Python seaborn数据可视化绘图(直方图,密度图,散点图)
目录
- 前言
- 一、直方图distplot()
- 二、密度图
- 1.单个样本数据分布密度图
- 2.两个样本数据分布密度图
- 三、散点图
- 1.jointplot()综合散点图
- 2.拆分综合散点图JointGrid()
- 3.pairplot()矩阵散点图
- 4.拆分综合散点图JointGrid()
前言
系统自带的数据表格,使用时通过sns.load_dataset('表名称')即可,结果为一个DataFrame。
print(sns.get_dataset_names()) #获取所有数据表名称
# ['anscombe', 'attention', 'brain_networks', 'car_crashes', 'diamonds', 'dots', 'exercise', 'flights',
# 'fmri', 'gammas', 'iris', 'mpg', 'planets', 'tips', 'titanic']
tips = sns.load_dataset('tips') #导入小费tips数据表,返回一个DataFrame
tips.head()
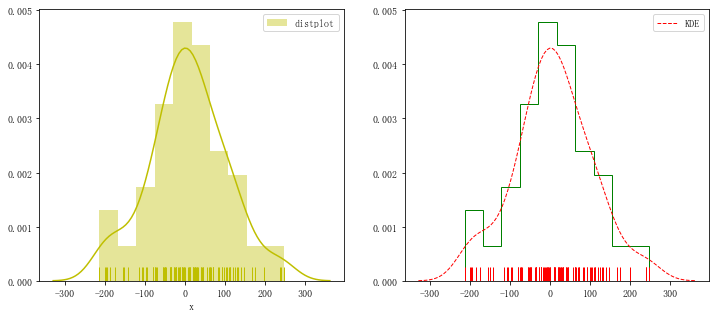
一、直方图distplot()
distplot(a, bins=None, hist=True, kde=True, rug=False, fit=None,hist_kws=None, kde_kws=None, rug_kws=None, fit_kws=None,color=None, vertical=False, norm_hist=False, axlabel=None,label=None, ax=None)
- a 数据源
- bins 箱数
- hist、kde、rug 是否显示箱数、密度曲线、数据分布,默认显示箱数和密度曲线不显示数据分析
- {hist,kde,rug}_kws 通过字典形式设置箱数、密度曲线、数据分布的各个特征
- norm_hist 直方图的高度是否显示密度,默认显示计数,如果kde设置为True高度也会显示为密度
- color 颜色
- vertical 是否在y轴上显示图标,默认为False即在x轴显示,即竖直显示
- axlabel 坐标轴标签
- label 直方图标签
fig = plt.figure(figsize=(12,5))
ax1 = plt.subplot(121)
rs = np.random.RandomState(10) # 设定随机数种子
s = pd.Series(rs.randn(100) * 100)
sns.distplot(s,bins = 10,hist = True,kde = True,rug = True,norm_hist=False,color = 'y',label = 'distplot',axlabel = 'x')
plt.legend()
ax1 = plt.subplot(122)
sns.distplot(s,rug = True,
hist_kws={"histtype": "step", "linewidth": 1,"alpha": 1, "color": "g"}, # 设置箱子的风格、线宽、透明度、颜色,风格包括:'bar', 'barstacked', 'step', 'stepfilled'
