Pandas 筛选和删除目标值所在的行的实现
目录
- 1.筛选出目标值所在行
- 单列筛选
- 多列筛选
- 2.删除目标值所在的行
- 扩展补充案例:删除列为指定值所在的行
1.筛选出目标值所在行
单列筛选
# df[列名].isin([目标值])对当前列中存在目标值的行会返回True,不存在的返回False df[df[列名].isin([目标值])]
练习案例
import pandas as pd
df_bom_data = pd.DataFrame([['A123',1200,5],
['B456',550,2],
['C437',500,10],
['D112',621,7],
['E211',755,11],
['F985',833,8]
],columns=['Material','Price','Quantity'])
df_material_shortage_data = pd.DataFrame([['A123','2022/6/21',100],
['B456','2022/6/22',120],
['C437','2022/6/23',250]
],columns=['Material','Schedule','LT'])
# 筛选出df_bom_data表中只包含df_material_shortage_data表中Material的行记录
df_bom_data = df_bom_data[df_bom_data['Material'].isin(df_material_shortage_data['Material'])]
df_bom_data

df_material_shortage_data

df_bom_data(处理后)

多列筛选
# 同时满足用&连接,或的话用 | 连接 df[df[列名].isin([目标值]) & df[列名].isin([目标值])] df[df[列名].isin([目标值]) | df[列名].isin([目标值])]
练习案例
import pandas as pd
df = pd.DataFrame([['L123','A',0],
['L456','A',1],
['L437','C',0],
['L112','B',1],
['L211','A',0],
['L985','B',1]
],columns=['Material','Level','Passing'])
# 筛选出指定列都有目标值的行
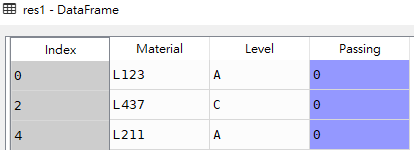
res1 = df[df['Level'].isin(['A','C']) & df['Passing'].isin([0])]
# 筛选出至少有一列有目标值的行
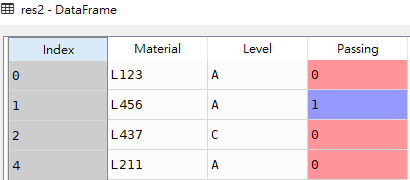
res2 = df[df['Level'].isin(['A','C']) | df['Passing'].isin([0])]
df

res1
res2
2.删除目标值所在的行
练习案例
import pandas as pd
import numpy as np
df_bom_data = pd.DataFrame([['A123',1200,5],
['B456',np.nan,np.nan],
['C437',500,10]
],columns=['Material','Price','Quantity'])
df_material_shortage_data = pd.DataFrame([['A123','2022/6/21',100],
['B456','2022/6/22',120],
['C437','2022/6/23',250]
],columns=['Material','Schedule','LT'])
# 筛选出df_bom_data中'Price'和'Quantity'两列字段的值都为空(nans)的行
df_isnull_bom_data = df_bom_data[pd.isnull(df_bom_data[df_bom_data.columns.tolist()[1:]]).all(axis=1)]
# df_material_shortage_data表删除all_isnull_df_bom_data表中的Material
df_material_shortage_data = df_material_shortage_data[~df_material_shortage_data['Material'].isin(df_isnull_bom_data['Material'])]
df_bom_data

df_material_shortage_data

df_isnull_bom_data

df_material_shortage_data(处理后)

扩展补充案例:删除列为指定值所在的行
import pandas as pd
df = pd.DataFrame([[0,1,2,3],
[4,5,6,7],
[8,9,10,11]
],columns=['A','B','C','D'])
# 通过重新取值,数据筛选后重新赋值,达到删除列为指定值的行数据
# 删除A列中值为0的那一行记录
df = df[df['A'] != 0]
df

df(处理后)

到此这篇关于Pandas 筛选和删除目标值所在的行的实现的文章就介绍到这了,更多相关Pandas 筛选和删除目标值所在的行内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python Pandas 对列/行进行选择,增加,删除操作
一.列操作 1.1 选择列 d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print (df ['one']) # 选择其中一列进行显示,列长度为最长列的长度 # 除了 index 和 数据,还会显示 列表头名,和 数据 类型 运行结果: a 1.0 b
-

