python遗传算法之geatpy的深入理解
目录
- 1. geatpy的安装
- 2. geatpy的基础数据结构
- 2.1 种群染色体
- 2.2 种群表现型
- 2.3 目标函数值
- 2.4 个体适应度
- 2.5 违反约束程度矩阵
- 2.6 译码矩阵
- 2.7 进化追踪器
- 3. geatpy的种群结构
- 3.1 Population类
- 3.2 PsyPopulation类
- 4. 求解标准测试函数——McCormick函数
- 5.参考文章
今天我们来学习python中的遗传算法的使用,我们这里使用的是geatpy的包进行学习,本博客主要从geatpy中的各种数据结构一步一步进行学习,请大家耐心看完。
其实以前也学习过遗传算法,但是主要使用matlab进行编程的,后面觉得matlab太麻烦了,还是使用python方便些,于是开始继续学习。
1. geatpy的安装
首先是安装geatpy,使用pip3命令进行安装即可:
pip3 install geatpy
出现如下提示即安装成功:

2. geatpy的基础数据结构
geatpy中的大部分数据都是都是使用numpy的数组进行存储和计算的,下面我将介绍遗传算法中的概念是如何用numpy数据表示,以及行和列的含义。
2.1 种群染色体
遗传算法中最重要的就是个体的染色体表示,在geatpy中种群染色体用Chrom表示,这是一个二维数组,其中每一行对应一个个体的染色体编码,Chrom的结构如下:其中lind表示编码的长度,Nind表示的是种群的规模(个体数量)。

2.2 种群表现型
种群表现型是是指种群染色体矩阵Chrom经过解码后得到的基因表现型矩阵Phen,每一行对应一个个体,每一列对应一个决策变量,Phen的结构如下:其中Nvar表示变量的个数
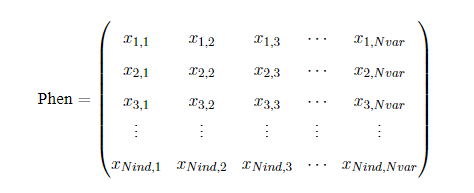
Phen的值与采用的解码方式有关。Geatpy提供二进制/格雷码编码转十进制整数或实数的解码方式。另外,在Geatpy也可以使用不需要解码的“实值编码”种群,这种种群的染色体的每一位就对应着决策变量的实际值,即这种编码方式下Phen等价Chrom。
2.3 目标函数值
Geatpy采用numpy的array类型矩阵来存储种群的目标函数值。一般命名为ObjV,每一行对应每一个个体,因此它拥有与Chrom相同的行数;每一列对应一个目标函数,因此对于单目标函数,ObjV会只有1列;而对于多目标函数,ObjV会有多列, ObjV的表示形式如下:

2.4 个体适应度
Geatpy采用列向量来存储种群个体适应度(适应度函数计算而来)。一般命名为FitnV,它同样是numpy的array类型,每一行对应种群矩阵的每一个个体。因此它拥有与Chrom相同的行数,FitnV的格式如下:

注意:Geatpy中的适应度遵循“最小适应度为0”的约定。
2.5 违反约束程度矩阵
Geatpy采用numpy的array类型的矩阵CV(Constraint Violation Value)来存储种群个体违反各个约束条件的程度。命名为CV,它的每一行对应种群的每一个个体,因此它拥有与Chrom相同的行数;每一列对应一个约束条件,因此若有一个约束条件,那么CV矩阵就会只有一列,如有多个约束条件,CV矩阵就会有多列。如果设有num个约束,则CV矩阵的结构如下图所示:

CV矩阵的某个元素若小于或等于0,则表示该元素对应的个体满足对应的约束条件。若大于0,则表示违反约束条件,在大于0的条件下值越大,该个体违反该约束的程度就越高。Geatpy提供两种处理约束条件的方法,一种是罚函数法,另一种是可行性法则。在使用可行性法则处理约束条件时,需要用到CV矩阵。
2.6 译码矩阵
所谓的译码矩阵,只是用来描述种群染色体特征的矩阵,如染色体中的每一位元素所表达的决策变量的范围、是否包含范围的边界、采用二进制还是格雷码、是否使用对数刻度、染色体解码后所代表的决策变量的是连续型变量还是离散型变量等等。
在只使用工具箱的库函数而不使用Geatpy提供的面向对象的进化算法框架时,译码矩阵可以单独使用。若采用Geatpy提供的面向对象的进化算法框架时,译码矩阵可以与一个存储着种群染色体编码方式的字符串Encoding来配合使用。