kde_kws={"color": "r", "linewidth": 1, "label": "KDE",'linestyle':'--'}, # 设置密度曲线颜色,线宽,标注、线形
rug_kws = {'color':'r'} ) # 设置数据频率分布颜色
二、密度图
#密度曲线 kdeplot(data, data2=None, shade=False, vertical=False, kernel="gau",bw="scott", gridsize=100, cut=3, clip=None, legend=True,cumulative=False,shade_lowest=True,cbar=False, cbar_ax=None,cbar_kws=None, ax=None, **kwargs)
- shade 是否填充与坐标轴之间的
- bw 取值'scott' 、'silverman'或一个数值标量,控制拟合的程度,类似直方图的箱数,设置的数量越大越平滑,越小越容易过度拟合
- shade_lowest 主要是对两个变量分析时起作用,是否显示最外侧填充颜色,默认显示
- cbar 是否显示颜色图例
- n_levels 主要对两个变量分析起作用,数据线的个数
数据分布rugplot(a, height=.05, axis="x", ax=None, **kwargs)
- height 分布线高度
- axis {'x','y'},在x轴还是y轴显示数据分布
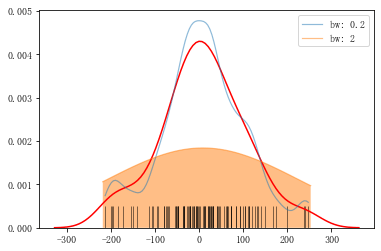
1.单个样本数据分布密度图
sns.kdeplot(s,shade = False, color = 'r',vertical = False)# 是否填充、设置颜色、是否水平 sns.kdeplot(s,bw=0.2, label="bw: 0.2",linestyle = '-',linewidth = 1.2,alpha = 0.5) sns.kdeplot(s,bw=2, label="bw: 2",linestyle = '-',linewidth = 1.2,alpha = 0.5,shade=True) sns.rugplot(s,height = 0.1,color = 'k',alpha = 0.5) #数据分布
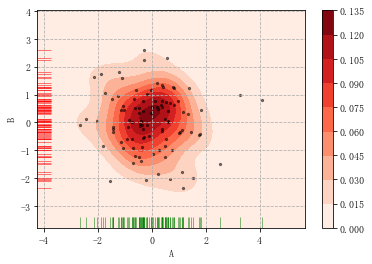
2.两个样本数据分布密度图
两个维度数据生成曲线密度图,以颜色作为密度衰减显示。
rs = np.random.RandomState(2) # 设定随机数种子 df = pd.DataFrame(rs.randn(100,2),columns = ['A','B']) sns.kdeplot(df['A'],df['B'],shade = True,cbar = True,cmap = 'Reds',shade_lowest=True, n_levels = 8)# 曲线个数(如果非常多,则会越平滑) plt.grid(linestyle = '--') plt.scatter(df['A'], df['B'], s=5, alpha = 0.5, color = 'k') #散点 sns.rugplot(df['A'], color="g", axis='x',alpha = 0.5) #x轴数据分布 sns.rugplot(df['B'], color="r", axis='y',alpha = 0.5) #y轴数据分布
