Python数据结构之图的存储结构详解
一、图的定义
图是一种比树更复杂的一种数据结构,在图结构中,结点之间的关系是任意的,任意两个元素之间都可能相关,因此,它的应用极广。图中的数据元素通常被称为顶点 ( V e r t e x ) (Vertex) (Vertex), V V V是顶点的有穷非空集合, V R VR VR是两个顶点之间的关系的集合(可以为空),可以表示为图 G = { V , { V R } } G=\{V,\{VR\}\} G={V,{VR}}。
二、相关术语
2.1 无向图
给定图 G = { V , { E } } G=\{V,\{E\}\} G={V,{E}},若该图中每条边都是没有方向的,则称其为无向图 ( U n d i g r a p h ) (Undigraph) (Undigraph)。对图 G G G中顶点 v v v和顶点 w w w的关系,可用无序对 ( v , w ) (v,w) (v,w)表示,它是连接 v v v和 w w w的一条边 ( E d g e ) (Edge) (Edge)。
2.2 有向图
给定图 G = { V , { A } } G=\{V,\{A\}\} G={V,{A}},若该图中每条边都是有方向的,则称其为有向图 ( D i g r a p h ) (Digraph) (Digraph)。对图 G G G中顶点 v v v和顶点 w w w的关系,可用有序对 < v , w > <v,w> <v,w>表示,它是从 v v v到 w w w的一条弧 ( A r c ) (Arc) (Arc),其中 v v v被称为弧尾 ( T a i l ) (Tail) (Tail), w w w被称为弧头 ( H e a d ) (Head) (Head)。
弧尾也叫初始点 ( I n i t i a l (Initial (Initial N o d e ) Node) Node),弧头也叫终端点 ( T e r m i n a l (Terminal (Terminal N o d e ) Node) Node)。
2.3 完全图
对于任一无向图,若其顶点的总数目为 n n n,边的总数目为 e = n ( n − 1 ) 2 e=\frac {n(n-1)} {2} e=2n(n−1),则称其为完全图 ( C o m p l e t e d (Completed (Completed G r a p h ) Graph) Graph)。
2.4 有向完全图
对于任一有向图,若其顶点的总数目为 n n n,边的总数目为 e = n ( n − 1 ) e=n(n-1) e=n(n−1),则称其为有向完全图。
2.5 稀疏图和稠密图
对于具有 n n n个顶点, e e e条边或弧的图来说,若 e e e很小,比如 e < n log n e<n\log n e<nlogn,则称其为稀疏图 ( S p a r s e (Sparse (Sparse G r a p h ) Graph) Graph),反之称其为稠密图 ( D e n s e (Dense (Dense G r a p h ) Graph) Graph)。
2.6 权和网
赋予图中边或弧的数值称为权 ( W e i g h t ) (Weight) (Weight),它可以表示从一个顶点到另一个顶点的距离;带权的图称为网 ( N e t w o r k ) (Network) (Network)。
2.7 稀疏网和稠密网
带权的稀疏图、稠密图称为稀疏网、稠密网。
2.8 子图
对于图 G = { V , { E } } G=\{V,\{E\}\} G={V,{E}}和图 G ′ = { V ′ , { E ′ } } G'=\{V',\{E'\}\} G′={V′,{E′}},若 V ′ ⊆ V V'\subseteq V V′⊆V且 E ′ ⊆ E E'\subseteq E E′⊆E,则称 G ′ G' G′为 G G G的子图 ( S u b g r a p h ) (Subgraph) (Subgraph)。
2.9 邻接点
对于无向图 G = { V , { E } } G=\{V,\{E\}\} G={V,{E}},若 v ∈ V v\in V v∈V、 w ∈ V w\in V w∈V且 ( v , w ) ∈ E (v,w)\in E (v,w)∈E,则称顶点 v v v和顶点 w w w互为邻接点 ( A d j a c e n t ) (Adjacent) (Adjacent),并称边 ( v , w ) (v,w) (v,w)依附 ( I n c i d e n t ) (Incident) (Incident)于顶点 v v v和顶点 w w w,或称边 ( v , w ) (v,w) (v,w)与顶点 v v v和顶点 w w w相关联。