目前Geatpy中有三种Encoding,分别为:
- BG:(二进制/格雷码)
- RI:((实整数编码,即实数和整数的混合编码)
- P:(排列编码,即染色体每一位的元素都是互异)
注:’RI’和’P’编码的染色体都不需要解码,染色体上的每一位本身就代表着决策变量的真实值,因此“实整数编码”和“排列编码”可统称为“实值编码”
以BG编码为例,我们展示一下编译矩阵FieldD。FieldD的结构如下:
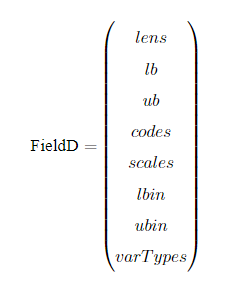
其中,lens,lb,ub,codes,scales,lbin,ubin,varTypes都是行向量,其长度等于决策变量的个数。
- lens:代表以条染色体中,每个子染色体的长度。
- lb:代表每个变量的上界
- ub:代表每个变量的下界
- codes:代表染色体字串用的编码方式,[1,0,1]代表第一个变量用的格雷编码,第二个变量用的二进制编码,第3个变量用的格雷编码。
- scales:指明每个子串用的是算术刻度还是对数刻度。scales[i] = 0为算术刻度,scales[i] = 1为对数刻度(对数刻度很少用,可以忽略。)
- lbin:代表变量上界是否包含其范围边界。0代表不包含,1代表包含。‘[ ’和 ‘(’ 的区别
- ubin:代表变量下界是否包含其范围边界。0代表不包含,1代表包含。
- varTypes:代表决策变量的类型,元素为0表示对应位置的决策变量是连续型变量;1表示对应的是离散型变量。
例如:有以下一个译码矩阵

它表示待解码的种群染色体矩阵Chrom解码后可以表示成3个决策变量,每个决策变量的取值范围分别是[1,10], [2,9], [3,15]。其中第一第二个变量采用的是二进制编码,第三个变量采用的是格雷编码,且第一、第三个决策变量为连续型变量;第二个为离散型变量。
#通过种群染色体chrom和译码矩阵FieldD,可解码成种群表现型矩阵。 import geatpy as ea Phen = ea.bs2ri(Chrom, FieldD)
2.7 进化追踪器
在使用Geatpy进行进化算法编程时,常常建立一个进化追踪器(如pop_trace)来记录种群在进化的过程中各代的最优个体,尤其是采用无精英保留机制时,进化追踪器帮助我们记录种群在进化过程中的最优个体。待进化完成后,再从进化追踪器中挑选出“历史最优”的个体。这种进化记录器有多种,其中一种是numpy的array类型的,结构如下:其中MAXGEN是种群进化的代数(迭代次数)。
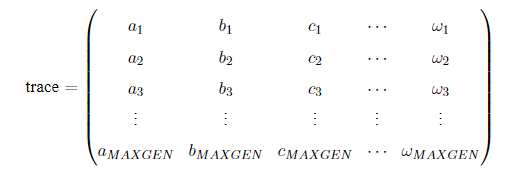
trace的每一列代表不同的指标,比如第一列记录各代种群的最佳目标函数值,第二列记录各代种群的平均目标函数值…trace的每一行对应每一代,如第一行代表第一代,第二行代表第二代…另外一种进化记录器是一个列表,列表中的每一个元素都是一个拥有相同数据类型的数据。比如在Geatpy的面向对象进化算法框架中的pop_trace,它是一个列表,列表中的每一个元素都是历代的种群对象。
3. geatpy的种群结构
3.1 Population类
在Geatpy提供的面向对象进化算法框架中,种群类(Population)是一个存储着与种群个体相关信息的类。它有以下基本属性:
- sizes : int -种群规模,即种群的个体数目。
- ChromNum : int -染色体的数目,即每个个体有多少条染色体。
- Encoding : str -染色体编码方式。
- Field : array -译码矩阵,可以是FieldD或FieldDR。
- Chrom : array -种群染色体矩阵,每一行对应一个个体的一条染色体。
- Lind : int -种群染色体长度。
- ObjV : array -种群目标函数值矩阵。
- FitnV : array -种群个体适应度列向量。
- CV : array -种群个体违反约束条件程度的矩阵。
- Phen : array -种群表现型矩阵。
