Python opencv医学处理的实现过程
题目描述
利用opencv或其他工具编写程序实现医学处理。
实现过程
# -*- coding: utf-8 -*-
'''
作者 : 丁毅
开发时间 : 2021/5/9 16:30
'''
import cv2
import numpy as np
# 图像细化
def VThin(image, array):
rows, cols = image.shape
NEXT = 1
for i in range(rows):
for j in range(cols):
if NEXT == 0:
NEXT = 1
else:
M = int(image[i, j - 1]) + int(image[i, j]) + int(image[i, j + 1]) if 0 < j < cols - 1 else 1
if image[i, j] == 0 and M != 0:
a = [0]*9
for k in range(3):
for l in range(3):
if -1 < (i - 1 + k) < rows and -1 < (j - 1 + l) < cols and image[i - 1 + k, j - 1 + l] == 255:
a[k * 3 + l] = 1
sum = a[0] * 1 + a[1] * 2 + a[2] * 4 + a[3] * 8 + a[5] * 16 + a[6] * 32 + a[7] * 64 + a[8] * 128
image[i, j] = array[sum]*255
if array[sum] == 1:
NEXT = 0
return image
def HThin(image, array):
rows, cols = image.shape
NEXT = 1
for j in range(cols):
for i in range(rows):
if NEXT == 0:
NEXT = 1
else:
M = int(image[i-1, j]) + int(image[i, j]) + int(image[i+1, j]) if 0 < i < rows-1 else 1
if image[i, j] == 0 and M != 0:
a = [0]*9
for k in range(3):
for l in range(3):
if -1 < (i-1+k) < rows and -1 < (j-1+l) < cols and image[i-1+k, j-1+l] == 255:
a[k*3+l] = 1
sum = a[0]*1+a[1]*2+a[2]*4+a[3]*8+a[5]*16+a[6]*32+a[7]*64+a[8]*128
image[i, j] = array[sum]*255
if array[sum] == 1:
NEXT = 0
return image
array = [0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,\
0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,\
1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 1,\
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1,\
0, 0, 1, 1, 0, 0, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,\
1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 1, 1, 1, 0, 0,\
1, 1, 0, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 0, 0, 0]
