使用tensorflow 实现反向传播求导
看代码吧~
X=tf.constant([-1,-2],dtype=tf.float32)
w=tf.Variable([2.,3.])
truth=[3.,3.]
Y=w*X
# cost=tf.reduce_sum(tf.reduce_sum(Y*truth)/(tf.sqrt(tf.reduce_sum(tf.square(Y)))*tf.sqrt(tf.reduce_sum(tf.square(truth)))))
cost=Y[1]*Y
optimizer = tf.train.GradientDescentOptimizer(1).minimize(cost)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print(sess.run(Y))
print(sess.run(w))
print(sess.run(cost))
print(sess.run(Y))
sess.run(optimizer)
print(sess.run(w))
结果如下

W由[2,3]变成[-4,-25]
过程:
f=y0*y=w0*x0*w*x=[w1*x1*w0*x0,w1*x1*w1*x1,]
f对w0求导,得w1*x0*x1+0=6 ,所以新的w0=w0-6=-4
f对w1求导,得 w0*x0*x1+2*w1*x1*x1=28,所以新的w1=w1-28=-25
补充:【TensorFlow篇】--反向传播
一、前述
反向自动求导是 TensorFlow 实现的方案,首先,它执行图的前向阶段,从输入到输出,去计算节点
值,然后是反向阶段,从输出到输入去计算所有的偏导。
二、具体
1、举例
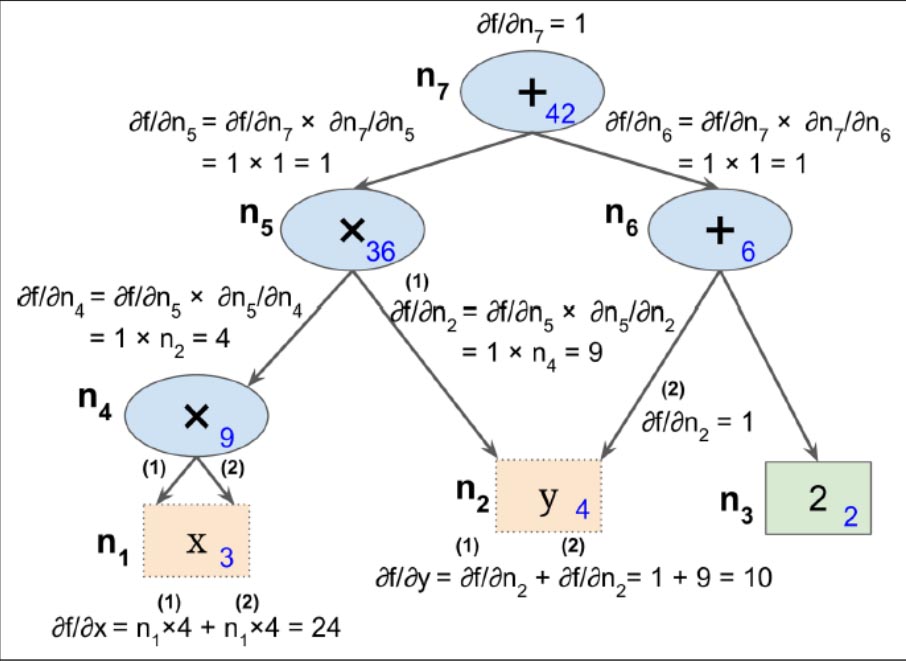
图是第二个阶段,在第一个阶段中,从 x =3和 y =4开始去计算所有的节点值
f ( x / y )=x 2 * y + y + 2
求解的想法是逐渐的从图上往下,计算 f ( x , y )的偏导,使用每一个连续的节点,直到我们到达变量节
点,严重依赖链式求导法则!