可以直接对种群对象进行提取个体、个体合并等操作,比如pop1和pop2是两个种群对象,则通过语句“pop3 = pop1 + pop2”,即可把两个种群的个体合并,得到一个新的种群。在合并的过程中,实际上是把种群的各个属性进行合并,然后用合并的数据来生成一个新的种群(详见Population.py)。又比如执行语句“pop3 = pop1[[0]]”,可以把种群的第0号个体抽取出来,得到一个新的只有一个个体的种群对象pop3。值得注意的是,种群的这种个体抽取操作要求下标必须为列表或是Numpy array类型的行向量,不能是标量(详见Population.py)
3.2 PsyPopulation类
PsyPopulation类是Population的子类,它提供Population类所不支持的多染色体混合编码。它有以下基本属性:
- sizes : int -种群规模,即种群的个体数目。
- ChromNum : int -染色体的数目,即每个个体有多少条染色体。
- Encodings : list -存储各染色体编码方式的列表。
- Fields : list -存储各染色体对应的译码矩阵的列表。
- Chroms : list -存储种群各染色体矩阵的列表。
- Linds : list -存储种群各染色体长度的列表。
- ObjV : array -种群目标函数值矩阵。
- FitnV : array -种群个体适应度列向量。
- CV : array -种群个体违反约束条件程度的矩阵。
- Phen : array -种群表现型矩阵。
可见PsyPopulation类基本与Population类一样,不同之处是采用Linds、Encodings、Fields和Chroms分别存储多个Lind、Encoding、Field和Chrom。
PsyPopulation类的对象往往与带“psy”字样的进化算法模板配合使用,以实现多染色体混合编码的进化优化。
4. 求解标准测试函数——McCormick函数
遗传算法求解以下函数的最小值:

代码实现:
#-*-coding:utf-8-*-
import numpy as np
import geatpy as ea#导入geatpy库
import time
"""============================目标函数============================"""
def aim(Phen):#传入种群染色体矩阵解码后的基因表现型矩阵
x1 = Phen[:, [0]]#取出第一列,得到所有个体的第一个自变量
x2 = Phen[:, [1]]#取出第二列,得到所有个体的第二个自变量
return np.sin(x1 + x2) + (x1 - x2) ** 2 - 1.5 * x1 + 2.5 * x2+1
"""============================变量设置============================"""
x1 = [-1.5, 4]#第一个决策变量范围
x2 = [-3, 4]#第二个决策变量范围
b1 = [1, 1]#第一个决策变量边界,1表示包含范围的边界,0表示不包含
b2 = [1, 1]#第二个决策变量边界,1表示包含范围的边界,0表示不包含
#生成自变量的范围矩阵,使得第一行为所有决策变量的下界,第二行为上界
ranges=np.vstack([x1, x2]).T
#生成自变量的边界矩阵
borders=np.vstack([b1, b2]).T
varTypes = np.array([0, 0])#决策变量的类型,0表示连续,1表示离散
"""==========================染色体编码设置========================="""
Encoding ='BG'#'BG'表示采用二进制/格雷编码
codes = [1, 1]#决策变量的编码方式,两个1表示变量均使用格雷编码
precisions =[6, 6]#决策变量的编码精度,表示解码后能表示的决策变量的精度可达到小数点后6位
scales = [0, 0]#0表示采用算术刻度,1表示采用对数刻度#调用函数创建译码矩阵