# 显示灰度图
img = cv2.imread(r"C:\Users\pc\Desktop\vas0.png",0)
cv2.imshow("img1",img)
# 自适应阈值分割
img2 = cv2.adaptiveThreshold(img, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 17, 4)
cv2.imshow('img2', img2)
# 图像反色
img3 = cv2.bitwise_not(img2)
cv2.imshow("img3", img3)
# 图像扩展
img4 = cv2.copyMakeBorder(img3, 1, 1, 1, 1, cv2.BORDER_REFLECT)
cv2.imshow("img4", img4)
contours, hierarchy = cv2.findContours(img4, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# 消除小面积
img5 = img4
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
if (area < 80) | (area > 10000):
cv2.drawContours(img5, [contours[i]], 0, 0, -1)
cv2.imshow("img5", img5)
num_labels, labels, stats, centroids = cv2.connectedComponentsWithStats(img5, connectivity=8, ltype=None)
# print(stats)
s = sum(stats)
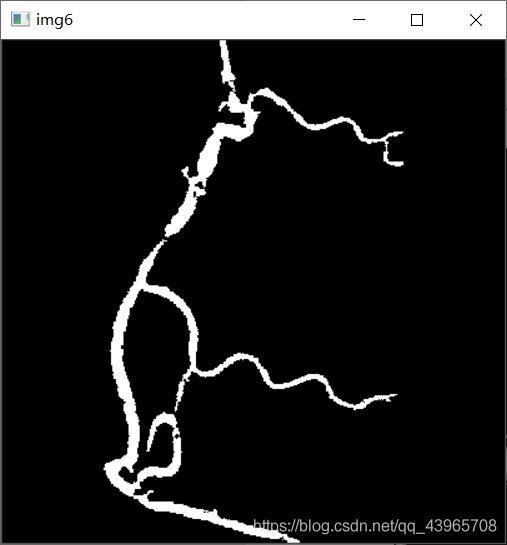
img6 = np.ones(img5.shape, np.uint8) * 0
for (i, label) in enumerate(np.unique(labels)):
# 如果是背景,忽略
if label == 0:
# print("[INFO] label: 0 (background)")
continue
numPixels = stats[i][-1]
div = (stats[i][4]) / s[4]
# print(div)
# 判断区域是否满足面积要求
if round(div, 3) > 0.002:
color = 255
img6[labels == label] = color
cv2.imshow("img6", img6)
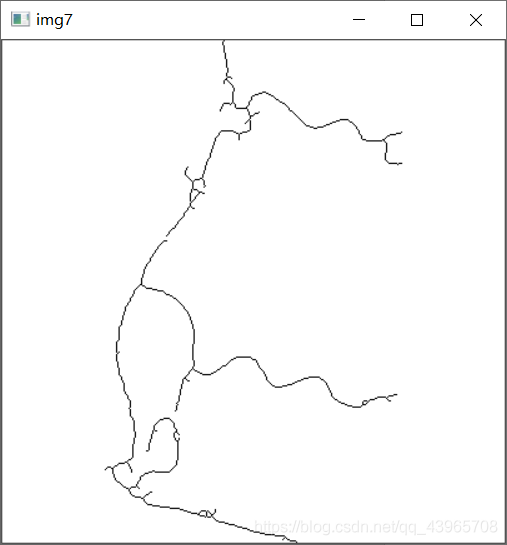
# 图像反色
img7 = cv2.bitwise_not(img6)
# 图像细化
for i in range(10):
VThin(img7, array)
HThin(img7, array)
cv2.imshow("img7",img7)
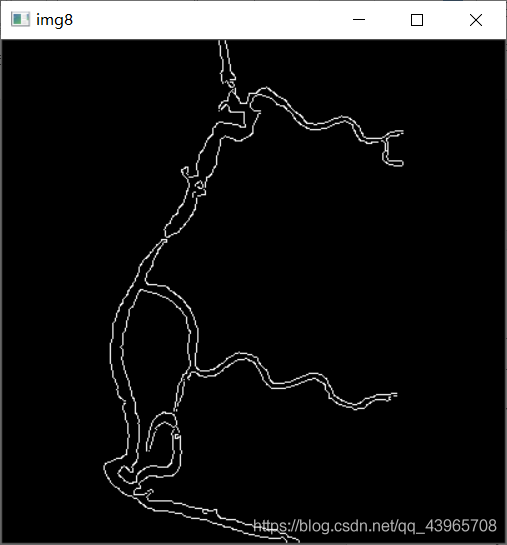
# 边缘检测
img8 = cv2.Canny(img6, 80, 255)
cv2.imshow("img8", img8)
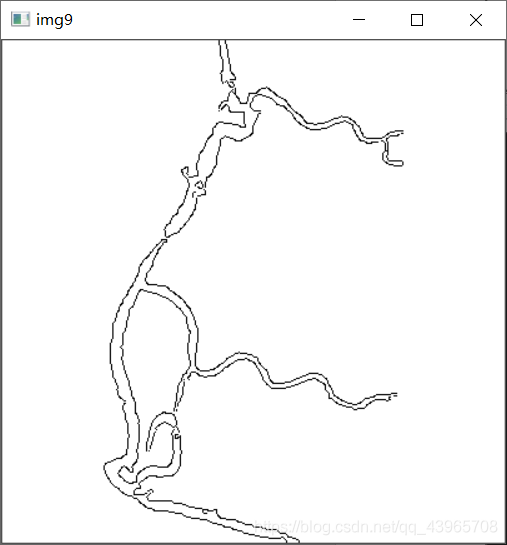
# 使灰度图黑白颠倒
img9 = cv2.bitwise_not(img8)
cv2.imshow("img9", img9)
cv2.waitKey(0)
运行结果
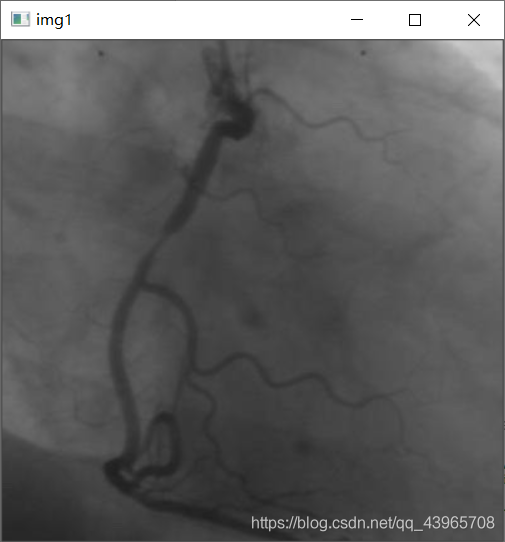
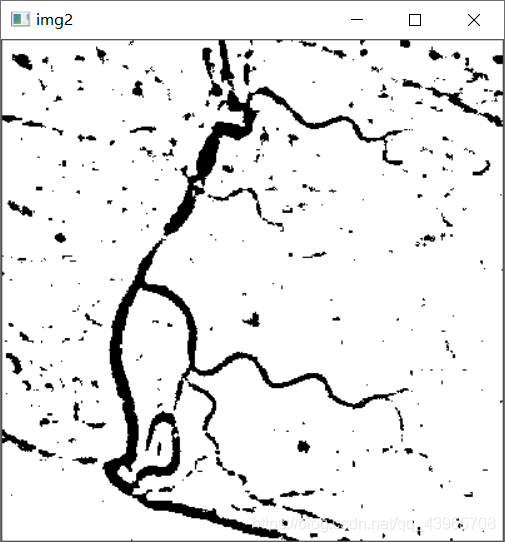
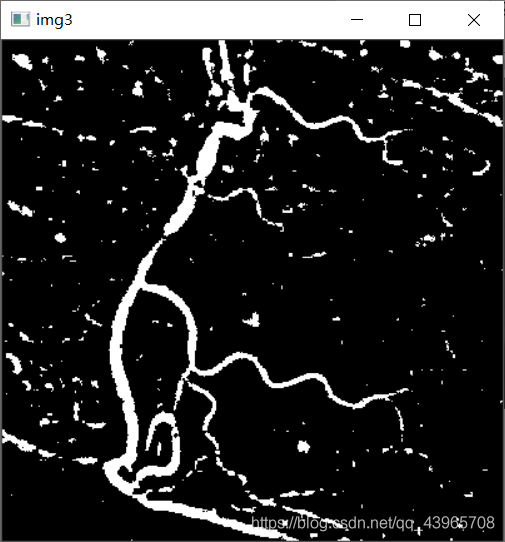
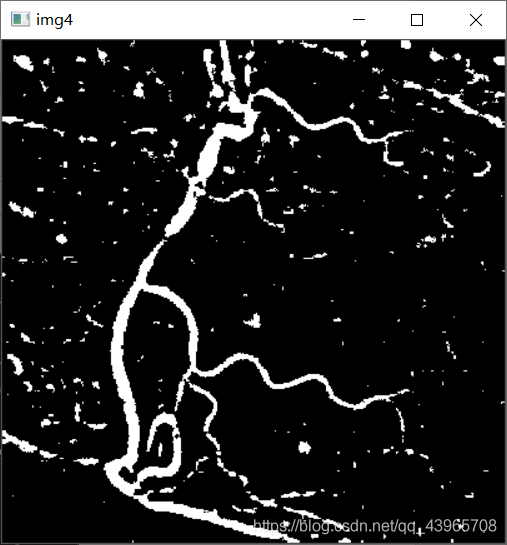