对于有向图 G = { V , { A } } G=\{V,\{A\}\} G={V,{A}},若 v ∈ V v\in V v∈V、 w ∈ V w\in V w∈V且 < v , w > ∈ A <v,w>\in A <v,w>∈A,则称顶点 v v v邻接到顶点 w w w,顶点 w w w邻接自顶点 v v v,并称弧 < v , w > <v,w> <v,w>与顶点 v v v和顶点 w w w相关联。
2.10 度、入度与出度
在无向图中,顶点 v v v的度 ( D e g r e e ) (Degree) (Degree)等于与该顶点相关联的边的数目,记为 T D ( v ) TD(v) TD(v)。
在有向图中,顶点 v v v的度等于该顶点的入度与出度之和,记为 T D ( v ) = I D ( v ) + O D ( v ) TD(v)=ID(v)+OD(v) TD(v)=ID(v)+OD(v),其中顶点 v v v的入度 ( I n D e g r e e ) (InDegree) (InDegree)为以该顶点为弧头的弧的数目,记为 I D ( v ) ID(v) ID(v),顶点 v v v的出度 ( O u t D e g r e e ) (OutDegree) (OutDegree)为以该顶点为弧尾的弧的数目,记为 O D ( v ) OD(v) OD(v)。
2.11 路径、简单路径与路径长度
路径 ( P a t h ) (Path) (Path)是任意两个有关联的顶点之间的边或弧,在图 G = { V , { V R } } G=\{V,\{VR\}\} G={V,{VR}}中,顶点 v 1 v_1 v1到顶点 v n v_n vn的路径是一个顶点序列 ( v 1 , v 2 , … , v i , v j , … , v n ) (v_1,v_2,\dots,v_i,v_j,\dots,v_n) (v1,v2,…,vi,vj,…,vn),对于上述序列中的任意相邻的顶点 v i v_i vi和 v j v_j vj,若图 G G G是无向图,则有 ( v , w ) ∈ E (v,w)\in E (v,w)∈E,若图 G G G是有向图,则有 < v , w > ∈ A <v,w>\in A <v,w>∈A。
对于给定的一条路径,若该路径对应的序列中的顶点不重复,则称为该路径为简单路径。
路径上边或弧的数目称为路径长度。
2.12 回路与简单回路
若某一路径中的第一个顶点和最后一个顶点相同,则称该路径为回路,也称为环 ( C y c l e ) (Cycle) (Cycle)。
在某一回路中,若除去第一个顶点和最后一个顶点外,其余顶点均不重复,则称为该回路为简单回路,也称为简单环。
2.13 连通图与连通分量
在无向图中,若从顶点 v v v到顶点 w w w有路径,则称为 v v v到 w w w是连通的,若该图中的任意两个顶点间都是连通的,则称该图为连通图 ( C o n n e c t e d (Connected (Connected G r a p h ) Graph) Graph)。无向图中的极大连通子图称为连通分量 ( C o n n e c t e d (Connected (Connected C o m p o n e n t ) Component) Component)。这里的极大就是尽可能地包含更多的顶点。
2.14 强连通图与强连通分量
在有向图中,若从顶点 v v v到顶点 w w w有路径,从顶点 w w w到顶点 v v v也有路径,则称为 v v v和 w w w是强连通的,若该图中的任意两个顶点间都是强连通的,则称该图为强连通图。有向图中的极大连通子图称为强连通分量。
2.15 生成树、最小生成树与生成森林
具有 n n n个顶点的连通图的极小连通子图称为生成树,生成树包含这一连通图的 n n n个顶点和 n − 1 n-1 n−1条边。这里的极小是尽可能少地包含边。
通常把各边带权的连通图称为连通网,在连通网的所有生成树中,对每一棵生成树的各边权值求和,其中权值最小的生成树称为该连通网的最小生成树。
非连通图的各连通分量的生成树组成的森林称为生成森林。
3. 图的性质
3.1 性质1