FieldD =ea.crtfld(Encoding,varTypes,ranges,borders,precisions,codes,scales)
"""=========================遗传算法参数设置========================"""
NIND = 20#种群个体数目
MAXGEN = 100#最大遗传代数
maxormins = np.array([1])#表示目标函数是最小化,元素为-1则表示对应的目标函数是最大化
selectStyle ='sus'#采用随机抽样选择
recStyle ='xovdp'#采用两点交叉
mutStyle ='mutbin'#采用二进制染色体的变异算子
Lind =int(np.sum(FieldD[0, :]))#计算染色体长度
pc= 0.9#交叉概率
pm= 1/Lind#变异概率
obj_trace = np.zeros((MAXGEN, 2))#定义目标函数值记录器
var_trace = np.zeros((MAXGEN, Lind))#染色体记录器,记录历代最优个体的染色体
"""=========================开始遗传算法进化========================"""
start_time = time.time()#开始计时
Chrom = ea.crtpc(Encoding,NIND, FieldD)#生成种群染色体矩阵
variable = ea.bs2ri(Chrom, FieldD)#对初始种群进行解码
ObjV = aim(variable)#计算初始种群个体的目标函数值
best_ind = np.argmin(ObjV)#计算当代最优个体的序号
#开始进化
for gen in range(MAXGEN):
FitnV = ea.ranking(maxormins * ObjV)#根据目标函数大小分配适应度值
SelCh = Chrom[ea.selecting(selectStyle,FitnV,NIND-1),:]#选择
SelCh = ea.recombin(recStyle, SelCh, pc)#重组
SelCh = ea.mutate(mutStyle, Encoding, SelCh, pm)#变异
# #把父代精英个体与子代的染色体进行合并,得到新一代种群
Chrom = np.vstack([Chrom[best_ind, :], SelCh])
Phen = ea.bs2ri(Chrom, FieldD)#对种群进行解码(二进制转十进制)
ObjV = aim(Phen)#求种群个体的目标函数值
#记录
best_ind = np.argmin(ObjV)#计算当代最优个体的序号
obj_trace[gen,0]=np.sum(ObjV)/ObjV.shape[0]#记录当代种群的目标函数均值
obj_trace[gen,1]=ObjV[best_ind]#记录当代种群最优个体目标函数值
var_trace[gen,:]=Chrom[best_ind,:]#记录当代种群最优个体的染色体
# 进化完成
end_time = time.time()#结束计时
ea.trcplot(obj_trace, [['种群个体平均目标函数值','种群最优个体目标函数值']])#绘制图像
"""============================输出结果============================"""
best_gen = np.argmin(obj_trace[:, [1]])
print('最优解的目标函数值:', obj_trace[best_gen, 1])
variable = ea.bs2ri(var_trace[[best_gen], :], FieldD)#解码得到表现型(即对应的决策变量值)
print('最优解的决策变量值为:')
for i in range(variable.shape[1]):
print('x'+str(i)+'=',variable[0, i])
print('用时:', end_time - start_time,'秒')
效果图:

结果如下:

5.参考文章
链接: geatpy说明文档.
