如何使用python爬取B站排行榜Top100的视频数据
记得收藏呀!!!
1、第三方库导入
from bs4 import BeautifulSoup # 解析网页 import re # 正则表达式,进行文字匹配 import urllib.request,urllib.error # 通过浏览器请求数据 import sqlite3 # 轻型数据库 import time # 获取当前时间
2、程序运行主函数
爬取过程主要包括声明爬取网页 -> 爬取网页数据并解析 -> 保存数据
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
(1)在爬取的过程中采用的技术为:伪装成浏览器对数据进行请求;
(2)解析爬取到的网页源码时:采用Beautifulsoup解析出需要的数据,使用re正则表达式对数据进行匹配;
(3)保存数据时,考虑到B站排行榜是每日进行刷新,故可以用当前日期进行保存数据库命名。
3、程序运行结果
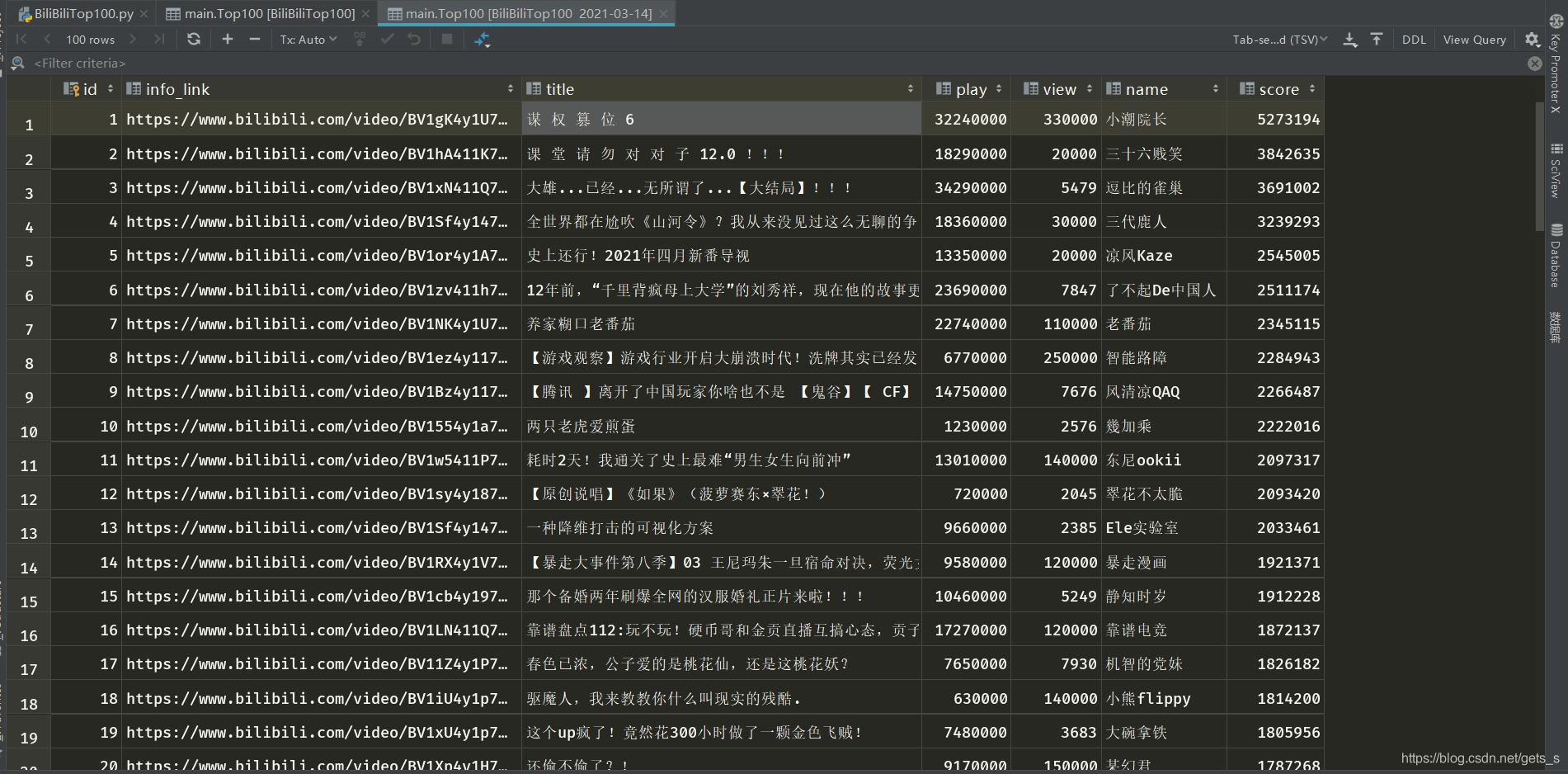
数据库中包含的数据有:排名、视频链接、标题、播放量、评论量、作者、综合分数这7个数据。
4、程序源代码
from bs4 import BeautifulSoup #解析网页
import re # 正则表达式,进行文字匹配
import urllib.request,urllib.error
import sqlite3
import time
def main():
#声明爬取网站
baseurl = "https://www.bilibili.com/v/popular/rank/all"
#爬取网页
datalist = getData(baseurl)
# print(datalist)
#保存数据
dbname = time.strftime("%Y-%m-%d", time.localtime())
dbpath = "BiliBiliTop100 " + dbname
saveData(datalist,dbpath)
#re正则表达式
findLink =re.compile(r'<a class="title" href="(.*?)" rel="external nofollow" ') #视频链接
findOrder = re.compile(r'<div class="num">(.*?)</div>') #榜单次序
findTitle = re.compile(r'<a class="title" href=".*?" rel="external nofollow" rel="external nofollow" target="_blank">(.*?)</a>') #视频标题
findPlay = re.compile(r'<span class="data-box"><i class="b-icon play"></i>([\s\S]*)(.*?)</span> <span class="data-box">') #视频播放量
findView = re.compile(r'<span class="data-box"><i class="b-icon view"></i>([\s\S]*)(.*?)</span> <a href=".*?" rel="external nofollow" rel="external nofollow" target="_blank"><span class="data-box up-name">') # 视频评价数
findName = re.compile(r'<i class="b-icon author"></i>(.*?)</span></a>',re.S) #视频作者
findScore = re.compile(r'<div class="pts"><div>(.*?)</div>综合得分',re.S) #视频得分
def getData(baseurl):
datalist = []
html = askURL(baseurl)
#print(html)
soup = BeautifulSoup(html,'html.parser') #解释器
for item in soup.find_all('li',class_="rank-item"):
# print(item)
data = []
item = str(item)
Order = re.findall(findOrder,item)[0]
data.append(Order)
# print(Order)
Link = re.findall(findLink,item)[0]
Link = 'https:' + Link
data.append(Link)
# print(Link)
Title = re.findall(findTitle,item)[0]
data.append(Title)
# print(Title)
Play = re.findall(findPlay,item)[0][0]
Play = Play.replace(" ","")
Play = Play.replace("\n","")
Play = Play.replace(".","")
Play = Play.replace("万","0000")
data.append(Play)
# print(Play)
View = re.findall(findView,item)[0][0]
