如何利用python批量提取txt文本中所需文本并写入excel
目录
- 1.提取txt文本
- 2.增加数据框的列
- 3.引入基础csv数据,并扩列
- 汇总
- 总结
1.提取txt文本
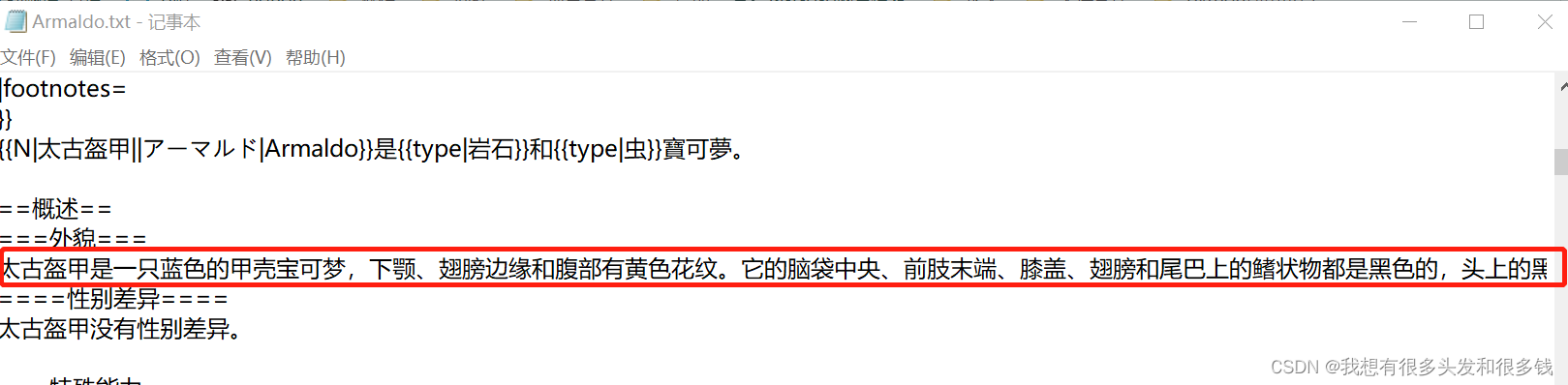
我想要的文本是如图所示,宝可梦的外貌描述文本,由于原本的数据源结构并不是很稳定,而且也不是表格形式,因此在csdn上查了半天。
最原始的一行一行提取(不建议,未采用)
fi = open("D:\python_learning\data\data\Axew.txt","r",encoding="utf-8")
wflag =False #写标记
newline = [] #创建一个新的列表
for line in fi : #按行读入文件,此时line的type是str
if "=" in line: #重置写标记
wflag =False
if "原型剖析" in line: #检验是否到了要写入的内容
wflag = True
continue
if wflag == True:
K = list(line)
if len(K)>1: #去除文本中的空行
for i in K : #写入需要内容
newline.append(i)
strlist = "".join(newline) #合并列表元素
newlines = str(strlist) #list转化成str
print(newlines)
"""
for D in range(1,100): #删掉句中()
newlines = newlines.replace("({})".format(D),"")
for P in range(0,9): #删掉前面数值标题
for O in range(0,9):
for U in range(0, 9):
newlines = newlines.replace("{}.{}{}".format(P,O,U), "")
fo.write(newlines)
fo.close()
fi.close()
"""
源代码为:将提取出的txt文本储存到另外一个txt中,跟我的需求不符合,因此注释掉了
正则表达式提取
由于txt文件打开后不是数据格式,因此先转为列表形式(一行是一个元素);再将列表元素合到一起,转为一个元素。
re.compile函数可以创建正则函数
pattern= re.compile(r’=栖息地=\n(.*?)\n==’, flags=re.DOTALL)
flags=re.DOTALL 这样找寻文本时可以跨行;
’=栖息地=\n(.*?)\n==’ 正则表达式表示只要小括号里面的以‘=栖息地=\n’开头,‘\n==’结尾的所有文本
pattern.findall函数可以在文本中找到符合正则函数的文本,但是莫名其妙会重复好多次,这个问题应该是我哪里写错了,但是因为实在没空纠结这个,所以直接用result=pattern.findall(f2)[0]来提取第一个。
path='D:\\python_learning\\data\\data\\'+df.iloc[0,3]+'.txt'
#为循环做准备
import re
f1=list(open(path,"r",encoding="utf-8"))#列表格式
f2="".join(f1)#合并列表元素
#print(type(f3))
pattern= re.compile(r'===栖息地===\n(.*?)\n==', flags=re.DOTALL)#在所有行里找以‘===栖息地===\n'开头,‘\n=='结尾的所有文本
if len(pattern.findall(f2))==0:#有可能找不到,以防报错
result='none'
else:
result=pattern.findall(f2)[0]
print(result)

2.增加数据框的列
