一文搞懂python异常处理、模块与包
一 异常处理
1.什么是异常
Error(错误)是系统中的错误,程序员是不能改变的和处理的,如系统崩溃,内存空间不足,方法调用栈溢等。遇到这样的错误,建议让程序终止。
Exception(异常)表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。
2常见异常
IndentationError: 缩进错误
KeyboardInterrupt: Ctrl+C被按下
UnboundLocalError : 有同名的全局变量
d = {'name':'westos'}
print(d['age']) # KeyError
with open('hello.txt') as f: # FileNotFoundError
pass
AttributeError 、IOError 、ImportError 、IndexError、
SyntaxError、TypeError、ValueError、KeyError、NameError
3 异常处理机制
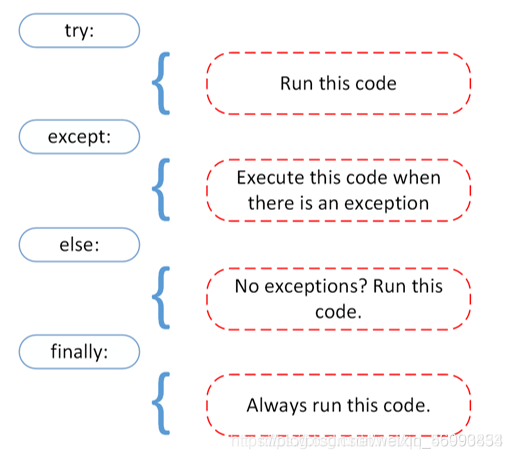
Python 的异常机制主要依赖 try 、except 、else、finally 和 raise 五个关键字。
try 关键字后缩进的代码块简称 try 块,它里面放置的是可能引发异常的代码;
except 关键字对应异常类型和处理该异常的代码块;
多个 except 块之后可以放一个 else 块,表明程序不出现异常时还要执行 else 块;
finally 块用于回收在 try 块里打开的物理资源,异常机制会保证 finally 块总被执行;
raise 用于引发一个实际的异常,raise 可以单独作为语句使用,引发一个具体的异常对象除了处理实际的错误条件之外,对于异常还有许多其它的用处。在标准 Python 库中一个普通的用法就是试着导入一个模块,然后检查是否它能使用。导入一个并不存在的模块将引发一个 ImportError 异常。
#异常处理机制:
# else:没有异常时,执行的内容
#finally: 总会执行的内容
try:
a = 1
print(b)
except NameError as e:
print('0-name error')
except KeyError:
print('4-key error')
except Exception as e:
print('1-exception')
else:
print('2-no error')
finally:
print('3-run code')
4 触发异常
Python 允许程序自行引发异常,自行引发异常使用 raise 语句来完成。
raise语句中 Exception 是异常的类型(例如,NameError)参数标准异常中任一种,
args 是自已提供的异常参数。
raise [Exception [, args [, traceback]]]
age = int(input('age:'))
if 0<age<150:
print(age)
else:
# 抛出异常
raise ValueError("年龄必须在0~150之间")
5 自定义异常
用户自定义异常都应该继承 Exception 基类或 Exception 的子类,在自定义异常类时基本不需要书写更多的代码,只要指定自定义异常类的父类即可。
# 自定义的异常
class AgeError(ValueError):
pass
age = int(input('age:'))
if 0<age<150:
print(age)
else:
# 抛出异常
raise AgeError("年龄必须在0~150之间")
```
二 模块与包
1.模块
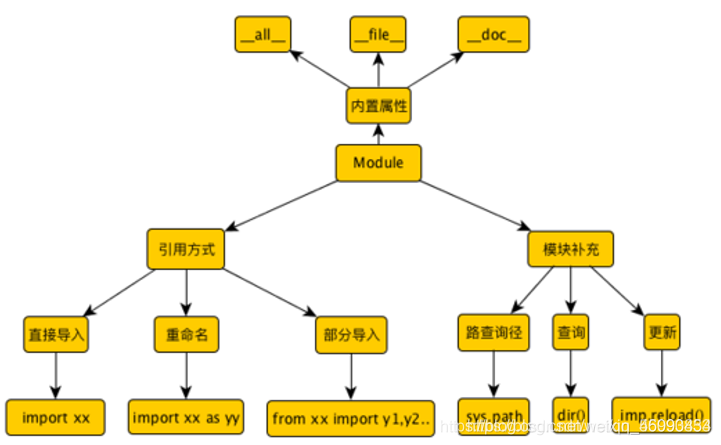

1.1在pycharm中建立一个python文件hello.py
"""
hello模块的说明文档
"""
digits = '0123456789'
def login():
print('login.......')