若图中有 n n n个顶点 v 1 , v 2 , … , v n v_1,v_2,\dots,v_n v1,v2,…,vn, e e e条边或弧,其中顶点的度分别为 T D ( v 1 ) , T D ( v 2 ) , … , T D ( v n ) TD(v_1),TD(v_2),\dots,TD(v_n) TD(v1),TD(v2),…,TD(vn),则有
e = 1 2 ∑ i = 1 n T D ( v i ) e=\frac {1} {2} \sum_{i=1} ^ {n} TD(v_i) e=21i=1∑nTD(vi)
3.2 性质2
一棵有 n n n个顶点的生成树有且仅有 n − 1 n-1 n−1条边。
4. 图的存储结构
4.1 邻接矩阵
用于无向图、有向图
在存储含有 n n n个结点的图 G = { V , { V R } } G=\{V,\{VR\}\} G={V,{VR}}时,将图中的所有顶点存储在长度为 n n n的一维数组中,将图中边或弧的信息存储在 n × n n\times n n×n的二维数组中,我们称这个二维的数组为邻接矩阵。假设图 G G G中顶点 v v v和顶点 w w w在一维数组中的下标分别为 i i i、 j j j,则该图对应各邻接矩阵定义如下:
若该图为无向图或有向图,则
A r c s [ j ] [ j ] = { 1 , ( v , w ) ∈ E 或 < v , w > ∈ A 0 , 其 他 Arcs[j][j]=\begin{cases} 1, & (v,w)\in E或<v,w>\in A\\ \\ 0, & 其他 \end{cases} Arcs[j][j]=⎩⎪⎨⎪⎧1,0,(v,w)∈E或<v,w>∈A其他 若该图为无向网或有向网,则
A r c s [ j ] [ j ] = { w i j , ( v , w ) ∈ E 或 < v , w > ∈ A ∞ , 其 他 Arcs[j][j]=\begin{cases} w_{ij}, & (v,w)\in E或<v,w>\in A\\ \\ \infty, & 其他 \end{cases} Arcs[j][j]=⎩⎪⎨⎪⎧wij,∞,(v,w)∈E或<v,w>∈A其他 其中, w i j w_{ij} wij为边或弧对应的权值。
定义图中的顶点:
class VertexMatrix(object):
"""
图的一个顶点
"""
def __init__(self, data):
self.data = data
self.info = None
定义图:
class GraphMatrix(object):
"""
图的邻接矩阵
"""
def __init__(self, kind):
# 图的类型: 无向图, 有向图, 无向网, 有向网
# kind: Undigraph, Digraph, Undinetwork, Dinetwork,
self.kind = kind
# 顶点表
self.vertexs = []
# 边表, 即邻接矩阵, 是个二维的
self.arcs = []
# 当前顶点数
self.vexnum = 0
# 当前边(弧)数
self.arcnum = 0
无向图及其邻接矩阵、有向网及其邻接矩阵如下:
A r c s = [ 0 1 0 1 1 0 0 1 0 0 0 1 1 1 1 0 ] A r c s = [ ∞ 1 2 ∞ ∞ ∞ 3 ∞ ∞ ∞ ∞ 4 ∞ ∞ ∞ ∞ ] Arcs=\begin{bmatrix} 0 & 1 & 0 & 1 \\ 1 & 0 & 0 & 1 \\ 0 & 0 & 0 & 1 \\ 1 & 1 & 1 & 0 \end{bmatrix} Arcs=\begin{bmatrix} \infty & 1 & 2 & \infty \\ \infty & \infty & 3 & \infty \\ \infty & \infty & \infty & 4 \\ \infty & \infty & \infty & \infty \end{bmatrix} Arcs=⎣⎢⎢⎡0101100100011110⎦⎥⎥⎤Arcs=⎣⎢⎢⎡∞∞∞∞1∞∞∞23∞∞∞∞4∞⎦⎥⎥⎤

邻接矩阵的特点如下:
(1) 由于在创建邻接矩阵时,输入顶点的顺序不同,其相应的邻接矩阵也是不同的;
(2) 对于含有 n n n个顶点的图,其邻接矩阵一定是 n × n n\times n n×n的二维数组;
(3) 无向图的邻接矩阵具有对称性,可采用压缩存储的方式存储;