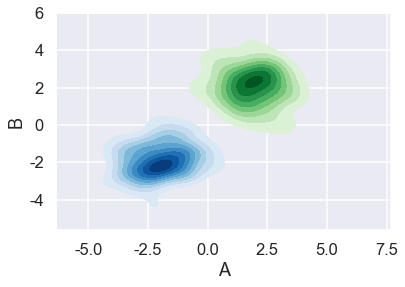
rs1 = np.random.RandomState(2)
rs2 = np.random.RandomState(5)
df1 = pd.DataFrame(rs1.randn(100,2)+2,columns = ['A','B'])
df2 = pd.DataFrame(rs2.randn(100,2)-2,columns = ['A','B'])
sns.set_style('darkgrid')
sns.set_context('talk')
sns.kdeplot(df1['A'],df1['B'],cmap = 'Greens',shade = True,shade_lowest=False)
sns.kdeplot(df2['A'],df2['B'],cmap = 'Blues', shade = True,shade_lowest=False)
三、散点图
jointplot() / JointGrid() / pairplot() /pairgrid()
1.jointplot()综合散点图
rs = np.random.RandomState(2)
df = pd.DataFrame(rs.randn(200,2),columns = ['A','B'])
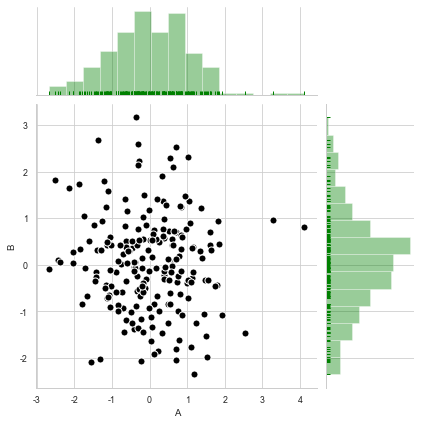
sns.jointplot(x=df['A'], y=df['B'], # 设置x轴和y轴,显示columns名称
data=df, # 设置数据
color = 'k', # 设置颜色
s = 50, edgecolor="w",linewidth=1, # 设置散点大小、边缘线颜色及宽度(只针对scatter)
kind = 'scatter', # 设置类型:“scatter”、“reg”、“resid”、“kde”、“hex”
space = 0.1, # 设置散点图和上方、右侧直方图图的间距
size = 6, # 图表大小(自动调整为正方形)
ratio = 3, # 散点图与直方图高度比,整型
marginal_kws=dict(bins=15, rug=True,color='green') # 设置直方图箱数以及是否显示rug
)
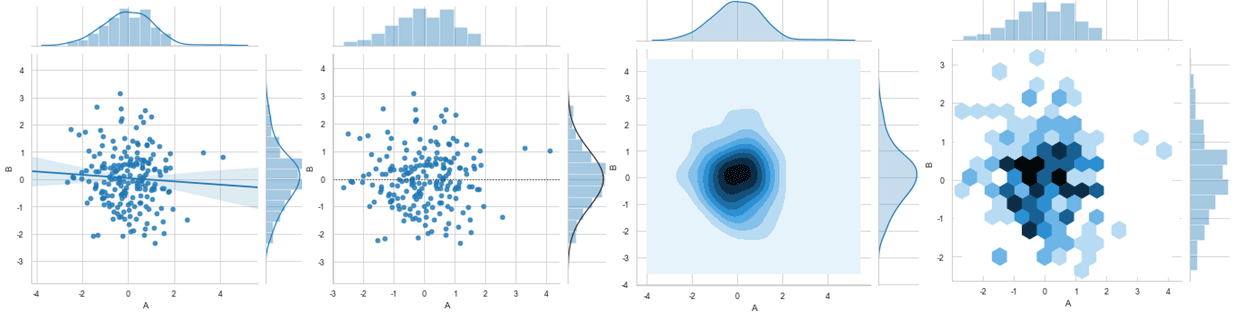
当kind分别设置为其他4种“reg”、“resid”、“kde”、“hex”时,图表如下:
sns.jointplot(x=df['A'], y=df['B'],data=df,kind='reg',size=5) # sns.jointplot(x=df['A'], y=df['B'],data=df,kind='resid',size=5) # sns.jointplot(x=df['A'], y=df['B'],data=df,kind='kde',size=5) # sns.jointplot(x=df['A'], y=df['B'],data=df,kind='hex',size=5) #蜂窝图
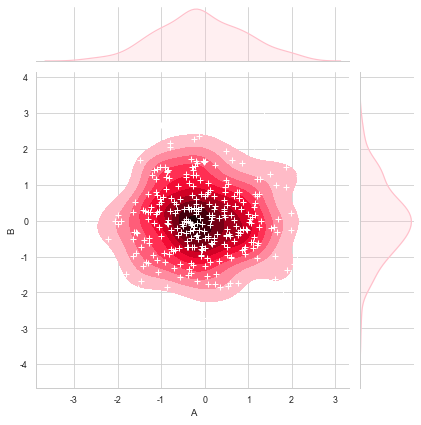
在密度图中添加散点图,先通过sns.jointplot()创建密度图并赋值给变量,再通过变量.plot_joint()在密度图中添加散点图。
