Python爬虫基础讲解之请求
一、请求目标(URL)
URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法。类似于windows的文件路径。

二、网址的组成:
1.http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议。
2.mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail。
3.163.com:这个是域名,是用来定位网站的独一无二的名字。
4.mail.163.com:这个是网站名,由服务器名+域名组成。
5./:这个是根目录,也就是说,通过网站名找到服务器,然后在服务器存放网页的根目录。
6.index.html:这个是根目录下的网页。
7.http://mail.163.com/index.html:这个叫做URL,统一资源定位符,全球性地址,用于定位网上的资源。
三、请求体(response)
就像打电话一样,HTTP到底和服务器说了什么,才能让服务器返回正确的消息的,其实客户端的请求告诉了服务器这些内容:请求行、请求头部、空行、请求数据
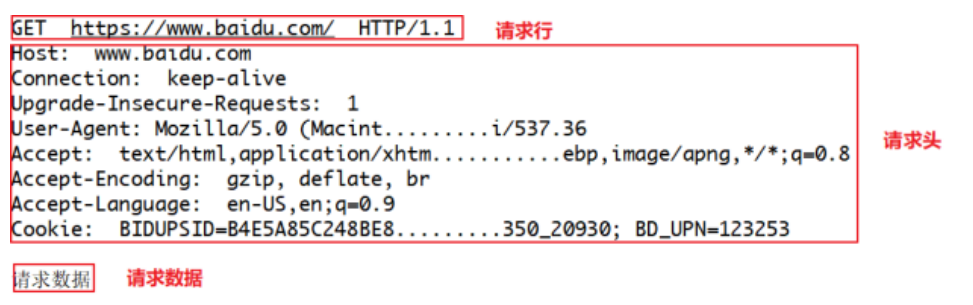
四、请求方法(Method)
HTTP请求可以使用多种请求方法,但是爬虫最主要就两种方法:GET和POST方法。
get请求:一般情况下,只从服务器获取数据下来,并不会对服务器资源产生任何影响的时候会使用get请求。
post请求:向服务器发送数据(登录)、上传文件等,会对服务器资源产生影响的时候会使用
post请求。
以上是在网站开发中常用的两种方法。并且一般情况下都会遵循使用的原则。但是有的网站和服务器为了做反爬虫机制,也经常会不按常理出牌,有可能一个应该使用get方法的请求就一定要改成post请求,这个要视情况而定。
GET与POST方法的区别:
1.GET是从服务器上获取数据,POST是向服务器传送数据
2.GET请求参数都显示在浏览器网址上,即Get"请求的参数是URL的一部分。例如: http://www.baidu.com/s?wd=Chinese
3.POST请求参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送,通常用来向HTTP服务器提交量比较大的数据。请求的参数类型包含在"Content-Type"消息头里,指明发送请求时要提交的数据格式。
注意:
网站制作者一般不会使用Get方式提交表单,因为有可能会导致安全问题。比如说在登陆表单中用Get方式,用户输入的用户名和密码将在地址栏中暴露无遗。并且浏览器会记录历史信息,导致账号不安全的因素存在。
五、常用的请求报头
请求头描述了客户端向服务器发送请求时所使用的编码,以及发送内容的长度,告诉服务器自己有没有登陆,采用的什么浏览器访问的等等。
1.Accept:浏览器告诉服务器自己接受什么数据类型,文字,图片等。
2.Accept-charset:浏览器申明自己接收的字符集。
3.Accept-Encoding:浏览器申明自己接收的编码方法,通常指定压缩方法,是否支持压缩,支持什么压缩方法(gzip, deflate,br)。
4.Accept-Language:浏览器申明自己接收的语言。
5.Authorization:授权信息,通常出现在对服务器发送的WWW-Authenticate头的应答中。
6.content-Length表示请求消息正文的长度。
7.origin:声明请求资源的起始位置
8.connection:处理完这次请求后,是断开连接还是继续保持连接。9.Cookie:发送给WEB服务器的Cookie内容,经常用来判断是否登陆了。
9.Cookie:发送给WEB服务器的Cookie内容,经常用来判断是否登陆了。
10.Host:客户端指定自己想访问的WEB服务器的域名/IP地址和端口号。
11.If-Modified-since:客户机通过这个头告诉服务器,资源的缓存时间。只有当所请求的内容在指定的时间后又经过修改才返回它,否则返回304"Not Modified"应答。
12.Pragma:指定"no-cache"值表示服务器必须返回一个刷新后的文档,即使它是代理服务器而且已经有了页面的本地拷贝。
13.Referer:告诉服务器该页面从哪个页面链接的。
14.From∶请求发送者的email地址,由一些特殊的Web客户程序使用,浏览器不会用到它。
15.(user-Agent:浏览器表明自己的身份(是哪种浏览器)
16.upgrade-insecure-requests∶申明浏览器支持从http请求自动升级为https请求,并且在以后发送请求的时候都使用https。
UA-Pixels,uA-Color,uA-oS,UA-CPU:由某些版本的IE浏览器所发送的非标准的请求头,表示屏幕大小、颜色深度、操作系统和CPu类型。
六、requests模块查看请求体
在我们用requests模块请求数据的时候携带上诉请求报头的字段信息,将我们的爬虫代码进行伪装。同样的伪装之后我们也可以通过代码查看请求体的字段信息,有如下几种常见的属性:
#查看请求体中的url地址 response.request.url #查看请求体中的请求头信息 response.request.headers #查看请求体中的请求方法 response.request.method
到此这篇关于Python爬虫基础讲解之请求的文章就介绍到这了,更多相关Python请求内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python爬虫系列网络请求案例详解
学习了之前的基础和爬虫基础之后,我们要开始学习网络请求了. 先来看看urllib urllib的介绍 urllib是Python自带的标准库中用于网络请求的库,无需安装,直接引用即可. 主要用来做爬虫开发,API数据获取和测试中使用. urllib库的四大模块: urllib.request: 用于打开和读取url urllib.error : 包含提出的例外,urllib.request urllib.parse:用于解析url urllib.robotparser:用于解析robots.tx
-
Python urllib request模块发送请求实现过程解析
1.Request()的参数 import urllib.request request=urllib.request.Request('https://python.org') response=urllib.request.urlopen(request) print(response.read().decode('utf-8')) 通过构造这个数据结构,一方面可以我们可以将请求独立成一个对象,另一方面可以更加丰富和灵活地配置参数. 它的构造方法如下: class.urllib.reques