由于我需要在已有数据集上增加上面提取到的文本数据,因此我准备先把csv数据放到Python里变成数据框,再把数据框里扩列,再改内容,再写入新的csv。
参考了代码,这个比较乱,只看第一个import下面就行,我单纯就是留个记录:
#数据框增加列的参考
import pandas as pd
df = pd.DataFrame(columns = list('abcd'),data = [[6,7,8,9],[10,11,12,13]])
#在b列前面增加一个m列
col_name = list(df.columns)
col_name.insert(1,'m')
df.reindex(columns = col_name,fill_value = 12)
#在b列前一次性增加三列h,n,g
col_name = col_name[0:2]+list('hng')+col_name[2:]
df.reindex(columns = col_name,fill_value = 10)
import pandas as pd
df = pd.DataFrame(columns =word,data = [['Bulbasaur',7,8,9],[10,11,12,13]])
print(df)
col_name = list(df.columns)#列名
print(col_name )
#在b列前面增加一个m列
col_name.insert(1,'m')
print(col_name)
df=df.reindex(columns =['name','概述', '外貌', '栖息地', '原型剖析'],fill_value = 12)
print(df)
3.引入基础csv数据,并扩列
是之后循环和写入的基础
import pandas as pd data_name = pd.read_csv(r'D:\python_learning\data\basedata.csv') #print(data_name) word=['概述','外貌','栖息地','原型剖析'] col_name = list(data_name.columns)#列名 col_name = col_name +word#添加新的列名 #print(col_name ) df=data_name.reindex(columns = col_name,fill_value =' ')#在数据框中增加四列,填充空格 print(df) #print(df.iloc[2,2])
我的数据是这样的:

汇总
把上面的放在一起,并且把需要循环的模块写成函数:
# # 引入包
# In[ ]:
import re
import pandas as pd
# # 引入基础数据
# In[135]:
data_name = pd.read_csv(r'D:\python_learning\data\basedata.csv')
#print(data_name)
word=['概述','外貌','栖息地','原型剖析']
col_name = list(data_name.columns)#列名
col_name = col_name +word#添加新的列名
#print(col_name )
df=data_name.reindex(columns = col_name,fill_value =' ')#在数据框中增加四列,填充空格
#print(df)
#print(df.iloc[2,2])
# # 引入函数
# In[ ]:
#去除空行函数
def deletespace(path1,path2):
with open(path1,'r',encoding = 'utf-8') as fr,open(path2,'w',encoding = 'utf-8') as fd:
for text in fr.readlines():
if text.split():
fd.write(text)
print('输出成功....')