(4) 对于无向图,若某一顶点 v v v在一维数组中的下标为 i i i,则该顶点的度为邻接矩阵的第 i + 1 i+1 i+1行中值为1的元素的总数目;
(5) 对于有向图,若某一顶点 v v v在一维数组中的下标为 i i i,则该顶点的出度为邻接矩阵的第 i + 1 i+1 i+1行中值为1的元素的总数目,入度为邻接矩阵的第 i + 1 i+1 i+1列中值为1的元素的总数目。
构造一个具有 n n n个顶点 e e e条边的无向网的时间复杂度为 O ( n 2 + n e ) O(n^2+ne) O(n2+ne),其中对邻接矩阵的初始化使用了 O ( n 2 ) O(n^2) O(n2)的时间。
4.2 邻接表
用于无向图、有向图
使用邻接表存储图时,将图分为两个部分:
第一部分为图中每一个顶点及与该顶点相关联的第一条边或弧,可以这样定义:
class VertexAdjacencyList(object):
"""
图的一个顶点
"""
def __init__(self, data):
self.data = data
# 与该顶点相连的第一条边FirstArc
self.FirstArc = None
使用data域来存储图中的每一个顶点,FirstArc域来存储与该顶点相关联的第一条弧或边,通常情况下指向第二部分单链表的第一个结点。
第二部分为用一个结点来存储图中的每一条边或弧,该结点由adjacent域、info域和NextArc域组成,这些结点形成了单链表。这部分结点可以这样定义:
class ArcAdjacencyList(object):
"""
图的一个边(弧)
"""
def __init__(self, adjacent):
# 邻接点或弧头, 与该顶点相连的另一顶点的index
self.adjacent = adjacent
self.info = None
# 与该边(弧)依附于相同顶点的下一条边(弧)NextArc
self.NextArc = None
根据上面图的邻接表可以这样定义:
class GraphAdjacencyList(object):
"""
图的邻接表
"""
def __init__(self, kind):
# 图的类型: 无向图, 有向图, 无向网, 有向网
# kind: Undigraph, Digraph, Undinetwork, Dinetwork,
self.kind = kind
# 邻接表
self.vertices = []
# 当前顶点数
self.vexnum = 0
# 当前边(弧)数
self.arcnum = 0
无向图及其邻接表:


有向网及其邻接表、逆邻接表:
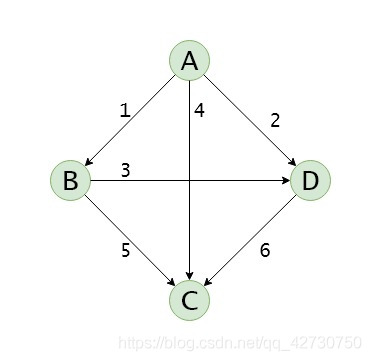


邻接表的特点如下:
(1) 由于存储边或弧通过不同的连接顺序会形成不同的单链表,所以图的邻接表不是唯一的;
(2) 对于具有 e e e条边的无向图,使用邻接表存储时需要 2 e 2e 2e个结点来存储图的边,而对于具有 e e e条弧的有向图,使用邻接表存储时需要 e e e个结点来存储图的弧;
(3) 对于具有 n n n个顶点 e e e条边或弧的稀疏图而言,若采用邻接矩阵存储,则需要 n 2 n^2 n2个存储空间来存储图的边或弧,而采用邻接表存储时,则至多需要 2 e 2e 2e个结点存储图的边或弧,所以稀疏图的存储使用邻接表会更节省空间;
(4) 对于无向图,顶点的度等于该顶点对应的单链表中结点的总数目;
(5) 对于有向图,若某一顶点在数组中的下标为 i i i,则该顶点的出度为该顶点对应的单链表中结点的总数目,入度为邻接表中adjacent域内值为 i i i的结点的总数目。
在使用邻接表存储图时,计算图中的某一顶点的出度很容易,但是在计算其入度时,最坏的情况需要遍历整个邻接表。因此,有时为了方便计算顶点的入度,可以为该图建立一个逆邻接表。
在建立邻接表或逆邻接表时,如输入的顶点信息为顶点的编号,则建立邻接表或逆邻接表的时间复杂度为 O ( n + e ) O(n+e) O(n+e),否则,需要通过查找才能确定顶点在图中的位置,对应的时间复杂度为 O ( n e ) O(ne) O(ne)。
4.3 十字链表
用于有向图
十字链表通常用于有向图,可以将它看成邻接表和逆邻接表的结合。同样分为两个部分,即顶点结点部分和弧部分,通常将顶结点存储在数组中,弧结点存储在单链表中。
顶点结点包含data域、FirstIn域和FirstOut域,其中data域存储顶点的值,FirstIn域指向以当前顶点为弧头的第