pandas删除指定行详解
在处理pandas的DataFrame中,如果想像excel那样筛选,只要其中的某一行或者几行,可以使用isin()方法来实现,只需要将需要的行值以列表方式传入即可,还可传入字典,进行指定筛选. pandas.DataFrame中删除包涵特定字符串所在的行:https://www.jb51.net/article/159052.htm 以上所述是小编给大家介绍的pandas删除指定行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支
-
如何利用Pandas删除某列指定值所在的行
目录 前言 1.data.dropna() 1-1 axis确定删除存在缺失值的行或者是列 1-2 how 确定存在缺失值时,是否删除行或者列 1-3 thresh=n表示保留至少含有n个非na数值的行 1-4 subset确定要在哪些列中查找缺失值 1-5 inplace确定是否直接在原DataFrame修改 2.data.drop 2-1 labels 指定行或者列的名称 2-2 index 指定要删除的行 2-3 columns 指定要删除的列 3.实例 3-1 统计0的数量 3-2 找出
-
pandas删除行删除列增加行增加列的实现
创建df: >>> df = pd.DataFrame(np.arange(16).reshape(4, 4), columns=list('ABCD'), index=list('1234')) >>> df A B C D 1 0 1 2 3 2 4 5 6 7 3 8 9 10 11 4 12 13 14 15 1,删除行 1.1,drop 通过行名称删除: df = df.drop(['1', '2']) # 不指定axis默认为0 df.drop(['1',
-
Pandas 筛选和删除目标值所在的行的实现
目录 1.筛选出目标值所在行 单列筛选 多列筛选 2.删除目标值所在的行 扩展补充案例:删除列为指定值所在的行 1.筛选出目标值所在行 单列筛选 # df[列名].isin([目标值])对当前列中存在目标值的行会返回True,不存在的返回False df[df[列名].isin([目标值])] 练习案例 import pandas as pd df_bom_data = pd.DataFrame([['A123',1200,5], ['B456',550,2], ['C437',500,10],
-
Pandas筛选DataFrame含有空值的数据行的实现
目录 数据准备 1.筛选指定单列中有空值的数据行 2.筛选指定多列中/全部列中满足所有列有空值的数据行 3.筛选指定多列中/全部列中满足任意一列有空值的数据行 数据准备 import pandas as pd df = pd.DataFrame([['ABC','Good',1], ['FJZ',None,2], ['FOC','Good',None] ],columns=['Site','Remark','Quantity']) df 注意:上述Remark字段中的数据类型为字符串str类型,
-
详解pandas.DataFrame中删除包涵特定字符串所在的行
你在使用pandas处理DataFrame中是否遇到过如下这类问题?我们需要删除某一列所有元素中含有固定字符元素所在的行,比如下面的例子: 以上所述是小编给大家介绍的pandas.DataFrame中删除包涵特定字符串所在的行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
pandas获取groupby分组里最大值所在的行方法
pandas获取groupby分组里最大值所在的行方法 如下面这个DataFrame,按照Mt分组,取出Count最大的那行 import pandas as pd df = pd.DataFrame({'Sp':['a','b','c','d','e','f'], 'Mt':['s1', 's1', 's2','s2','s2','s3'], 'Value':[1,2,3,4,5,6], 'Count':[3,2,5,10,10,6]}) df Count Mt Sp Value 0 3 s1
-
python pandas数据处理之删除特定行与列
目录 dropna() 方法过滤任何含有缺失值的行 方法一:dropna() 其他参数解析 方法二:替换并删除,Python pandas 如果某列值为空,过滤删除所在行数据 总结 dropna() 方法过滤任何含有缺失值的行 pandas.DataFrame里,如果一行数据有任意值为空,则过滤掉整行,这时候使用dropna()方法是合适的.下面的案例,任意列只要有一个为空数据,则整行都干掉.但是我们常常遇到的情况,是根据一个指标(一列)数据的情况,去过滤行数据,类似Excel里面的过滤漏斗,怎
-
python如何删除列为空的行
1.摘要 dropna()方法,能够找到DataFrame类型数据的空值(缺失值),将空值所在的行/列删除后,将新的DataFrame作为返回值返回. 2.函数详解 函数形式:dropna(axis=0, how='any', thresh=None, subset=None, inplace=False) 参数: axis:轴.0或'index',表示按行删除:1或'columns',表示按列删除. how:筛选方式.'any',表示该行/列只要有一个以上的空值,就删除该行/列:'all',表
-
pandas数据清洗实现删除的项目实践
目录 准备工作(导入库.导入数据) 检测数据情况 DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 方式一:删除指定行或列 方式二:利用boolean删除满足条件元素所在的行 准备工作(导入库.导入数据) import pandas as pd import matplotlib.pyplot as plt import numpy as np import seaborn as sns sn
-
在pandas中一次性删除dataframe的多个列方法
之前沉迷于使用index删除,然而发现pandas貌似有bug? import pandas as pd import numpy as np df = pd.DataFrame(np.arange(12).reshape(3,4), columns=['A', 'B', 'C', 'D']) x=[1,2] df.drop(index=[1,2], axis=1, inplace=True) #axis=1,试图指定列,然并卵 print df 输出为 A B C D 0 0 1 2 3 还是
-
pandas创建新Dataframe并添加多行的实例
处理数据的时候,偶然遇到要把一个Dataframe中的某些行添加至一个空白的Dataframe中的问题. 最先想到的方法是创建Dataframe,从原有的Dataframe中逐行筛选出指定的行(类型为pandas的Series),并使用append方法进行添加.这种方法速度很慢,而且添加之后总会出现奇怪的问题,数据类型也不对. 较快的方法为,首先创建空的list,对原有的Dataframe进行逐行筛选,筛选出的行转化为dict类型,append进list中.全部添加完毕后,再将整个list转化为