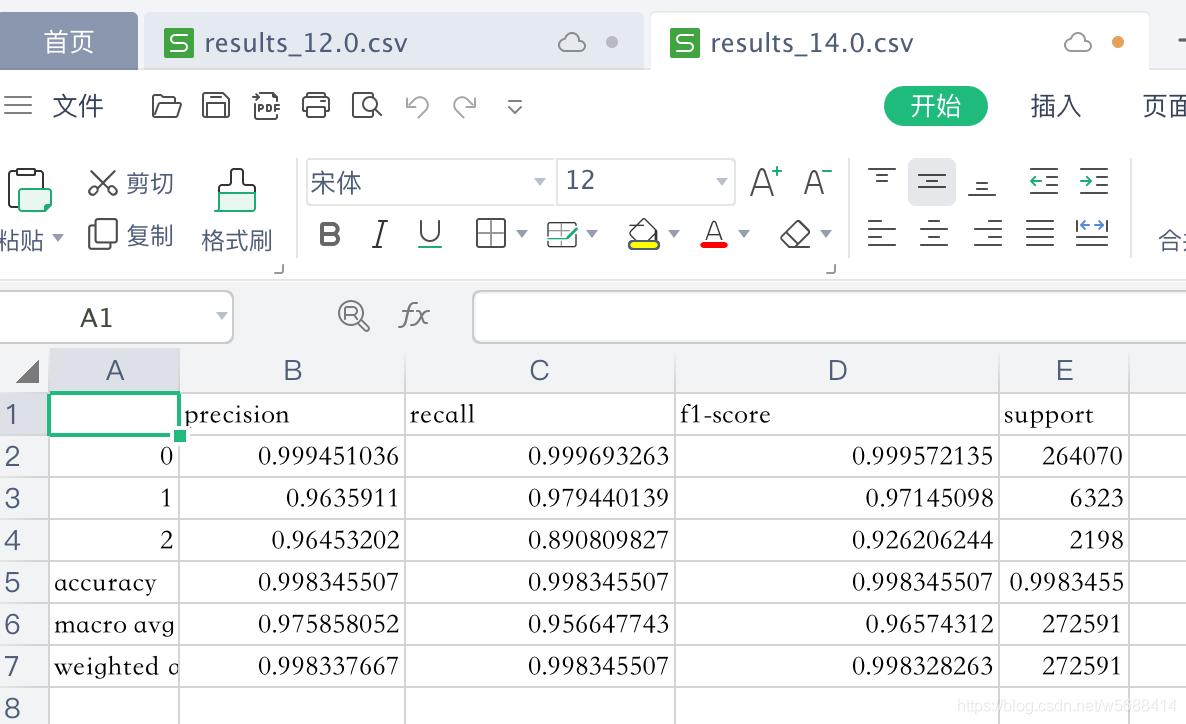
补充:sklearn classification_report 输出说明
| svm-rbf | 0.606 | |||
| precision recall f1-score support | ||||
| 0.0 0.56 0.39 0.46 431 | ||||
| 1.0 0.62 0.77 0.69 569 | ||||
| avg / total 0.60 0.61 0.59 1000 | ||||
最后一行是用support 加权平均算出来的,如0.59 = (431*0.46+569*0.69)/ 1000
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
利用Python如何将数据写到CSV文件中
前言 我们从网上爬取数据,最后一步会考虑如何存储数据.如果数据量不大,往往不会选择存储到数据库,而是选择存储到文件中,例如文本文件.CSV 文件.xls 文件等.因为文件具备携带方便.查阅直观. Python 作为胶水语言,搞定这些当然不在话下.但在写数据过程中,经常因数据源中带有中文汉字而报错.最让人头皮发麻的编码问题. 我先说下编码相关的知识.编码方式有很多种:UTF-8, GBK, ASCII 等. ASCII 码是美国在上个世纪 60 年代制定的一套字符编码.主要是规范英语字符和二进制位
-
python写入数据到csv或xlsx文件的3种方法
本文实例为大家分享了三种方式使用python写数据到csv或xlsx文件,供大家参考,具体内容如下 第一种:使用csv模块,写入到csv格式文件 # -*- coding: utf-8 -*- import csv with open("my.csv", "a", newline='') as f: writer = csv.writer(f) writer.writerow(["URL", "predict", "
-

python 编写输出到csv的操作
如下所示: def test_write(self): fields=[] fields.append(orderCode) with open(r'./test001.csv', 'a',newline="") as f: writer = csv.writer(f) writer.writerow(fields) 定义一个列表:然后将需要写的数据添加到列表 a #追加数据到下一行 newline='' //去除每一行中间的空行,若不加的话,行与行中间有空格 加newline 不加:
-
python 如何把classification_report输出到csv文件
今天想把classification_report的统计结果输出到文件中,我这里分享一下一个简洁的方式: 我的pandas版本: pandas 1.0.3 代码: from sklearn.metrics import classification_report report = classification_report(y_test, y_pred, output_dict=True) df = pd.DataFrame(report).transpose() df.to_csv("resu
-
Python利用pandas计算多个CSV文件数据值的实例
功能:扫描当前目录下所有CSV文件并对其中文件进行统计,输出统计值到CSV文件 pip install pandas import pandas as pd import glob,os,sys input_path='./' output_fiel='pandas_union_concat.csv' all_files=glob.glob(os.path.join(input_path,'sales_*')) all_data_frames=[] for file in all_files:
-
python的pandas工具包,保存.csv文件时不要表头的实例