rs = np.random.RandomState(15) df = pd.DataFrame(rs.randn(300,2),columns = ['A','B']) g = sns.jointplot(x=df['A'], y=df['B'],data = df, kind="kde", color="pink",shade_lowest=False) #密度图,并赋值给一个变量 g.plot_joint(plt.scatter,c="w", s=30, linewidth=1, marker="+") #在密度图中添加散点图
2.拆分综合散点图JointGrid()
上述综合散点图可分为上、右、中间三部分,设置属性时对这三个参数都生效,JointGrid()可将这三部分拆开分别设置属性。
①拆分为中间+上&右 两部分设置
# plot_joint() + plot_marginals()
g = sns.JointGrid(x="total_bill", y="tip", data=tips)# 创建一个绘图区域,并设置好x、y对应数据
g = g.plot_joint(plt.scatter,color="g", s=40, edgecolor="white") # 中间区域通过g.plot_joint绘制散点图
plt.grid('--')
g.plot_marginals(sns.distplot, kde=True, color="y") #
h = sns.JointGrid(x="total_bill", y="tip", data=tips)# 创建一个绘图区域,并设置好x、y对应数据
h = h.plot_joint(sns.kdeplot,cmap = 'Reds_r') # 中间区域通过g.plot_joint绘制散点图
plt.grid('--')
h.plot_marginals(sns.kdeplot, color="b")
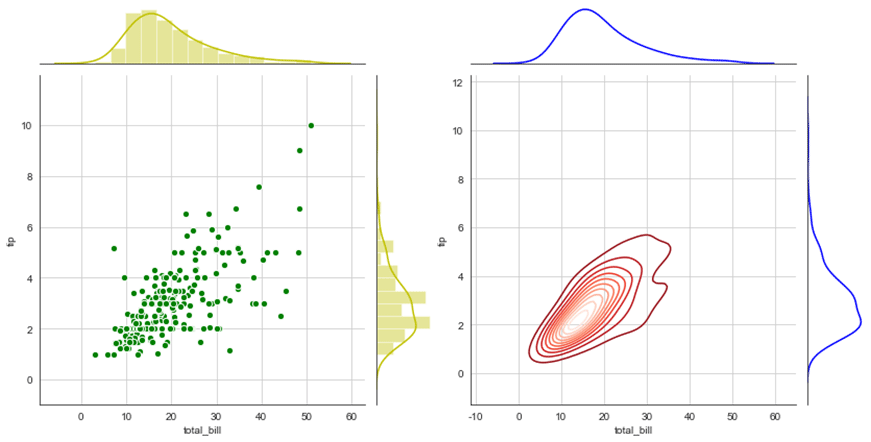
②拆分为中间+上+右三个部分分别设置
# plot_joint() + ax_marg_x.hist() + ax_marg_y.hist()
sns.set_style("white")# 设置风格
tips = sns.load_dataset("tips") # 导入系统的小费数据
print(tips.head())
g = sns.JointGrid(x="total_bill", y="tip", data=tips)# 创建绘图区域,设置好x、y对应数据
g.plot_joint(plt.scatter, color ='y', edgecolor = 'white') # 设置内部散点图scatter
g.ax_marg_x.hist(tips["total_bill"], color="b", alpha=.6,bins=np.arange(0, 60, 3)) # 设置x轴直方图,注意bins是数组
g.ax_marg_y.hist(tips["tip"], color="r", alpha=.6, orientation="horizontal", bins=np.arange(0, 12, 1)) # 设置y轴直方图,需要orientation参数
from scipy import stats
g.annotate(stats.pearsonr) # 设置标注,可以为pearsonr,spearmanr