问题及解决方法
1.自适应阈值处理运行报错
参考链接
解决方式:
void adaptiveThreshold(InputArray src, OutputArray dst, double
maxValue, int adaptiveMethod, int thresholdType, int bolckSize, double C)
src:InputArray类型的src,输入图像,填单通道,单8位浮点类型Mat即可。dst:函数运算后的结果存放在这。即为输出图像(与输入图像同样的尺寸和类型)。maxValue:预设满足条件的最大值。adaptiveMethod自适应阈值算法。ADAPTIVE_THRESH_MEAN_C或ADAPTIVE_THRESH_GAUSSIAN_C两种。thresholdType:指定阈值类型。可选择THRESH_BINARY或者THRESH_BINARY_INV两种(即二进制阈值或反二进制阈值)。bolckSize:表示邻域块大小,用来计算区域阈值,一般选择为3、5、7......等。C:参数C表示与算法有关的参数,它是一个从均值或加权均值提取的常数,可以是负数。- 根据报错提示及参数解释,
blockSize的取值需要大于1且为奇数。
2.图像扩展
参考链接
方式:使用cv2.copyMakeBorder()函数。
主要参数:
src: 输入的图片。top, bottom, left, right:相应方向上的边框宽度。borderType:定义要添加边框的类型,详情参考链接。
3.面积选择
参考链接
方式:选择满足面积80-10000的图像输出, 去除噪声位置元素。
4.图像细化
参考链接
方式:经过一层层的剥离,从原来的图中去掉一些点,但仍要保持原来的形状,直到得到图像的骨架。骨架,可以理解为图像的中轴。
到此这篇关于Python opencv医学处理的实现过程的文章就介绍到这了,更多相关Python opencv医学处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python OpenCV实现测量图片物体宽度
一. 题目描述 测量所给图片的高度,即上下边缘间的距离. 思路: 将图片进行阈值操作得到二值化图片. 截取只包含上下边框的部分,以便于后续的轮廓提取 轮廓检测 得到结果 二. 实现过程 1.用于给图片添加中文字符 #用于给图片添加中文字符 def ImgText_CN(img, text, left, top, textColor=(0, 255, 0), textSize=20): if (isinstance(img, np.ndarray)): #判断是否为OpenCV图片类型 img =
-
python用opencv完成图像分割并进行目标物的提取
运行平台: Windows Python版本: Python3.x IDE: Spyder 今天我们想实现的功能是对单个目标图片的提取如图所示: 图片读取 ###############头文件 import matplotlib.pyplot as plt import os import cv2 import numpy as np from PIL import Image #from skimage import io import random from PIL import Image
-
python opencv把一张图片嵌入(叠加)到另一张图片上的实现代码
python opencv把一张图片嵌入(叠加)到另一张图片上 1.背景: 最近做了个烟火生成系统的界面设计,需要将烟雾图片嵌入到任意一张图片中,因此需要python opencv把一张图片嵌入(叠加)到另一张图片上的知识.(图中红框最终生成图片没有的,只是界面有这个功能) 2.代码 resized1[global_y0:height+global_y0, global_x0:weight+global_x0] = resized0 resized0是小图 resized1是大图,其他参数是左上