fr.close()
fd.close()
# In[143]:
#正则找文本
def find(path,conversion):
f1=list(open(path,"r",encoding="utf-8"))#列表格式
f2="".join(f1)#合并列表元素
#print(type(f3))
pattern= re.compile(conversion, flags=re.DOTALL)#在所有行里找以‘===栖息地===\n'开头,‘\n=='结尾的所有文本
if len(pattern.findall(f2))==0:#有可能找不到,以防报错
result='none'
else:
result=pattern.findall(f2)[0]
return result
# # 起始准备 把所有空行消除,不需要运行第二遍
# In[ ]:
data_name = pd.read_csv(r'D:\python_learning\data\basedata.csv')
for word in df.iloc[:,3]:
path1='D:\\python_learning\\data\\data\\'+word+'.txt'#爬虫获取的数据
path2='D:\\python_learning\\data\\description\\'+word+'.txt'
deletespace(path1,path2)
# # 开始循环
# In[ ]:
word=['概述','外貌','栖息地','原型剖析']#根据文本中情况进行正则
conversion=['==概述==\n(.*?)==','===外貌===\n(.*?)==','===栖息地===\n(.*?)==','==原型剖析==\n(.*?)==']#正则文本
word1=col_name[7]
print(word1)
newlines=seek(path,word1)
print(newlines)
# In[145]:
print(len(df))
print(len(list(df.columns)))
# In[150]:
for i in range(len(df)):
for j in range(6,len(list(df.columns))):
path='D:\\python_learning\\data\\description\\'+df.iloc[i,3]+'.txt'
k=j-6
cword=conversion[k]
result=find(path,cword)
df.iloc[i,j]=result
# In[152]:
df.to_csv('df.csv',encoding ='utf_8_sig')#输出中文必须用这个utf_8_sig 编码才是中文
print("已输出文档")
#出现问题,很多匹配不到,发现是原始文本的原因
总之我文本描述的准备是差不多了。
总结
到此这篇关于如何利用python批量提取txt文本中所需文本并写入excel的文章就介绍到这了,更多相关python批量提取txt文本写入excel内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python批量读取文件名并写入txt文件中
本文实例为大家分享了python批量读取文件名并写入txt中的具体代码,供大家参考,具体内容如下 先说下脚本使用的环境吧,在做项目的过程中需要动态加载图片,使用Unity的Resources.Load方法,但是百十张图片怎么能一 一写下他们的名字作为加载的路径呢?总不能一个一个编辑后存到数组中吧,(虽然我最初是这么做的).所以必须有一个批量的工具,必须的. 于是乎激发了我的灵感,下面看代码.备注少,不动的给我留言,我会及时回复的. #coding=utf-8 import sys import
-

如何利用python批量提取txt文本中所需文本并写入excel
目录 1.提取txt文本 2.增加数据框的列 3.引入基础csv数据,并扩列 汇总 总结 1.提取txt文本 我想要的文本是如图所示,宝可梦的外貌描述文本,由于原本的数据源结构并不是很稳定,而且也不是表格形式,因此在csdn上查了半天. 最原始的一行一行提取(不建议,未采用) fi = open("D:\python_learning\data\data\Axew.txt","r",encoding="utf-8") wflag =False #
-
教你用python提取txt文件中的特定信息并写入Excel
目录 问题描述: 工具: 操作: 源代码: Reference: 总结 问题描述: 我有一个这样的数据集叫test_result_test.txt,大概几百上千行,两行数据之间隔一个空行. N:505904X:0.969wsecY:0.694wsec N:506038X:4.246wsecY:0.884wsec N:450997X:8.472wsecY:0.615wsec ... 现在我希望能提取每一行X:和Y:后面的数字,然后保存进Excel做进一步的数据处理和分析 就拿第一行来说,我只需要0