plt.grid(linestyle = '--')
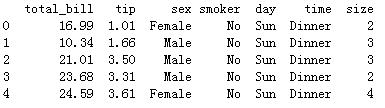
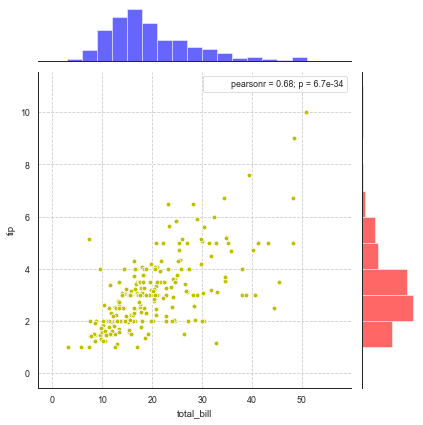
3.pairplot()矩阵散点图
矩阵散点图类似pandas的pd.plotting.scatter_matrix(...),将数据从多个维度进行两两对比。
对角线默认显示密度图,非对角线默认显示散点图。
sns.set_style("white")
iris = sns.load_dataset("iris")
print(iris.head())
sns.pairplot(iris,
kind = 'scatter', # 散点图/回归分布图 {‘scatter', ‘reg'}
diag_kind="hist", # 对角线处直方图/密度图 {‘hist', ‘kde'}
hue="species", # 按照某一字段进行分类
palette="husl", # 设置调色板
markers=["o", "s", "D"], # 设置不同系列的点样式(个数与hue分类的个数一致)
height = 1.5, # 图表大小
)
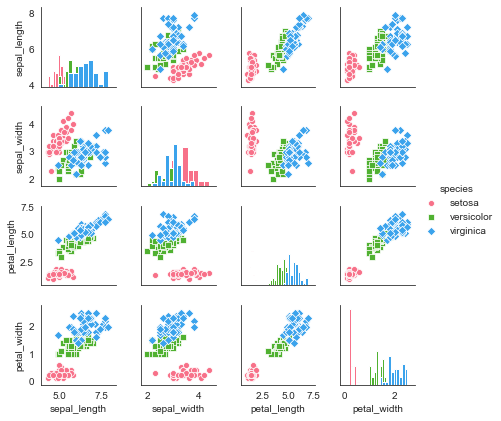
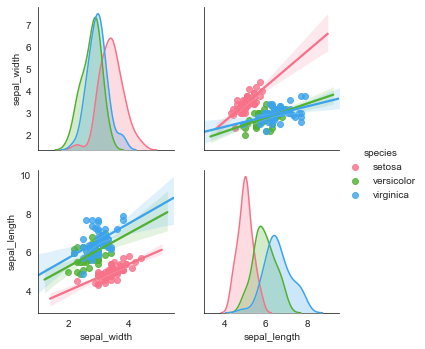
对原数据的局部变量进行分析,可添加参数vars
sns.pairplot(iris,vars=["sepal_width", "sepal_length"], kind = 'reg', diag_kind="kde", hue="species", palette="husl")
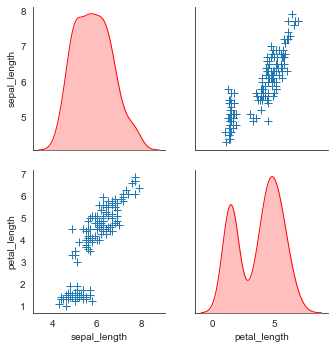
plot_kws()和diag_kws()可分别设置对角线和非对角线的显示:
sns.pairplot(iris, vars=["sepal_length", "petal_length"],diag_kind="kde", markers="+",
plot_kws=dict(s=50, edgecolor="b", linewidth=1),# 设置非对角线点样式
diag_kws=dict(shade=True,color='r',linewidth=1)# 设置对角线密度图样式
)
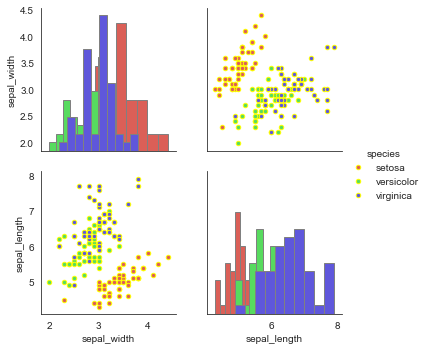
4.拆分综合散点图JointGrid()
类似JointGrid()的功能,将矩阵散点图拆分为对角线和非对角线图表分别设置显示属性。
①拆分为对角线和非对角线
# map_diag() + map_offdiag()
g = sns.PairGrid(iris,hue="species",palette = 'hls',vars=["sepal_width", "sepal_length"])
g.map_diag(plt.hist, # 对角线图表,plt.hist/sns.kdeplot
histtype = 'barstacked', # 可选:'bar', 'barstacked', 'step', 'stepfilled'
linewidth = 1, edgecolor = 'gray')
g.map_offdiag(plt.scatter, # f非对角线其他图表,plt.scatter/plt.bar...
