Python+Opencv身份证号码区域提取及识别实现
前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出。现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论。最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^。
实训环境:CentOS-7.5.1804 + Python-3.6.6 + Opencv-3.4.1
做测试用的照片以及数字识别匹配使用的模板(自制)提供给大家,通过查询得到,身份证号码使用的字体格式为OCR-B 10 BT格式,实训中用到的身份证图片为训练测试图片,有一部分是老师当时直接给出的,还有一部分是我自己用自己身份证做的测试和从网上找到了一张,由于部分身份证号码不是标准字体格式,对识别造成影响,所以有部分图片我还提前ps了一下。



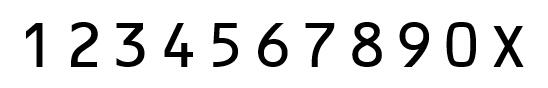
流程图

前期处理的部分不在描述,流程图和代码注释中都有。其实整个过程并不是很复杂,本来想过在数字识别方面用现成的一些方法,或者想要尝试用到卷积神经网络(CNN)然后做训练集来识别。后来在和老师交流的时候,老师给出建议可以尝试使用特征点匹配或者其他类方法。根据最后数字分割出来单独显示的效果,想到了一个适合于我代码情况的简单方法。
建立一个标准号码库(利用上面自制模板数字分割后获得),然后用每一个号码图片与库中所有标准号码图片做相似度匹配,和哪一个模板相似度最高,则说明该图片为哪一位号码。在将模板号码分割成功后,最关键的一步就是进行相似度匹配。为提高匹配的精确度和效率,首先利用cv.resize()将前面被提取出的每位身份证号码以及标准号码库中的号码做图像大小调整,统一将图像均调整为12x18像素的大小,图像大小的选择是经过慎重的考虑的,如果太大则计算过程耗时,如果过小则可能存在较大误差。匹配的具体方案为:记录需要识别的图片与每个模板图片中有多少位置的像素点相同,相同的越多,说明相似度越高,也就最有可能是某个号码。最终将18位号码都识别完成后,得到的具体的相似度矩阵。
具体代码如下所示:
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
# 将身份证号码区域从身份证中提取出
def Extract(op_image, sh_image):
binary, contours, hierarchy = cv.findContours(op_image,
cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
contours.remove(contours[0])
max_x, max_y, max_w, max_h = cv.boundingRect(contours[0])
color = (0, 0, 0)
for c in contours:
x, y, w, h = cv.boundingRect(c)
cv.rectangle(op_image, (x, y), (x + w, y + h), color, 1)
cv.rectangle(sh_image, (x, y), (x + w, y + h), color, 1)
if max_w < w:
max_x = x
max_y = y
max_w = w
max_h = h
cut_img = sh_image[max_y:max_y+max_h, max_x:max_x+max_w]
cv.imshow("The recognized enlarged image", op_image)
cv.waitKey(0)
cv.imshow("The recognized binary image", sh_image)
cv.waitKey(0)
return cut_img
# 号码内部区域填充(未继续是用此方法)
def Area_filling(image, kernel):
# The boundary image
iterate = np.zeros(image.shape, np.uint8)
iterate[:, 0] = image[:, 0]
iterate[:, -1] = image[:, -1]
iterate[0, :] = image[0, :]
iterate[-1, :] = image[-1, :]
while True:
old_iterate = iterate
iterate_dilation = cv.dilate(iterate, kernel, iterations=1)
iterate = cv.bitwise_and(iterate_dilation, image)
difference = cv.subtract(iterate, old_iterate)
# if difference is all zeros it will return False
if not np.any(difference):
break
return iterate
# 将身份证号码区域再次切割使得一张图片一位号码
def Segmentation(cut_img, kernel, n):
#首先进行一次号码内空白填充(效果不佳,放弃)
#area_img = Area_filling(cut_img, kernel)
#cv.imshow("area_img", area_img)
#cv.waitKey(0)
#dilate = cv.dilate(area_img, kernel, iterations=1)
#cv.imshow("dilate", dilate)
#cv.waitKey(0)
cut_copy = cut_img.copy()
binary, contours, hierarchy = cv.findContours(cut_copy, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
contours.remove(contours[0])
for c in contours:
x, y, w, h = cv.boundingRect(c)
for i in range(h):
for j in range(w):
# 把首次用findContours()方法识别的轮廓内区域置黑色
cut_copy[y + i, x + j] = 0