到此这篇关于python遗传算法之geatpy的深入理解的文章就介绍到这了,更多相关python遗传算法之geatpy内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现简单遗传算法
今天整理之前写的代码,发现在做数模期间写的用python实现的遗传算法,感觉还是挺有意思的,就拿出来分享一下. 首先遗传算法是一种优化算法,通过模拟基因的优胜劣汰,进行计算(具体的算法思路什么的就不赘述了).大致过程分为初始化编码.个体评价.选择,交叉,变异. 以目标式子 y = 10 * sin(5x) + 7 * cos(4x)为例,计算其最大值 首先是初始化,包括具体要计算的式子.种群数量.染色体长度.交配概率.变异概率等.并且要对基因序列进行初始化 pop_size = 500 # 种群
-
python实现使用遗传算法进行图片拟合
目录 引言 预备知识及准备工作 打开图片 随机生成生物族群 按照生物性状画图 对比生物个体和目标图片的相似度 保存图片 算法主体 交叉互换 基因突变 基因片段易位 增加基因片段 减少基因片段 变异 繁殖 淘汰 拟合 示例展示 降低图片分辨率 原图 拟合过程展示 完整代码下载(已封装成类) 引言 算法思路 假设我们有这样一个生物族群,他们的每个基因片段都是一个个三角形(即只含三个点和颜色信息),他们每个个体表现出的性状就是若干个三角形叠加在一起.假设我们有一张图片可以作为这种生物族群最适应环境的性
-
python 如何实现遗传算法
1.基本概念 遗传算法(GA)是最早由美国Holland教授提出的一种基于自然界的"适者生存,优胜劣汰"基本法则的智能搜索算法.该法则很好地诠释了生物进化的自然选择过程.遗传算法也是借鉴该基本法则,通过基于种群的思想,将问题的解通过编码的方式转化为种群中的个体,并让这些个体不断地通过选择.交叉和变异算子模拟生物的进化过程,然后利用"优胜劣汰"法则选择种群中适应性较强的个体构成子种群,然后让子种群重复类似的进化过程,直到找到问题的最优解或者到达一定的进化(运算)时间.
-
python 遗传算法求函数极值的实现代码
废话不多说,大家直接看代码吧! """遗传算法实现求函数极大值-Zjh""" import numpy as np import random import matplotlib.pyplot as plt class Ga(): """求出二进制编码的长度""" def __init__(self): self.boundsbegin = -2 self.boundsend = 3 p
-
Python实现简单遗传算法(SGA)
本文用Python3完整实现了简单遗传算法(SGA) Simple Genetic Alogrithm是模拟生物进化过程而提出的一种优化算法.SGA采用随机导向搜索全局最优解或者说近似全局最优解.传统的爬山算法(例如梯度下降,牛顿法)一次只优化一个解,并且对于多峰的目标函数很容易陷入局部最优解,而SGA算法一次优化一个种群(即一次优化多个解),SGA比传统的爬山算法更容易收敛到全局最优解或者近似全局最优解. SGA基本流程如下: 1.对问题的解进行二进制编码.编码涉及精度的问题,在本例中精度de
-
Python实现遗传算法(虚拟机中运行)
目录 (一)问题 (二)代码 (三)运行结果 (四)结果描述 (一)问题 遗传算法求解正方形拼图游戏 (二)代码 #!/usr/bin/env python # -*- coding: utf-8 -*- from PIL import Image, ImageDraw import os import gc import random as r import minpy.numpy as np class Color(object): ''' 定义颜色的类,这个类包含r,g,b,a表示颜色属性
-
详解用python实现简单的遗传算法
今天整理之前写的代码,发现在做数模期间写的用python实现的遗传算法,感觉还是挺有意思的,就拿出来分享一下. 首先遗传算法是一种优化算法,通过模拟基因的优胜劣汰,进行计算(具体的算法思路什么的就不赘述了).大致过程分为初始化编码.个体评价.选择,交叉,变异. 遗传算法介绍 遗传算法是通过模拟大自然中生物进化的历程,来解决问题的.大自然中一个种群经历过若干代的自然选择后,剩下的种群必定是适应环境的.把一个问题所有的解看做一个种群,经历过若干次的自然选择以后,剩下的解中是有问题的最优解的.当然,只
-
python遗传算法之geatpy的深入理解
目录 1. geatpy的安装 2. geatpy的基础数据结构 2.1 种群染色体 2.2 种群表现型 2.3 目标函数值 2.4 个体适应度 2.5 违反约束程度矩阵 2.6 译码矩阵 2.7 进化追踪器 3. geatpy的种群结构 3.1 Population类 3.2 PsyPopulation类 4. 求解标准测试函数——McCormick函数 5.参考文章 今天我们来学习python中的遗传算法的使用,我们这里使用的是geatpy的包进行学习,本博客主要从geatpy中的各种数据结
-