edgecolor="yellow", s=20, linewidth = 1, # 设置点颜色、大小、描边宽度)
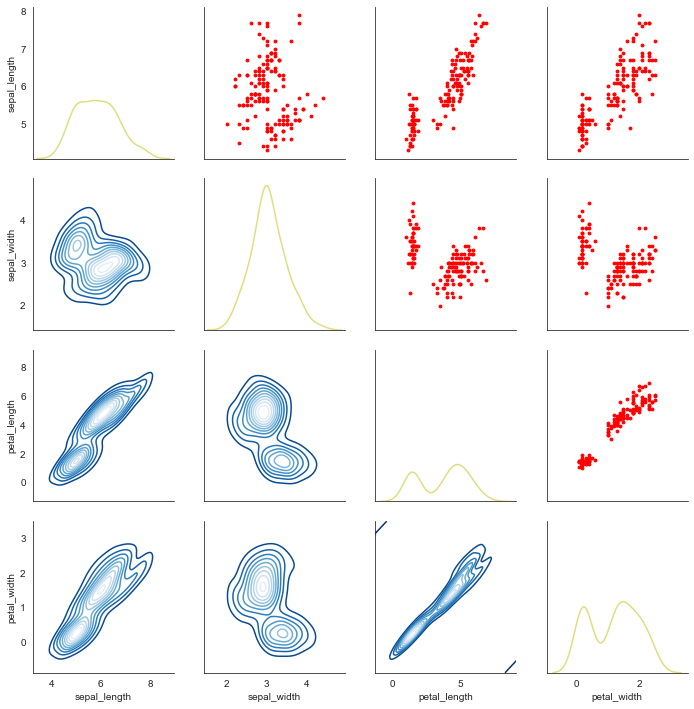
②拆分为对角线+对角线上+对角线下 3部分设置
# map_diag() + map_lower() + map_upper() g = sns.PairGrid(iris) g.map_diag(sns.kdeplot, lw=1.5,color='y',alpha=0.5) # 设置对角线图表 g.map_upper(plt.scatter, color = 'r',s=8) # 设置对角线上端图表显示为散点图 g.map_lower(sns.kdeplot,cmap='Blues_r') # 设置对角线下端图表显示为多密度分布图
到此这篇关于Python seaborn数据可视化绘图(直方图,密度图,散点图)的文章就介绍到这了,更多相关Python seaborn 绘图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python数据可视化Seaborn绘制山脊图
目录 1. 引言 2. 举个栗子 3.山脊图 4.扩展 5.结论 1. 引言 山脊图一般由垂直堆叠的折线图组成,这些折线图中的折线区域间彼此重叠,此外它们还共享相同的x轴. 山脊图经常以一种相对不常见且非常适合吸引大家注意力的紧凑图的形式表现.观察上图,我们给其起名叫Ridge plot是非常恰当的,因为上述图表看起来确实很像山的脊背.此外,上述图像还有另一个称呼叫做Joy Plots–这主要是因为Joy Division乐队在如下专辑封面上采用了这种可视化形式. 2. 举个栗子 在介绍完山脊图
-
python数据可视化Seaborn画热力图
目录 1.引言 2. 栗子 3. 数据预处理 4. 画热力图 5. 添加数值 6. 调色板优化 1.引言 热力图的想法很简单,用颜色替换数字. 现在,这种可视化风格已经从最初的颜色编码表格走了很长一段路.热力图被广泛用于地理空间数据.这种图通常用于描述变量的密度或强度,模式可视化.方差甚至异常可视化等. 鉴于热力图有如此多的应用,本文将介绍如何使用Seaborn 来创建热力图. 2. 栗子 首先我们导入Pandas和Numpy库,这两个库可以帮助我们进行数据预处理. import pandas
-
Python数据可视化库seaborn的使用总结
seaborn是python中的一个非常强大的数据可视化库,它集成了matplotlib,下图为seaborn的官网,如果遇到疑惑的地方可以到官网查看.http://seaborn.pydata.org/ 从官网的主页我们就可以看出,seaborn在数据可视化上真的非常强大. 1.首先我们还是需要先引入库,不过这次要用到的python库比较多. import numpy as np import pandas as pd import matplotlib as mpl import matpl
-
Python 数据可视化之Seaborn详解
目录 安装 散点图 线图 条形图 直方图 总结 安装 要安装 seaborn,请在终端中输入以下命令. pip install seaborn Seaborn 建立在 Matplotlib 之上,因此它也可以与 Matplotlib 一起使用.一起使用 Matplotlib 和 Seaborn 是一个非常简单的过程.我们只需要像之前一样调用 Seaborn Plotting 函数,然后就可以使用 Matplotlib 的自定义函数了. 注意: Seaborn 加载了提示.虹膜等数据集,但在本教程
-
Python中seaborn库之countplot的数据可视化使用