# __all__当用户使用from module import *时,需要导入的内容。
__all__ = ['digits']
# 当模块内部执行时,需要执行的代码。 当模块被导入,则不执行。
if __name__ == '__main__':
print(__name__)
# 当在模块内部执行__name__的值为__main__.
# 当模块被导入时,__name__的值为hello(模块名)
1.2. 注意: 自定义的python文件的文件名一定不要和已有的模块冲突。
1.3. 导入模块实质上是加载并执行模块的内容。
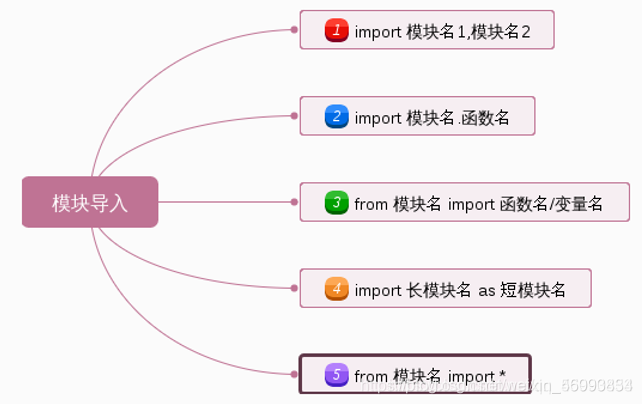
1.4. 导入模块的几种方式:
import hello print(hello.digits) hello.login()
1.5. 模块的其他信息
import sys
print(sys.path) # 模块的查询路径import hello
print(dir(hello)) # 查看hello模块可以使用的变量和函数…print(hello.__doc__)# 查看模块的说明文档
print(hello.__file__) # 显示模块的绝对路径
print(hello.__name__) # __name__当模块被导入时,显示的是模块的名称
name的特殊用法
import hello
"""
digits = '0123456789'
def login():
print('login.......')
print(__name__) # 当在模块内部执行__name__的值为__main__.
"""
2.包
包将有联系的模块组织在一起,有效避免模块名称冲突问题,让应用组织结构更加清晰。
一个普通的python应用程序目录结构:
2.1. 包实质上是包含__init__.py文件的目录。
2.2. 导入包实质是在做什么? 执行包里面的__init__.py的内容。
2.3. 导入包的方式:
sdk目录下包含的文件:
1.huawei.py
内容:
def create_ecs(): print('创建华为云') def delete_ecs(): print("删除华为云")2.aili.py
def create_ecs():
print('创建阿里云')def delete_ecs():
print("删除阿里云")3._init_.py
from . import ali
from . import huawei
from sdk import ali from sdk import huawei ali.create_ecs() huawei.create_ecs() import sdk sdk.ali.create_ecs() sdk.huawei.create_ecs()
2.4.模块的分类
time模块
import time print(time.time()) # 计算时间戳 print(time.ctime()) # 字符串的时间, Sun Feb 7 17:09:55 2021 tuple_time = time.localtime() # 元组类型的时间 print(tuple_time.tm_year)
datetime
from datetime import date, datetime, timedelta print(date.today()) # 获取今天的日期 print(datetime.now()) # 获取当前时间2021-02-07 17:13:17.170345 print(date.today() + timedelta(days=3)) # 获取3天后的日期 print(date.today() - timedelta(days=3)) # 获取3天前的日期 print(datetime.now() + timedelta(minutes=10)) # 获取10分钟之后的时间信息 print(datetime.now() - timedelta(minutes=10)) # 获取10分钟之前的时间信息
random
import random print(random.random()) # 生成0-1之间的小数 print(random.randint(1, 10)) # 生成1-10之间的整数 print(random.choice(['li', 'happy', 'fi'])) # 随机选择一个元素 print(random.sample(['ll', 'ff', 'oo'], 2)) # 随机选择n(n=2)个元素 print(random.choices(['ll', 'ff', 'oo'], weights=[100, 10, 10])) # 随机选择一个元素,可以指定权重
string
import string print(string.digits) # 获取所有的数字 print(string.ascii_letters) print(string.ascii_lowercase) print(string.ascii_uppercase)
颜色模块
from colorama import Fore print(Fore.RED + 'Error: 主机不存在') print(Fore.GREEN + 'Success: 主机创建成功')
生成测试信息的模块
from faker import Faker
fake = Faker('zh-cn')
print(fake.name())
print(fake.address())
print(fake.email())
2.5.模块的安装
pip install ** 但在安装的时候较慢,尽量选择合适的源安装
pip install colorama -i https://pypi.douban.com/simple
以上就是python异常处理、模块与包的详细内容,更多关于python异常处理、模块与包的资料请关注我们其它相关文章!