一条弧和FirstOut域指向以当前顶点为弧尾的第一条弧。
弧结点包含TailVertex域、HeadVertex域、HeadLink域、TailLink域和info域,其中TailVertex域存储当前弧的弧尾在数组中的下标,HeadVertex域存储当前弧的弧头在数组中的下标,HeadLink域指向与当前弧有相同弧头的下一条弧,TailLink域指向与当前弧有相同弧尾的下一条弧,info域存储当前弧的其他信息。
顶点结点定义如下:
class VertexOrthogonalList(object):
"""
有向图的一个顶点
"""
def __init__(self, data):
self.data = data
# 以该顶点为弧头的第一条弧FirstIn
self.FirstIn= None
# 以该顶点为弧尾的第一条弧FirstOut
self.FirstOut= None
弧结点定义如下:
class ArcOrthogonalList(object):
"""
有向图的一条弧
"""
def __init__(self):
# 当前弧中弧头在数组中的下标HeadVertex
self.HeadVertex = None
# 当前弧中弧尾在数组中的下标TailVertex
self.TailVertex = None
# 与当前弧有相同弧头的下一条弧HeadLink
self.HeadLink = None
# 与当前弧有相同弧尾的下一条弧TailLink
self.TailLink = None
self.info = None
十字链表表示的有向图定义如下:
class GraphOrthogonalList(object):
"""
有向图的十字链表
"""
def __init__(self):
# 十字链表
self.vertices = []
# 当前顶点数
self.vexnum = 0
# 当前边(弧)数
self.arcnum = 0
有向图及其十字链表:


4.4 邻接多重表
用于无向图
在使用邻接表存储无向图时,图的每一条边都对应两个结点,由于这两个结点属于两个不同的邻接表,所以在进行删除操作时需要对邻接表的两条单链表进行操作,比较麻烦,所有引出了邻接多重表。邻接多重表同样分为两个部分,即顶点结点和边结点,通常将顶点结点存储在数组中,边结点存储在单链表中。
顶点结点包含data域和FirstEdge域,其中data域存储顶点的值,FirstEdge域指向与当前顶点相关联的第一条边。
边结点包含mark域、VertexOne域、NextEdgeOne域、VertexTwo域、NextEdgeTwo域和info域,其中mark域用于标记当前是否被访问,VertexOne域和VertexTwo域分别存储当前边的两个顶点在数组中的下标,NextEdgeOne域指向与VertexOne域对应的顶点相关联的下一条边,NextEdgeTwo域指向与VertexTwo域对应的顶点相关联的下一条边,info域存储当前边的其他信息。
顶点结点定义如下:
class VertexAdjacencyMultitable(object):
"""
无向图的一个顶点
"""
def __init__(self, data):
self.data = data
# 与该顶点相连的第一条边FirstEdge
self.FirstEdge = None
边结点定义如下:
class Edge(object):
"""
无向图的邻接多重表
"""
def __init__(self):
# 用来标记当前边是否已被访问过
self.mark = None
# 该边的两个顶点在数组中的下标
self.VertexOne = None
self.VertexTwo = None
# 与VertexOne对应的顶点相连的下一条边NextEdgeOne
self.NextEdgeOne = None
# 与VertexTwo对应的顶点相连的下一条边NextEdgeTwo
self.NextEdgeTwo = None
self.info = None
多重邻接表表示的图定义如下:
class GraphAdjacencyMultitable(object):
"""
无向图的邻接多重表
"""
def __init__(self):
self.vertices = []
self.vertexnum = 0
self.edgenum = 0
无向图及其邻接多重链表:


