如何使用Python逆向抓取APP数据
今天给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固,所以除了抓包之外,还需要对 APP 进行查壳脱壳反编译等操作。
所需设备和环境:
设备:安卓手机
抓包:
fiddler+xposed+JustTrustme
查壳:ApkScan-PKID
脱壳:frida-DEXDump
反编译:jadx-gui
hook:frida
抓包
手机安装app,设置好代理,打开 fiddler 先来抓个包,发现这个 app 做了证书验证,fiddler 开启之后 app提示连接不到服务器:

那就是 app 做了 SSL pinning 证书验证,解决这种问题一般都是安装 xposed 框架,里面有一个 JustTrustme 模块,它的原理就是hook,直接绕过证书验证类,安装方法大家百度吧。
之后再打开app,可以看到成功抓到了包:
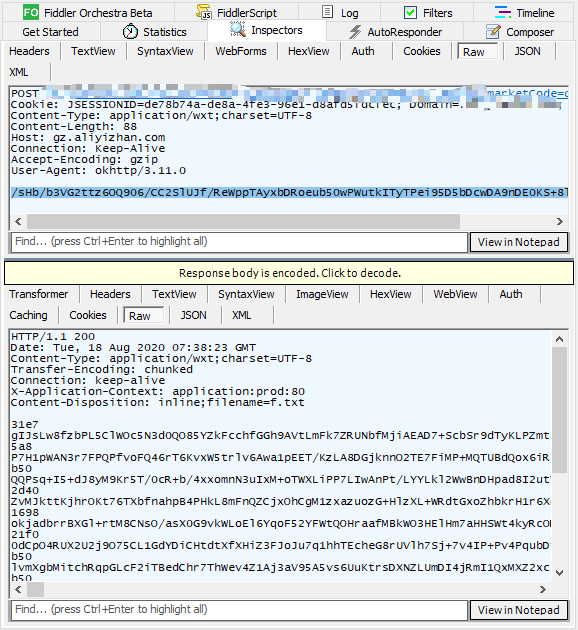
先简单分析一下,可以看到请求体中 formdata 是密文,响应内容也是密文,这个请求和响应中有用信息非常少,甚至都不知道在 jadx-gui 里怎么搜索,请求体中 formdata 是以两个等号结尾的,应该是个 base64 编码,其他一概不知。。。
脱壳反编译
那先来反编译,在这之前,通常是先用查壳工具检查一下 app 是否加固,打开 ApkScan-PKID ,把 app
可以看到这个 app 使用了 360 加固,真是层层设限啊!!这里使用frida-DEXDump来脱壳,可以到 github 上下载 frida-DEXDump 的源代码,完成之后打开项目所在文件夹,在当前位置打开命令行运行以下命令:
python main.py
等待脱壳完成,可以看到当前项目中生成了一个对应文件夹,里面有很多dex文
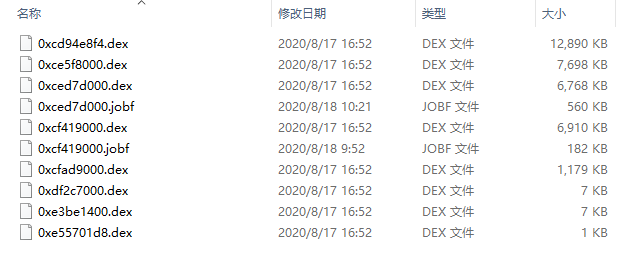
下面用 jadx-gui 打开 dex 文件,一般先从最大的文件开始依次搜索关键字,我们知道 java 中使用 base64 是有 BASE64Encoder 关键字的,因为抓包得到的信息非常少,在这里就只能搜索这个关键字了,搜到第四个dex中,得到了疑似加密处:
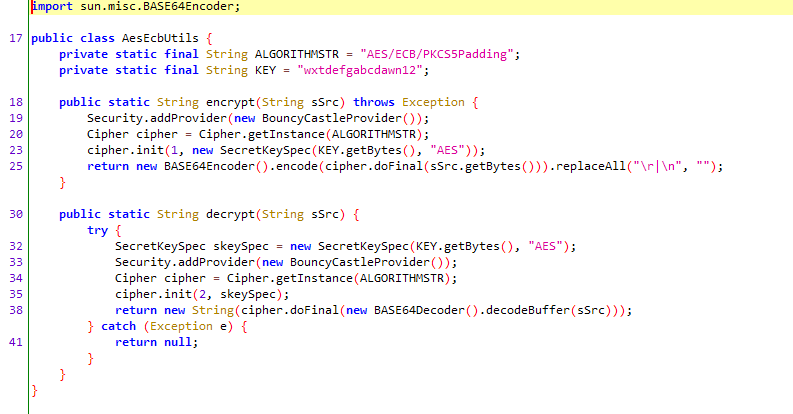
可以看到是使用了一个 aes 加密,密钥是固定的字符串。
Frida Hoo
Java不太熟,分析不来,直接使用 frida 来写一段 hook 代码看一看 encrypt 函数入参和出参的内容:
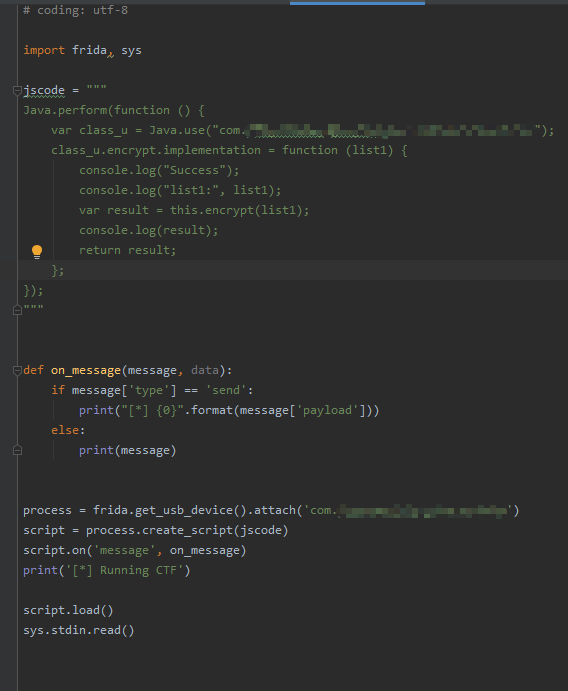
同时来抓包对比:
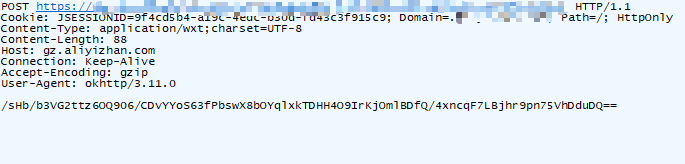

就得到了这里的请求 data 入参数据:
pageIndex:当前页码
pageSize:当前页对应的数据条数
typeId 和 source 是固定的, 接下来再来 hook decrypt 函数,对比抓包和 hook 结果:

结果是一样的,至此,我们逆向分析就完成了。
总结一下请求和响应过程,就是请求体中的 data 经过 encrypt 函数加密传参,改变 pageIndex 就可以得到每页数据,响应是经过 decrypt 函数加密显示,那我们只需要在 python 中实现这个 aes 加密解密过程就行了,从反编译的 java 代码中可以看出密钥是固定的:wxtdefgabcdawn12,没有 iv 偏移。