相关推荐
-
Python 中的Selenium异常处理实例代码
自动化测试执行过程中,难免会有错误/异常出现,比如测试脚本没有发现对应元素,则会立刻抛出NoSuchElementException异常.这时不要怕,肯定是测试脚本或者测试环境哪里出错了!那如何处理才是关键?因为一般只是局部有问题,为了让脚本继续执行,so我们可以用try...except...raise捕获异常.该捕获异常后可以打印出相应的异常原因,这样以便于分析异常原因. 下面将举例说明,当异常抛出后将信息打印在控制台,同时截取当前浏览器窗口,作为后续bug的依据给相应开发人员更好下定位问题
-
Python模块/包/库安装的六种方法及区别
方法1: 单文件模块 直接把文件拷贝到 $python_dir/Lib 方法2: 多文件模块,文件内有setup.py文件 在官网或者GitHub上下载模块包(压缩文件zip或tar.gz),解压缩之后,文件夹下会有setup.py文件,从命令行窗口进入该文件夹,然后输入命令: python setup.py install 方法3:easy_install 方式 先下载 ez_setup.py,运行 python ez_setup 进行easy_install工具的安装,之后就可以使用easy
-
Python3.4学习笔记之类型判断,异常处理,终止程序操作小结
本文实例讲述了Python3.4类型判断,异常处理,终止程序操作.分享给大家供大家参考,具体如下: python3.4学习笔记 类型判断,异常处理,终止程序,实例代码: #idle中按F5可以运行代码 #引入外部模块 import xxx #random模块,randint(开始数,结束数) 产生整数随机数 import random import sys import os secret = random.randint(1,10) temp = input("请输入一个数字\n")
-
Python中的异常处理try/except/finally/raise用法分析
本文实例分析了Python中的异常处理try/except/finally/raise用法.分享给大家供大家参考,具体如下: 异常发生在程序执行的过程中,如果python无法正常处理程序就会发生异常,导致整个程序终止执行,python中使用try/except语句可以捕获异常. try/except 异常的种类有很多,在不确定可能发生的异常类型时可以使用Exception捕获所有异常: try: pass except Exception, e: print Exception, ":"
-
python try 异常处理(史上最全)
在程序出现bug时一般不会将错误信息显示给用户,而是现实一个提示的页面,通俗来说就是不让用户看见大黄页!!! 有时候我们写程序的时候,会出现一些错误或异常,导致程序终止. 为了处理异常,我们使用try...except 把可能发生错误的语句放在try模块里,用except来处理异常. except可以处理一个专门的异常,也可以处理一组圆括号中的异常, 如果except后没有指定异常,则默认处理所有的异常. 每一个try,都必须至少有一个except 在python的异常中,有一个万能异常:Exc
-
Python安装依赖(包)模块方法详解
Python模块,简单说就是一个.py文件,其中可以包含我们需要的任意Python代码.迄今为止,我们所编写的所有程序都包含在单独的.py文件中,因此,它们既是程序,同时也是模块.关键的区别在于,程序的设计目标是运行,而模块的设计目标是由其他程序导入并使用. 不是所有程序都有相关联的.py文件-比如说,sys模块就内置于Python中,还有些模块是使用其他语言(最常见的是C语言)实现的.不过,Python的大多数库文件都是使用Python实现的,因此,比如说,我们使用了语句import coll
-
安装完Python包然后找不到模块的解决步骤
首先呢我去安装了一个那个pytorch,然后导入一下发现: 连numpy都找不到,于是我表示很生气 重新安装,它说安装过了,地址是balabala: 说明是找不到的问题,于是乎我去配了一下环境变量 在环境变量最后加入了一行: export PYTHONPATH=/usr/local/lib/python3.6/dist-packages:$PYTHONPATH 然后就导入成功了 以上这篇安装完Python包然后找不到模块的解决步骤就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多
-
Python 异常处理的实例详解
Python 异常处理的实例详解 与许多面向对象语言一样,Python 具有异常处理,通过使用 try...except 块来实现. Note: Python v s. Java 的异常处理 Python 使用 try...except 来处理异常,使用 raise 来引发异常.Java 和 C++ 使用 try...catch 来处理异常,使用 throw 来引发异常. 异常在 Python 中无处不在:实际上在标准 Python 库中的每个模块都使用了它们,并且 Python 自已会在许多不