到此这篇关于P-ython数据结构之图的存储结构详解的文章就介绍到这了,更多相关P-ython图的存储结构内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python数据结构与算法之图的最短路径(Dijkstra算法)完整实例
本文实例讲述了Python数据结构与算法之图的最短路径(Dijkstra算法).分享给大家供大家参考,具体如下: # coding:utf-8 # Dijkstra算法--通过边实现松弛 # 指定一个点到其他各顶点的路径--单源最短路径 # 初始化图参数 G = {1:{1:0, 2:1, 3:12}, 2:{2:0, 3:9, 4:3}, 3:{3:0, 5:5}, 4:{3:4, 4:0, 5:13, 6:15}, 5:{5:0, 6:4}, 6:{6:0}} # 每次找到离源点最近的一个顶
-
Python数据结构与算法之图的广度优先与深度优先搜索算法示例
本文实例讲述了Python数据结构与算法之图的广度优先与深度优先搜索算法.分享给大家供大家参考,具体如下: 根据维基百科的伪代码实现: 广度优先BFS: 使用队列,集合 标记初始结点已被发现,放入队列 每次循环从队列弹出一个结点 将该节点的所有相连结点放入队列,并标记已被发现 通过队列,将迷宫路口所有的门打开,从一个门进去继续打开里面的门,然后返回前一个门处 """ procedure BFS(G,v) is let Q be a queue Q.enqueue(v) lab
-
python数据结构之图的实现方法
本文实例讲述了python数据结构之图的实现方法.分享给大家供大家参考.具体如下: 下面简要的介绍下: 比如有这么一张图: A -> B A -> C B -> C B -> D C -> D D -> C E -> F F -> C 可以用字典和列表来构建 graph = {'A': ['B', 'C'], 'B': ['C', 'D'], 'C': ['D'], 'D': ['C'], 'E': [
-

Python数据结构与算法之图结构(Graph)实例分析
本文实例讲述了Python数据结构与算法之图结构(Graph).分享给大家供大家参考,具体如下: 图结构(Graph)--算法学中最强大的框架之一.树结构只是图的一种特殊情况. 如果我们可将自己的工作诠释成一个图问题的话,那么该问题至少已经接近解决方案了.而我们我们的问题实例可以用树结构(tree)来诠释,那么我们基本上已经拥有了一个真正有效的解决方案了. 邻接表及加权邻接字典 对于图结构的实现来说,最直观的方式之一就是使用邻接列表.基本上就是针对每个节点设置一个邻接列表.下面我们来实现一个最简
-
Python数据结构之图的存储结构详解
一.图的定义 图是一种比树更复杂的一种数据结构,在图结构中,结点之间的关系是任意的,任意两个元素之间都可能相关,因此,它的应用极广.图中的数据元素通常被称为顶点 ( V e r t e x ) (Vertex) (Vertex), V V V是顶点的有穷非空集合, V R VR VR是两个顶点之间的关系的集合(可以为空),可以表示为图 G = { V , { V R } } G=\{V,\{VR\}\} G={V,{VR}}. 二.相关术语 2.1 无向图 给定图 G = { V , { E }
-
C语言数据结构之图的遍历实例详解
C语言数据结构之图的遍历实例详解 输入一组顶点,建立无向图的邻接矩阵.输入一组顶点,建立有向图的邻接表.分别对无向图和有向图进行DFS(深度优先遍历)和BFS(广度优先遍历).写出深度优先遍历的递归和非递归算法.根据建立的有向图,判断该图是否是有向无环图,若是,则输出其一种拓扑有序序列. 实现代码: #include <stdio.h> #include <stdlib.h> #define MAX 20 typedef struct ArcNode{ int adjvex; st
-
Python数据结构与算法之跳表详解
目录 0. 学习目标 1. 跳表的基本概念 1.1 跳表介绍 1.2 跳表的性能 1.3 跳表与普通链表的异同 2. 跳表的实现 2.1 跳表结点类 2.2 跳表的初始化 2.3 获取跳表长度 2.4 读取指定位置元素 2.5 查找指定元素 2.6 在跳表中插入新元素 2.7 删除跳表中指定元素 2.8 其它一些有用的操作 3. 跳表应用 3.1 跳表应用示例 0. 学习目标 在诸如单链表.双线链表等普通链表中,查找.插入和删除操作由于必须从头结点遍历链表才能找到相关链表,因此时间复杂度均为O(