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是seaborn库中分类图的一种,作用是使用条形显示每个分箱器中的观察计数.接下来,对seaborn中的countplot方法进行详细的一个讲解,希望可以帮助到刚入门的同行. 导入seaborn库 import seaborn as sns 使用countplot sns.countplot() cou
-
Python数据可视化之Seaborn的使用详解
目录 1. 安装 seaborn 2.准备数据 3.背景与边框 3.1 设置背景风格 3.2 其他 3.3 边框控制 4. 绘制 散点图 5. 绘制 折线图 5.1 使用 replot()方法 5.2 使用 lineplot()方法 6. 绘制直方图 displot() 7. 绘制条形图 barplot() 8. 绘制线性回归模型 9. 绘制 核密度图 kdeplot() 9.1 一般核密度图 9.2 边际核密度图 10. 绘制 箱线图 boxplot() 11. 绘制 提琴图 violinpl
-
Python seaborn数据可视化绘图(直方图,密度图,散点图)
目录 前言 一.直方图distplot() 二.密度图 1.单个样本数据分布密度图 2.两个样本数据分布密度图 三.散点图 1.jointplot()综合散点图 2.拆分综合散点图JointGrid() 3.pairplot()矩阵散点图 4.拆分综合散点图JointGrid() 前言 系统自带的数据表格,使用时通过sns.load_dataset('表名称')即可,结果为一个DataFrame. print(sns.get_dataset_names()) #获取所有数据表名称 # ['ans
-
python使用seaborn绘图直方图displot,密度图,散点图
目录 一.直方图distplot() 二.密度图 2.1 单个样本数据分布密度图 一.直方图distplot() import numpy as np import seaborn as sns import matplotlib.pyplot as plt import matplotlib import pandas as pd fig = plt.figure(figsize=(12, 5)) ax1 = plt.subplot(121) rs = np.random.RandomStat
-
Python数据可视化绘图实例详解
目录 利用可视化探索图表 1.数据可视化与探索图 2.常见的图表实例 数据探索实战分享 1.2013年美国社区调查 2.波士顿房屋数据集 利用可视化探索图表 1.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 2.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matpl
-
Python读取CSV文件并进行数据可视化绘图
介绍:文件 sitka_weather_07-2018_simple.csv是阿拉斯加州锡特卡2018年1月1日的天气数据,其中包含当天的最高温度和最低温度.数据文件存储与data文件夹下,接下来用Python读取该文件数据,再基于数据进行可视化绘图.(详细细节请看代码注释) sitka_highs.py import csv # 导入csv模块 from datetime import datetime import matplotlib.pyplot as plt filename = 'd
-
Python matplotlib数据可视化图绘制