请求
直接上代码:
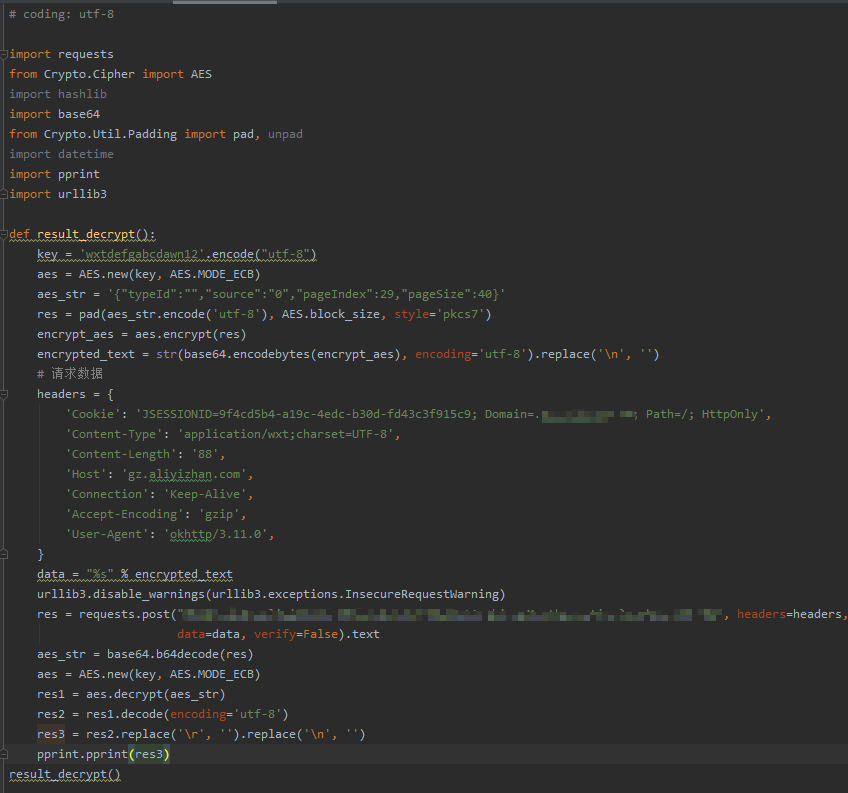
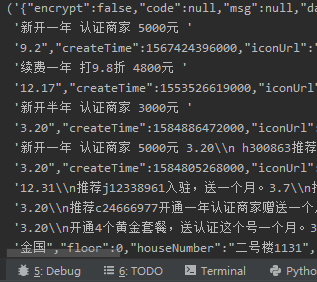
运行代码,成功拿到数据:
到此这篇关于如何使用Python逆向抓取APP数据的文章就介绍到这了,更多相关Python逆向抓取APP数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫抓取手机APP的传输数据
大多数APP里面返回的是json格式数据,或者一堆加密过的数据 .这里以超级课程表APP为例,抓取超级课程表里用户发的话题. 1.抓取APP数据包 方法详细可以参考这篇博文:Fiddler如何抓取手机APP数据包 得到超级课程表登录的地址:http://120.55.151.61/V2/StudentSkip/loginCheckV4.action 表单: 表单中包括了用户名和密码,当然都是加密过了的,还有一个设备信息,直接post过去就是. 另外必须加header,一开始我没有加header得
-
如何使用Python逆向抓取APP数据
今天给大伙分享一下 Python 爬虫的教程,这次主要涉及到的是关于某 APP 的逆向分析并抓取数据,关于 APP 的反爬会麻烦一些,比如 Android 端的代码写完一般会进行打包并混淆加密加固,所以除了抓包之外,还需要对 APP 进行查壳脱壳反编译等操作. 所需设备和环境: 设备:安卓手机 抓包: fiddler+xposed+JustTrustme 查壳:ApkScan-PKID 脱壳:frida-DEXDump 反编译:jadx-gui hook:frida 抓包 手机安装app,设置好
-
Python使用Appium在移动端抓取微博数据的实现
目录 使用Appium在移动端抓取微博数据 查找Android App的Package和入口 记录微博刷新动作 爬取微博第一条信息 使用Appium在移动端抓取微博数据 Appium是移动端的自动化测试工具,读者可以类比为PC端的selenium.通过它,我们可以驱动App完成自动化的一系列操作,同样也可以爬取需要的内容. 这里,我们需要首先在PC端安装Appium软件,安装下载的地址如下:https://github.com/appium/appium-desktop/releases 安装软
-
使用python实现抓取中国银行外汇牌价首页数据实现
利用requests.BeautifulSoup.xlwings库抓取中国银行外汇牌价首页数据 1. 利用requests.BeautifulSoup.xlwings库抓取中国银行外汇牌价首页数据. (1)中国银行外汇牌价网址如下. https://www.bankofchina.com/sourcedb/whpj/ (2)调用requests模块中get方法访问上述网址,获取Response 对象. url = "https://www.bankofchina.com/sourcedb/whp
-
python爬虫抓取时常见的小问题总结
