python实现csdn全部博文下载并转PDF
我们学习编程,在学习的时候,会有想把有用的知识点保存下来,我们可以把知识点的内容爬下来转变成pdf格式,方便我们拿手机可以闲时翻看,是很方便的
先来一个单个的博文下载转pdf格式的操作

python中将html转化为pdf的常用工具是Wkhtmltopdf工具包,在python环境下,pdfkit是这个工具包的封装类。如何使用pdfkit以及如何配置呢?分如下几个步骤。
下载wkhtmltopdf安装包,并且安装到电脑上。
下载地址:https://wkhtmltopdf.org/downloads.html

我下的是这个版本,安装的时候要记住路径,之后调用要用到路径

开发工具
- python
- pycharm
- pdfkit (pip install pdfkit)
- lxml
今天目标:博主的全部博文下载,并且转pdf格式保存
基本思路:
1、url + headers
2、分析网页: CSDN网页是静态网页, 请求获取网页源代码
3、lxml解析获取boke_urls, author_name
4、循环遍历,得到 boke_url
5、xpath解析获取文件名
6、css选择器获取标签文本的主体
7、构造拼接html文件
8、保存html文件
9、文件的转换
分析网页: CSDN网页是静态网页, 请求获取网页源代码
start_url =“https://i1bit.blog.csdn.net/” 为例
确定网址为同步加载
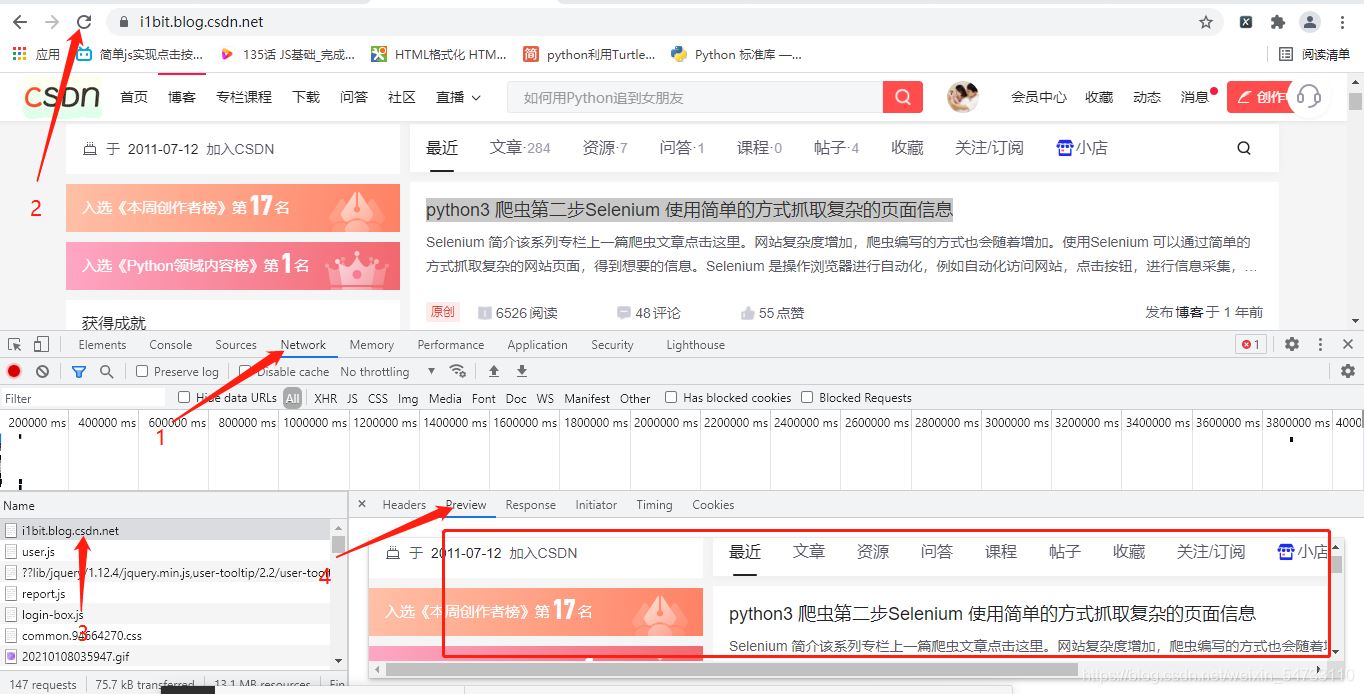
css选择器获取标签文本的主体为代码要点部分
css语法部分
# css选择器获取标签文本的主体
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 构造拼接html文件
html = \
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_content)
点开博主的一篇博文打开开发者工具