-
Python批量提取PDF文件中文本的脚本
本文实例为大家分享了Python批量提取PDF文件中文本的具体代码,供大家参考,具体内容如下 首先需要执行命令pip install pdfminer3k来安装处理PDF文件的扩展库. import os import sys import time pdfs = (pdfs for pdfs in os.listdir('.') if pdfs.endswith('.pdf')) for pdf1 in pdfs: pdf = pdf1.replace(' ', '_').replace('-
-
利用Python批量提取Win10锁屏壁纸实战教程
前言 相信使用Win10的朋友会发现,每次开机锁屏界面都会有不一样的漂亮图片,这些图片通常选自优秀的摄影作品,十分精美. 但是由于系统会自动更换这些图片,所以就算再好看的图片,也许下次开机之后就被替换掉了. 借助Python,我们可以用简单的几行代码,批量提取这些精美的锁屏图片.把喜欢的图片设置成桌面背景,就不用担心被替换掉啦. 下面话不多说了,来一起看看详细的介绍吧. 提取原理 Win10系统会自动下载最新的锁屏壁纸,并将他们保存在一个系统文件夹中,路径是C:\Users\[用户名]\AppD
-
利用Python批量识别电子账单数据的方法
一.前言 有一定数量类似如下截图所示的账单,利用 Python 批量识别电子账单数据,并将数据保存到Excel. 百度智能云接口 打开https://cloud.baidu.com/,如未注册请先注册,然后登录点击管理控制台,点击左侧产品服务→人工智能→文字识别,点击创建应用,输入应用名称如Baidu_OCR,选择用途如学习办公,最后进行简单应用描述,即可点击立即创建.会出现应用列表,包括AppID.API Key.Secret Key等信息,这些稍后会用到. 二.调用Baidu aip识别 首
-
教你利用python如何读取txt中的数据
目录 前言 方法一:运用open()函数 方法二:使用numpy包的loadtxt方法 方法三:使用pandas的read_table方法进行读取 总结 前言 当我们在用python时可能会遇到想要把txt文档里的数据读取出来然后进行绘图,那么我们要怎么才能够将txt里的数据读取出来呢? 假设有txt文本如下: 想要把上述文本数据读取出来,可以用以下方法: 方法一:运用open()函数 该方法使用最基本的open函数进行读取,此处将会把数据读取到一个列表中,这个方法一般就是open打开文件.re
-
基于Python正则表达式提取搜索结果中的站点地址
正则表达式对于Python来说并不是独有的,最近在把google搜索的结果中所有的站点地址导出,于是想到用python正则表达式提取搜索结果中的站点地址. 这其中涉及几个需要解决的问题: 1.获取搜索的结果文本 为了获得更多的地址,我使用了Google的高级搜索功能,每个页面显示100条结果. 获得显示的结果后,可以查看源码,并保持成文本文件就有了搜索的结果文本 2.分析如何提取站点信息 首先需要分析获取的页面,查看以怎样的方式可以提取出站点信息. 我使用IE8自带的开发工具(按F12就会弹出来
-
python批量读取txt文件为DataFrame的方法
我们有时候会批量处理同一个文件夹下的文件,并且希望读取到一个文件里面便于我们计算操作.比方我有下图一系列的txt文件,我该如何把它们写入一个txt文件中并且读取为DataFrame格式呢? 首先我们要用到glob模块,这个python内置的模块可以说是非常的好用. glob.glob('*.txt') 得到如下结果: all.txt是我最后得到的结果文件.可以见返回的是一个包含txt文件名称的列表,当然如果你的文件夹下面只有txt文件,那么你用os.listdir()可以得到一个一样的列表 然后
-
利用python批量爬取百度任意类别的图片的实现方法
利用python批量爬取百度任意类别的图片时: (1):设置类别名字. (2):设置类别的数目,即每一类别的的图片数量. (3):编辑一个txt文件,命名为name.txt,在txt文件中输入类别,此类别即为关键字.并将txt文件与python源代码放在同一个目录下. python源代码: # -*- coding: utf-8 -*- """ Created on Sun Sep 13 21:35:34 2020 @author: ydc """
-
python批量提取图片信息并保存的实现
程序运行环境 code # -*- coding:utf-8 -*- # ----------------------------------- # @Time : 2021/2/3 9:23 # @Author : HaoWu # @File : OutPixel.py # ------------------------------------ import sys import os from glob import glob from PIL import Image sys.path.