-

一文搞懂python异常处理、模块与包
一 异常处理 1.什么是异常 Error(错误)是系统中的错误,程序员是不能改变的和处理的,如系统崩溃,内存空间不足,方法调用栈溢等.遇到这样的错误,建议让程序终止. Exception(异常)表示程序可以处理的异常,可以捕获且可能恢复.遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常. 2常见异常 IndentationError: 缩进错误 KeyboardInterrupt: Ctrl+C被按下 UnboundLocalError : 有同名的全局变量 d = {'n
-
一文搞懂Python中subprocess模块的使用
目录 简介 常用方法和接口 subprocess.run()解析 subprocess.Popen()解析 Popen 对象方法 subprocess.run()案例 subprocess.call()案例 subprocess.check_call()案例 subprocess.getstatusoutput()案例 subprocess.getoutput()案例 subprocess.check_output()案例 subprocess.Popen()综合案例 简介 subprocess
-
一文搞懂Python中列表List和元组Tuple的使用
目录 列表 List 列表是有序的 列表可以包含任意对象 通过索引访问列表元素 列表嵌套 列表可变 元组 Tuple 定义和使用元组 元素对比列表的优点 元组分配.打包和解包 List 与 Tuple 的区别 列表 List 列表是任意对象的集合,在 Python 中通过逗号分隔的对象序列括在方括号 ( [] ) 中 people_list = ['曹操', '曹丕', '甄姫', '蔡文姫'] print(people_list) ['曹操', '曹丕', '甄姫', '蔡文姫'] peopl
-
一文搞懂Python读取text,CSV,JSON文件的方法
目录 前言 打开文件 Python 中的文件读取模式 读取文本文件 读取 CSV 文件 读取 JSON 文件 总结 前言 文件是无处不在的,无论我们使用哪种编程语言,处理文件对于每个程序员都是必不可少的 文件处理是一种用于创建文件.写入数据和从中读取数据的过程,Python 拥有丰富的用于处理不同文件类型的包,从而使得我们可以更加轻松方便的完成文件处理的工作 本文大纲: 使用上下文管理器打开文件 Python 中的文件读取模式 读取 text 文件 读取 CSV 文件 读取 JSON 文件 打开
-
一文搞懂Python Sklearn库使用
目录 1.LabelEncoder 2.OneHotEncoder 3.sklearn.model_selection.train_test_split随机划分训练集和测试集 4.pipeline 5 perdict 直接返回预测值 6 sklearn.metrics中的评估方法 7 GridSearchCV 8 StandardScaler 9 PolynomialFeatures 4.10+款机器学习算法对比 4.1 生成数据 4.2 八款主流机器学习模型 4.3 树模型 - 随机森林 4.
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
一文搞懂Python中pandas透视表pivot_table功能
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中的进程,线程和协程
目录 1.什么是并发编程 2.进程与多进程 3.线程与多线程 4.协程与多协程 5.总结 1.什么是并发编程 并发编程是实现多任务协同处理,改善系统性能的方式.Python中实现并发编程主要依靠 进程(Process):进程是计算机中的程序关于某数据集合的一次运行实例,是操作系统进行资源分配的最小单位 线程(Thread):线程被包含在进程之中,是操作系统进行程序调度执行的最小单位 协程(Coroutine):协程是用户态执行的轻量级编程模型,由单一线程内部发出控制信号进行调度 直接上一张图看看
-
一文搞懂python可迭代对象,迭代器,生成器,协程
目录 设计模式:迭代 python:可迭代对象和迭代器 为什么要有生成器? python的生成器实现 协程 设计模式:迭代 迭代是一种设计模式,解决有序便利序列的问题.通用的可迭代对象需要支持done和next方法. 伪代码如下: while not iterator.done(): item = iterator.next() ..... python:可迭代对象和迭代器 python的可迭代对象需要实现__iter__()方法,返回一个迭代器.for循环和顶级函数iter(obj)调用obj