View = View.replace(" ","")
View = View.replace("\n","")
View = View.replace(".","")
View = View.replace("万","0000")
data.append(View)
# print(View)
Name = re.findall(findName,item)[0]
Name = Name.replace(" ","")
Name = Name.replace("\n","")
data.append(Name)
# print(Name)
Score = re.findall(findScore,item)[0]
data.append(Score)
# print(Score)
datalist.append(data)
return datalist
def askURL(url):
#设置请求头
head = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/80.0.3987.163Safari/537.36"
}
request = urllib.request.Request(url, headers = head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
def saveData(datalist,dbpath):
init_db(dbpath)
conn = sqlite3.connect(dbpath)
cur = conn.cursor()
for data in datalist:
sql = '''
insert into Top100(
id,info_link,title,play,view,name,score)
values("%s","%s","%s","%s","%s","%s","%s")'''%(data[0],data[1],data[2],data[3],data[4],data[5],data[6])
print(sql)
cur.execute(sql)
conn.commit()
cur.close()
conn.close()
def init_db(dbpath):
sql = '''
create table Top100
(
id integer primary key autoincrement,
info_link text,
title text,
play numeric,
view numeric,
name text,
score numeric
)
'''
conn = sqlite3.connect(dbpath)
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
conn.close()
if __name__ =="__main__":
main()
到此这篇关于如何使用python爬取B站排行榜Top100的视频数据的文章就介绍到这了,更多相关python B站视频 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
基于python对B站收藏夹按照视频发布时间进行排序的问题
前言 在最一开始,我的B站收藏一直是存放在默认收藏夹中,但是随着视频收藏的越来越多,没有分类的视频放在一起,想在众多视频中找到想要的视频非常困难,因此就对收藏夹里面的视频进行了分类.但是分类之后紧接着又出现了一个新的问题:原来存放在默认收藏夹里面视频的相对顺序被打乱了--明明前几天刚收藏的视频却要翻很多很多页才能找到,因此有了这个程序. 程序的作用 因为我们看到的视频大部分都是通过推荐得到的,而推荐的视频大部分都是刚发布不久,因此大部分收藏的视频的顺序也基本是按照视频发布的顺序来的.那么通过程序
-

如何用python抓取B站数据
概述 可以获取的数据包括: video-视频模块 user-用户模块 dynamic-动态模块 这次用"Running Man"十周年特辑的视频,来做个获取弹幕的Demo. 我是对比 没有对比,就没有伤害,就像最近的"哈工大"某学生和"浙大"某学生一样. 这是之前获取弹幕的过程: 1.弹幕数据接口 https://comment.bilibili.com/123072475.xml (一个固定的url地址 + 视频的cid + .xml) 2.利
-
教你如何使用Python下载B站视频的详细教程
前言 众所周知,网页版的B站无法下载视频,然本人喜欢经常在B站学习,奈何没有网时,无法观看视频资源,手机下载后屏幕太小又不想看,遂写此程序以解决此问题 步骤 话不多说,进入正题 1.在电脑上下载python的开发环境,点一下,观看具体步骤 2.下载pycharm开发工具,点一下观看具体步骤 3.同时按键盘上的win键与r键,在弹出的对话框中输入cmd 点击确定进入cmd命令行,在里面输入pip install you-get,之后按键盘enter键,进行you-get的下载,下载完后退出cmd
-
用基于python的appium爬取b站直播消费记录