-
python 发送get请求接口详解
简介 如果想用python做接口测试,我们首先有不得不了解和学习的模块.它就是第三方模块:Requests. 虽然Python内置的urllib模块,用于访问网络资源.但是,它用起来比较麻烦,而且,缺少很多实用的高级功能.更好的方案是使用 requests.它是一个Python第三方库,处理URL资源特别方便.查看其中文官网:http://cn.python-requests.org/zh_CN/latest/index.html英文官网:http://www.python-requests.o
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
Python3+Django get/post请求实现教程详解
一.说明 之前写了一篇"Python3+PyCharm+Django+Django REST framework开发教程 ",想着直接介绍rest就完了.但回过头来看,一是rest在解耦的同时将框架复杂化了如果没有多终端那rest根本没有降低复杂度反而增加了复杂度,二是基础的get和post实现自己还是看半天.所以还是有必要再写一篇来介绍django常规的MVC开发. 环境搭建程项目创建都类似的的rest化部分之前(2.5及之前)进行操作即可,就不重复说明了.这里我创建的项目为djan
-
python 爬虫请求模块requests详解
requests 相比urllib,第三方库requests更加简单人性化,是爬虫工作中常用的库 requests安装 初级爬虫的开始主要是使用requests模块 安装requests模块: Windows系统: cmd中: pip install requests mac系统中: 终端中: pip3 install requests requests库的基本使用 import requests url = 'https://www.csdn.net/' reponse = requests.
-
Python Http请求json解析库用法解析
httpparser介绍 :1.解析字节类型的http与https请求数据 :2.支持已k-v形式修改请求数据 :3.支持重新编码请求数据 源码 import json __author = "-ling" def parser(request_data): # 获取请求的三个段: # 1.请求方法 URI协议 版本 # 2.请求头(Request Header) # 3.请求正文 index0 = request_data.find(b"\r\n\r\n") re
-
详解python requests中的post请求的参数问题
问题:最新在爬取某站点的时候,发现在post请求当中,参数构造正确却获取不到数据,索性将post的参数urlencode之后放到post请求的url后面变成get请求,结果成功获取到数据,对此展开疑问. 1.http请求中Form Data和Request Playload的区别: Ajax post请求中常用的两种参数形式:form data 和 request payload get请求的时候,我们的参数直接反映在url里面,为key1=value1&key2=value2形式,如果是pos
-
python 实现Requests发送带cookies的请求
一.缘 起 最近学习[悠悠课堂]的接口自动化教程,文中提到Requests发送带cookies请求的方法,笔者随之也将其用于手头实际项目中,大致如下 二.背 景 实际需求是监控平台侧下发消息有无异常,如有异常便触发报警推送邮件,项目中下发消息接口需要带cookies 三.说 明 脚本的工程名为ynJxhdSendMsg,大致结构如下图 sendMsg.py为主程序,函数checkMsg为在已发消息列表中查找已下发消息,函数sendMsg为发消息并根据结果返回对应的标识 sendAlertEmai
-
快速一键生成Python爬虫请求头
今天介绍个神奇的网站!堪称爬虫偷懒的神器! 我们在写爬虫,构建网络请求的时候,不可避免地要添加请求头( headers ),以 mdn 学习区为例,我们的请求头是这样的: 一般来说,我们只要添加 user-agent 就能满足绝大部分需求了,Python 代码如下: import requests headers = { #'authority': 'developer.mozilla.org', #'pragma': 'no-cache', #'cache-control': 'no-cach
-
python实现三种随机请求头方式
相信大家在爬虫中都设置过请求头 user-agent 这个参数吧? 在请求的时候,加入这个参数,就可以一定程度的伪装成浏览器,就不会被服务器直接识别为spider.demo.code ,据我了解的,我很多读者每次都是直接从network 中去复制 user-agent 然后把他粘贴到代码中, 这样获取的user-agent 没有错,可以用, 但是如果网站反爬措施强一点,用固定的请求头可能就有点问题, 所以我们就需要设置一个随机请求头,在这里,我分享一下我自己一般用的三种设置随机请求头方式 思路介
-
python+excel接口自动化获取token并作为请求参数进行传参操作
1.登录接口登录后返回对应token封装: import json import requests from util.operation_json import OperationJson from base.runmethod import RunMethod class OperationHeader: def __init__(self, response): self.response = json.loads(response) def get_response_token(self
-
Python使用grequests并发发送请求的示例
前言 requests是Python发送接口请求非常好用的一个三方库,由K神编写,简单,方便上手快.但是requests发送请求是串行的,即阻塞的.发送完一条请求才能发送另一条请求. 为了提升测试效率,一般我们需要并行发送请求.这里可以使用多线程,或者协程,gevent或者aiohttp,然而使用起来,都相对麻烦. grequests是K神基于gevent+requests编写的一个并发发送请求的库,使用起来非常简单. 安装方法: pip install gevent grequests 项目地