# cv.rectangle(cut_copy, (x, y), (x + w, y + h), color, 1)
cv.imshow("Filled image", cut_copy)
cv.waitKey(0)
# 尝试进行分割
binary, contours, hierarchy = cv.findContours(cut_copy, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
#tmp_img = cut_img.copy()
# 如果识别的轮廓数量不是n+1位(首先是一个整个区域的轮廓,然后是n位号码各自的轮廓,身份证和匹配模板分割均用此方法)
while len(contours)!=n+1:
if len(contours) < n+1:
# 如果提取的轮廓数量小于n+1, 说明可能有两位数被识别到一个轮廓中,做一次闭运算,消除数位之间可能存在的连接部分,然后再次尝试提取
#cut_copy = cv.dilate(cut_copy, kernel, iterations=1)
cut_copy = cv.morphologyEx(cut_copy, cv.MORPH_CLOSE, kernel)
cv.imshow("cut_copy", cut_copy)
cv.waitKey(0)
# 再次尝试提取身份证区域的轮廓并将轮廓内区域用黑色覆盖
binary, contours, hierarchy = cv.findContours(cut_copy, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
# 去掉提取出的第一个轮廓(第一个轮廓为整张图片)
contours.remove(contours[0])
for c in contours:
x, y, w, h = cv.boundingRect(c)
for i in range(h):
for j in range(w):
cut_copy[y + i, x + j] = 0
# cv.rectangle(cut_copy, (x, y), (x + w, y + h), color, 1)
cv.imshow("Filled image", cut_copy)
cv.waitKey(0)
#如果findContours()结果为n,跳出
if len(contours) == n:
break
elif len(contours) > n+1:
# 如果提取的轮廓数量大于n+1, 说明可能有一位数被识别到两个轮廓中,做一次开运算,增强附近身份证区域部分之间的连接部分,然后再次尝试提取
#cut_copy = cv.erode(cut_copy, kernel, iterations=1)
cut_copy = cv.morphologyEx(cut_copy, cv.MORPH_OPEN, kernel2)
cv.imshow("cut_copy", cut_copy)
cv.waitKey(0)
#再次尝试提取身份证区域的轮廓并将轮廓内区域用黑色覆盖
binary, contours, hierarchy = cv.findContours(cut_copy, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
#去掉提取出的第一个轮廓(第一个轮廓为整张图片)
contours.remove(contours[0])
for c in contours:
x, y, w, h = cv.boundingRect(c)
for i in range(h):
for j in range(w):
cut_copy[y + i, x + j] = 0
# cv.rectangle(cut_copy, (x, y), (x + w, y + h), color, 1)
#cv.imshow("cut_copy", cut_copy)
#cv.waitKey(0)
if len(contours) == n:
break
# 上述while()中循环完成后,处理的图像基本满足分割要求,进行最后的提取分割
binary, contours, hierarchy = cv.findContours(cut_copy, cv.RETR_TREE, cv.CHAIN_APPROX_SIMPLE)
contours.remove(contours[0])
color = (0, 0, 0)
for c in contours:
x, y, w, h = cv.boundingRect(c)
for i in range(h):
for j in range(w):
cv.rectangle(cut_copy, (x, y), (x + w, y + h), color, 1)
cv.rectangle(cut_img, (x, y), (x + w, y + h), color, 1)
cv.imshow("Filled image", cut_copy)
cv.waitKey(0)
cv.imshow("cut_img", cut_img)
cv.waitKey(0)
#print('number:', len(contours))
# Returns the result of the split
return contours
#return cut_img
# Sort排序方法,先将图像分割,由于分割的先后顺序不是按照从左往右,根据横坐标大小将每位身份证号码图片进行排序
def sort(contours, image):
tmp_num = []
x_all = []
x_sort = []
for c in contours:
x, y, w, h = cv.boundingRect(c)
# 使用x坐标来确定身份证号码图片的顺序,把个图片坐标的x值放入x_sort中
x_sort.append(x)
# 建立一个用于索引x坐标的列表
x_all.append(x)
tmp_img = image[y+1:y+h-1, x+1:x+w-1]
tmp_img = cv.resize(tmp_img, (40, 60))
cv.imshow("Number", tmp_img)
cv.waitKey(0)
# 将分割的图片缩小至12乘18像素的大小,标准化同时节约模板匹配的时间
tmp_img = cv.resize(tmp_img, (12, 18))