2.具体过程:
因为n7是输出节点,所以f=n7,所以𝜕f/𝜕𝑛7= 1
让我们继续往下走到n5节点,𝜕f/𝜕𝑛5=𝜕f/𝜕𝑛7∗𝜕𝑛7/𝜕𝑛5 . 我们已知𝜕f/𝜕𝑛7=1,所以我们需要知道𝜕𝑛7/𝜕𝑛5 ,因为n7=n5+n6,所以我们求得𝜕𝑛7/𝜕𝑛5=1,所以𝜕f/𝜕𝑛5=1*1=1
现在我们继续走到节点n4,𝜕f/𝜕𝑛4=𝜕f/𝜕𝑛5∗𝜕𝑛5/𝜕𝑛4,因为n5=n4*n2,我们求得�𝑛5/𝜕𝑛4=n2,𝜕f/𝜕𝑛4=1*4
沿着图一路向下,我们可以计算出所有节点,就能计算出 𝜕𝑓/𝜕x= 24,𝜕𝑓/𝜕y= 10
那我们就可以利用和上面类似的方式方法去计算𝜕𝑓/𝜕𝑤
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
tensorflow中的梯度求解及梯度裁剪操作
1. tensorflow中梯度求解的几种方式 1.1 tf.gradients tf.gradients( ys, xs, grad_ys=None, name='gradients', colocate_gradients_with_ops=False, gate_gradients=False, aggregation_method=None, stop_gradients=None, unconnected_gradients=tf.UnconnectedGradients.NONE )
-
解决tensorflow 与keras 混用之坑
在使用tensorflow与keras混用是model.save 是正常的但是在load_model的时候报错了在这里mark 一下 其中错误为:TypeError: tuple indices must be integers, not list 再一一番百度后无结果,上谷歌后找到了类似的问题.但是是一对鸟文不知道什么东西(翻译后发现是俄文).后来谷歌翻译了一下找到了解决方法.故将原始问题文章贴上来警示一下 原训练代码 from tensorflow.python.keras.preproce
-

TensorFlow的自动求导原理分析
原理: TensorFlow使用的求导方法称为自动微分(Automatic Differentiation),它既不是符号求导也不是数值求导,而类似于将两者结合的产物. 最基本的原理就是链式法则,关键思想是在基本操作(op)的水平上应用符号求导,并保持中间结果(grad). 基本操作的符号求导定义在\tensorflow\python\ops\math_grad.py文件中,这个文件中的所有函数都用RegisterGradient装饰器包装了起来,这些函数都接受两个参数op和grad,参数op是
-
Tensorflow 如何从checkpoint文件中加载变量名和变量值
假设你已经经过上千次的迭代,并且得到了以下模型: 则从这些checkpoint文件中加载变量名和变量值代码如下: model_dir = './ckpt-182802' import tensorflow as tf from tensorflow.python import pywrap_tensorflow reader = pywrap_tensorflow.NewCheckpointReader(model_dir) var_to_shape_map = reader.get_varia
-
Python3安装tensorflow及配置过程
简介 TensorFlow 是一个端到端开源机器学习平台.它拥有一个全面而灵活的生态系统,其中包含各种工具.库和社区资源,可助力研究人员推动先进机器学习技术的发展,并使开发者能够轻松地构建和部署由机器学习提供支持的应用.那它能干什么用呢? 轻松地构建模型:在即刻执行环境中使用 Keras 等直观的高阶 API 轻松地构建和训练机器学习模型,该环境使我们能够快速迭代模型并轻松地调试模型. 随时随地进行可靠的机器学习生产:无论您使用哪种语言,都可以在云端.本地.浏览器中或设备上轻松地训练和部署模型.