# css选择器获取标签文本的主体
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 构造拼接html文件
html = \
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_content)
文件的转换
config = pdfkit.configuration(wkhtmltopdf=r'这里为下载wkhtmltopdf.exe的路径')
pdfkit.from_file(
第一个参数要转变的html文件,
第二个参数转变后的pdf文件,
configuration=config
)
# 上面这样写清楚一点,也可以直接
pdfkit.from_file(
第一个参数要转变的html文件,
第二个参数转变后的pdf文件,
configuration=pdfkit.configuration(wkhtmltopdf=r'这里为下载wkhtmltopdf.exe的路径')
)
源码展示:
import parsel, os, pdfkit
from lxml import etree
from requests_html import HTMLSession
session = HTMLSession()
def main():
# 1、url + headers
start_url = input(r'请输入csdn博主的地址:')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36'
}
# 2、分析网页: CSDN网页是静态网页, 请求获取网页源代码
response_1 = session.get(start_url, headers=headers).text
# 3、解析获取boke_urls, author_name
html_xpath_1 = etree.HTML(response_1)
author_name = html_xpath_1.xpath(r'//*[@id="floor-user-profile_485"]/div/div[1]/div[2]/div[2]/div[1]/div[1]/text()')[0]
boke_urls = html_xpath_1.xpath(r'//article[@class="blog-list-box"]/a/@href')
# 4、循环遍历,得到 boke_url
for boke_url in boke_urls:
# 5、请求
response_2 = session.get(boke_url, headers=headers).text
# 6、xpath解析获取文件名
html_xpath_2 = etree.HTML(response_2)
file_name = html_xpath_2.xpath(r'//h1[@id="articleContentId"]/text()')[0]
# 7、css选择器获取标签文本的主体
html_css = parsel.Selector(response_2)
html_content = html_css.css('article').get()
# 8、构造拼接html文件
html = \
'''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
{}
</body>
</html>
'''.format(html_content)
# 9、创建两个文件夹, 一个用来保存html 一个用来保存pdf文件
if not os.path.exists(r'{}-html'.format(author_name)):
os.mkdir(r'{}-html'.format(author_name))
if not os.path.exists(r'{}-pdf'.format(author_name)):
os.mkdir(r'{}-pdf'.format(author_name))
# 10、保存html文件
try:
with open(r'{}-html/{}.html'.format(author_name, file_name), 'w', encoding='utf-8') as f:
f.write(html)
except Exception as e:
print('文件名错误')
# 11、文件的转换
try:
config = pdfkit.configuration(wkhtmltopdf=r'C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')
pdfkit.from_file(
'{}-html/{}.html'.format(author_name, file_name),
'{}-pdf/{}.pdf'.format(author_name, file_name),
configuration=config
)
a = print(r'--文件下载成功:{}.pdf'.format(file_name))
except Exception as e:
continue
if __name__ == '__main__':
main()
代码操作:

到此这篇关于python实现csdn全部博文下载并转PDF的文章就介绍到这了,更多相关python 博文下载并转PDF内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 三种方法提取pdf中的图片
有时我们需要将一份或者多份PDF文件中的图片提取出来,如果采取在线的网站实现的话又担心图片泄漏,手动操作又觉得麻烦,其实用Python也可以轻松搞定! 今天就跟大家系统分享几种Python提取 PDF 图片的方法.其实没有非常完美的方法,每种方法提取效率都不是百分之百,因此可以考虑用多种方法进行互补,主要将涉及: 基于 fitz 库和正则搜索提取图片 基于 pdf2image 库的两种方法提取图片 基于 fitz 库和正则搜索 fitz 是 pymupdf 的子模块,需要先用命令行安装 pymu
-
Python提取PDF指定内容并生成新文件
在之前的Python办公自动化案专题中,我们已经介绍了如何有选择的提取某些页面进行合并. 但是很多时候,我们并不会预知希望提取的页号,而是希望将包含指定内容的页面提取合并为新PDF,本文就以两个真实需求为例进行讲解. 01需求描述 数据是一份有286页的上市公司公开年报PDF,大致如下 现在需要利用 Python 完成以下两个需求 " 需求一:提取所有包含 战略 二字的页面并合并新PDF 需求二:提取所有包含图片的页面,并分别保存为 PDF 文件 " 02前置知识和逻辑梳理 2.1 P
-
python解析PDF程序代码
说在前面 和word的文本相比PDF更类似于一张张图片,图上放着一个个文字.对其的解析是将图片上的文字提取到text文件中,方便之后的分析. 添加依赖 在python的环境中安装PDFminer3k,不要装错了,一开始我装的是PDFminer,结果有几个包不能用 pip install pdfminer3k 源程序代码 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # pip3 install pdfminer3k import os from pd
-
Python实现给PDF添加水印的方法
前言 利用 PyPDF2 处理 PDF 文件,相关文档:https://pythonhosted.org/PyPDF2/ 本文针对 仅有 PDF 文件,而无相关 PDF 编辑器的情况下,给 PDF 添加水印. 一.前期准备 安装 PyPDF2 ,命令提示框输入: pip install PyPDF2 新建 watermark.pdf 文件 实际的水印,可以在此文件里修改水印文字的字体和位置. 实现步骤: 新建 watermark.word ,[设计] → \to → [水印][自定义水印] →
-
Python 多张图片合并成一个pdf的参考示例
过程 拿到一个需求最重要的就是将大块任务拆分成一个个小模块,逐个击破. 拍照 这一步首先是将所有的书页拍好,需要注意的是要按照书的页码来拍,因为后面的排序是按照文件名进行排序的,拍照的文件名基本上是按照时间生成的,如果拍的时候乱了,到时候生成的 pdf 里面的页码也会乱掉. 用到的Python 操作库 Python 最好的地方就是有大量的第三方库能帮我们快速实现我们想要的方法,搜索到了两个库, PyFPDF 和img2pdf,我们这里选择img2pdf来完成我们的需求 pip install i
-
python操作mysql、excel、pdf的示例
一.学习如何定义一个对象 代码: #!/usr/bin/python # -*- coding: UTF-8 -*- # 1. 定义Person类 class Person: def __init__(self, name, age): self.name = name self.age = age def watch_tv(self): print(f'{self.name} 看电视') # 2. 定义loop函数 # 打印 1-max 中的奇数 def test_person(): pers
-
详解用Python把PDF转为Word方法总结
先讲一下为啥要写这个文章,网上其实很多这种PDF转化的代码和软件.我一直想用Python做,但是网上搜到的代码很多都不能用,很多是2.7版本的代码,再就是PDF需要用到的库在导入的时候,很多的报错,解决起来特别费劲,而且自从2021年初以来,似乎网上很少有关PDF转化的代码出现了.我在研究了很多代码和pdfminer的用法后,总结了几个方法,目前这几种方法可以解决大多数格式的转化,后面我也专门放了提取PDF表格的代码,文末有高效的免费在线工具推荐. 下面这个是我最最推荐的方法 ,简单高效 ,只要
-
python pdfkit 中文乱码问题的解决方案
使用python pdfkit生成pdf文件中遇到中文乱码问题 1.生成的文件名不能带有中文字符 2.生成的pdf内容中文为乱码 生成的文件名不能带有中文字符 解决方法: 我暂时想到的处理方式是先生成英文文件名,再将这个文件重命名为中文的文件名 #coding=utf8 import os import pdfkit from uuid import uuid1 ret = '<html><head><meta charset="UTF-8"><
-
Python合并多张图片成PDF
前言 最近需要将记的笔记整理成一个 pdf 进行保存,所以就研究了一下如何利用 Python 代码将拍下来的照片整个合并成一个 pdf 过程 拿到一个需求最重要的就是将大块任务拆分成一个个小模块,逐个击破. 拍照 这一步首先是将所有的书页拍好,需要注意的是要按照书的页码来拍,因为后面的排序是按照文件名进行排序的,拍照的文件名基本上是按照时间生成的,如果拍的时候乱了,到时候生成的 pdf 里面的页码也会乱掉. 用到的Python 操作库 Python 最好的地方就是有大量的第三方库能帮我们快速实现
-
Python读取pdf表格写入excel的方法
背景 今天突然想到之前被要求做同性质银行的数据分析.妈耶!十几个银行,每个银行近5年的财务数据,而且财务报表一般都是 pdf 的,我们将 pdf 中表的数据一个个的拷贝到 excel 中,再借助 excel 去进行求和求平均等聚合函数操作,完事了还得把求出来的结果再统一 CV 到另一张表中,进行可视化分析- 当然,那时风流倜傥的 老Amy 还熟练的玩转着 excel ,也是个秀儿~ 今天就思索着,如果当年我会 Python 是不是可以让我成为班级最靓的崽!用技术占领高地,HHH,所以今天我来了,