tmp_num.append(tmp_img)
# 利用x_sort排序,用x_all索引,对身份证号码图片排序
x_sort.sort()
num_img = []
for x in x_sort:
index = x_all.index(x)
num_img.append(tmp_num[index])
# 返回排序后图片列表
return num_img
# 图像识别方法
def MatchImage(img_num, tplt_num):
# IDnum用于存储最终的身份证字符串
IDnum = ''
# 身份证号码18位
for i in range(18):
# 存储最大相似度模板的索引以及最大相似度
max_index = 0
max_simil = 0
# 模板有1~9,0,X共11个
for j in range(11):
# 存储身份证号码图片与模板之间的相似度
simil = 0
for y in range(18):
for x in range(12):
# 如果身份证号码图片与模板之间对应位置像素点相同,simil 值自加1
if img_num[i][y,x] == tplt_num[j][y,x]:
simil+=1
if max_simil < simil:
max_index = j
max_simil = simil
print(str(simil)+' ',end='')
if max_index < 9:
IDnum += str(max_index+1)
elif max_index == 9:
IDnum += str(0)
else:
IDnum += 'X'
print()
return IDnum
# 最终效果展示
def display(IDnum, image):
image = cv.resize(image, (960, 90))
plt.figure(num='ID_Number')
plt.subplot(111), plt.imshow(image, cmap='gray'), plt.title(IDnum, fontsize=30), plt.xticks([]), plt.yticks([])
plt.show()
if __name__ == '__main__':
# 一共三张做测试用身份证图像
path = 'IDcard01.jpg'
#path = 'IDcard02.png'
#path = 'IDcard.jpg'
id_card = cv.imread(path, 0)
cv.imshow('Original image', id_card)
cv.waitKey(0)
# 将图像转化成标准大小
id_card = cv.resize(id_card,(1200, 820))
cv.imshow('Enlarged original image', id_card)
cv.waitKey(0)
# 图像二值化
ret, binary_img = cv.threshold(id_card, 127, 255, cv.THRESH_BINARY)
cv.imshow('Binary image', binary_img)
cv.waitKey(0)
# RECTANGULAR
kernel = cv.getStructuringElement(cv.MORPH_RECT, (3, 3))
# RECTANGULAR
kernel2 = cv.getStructuringElement(cv.MORPH_DILATE, (5, 5))
#close_img = cv.morphologyEx(binary_img, cv.MORPH_CLOSE, kernel)
# The corrosion treatment connects the ID Numbers
erode = cv.erode(binary_img, kernel, iterations=10)
cv.imshow('Eroded image', erode)
cv.waitKey(0)
cut_img = Extract(erode, binary_img.copy())
cv.imshow("cut_img", cut_img)
cv.waitKey(0)
# 存储最终分割的轮廓
contours = Segmentation(cut_img, kernel, 18)
# 对图像进行分割并排序
img_num = sort(contours, cut_img)
# 识别用的模板
tplt_path = '/home/image/Pictures/template.jpg'
tplt_img = cv.imread(tplt_path, 0)
#cv.imshow('Template image', tplt_img)
#cv.waitKey(0)
ret, binary_tplt = cv.threshold(tplt_img, 127, 255, cv.THRESH_BINARY)
cv.imshow('Binary template image', binary_tplt)
cv.waitKey(0)
# 与身份证相同的分割方式
contours = Segmentation(binary_tplt, kernel, 11)
tplt_num = sort(contours, binary_tplt)
# 最终识别出的身份证号码
IDnum = MatchImage(img_num, tplt_num)
print('\nID_Number is:', IDnum)
# 图片展示
display(IDnum, cut_img)
效果展示:

到此这篇关于Python+Opencv身份证号码区域提取及识别实现的文章就介绍到这了,更多相关Python+Opencv身份证号码区域提取及识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

基于Python的身份证号码自动生成程序
需求细化: 1.身份证必须能够通过身份证校验程序. 2.通过查询,发现身份证号码是有国家标准的,标准号为 GB 11643-1999 可以从百度下载到这个文档 下载:GB11643-1999sfz(jb51.net).rar 现行身份证号为18位,分别为6位地址码,8位生日,3位顺序码,一位校验码.具体例子可见下图. 前六位也是国家标准,GB2260-2007.吐槽一下,国标竟然没有一个网站供全面检索和免费下载...还好国家统计局有这些公开数据.可以从统计数据->统计标准->行政区划代码页面内