-
使用tensorflow 实现反向传播求导
看代码吧~ X=tf.constant([-1,-2],dtype=tf.float32) w=tf.Variable([2.,3.]) truth=[3.,3.] Y=w*X # cost=tf.reduce_sum(tf.reduce_sum(Y*truth)/(tf.sqrt(tf.reduce_sum(tf.square(Y)))*tf.sqrt(tf.reduce_sum(tf.square(truth))))) cost=Y[1]*Y optimizer = tf.train.Gra
-
pytorch中的自定义反向传播,求导实例
pytorch中自定义backward()函数.在图像处理过程中,我们有时候会使用自己定义的算法处理图像,这些算法多是基于numpy或者scipy等包. 那么如何将自定义算法的梯度加入到pytorch的计算图中,能使用Loss.backward()操作自动求导并优化呢.下面的代码展示了这个功能` import torch import numpy as np from PIL import Image from torch.autograd import gradcheck class Bicu
-
Pytorch反向求导更新网络参数的方法
方法一:手动计算变量的梯度,然后更新梯度 import torch from torch.autograd import Variable # 定义参数 w1 = Variable(torch.FloatTensor([1,2,3]),requires_grad = True) # 定义输出 d = torch.mean(w1) # 反向求导 d.backward() # 定义学习率等参数 lr = 0.001 # 手动更新参数 w1.data.zero_() # BP求导更新参数之前,需先对导
-
Pytorch反向传播中的细节-计算梯度时的默认累加操作
Pytorch反向传播计算梯度默认累加 今天学习pytorch实现简单的线性回归,发现了pytorch的反向传播时计算梯度采用的累加机制, 于是百度来一下,好多博客都说了累加机制,但是好多都没有说明这个累加机制到底会有啥影响, 所以我趁着自己练习的一个例子正好直观的看一下以及如何解决: pytorch实现线性回归 先附上试验代码来感受一下: torch.manual_seed(6) lr = 0.01 # 学习率 result = [] # 创建训练数据 x = torch.rand(20, 1
-
pytorch loss反向传播出错的解决方案
今天在使用pytorch进行训练,在运行 loss.backward() 误差反向传播时出错 : RuntimeError: grad can be implicitly created only for scalar outputs File "train.py", line 143, in train loss.backward() File "/usr/local/lib/python3.6/dist-packages/torch/tensor.py", li
-
Tensorflow 卷积的梯度反向传播过程
一. valid卷积的梯度 我们分两种不同的情况讨论valid卷积的梯度:第一种情况,在已知卷积核的情况下,对未知张量求导(即对张量中每一个变量求导):第二种情况,在已知张量的情况下,对未知卷积核求导(即对卷积核中每一个变量求导) 1.已知卷积核,对未知张量求导 我们用一个简单的例子理解valid卷积的梯度反向传播.假设有一个3x3的未知张量x,以及已知的2x2的卷积核K Tensorflow提供函数tf.nn.conv2d_backprop_input实现了valid卷积中对未知变量的求导,以
-
TensorFlow如何实现反向传播
使用TensorFlow的一个优势是,它可以维护操作状态和基于反向传播自动地更新模型变量. TensorFlow通过计算图来更新变量和最小化损失函数来反向传播误差的.这步将通过声明优化函数(optimization function)来实现.一旦声明好优化函数,TensorFlow将通过它在所有的计算图中解决反向传播的项.当我们传入数据,最小化损失函数,TensorFlow会在计算图中根据状态相应的调节变量. 回归算法的例子从均值为1.标准差为0.1的正态分布中抽样随机数,然后乘以变量A,损失函
-
tensorflow求导和梯度计算实例
1. 函数求一阶导 import tensorflow as tf tf.enable_eager_execution() tfe=tf.contrib.eager from math import pi def f(x): return tf.square(tf.sin(x)) assert f(pi/2).numpy()==1.0 sess=tf.Session() grad_f=tfe.gradients_function(f) print(grad_f(np.zeros(1))[0].n
-
tensorflow 实现自定义梯度反向传播代码
以sign函数为例: sign函数可以对数值进行二值化,但在梯度反向传播是不好处理,一般采用一个近似函数的梯度作为代替,如上图的Htanh.在[-1,1]直接梯度为1,其他为0. #使用修饰器,建立梯度反向传播函数.其中op.input包含输入值.输出值,grad包含上层传来的梯度 @tf.RegisterGradient("QuantizeGrad") def sign_grad(op, grad): input = op.inputs[0] cond = (input>=-1