目录 前言 1.折线图 2.直方图 3.箱线图 4.柱状图 5.饼图 6.散点图 前言 导入绘图库: import matplotlib.pyplot as plt import numpy as np import pandas as pd import os 读取数据(数据来源是一个EXCLE表格,这里演示的是如何将数据可视化出来) os.chdir(r'E:\jupyter\数据挖掘\数据与代码') df = pd.read_csv('air_data.csv',na_values= '-
-
Python数据可视化之简单折线图的绘制
目录 创建RandomWalk类 选择方向 绘制随机漫步图 模拟多次随机漫步 给点着色 突出起点和终点 增加点数 调整尺寸以适用屏幕 创建RandomWalk类 为模拟随机漫步,我们将创建一个RandomWalk类,随机选择前进方向,这个类有三个属性,一个存储随机漫步的次数,另外两个存储随机漫步的每个点的x,y坐标,每次漫步都从点(0,0)出发 from random import choice class RandomWalk(): '''一个生成随机漫步数据的类''' def __init_
-
R语言绘图数据可视化Ridgeline plot山脊图画法
目录 Step1. 绘图数据的准备 Step2. 绘图数据的读取 Step3. 绘图所需package的安装.调用 Step4. 绘图 调整透明度 更改顺序 更改线条形状 今天给大家介绍一下Ridgeline plot(山脊图)的画法. 作图数据如下: Step1. 绘图数据的准备 首先要把你想要绘图的数据调整成R语言可以识别的格式,建议大家在excel中保存成csv格式. Step2. 绘图数据的读取 data<-read.csv("your file path", heade
-
R语言数据可视化绘图Slope chart坡度图画法
目录 Step1. 绘图数据的准备 Step2. 绘图数据的读取 Step3. 绘图所需package的安装.调用 Step4. 绘图 今天小仙给大家分享一下Slope chart(坡度图)的画法,我在paper中看到的图是这样的 这个图的意思大概是Nasal Tissue比Brochial Tissue的ACE2表达量高(ACE2就是新冠病毒的受体啦) .为了复刻这张图,小仙捏造了一组差不多的数据,竟然感觉比原图好看! 废话不多说,进入正题. Step1. 绘图数据的准备 首先要把你想要绘图的
-
python数据可视化matplotlib绘制折线图示例
目录 plt.plot()函数各参数解析 各参数具体含义为: x,y color linestyle linewidth marker 关于marker的参数 plt.plot()函数各参数解析 plt.plot()函数的作用是绘制折线图,它的参数有很多,常用的函数参数如下: plt.plot(x,y,color,linestyle,linewidth,marker,markersize,markerfacecolor,markeredgewidth,markeredgecolor) 各参数具体
-
python用matplotlib可视化绘图详解
目录 1.Matplotlib 简介 2.Matplotlib图形绘制 1)折线图 2)柱状图 3)条形图 3)饼图 4)散点图 5)直方图 6)箱型图 7)子图 1.Matplotlib 简介 Matplotlib 简介: Matplotlib 是一个python的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形,matplotlib 对于图像美化方面比较完善,可以自定义线条的颜色和样式,可以在一张绘图纸上绘制多张小图,也可以在一张图上绘制多条线,可以很方便地将数据可