-
opencv python 图片读取与显示图片窗口未响应问题的解决
显示图像是 Opencv最基本的操作之一, imshow()函数可以实现该操作.如果使用过其他GUI框架背景,就会很自然地调用 imshow来显示一幅图像.但这个观点并不完全正确,因为图像确实会显示出来,但随即会消失. 例如下面代码: import cv2 import numpy as np img = cv2.imread('C://Users/yefci/Pictures/0.2.jpg') cv2.imshow('C://Users/yefci/Pictures/0.2.jpg',img
-
opencv-python的RGB与BGR互转方式
一.格式转换 opencv读取图片的默认像素排列是BGR,需要转换.PIL库是RGB格式. caffe底层的图像处理是基于opencv,其使用的颜色通道顺序与也是BGR(Blue-Green-Red),而日常图片存储时颜色通道顺序是RGB. 在Python中,将RGB顺序的图像转成BGR顺序,需要调整channel dimension的各颜色通道顺序. 方法1: img = cv2.imread("001.jpg") img_ = img[:,:,::-1].transpose((2,
-
python opencv 实现读取、显示、写入图像的方法
opencv是一个强大的图像处理和计算机视觉库,实现了很多实用算法,值得学习和深究下. opencv包安装 · 这里直接安装opencv-python包(非官方): pip install opencv-python 官方文档:https://opencv-python-tutroals.readthedocs.io/en/latest/ 1.读取图像 import cv2 image=cv2.imread("dog2.jpg",1) 说明: 第二个参数是一个标志,它指定了读取图像的方
-
解决Opencv+Python cv2.imshow闪退问题
Opencv+Python cv2.imshow闪退 # 读入原始图像 origineImage = cv2.imread('./pic/6.jpeg') # 图像灰度化 # image = cv2.imread('test.jpg',0) image = cv2.cvtColor(origineImage, cv2.COLOR_BGR2GRAY) #image.save('./pic/gray.jpg') cv2.imshow('gray', image) # 将图片二值化 retval, i
-

Python opencv医学处理的实现过程
题目描述 利用opencv或其他工具编写程序实现医学处理. 实现过程 # -*- coding: utf-8 -*- ''' 作者 : 丁毅 开发时间 : 2021/5/9 16:30 ''' import cv2 import numpy as np # 图像细化 def VThin(image, array): rows, cols = image.shape NEXT = 1 for i in range(rows): for j in range(cols): if NEXT == 0:
-
python Opencv计算图像相似度过程解析
这篇文章主要介绍了python Opencv计算图像相似度过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.相关概念 一般我们人区分谁是谁,给物品分类,都是通过各种特征去辨别的,比如黑长直.大白腿.樱桃唇.瓜子脸.王麻子脸上有麻子,隔壁老王和儿子很像,但是儿子下巴涨了一颗痣和他妈一模一样,让你确定这是你儿子. 还有其他物品.什么桌子带腿.镜子反光能在里面倒影出东西,各种各样的特征,我们通过学习.归纳,自然而然能够很快识别分类出新物品.