python遗传算法之单/多目标规划问题
目录 1. 运行环境 2. 面向对象的原理 3. 带约束的单目标优化问题 3.1 继承 Problem 问题类完成对问题模型的描述 3.2 调用算法模板进行求解 3.3 结果 4. 带约束的多目标优化问题 4.1 继承 Problem 问题类完成对问题模型的描述 4.2 调用算法模板进行求解 4.3 结果 5. 参考资料 在上一篇博客中,我们学习了python遗传算法包geatpy.并用它展示了一个不带约束的单目标规划问题,对往期内容感兴趣的同学可以参考: 链接: python遗传算法之geat
-
Python遗传算法Geatpy工具箱使用介绍
目录 一. 什么是遗传算法? 二. 遗传算法库Geatpy 2.1 遗传算法工具箱Geatpy参数介绍 三.最佳实践 3.1 代码示例 | 参数模板 3.2 最佳实践 一. 什么是遗传算法? 遗传算法是仿真生物遗传学和自然选择机理,通过人工方式所构造的一类搜索算法,从某种程度上说遗传算法是对生物进化过程进行的数学方式仿真.生物种群的生存过程普遍遵循达尔文进化准则,群体中的个体根据对环境的适应能力而被大自然所选择或淘汰.进化过程的结果反映在个体的结构上,其染色体包含若干基因,相应的表现型和基因型的
-
Python 多进程和数据传递的理解
Python 多进程和数据传递的理解 python不仅线程用的是系统原生线程,进程也是用的原生进程 进程的用法和线程大同小异 import multiprocessing p = multiprocessing.Process(target=fun,args=()) 线程的基本方法在进程中都能够使用 但是进程和线程中有一个明显的区别:可以实现多核的运用 python本身会启动一个主进程,并且拥有一个主线程把主进程看做一家之主,那主线程也是他本身,其他线程就相当于老婆们 而进程,长大了的儿子们,线
-
对python pandas中 inplace 参数的理解
pandas 中 inplace 参数在很多函数中都会有,它的作用是:是否在原对象基础上进行修改 inplace = True:不创建新的对象,直接对原始对象进行修改: inplace = False:对数据进行修改,创建并返回新的对象承载其修改结果. 默认是False,即创建新的对象进行修改,原对象不变,和深复制和浅复制有些类似. 例: inplace=True情况: import pandas as pd import numpy as np df=pd.DataFrame(np.rand
-
Python光学仿真之对光的干涉理解学习
光的干涉 干涉即两束光在叠加过程中出现的强度周期性变化情况,其最简单的案例即为杨氏双缝干涉. 如图所示,光从 S S S点发出,通过两个狭缝 S 1 , S 2 S_1,S_2 S1,S2,最终汇聚在右侧的干涉屏上,在不同位置处将会产生不同的相位差. import numpy as np import matplotlib.pyplot as plt #两束光叠加 waveAdd = lambda I1,I2,theta : I1+I2+2*np.sqrt(I1*I2)*np.cos(the
-
Python中super().__init__()测试以及理解
目录 python里的super().init()有什么用? Python super().__init__()测试 super() 在 python2.3中的区别 总结 python里的super().init()有什么用? 对于python里的super().__init__()有什么作用,很多同学没有弄清楚. 直白的说super().__init__(),就是继承父类的init方法,同样可以使用super()点 其他方法名,去继承其他方法. Python super().__init__(
-
Python内建类型bytes深入理解
目录 引言 1 bytes和str之间的关系 2 bytes对象的结构:PyBytesObject 3 bytes对象的行为 3.1 PyBytes_Type 3.2 bytes_as_sequence 4 字符缓冲池 引言 “深入认识Python内建类型”这部分的内容会从源码角度为大家介绍Python中各种常用的内建类型. 在我们日常的开发中,str是很常用的一个内建类型,与之相关的我们比较少接触的就是bytes,这里先为大家介绍一下bytes相关的知识点,下一篇博客再详细介绍str的相关内容
-
Python正则表达式 r'(.*) are (.*?) .*'的深入理解
在学习Python3的正则表达式的时候遇到一个例子 #!/usr/bin/python3 import re line = "Cats are smarter than dogs" # .* 表示任意匹配除换行符(\n.\r)之外的任何单个或多个字符 # (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串 matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I) if matchObj: print