-
Python数据结构之优先级队列queue用法详解
一.基本用法 Queue类实现了一个基本的先进先出容器.使用put()将元素增加到这个序列的一端,使用get()从另一端删除.具体代码如下所示: import queue q = queue.Queue() for i in range(1, 10): q.put(i) while not q.empty(): print(q.get(), end=" ") 运行之后,效果如下: 这里我们依次添加1到10到队列中,因为先进先出,所以出来的顺序也与添加的顺序相同. 二.LIFO队列 既然
-
Python数据结构与算法中的栈详解
目录 0.学习目标 1.栈的基本概念 1.1栈的基本概念 1.2栈抽象数据类型 1.3栈的应用场景 2.栈的实现 2.1顺序栈的实现 2.1.1栈的初始化 2.1.2求栈长 2.1.3判栈空 2.1.4判栈满 2.1.5入栈 2.1.6出栈 2.1.7求栈顶元素 2.2链栈的实现 2.2.1栈结点 2.2.2栈的初始化 2.2.3求栈长 2.2.4判栈空 2.2.5入栈 2.2.6出栈 2.3栈的不同实现对比 3.栈应用 3.1顺序栈的应用 3.2链栈的应用 3.3利用栈基本操作实现复杂算法 总
-
python数据结构之列表和元组的详解
python数据结构之 列表和元组 序列:序列是一种数据结构,它包含的元素都进行了编号(从0开始).典型的序列包括列表.字符串和元组.其中,列表是可变的(可以进行修改),而元组和字符串是不可变的(一旦创建了就是固定的).序列中包含6种内建的序列,包括列表.元组.字符串.Unicode字符串.buffer对象.xrange对象. 列表的声明: mylist = [] 2.列表的操作: (1) 序列的分片: 用法:mylist[startIndex:endIndex:step] exam: myli
-
Mysql InnoDB引擎的索引与存储结构详解
前言 在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的. 而MySql数据库提供了多种存储引擎.用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎. MySQL主要存储引擎的区别 MySQL默认的存储引擎是MyISAM,其他常用的就是InnoDB,另外还有MERGE.MEMORY(HEAP)等. 主要的几个存储引擎 MyISAM管理非事务表,提供高速存储和检索,以及全文搜索能力. MyISAM是Mysql的
-
Java数据结构之栈的线性结构详解
目录 一:栈 二:栈的实现 三:栈的测试 四:栈的应用(回文序列的判断) 总结 一:栈 栈是限制插入和删除只能在一个位置上进行的表,此位置就是表的末端,叫作栈顶. 栈的基本操作分为push(入栈) 和 pop(出栈),前者相当于插入元素到表的末端(栈顶),后者相当于删除栈顶的元素. 二:栈的实现 public class LinearStack { /** * 栈的初始默认大小为10 */ private int size = 5; /** * 指向栈顶的数组下标 */ int top = -1
-
Python数据结构与算法中的栈详解(2)
目录 匹配括号 匹配符号 总结 匹配括号 接下来,我们使用栈解决实际的计算机科学问题. 比如我们都写过这样所示的算术表达式, ( 5 + 6 ) ∗ ( 7 + 8 ) / ( 4 + 3 ) (5 + 6) * (7 + 8) / (4 + 3) (5+6)∗(7+8)/(4+3),其中的括号用来改变计算顺序,或提升运算优先级. 匹配括号是指每一个左括号都有与之对应的一个右括号,并且括号对有正确的嵌套关系. 正确的嵌套关系: ( ( ) ( ) ( ) ( ) ) (()()()()) (
-
Python数据结构与算法中的栈详解(3)
目录 前序.中序和后序表达式是什么? 我们为什么要学习前/后序表达式? 从中序向前序和后序转换 用Python实现从中序表达式到后序表达式的转换 计算后序表达式 总结 前序.中序和后序表达式是什么? 对于像B∗C 这样的算术表达式,可以根据其形式来正确地运算.在B∗C 的例子中,由于乘号出现在两个变量之间,因此我们知道应该用变量 B 乘以变量 C . 因为运算符出现在两个操作数的中间 ,所以这种表达式被称作中序表达式 . 来看另一个中序表达式的例子:A+B∗C.虽然运算符 “ + ” 和