用pandas处理.csv文件时,有时我们希望保存的.csv文件没有表头,于是我去看了DataFrame.to_csv的document. 发现只需要再添加header=None这个参数就行了(默认是True), 下面贴上document: DataFrame.to_csv(path_or_buf=None, sep=', ', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=Non
-
python读取几个G的csv文件方法
如下所示: import pandas as pd file = pd.read_csv('file.csv',iterator=True) while True: chunk = file.get_chunk(1000) print(chunk.head(10)) print(chunk.tail(10)) 以上这篇python读取几个G的csv文件方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python利用 utf-8-sig 编码格式解决写入 csv 文件乱码问题
先举个例子,分别以不指定编码.指定编码为 utf-8.指定编码为 utf-8-sig 三种方式来做比较,再将写入 csv 文件和 txt 文件来做个对比 一.不指定编码方式,直接存入 csv 文件 import csv with open('test.csv', 'w') as fp: writer = csv.writer(fp) writer.writerow(['汉语', '俄语', '韩语', '日语', '英语']) writer.writerow(['爱你', 'люблю тебя
-
Python如何把字典写入到CSV文件的方法示例
在实际数据分析过程中,我们分析用Python来处理数据(海量的数据),我们都是把这个数据转换为Python的对象的,比如最为常见的字典. 比如现在有几十万份数据(当然一般这么大的数据,会用到数据库的概念,不会去在CPU内存里面运行),我们不可能在Excel里面用函数进行计算一些值吧,这样是不现实的. Excel只适合处理比较少的数据,具有方便快速的优势 那么我们假设是这么多数据,现在我要对这个数据进行解析,转换,最后数据分析,处理,然后写入数据到CSV文件,这样才达到要求,那么如何把数据字典写入
-
python用pandas读写和追加csv文件
目录 csv文件 一.创建csv文件 二.读写csv文件 1.基础python 2.pandas 三.追加csv文件 1.基础python 2.pandas 总结 csv文件 CSV文件是最常用的一个文件存储方式.逗号分隔值(Common-Separated Values,CSV)文件以纯文本形式存储表格数据(注:分隔字符也可以是其他字符).纯文本说明该文件是一个字符序列,不包含必须像二进制数字那样被解读的数据. CSV文件由任意数目记录组成,记录间以某种换行符分隔:每条记录由若干字段组成,字段
-
python pandas 解析(读取、写入)CSV 文件的操作方法
目录 1. 使用 pandas 读取 CSV 文件 2. 使用 pandas 写入 CSV 文件 1. 使用 pandas 读取 CSV 文件 原始数据包含了公司员工的数据: Name Hire Date Salary Sick Days remaining Graham Chapman 03/15/14 50000.00 10 John Cleese 06/01/15 65000.00 8 Eric Idle 05/12/14 45000.00 10 Terry Jones 11/01/13
-
在Python的Django框架中生成CSV文件的方法
CSV 是一种简单的数据格式,通常为电子表格软件所使用. 它主要是由一系列的表格行组成,每行中单元格之间使用逗号(CSV 是 逗号分隔数值(comma-separated values) 的缩写)隔开.例如,下面是CSV格式的"不守规矩"的飞机乘客表. Year,Unruly Airline Passengers 1995,146 1996,184 1997,235 1998,200 1999,226 2000,251 2001,299 2002,273 2003,281 2004,3