基于python的Appium进行b站直播消费记录爬取 之前看文章说fiddler也可以进行爬取,但尝试了一下没成功,这次选择appium进行爬取.类似的,可以运用爬取微信朋友圈和抖音等手机app相关数据 正文 #环境配置参考 前期工作准备,需要安装python.jdk.PyCharm.Appium-windows-x.x.Appium_Python_Client.Android SDK,pycharm可以用anaconda的jupyter来替代 具体可以参考这篇博客,讲的算是很清楚啦 http
-
如何使用python爬取B站排行榜Top100的视频数据
记得收藏呀!!! 1.第三方库导入 from bs4 import BeautifulSoup # 解析网页 import re # 正则表达式,进行文字匹配 import urllib.request,urllib.error # 通过浏览器请求数据 import sqlite3 # 轻型数据库 import time # 获取当前时间 2.程序运行主函数 爬取过程主要包括声明爬取网页 -> 爬取网页数据并解析 -> 保存数据 def main(): #声明爬取网站 baseurl = &q
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-
python爬取豆瓣电影排行榜(requests)的示例代码
''' 爬取豆瓣电影排行榜 设计思路: 1.先获取电影类型的名字以及特有的编号 2.将编号向ajax发送get请求获取想要的数据 3.将数据存放进excel表格中 ''' 环境部署: 软件安装: Python 3.7.6 官网地址:https://www.python.org/ 安装地址:https://www.python.org/ftp/python/3.7.6/python-3.7.6-amd64.exe PyCharm 2020.2.2
-
python爬取B站关注列表及数据库的设计与操作
目录 一.数据库的设计与操作 1.数据的分析 2.数据库设计 3.数据库操作 二.爬虫 三.完整代码 四.项目仓库 一.数据库的设计与操作 1.数据的分析 B站的关注列表在 https://api.bilibili.com/x/relation/followings?vmid=UID&pn=1&ps=50&order=desc&order_type=attention 中,一页最多50条信息. 我们大致分析一下信息, { "code": 0, "
-
Python爬虫之爬取哔哩哔哩热门视频排行榜
一.bs4解析 import requests from bs4 import BeautifulSoup import datetime if __name__=='__main__': url = 'https://www.bilibili.com/v/popular/rank/all' headers = { //设置自己浏览器的请求头 } page_text=requests.get(url=url,headers=headers).text soup=BeautifulSoup(pag
-
Python基于Tkinter开发一个爬取B站直播弹幕的工具
简介 使用Python Tkinter开发一个爬取B站直播弹幕的工具,启动后在弹窗中输入房间号即可,弹幕内容会保存在脚本文件同级目录下的.log扩展名的文件中 开发工具 python 3.7.9 pycharm 2019.3.5 实现代码 import threading import time import tkinter.simpledialog # 使用Tkinter前需要先导入 from tkinter import END, messagebox import requests # 全
-
Python实现爬取某站视频弹幕并绘制词云图
目录 前言 爬取弹幕 爬虫基本思路流程 导入模块 代码 制作词云图 导入模块 读取弹幕数据 前言 [课 题]: Python爬取某站视频弹幕或者腾讯视频弹幕,绘制词云图 [知识点]: 1. 爬虫基本流程 2. 正则 3. requests >>> pip install requests 4. jieba >>> pip install jieba 5. imageio >>> pip install imageio 6. wordcloud >
-
python爬取分析超级大乐透历史开奖数据第1/2页
博主作为爬虫初学者,本次使用了requests和beautifulsoup库进行数据的爬取 爬取网站:http://datachart.500.com/dlt/history/history.shtml -500彩票网 (分析后发现网站源代码并非是通过页面跳转来查找不同的数据,故可通过F12查找network栏找到真正储存所有历史开奖结果的网页) 如图: 爬虫部分: from bs4 import BeautifulSoup #引用BeautifulSoup库 import requests #
-
Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析
前言 要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful Soup爬取网页. 什么是Beautiful Soup Beautiful Soup是一款高效的Python网页解析分析工具,可以用于解析HTL和XML文件并从中提取数据. Beautiful Soup输入文件的默认编码是Unicode,输出文件的编码是UTF-8. Beautiful Soup具有将