目录 01 无法正常显示中文? 解决方法 02 加密问题 03 获取不到网页的全部代码? 04 点击下一页时网页网页不变 05 文本节点问题 06 如何快速找到提取数据? 07 获取标签中的数据 08 去除指定内容 09 转化为字符串类型 10 滥用遍历文档树 11 数据库保存问题 12 爬虫采集遇到的墙问题 逃避IP识别 变换请求内容 降低访问频率 慢速攻击判别 13 验证码问题 正向破解 逆向破解 前言: 现在写爬虫,入门已经不是一件门槛很高的事情了,网上教程一大把,但很多爬虫新手在爬取数据
-
Python正则抓取新闻标题和链接的方法示例
本文实例讲述了Python正则抓取新闻标题和链接的方法.分享给大家供大家参考,具体如下: #-*-coding:utf-8-*- import re from urllib import urlretrieve from urllib import urlopen #获取网页信息 doc = urlopen("http://www.itongji.cn/news/").read() #自己找的一个大数据的新闻网站 #抓取新闻标题和链接 def extract_title(info):
-
python访问抓取网页常用命令总结
python访问抓取网页常用命令 简单的抓取网页: import urllib.request url="http://google.cn/" response=urllib.request.urlopen(url) #返回文件对象 page=response.read() 直接将URL保存为本地文件: import urllib.request url="http://google.cn/" response=urllib.request.urlopen(url)
-
Python如何抓取天猫商品详细信息及交易记录
本文实例为大家分享了Python抓取天猫商品详细信息及交易记录的具体代码,供大家参考,具体内容如下 一.搭建Python环境 本帖使用的是Python 2.7 涉及到的模块:spynner, scrapy, bs4, pymmssql 二.要获取的天猫数据 三.数据抓取流程 四.源代码 #coding:utf-8 import spynner from scrapy.selector import Selector from bs4 import BeautifulSoup import ran
-
Python实现抓取HTML网页并以PDF文件形式保存的方法
本文实例讲述了Python实现抓取HTML网页并以PDF文件形式保存的方法.分享给大家供大家参考,具体如下: 一.前言 今天介绍将HTML网页抓取下来,然后以PDF保存,废话不多说直接进入教程. 今天的例子以廖雪峰老师的Python教程网站为例:http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000 二.准备工作 1. PyPDF2的安装使用(用来合并PDF): PyPDF2版本:1.2
-
python爬虫爬取网页数据并解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序. 只要浏览器能够做的事情,原则上,爬虫都能够做到. 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以用于做搜索引擎,也可以爬取网站上面的图片,比如有些朋友将某些网站上的图片全部爬取下来,集中进行浏览,同时,网络爬虫也可以用于金融投资领域,比如可以自动爬取一些金融信息,并进行投资分析等. 有时,我们比较喜欢的新闻网站可能有几个,每次都要分别