-
python+opencv实现目标跟踪过程
目录 python opencv实现目标跟踪 这里根据官网示例写了一个追踪器类 python opencv实现目标跟踪 python-opencv3.0新增了一些比较有用的追踪器算法 这里根据官网示例写了一个追踪器类 程序只能运行在安装有opencv3.0以上版本和对应的contrib模块的python解释器 #encoding=utf-8 import cv2 from items import MessageItem import time import numpy as np ''' 监视
-
python opencv之SURF算法示例
本文介绍了python opencv之SURF算法示例,分享给大家,具体如下: 目标: SURF算法基础 opencv总SURF算法的使用 原理: 上节课使用了SIFT算法,当时这种算法效率不高,需要更快速的算法.在06年有人提出了SURF算法"加速稳定特征",从名字上来看,他是SIFT算法的加速版本. (原文) 在SIFT算法当中使用高斯差分方程(Difference of Gaussian)对高斯拉普拉斯方程( Laplacian of Gaussian)进行近似.然而,SURF使
-
Python OpenCV获取视频的方法
之前有文章,使用Android平台的OpenCV接入了视频,控制的目标是手机的摄像头,这是OpenCV的好处,使用OpenCV可以使用跨平台的接口实现相同的功能,减少了平台间移植的困难.正如本文后面,将使用类似的接口,从笔记本的摄像头获取视频,所以,尝试本文代码需要有一台有摄像头的电脑. 不过,需要说明的的是,OpenCV的强项在于图像相关的处理,而不是视频的编解码,所以,不要使用OpenCV做多余的事情,我们使用OpenCV接入视频或者图片的目的,是为了对视频或图片进行处理. 关于Python
-
python+openCV利用摄像头实现人员活动检测
本文实例为大家分享了python+openCV利用摄像头实现人员活动检测的具体代码,供大家参考,具体内容如下 1.前言 最近在做个机器人比赛,其中一项要求是让机器人实现对是否有人员活动的检测,所以就先拿PC端写一下,准备移植到机器人的树莓派. 2.工具 工具还是简单的python+视觉模块openCV,代码量也比较少.很简单就可以实现 3.人员检测的原理 从图书馆借了一本<特征提取与图像处理(第二版)>,是Mark S.Nixon和Alberto S.Aguado写的,其中讲了跟多关于检测
-
Python+OpenCV+pyQt5录制双目摄像头视频的实例
起因 说起来录制视频,我们可能有很多的软件,但是比较坑的是,好像很少的软件支持能够同时录制两个摄像头的视频,于是我们用python自己写一个.要是OpenCV+python.貌似很简单就能OK的事情,但是,我们的项目不是一般要展示给老师看嘛.谁愿意看一个没有界面的录制过程是吧~,最后会附上源代码~ 依赖的包 在这里,我直接把import的包写出来了各位可以进行对号入座,然后就能知道需要安装哪个包啦! import cv2 import numpy as np from PyQt5.QtWidge
-
python+opencv+caffe+摄像头做目标检测的实例代码
首先之前已经成功的使用Python做图像的目标检测,这回因为项目最终是需要用摄像头的, 所以实现摄像头获取图像,并且用Python调用CAFFE接口来实现目标识别 首先是摄像头请选择支持Linux万能驱动兼容V4L2的摄像头, 因为之前用学ARM的时候使用的Smart210,我已经确认我的摄像头是支持的, 我把摄像头插上之後自然就在 /dev 目录下看到多了一个video0的文件, 这个就是摄像头的设备文件了,所以我就没有额外处理驱动的部分 一.检测环境 再来在开始前因为之前按着国嵌的指导手册安
-
Python+OpenCV 实现图片无损旋转90°且无黑边
0. 引言 有如上一张图片,在以往的图像旋转处理中,往往得到如图所示的图片. 然而,在进行一些其他图像处理或者图像展示时,黑边带来了一些不便.本文解决图片旋转后出现黑边的问题,实现了图片尺寸不变的旋转(以上提到的黑边是图片的一部分). 1. 方法流程 (1)旋转图片,得到有黑边的旋转图片. (2)找出图片区域(不含黑边)的位置. (3)创建一个空图片(其实是矩阵). (4)将图片区域搬到此空图片. 2. 程序 #!/usr/bin/python # -*- coding: UTF-8 -*- "
-
Python+opencv+pyaudio实现带声音屏幕录制
基于个人的爱好和现实的需求,决定用Python做一个屏幕录制的脚本.因为要看一些加密的视频,每次都要登录,特别麻烦,遂决定用自己写的脚本,将加密视频的播放过程全程录制下来,这样以后看自己的录播就好了.结合近期自己学习的内容,正好用Python来练练手,巩固自己的学习效果. 经过多番搜索,决定采用Python+opencv+pyaudio来实现屏幕录制.网上搜索到的录屏,基本都是不带声音的,而我要实现的是带声音的屏幕录制.下面就开始一步一步的实现吧. 声音录制 import pyaudio imp