-
使用python代码进行身份证号校验的实现示例
先说,还有很多可以优化的地方. 1.比如加入15位身份证号的校验,嗯哼,15位的好像没有校验,那就只能提取个出生年月日啥的了. 2.比如判断加入地址数据库,增加输出信息 3.增加时间判断,出生日期大于当前时间的判为非法 代码是老师放了一个提取出生年月日的题目扩展过来的,目前来看代码运行正常,有没有bug就不造了. 身份证号校验规则 话说身份证号校验,最重要的肯定是校验.那么如何校验?如何又有15.18位身份证号之分? 1.1999年07月01日以前使用15位身份证号,也就是第一代身份证 2.二代
-
一个计算身份证号码校验位的Python小程序
S = Sum(Ai * Wi), i=0,.......16 (现在的身份证号码都是18位长,其中最后一位是校验位,15位的身份证号码好像不用了) Ai对应身份证号码,Wi则为用于加权计算的值,它一串固定的数值,应该是根据某种规则得出的吧,用于取得最好的随机性,Wi的取之如下: 7 9 10 5 8 4 2 1 6 3 7 9 10 5 8 4 2 经过加权计算之后,得到一个S,用这个S去模11,取余值,然后查表得到校验位,这个索引表如下: 0 ---
-
Python随机生成身份证号码及校验功能
GitHub : https://github.com/jayknoxqu/id-number-util 身份组成方式 中华人民共和国国家标准GB 11643-1999<公民身份号码>中规定:公民身份号码是特征组合码,由十七位数字本体码和一位校验码组成. 18位数字组合的方式是: 1 1 0 1 0 2 Y Y Y Y M M D D 8 8 8 X 区域码(6位) 出生日期码(8位) 顺序码(2位) 性别码(1位) 校验码(1位) 区域码(6位) 出生日期码(8位) 顺序码(2位) 性别码(
-
Python开发之身份证验证库id_validator验证身份证号合法性及根据身份证号返回住址年龄等信息
上个星期,大佬分享了一个验证身份证号合法性的库:id_validator,没空去试着用一下看看,今天有点时间,来试着用下这个库. 1.首先,要安装这个库,windows+R键运行cmd,打开命令行窗口,输入下面的命令: pip install id_validator 2.安装成功后,开始来使用这个库 (1).首先,输入命令 python: (2).接着,引用这个库底下的一个模块,输入命令 from id_validator import validator (3).依次输入下面的命令,来看下校
-
Python实现身份证号码解析
中国的居民身份证有18位.其中前17位是信息码,最后1位是校验码.每位信息码可以是0-9的数字,而校验码可以是0-9或X,其中X表示10. 身份证校验码算法: 设18位身份证号序列从左到右为: 引用 a[0], a[1], a[2], a[3], ..., a[16], a[17] 其中a[i]表示第i位数字,i=0,1,2,...,17,如果最后一位(校验位)是X,则a[17]=10 每一位被赋予一个"权值",其中,第i位的权值w[i]的计算方法是: 引用 w[i] = 2**(17
-
Python+Opencv身份证号码区域提取及识别实现
前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出.现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论.最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^. 实训环境:CentOS-7.5.1804 + Python-3.6.6 + Opencv-3.4.
-
Opencv获取身份证号码区域的示例代码
记得应该是16年的时候,从一个公开课看到了关于OCR方面的内容,里面讲到了通过OpenCV对身份证号码区域的剪裁以及使用Tess-Two进行文字识别,实现了对身份证号码的识别功能. 断断续续看了点关于OpenCV的资料,感觉不是这个专业的真难看懂,各种公式各种名词.今天主要用于做个记录,那个一直碎碎念的东西终于完成了! 原理 我理解的原理(除去文字识别): 对图片进行降噪以及二值化,凸显内容区域 对图片进行轮廓检测 对轮廓结果进行分析 剪裁指定区域 代码实现 本文采用VS2017实现,代码如下:
-
Python+OpenCV感兴趣区域ROI提取方法
方法一:使用轮廓 步骤1 """src为原图""" ROI = np.zeros(src.shape, np.uint8) #感兴趣区域ROI proimage = src.copy() #复制原图 """提取轮廓""" proimage=cv2.cvtColor(proimage,cv2.COLOR_BGR2GRAY) #转换成灰度图 proimage=cv2.adaptiveThre
-
Python+OpenCV图片局部区域像素值处理改进版详解
上个版本的Python OpenCV图片局部区域像素值处理,虽然实现了我需要的功能,但还是走了很多弯路,我意识到图片本就是数组形式,对于8位灰度图,通道数为1,它就是个二位数组,这样就没有必要再设置ROI区域,复制出来这块区域再循环提取像素存入数组进行处理了,可以直接将图片存入数组,再利用numpy进行切分相应的数组操作就可以了,这样一想就简单很多了,这篇我会贴出修改后的代码,直接省去了大段的代码啊. ps:这次我重新装的opencv3.2.0版本,代码里面直接用cv2了 # 查看opencv版
-
python opencv实现目标区域裁剪功能
这个任务是自己在项目中数据处理的一部分内容,待处理的图片如下所示: 我需要将目标区域给裁剪出来,要不然在后期训练网络的时候整幅图像过大,且目标区域过小,得到结果不好,还会加剧计算量.在网上找了各个大佬的博客看,没找到合适的,便自己动手写了,顺便自己的小破站刚搭建起来,记录一下自己的思路. 思路 去寻找目标区域的最左边,最右边,最上面和最下面的像素点,取到坐标信息以后用CV2的裁剪一下就可以实现了. #难点 数据总共是11952张图片,每张图片是1024*768大小的,依次去遍历的话担心太费时间了
-
Python Opencv实战之印章提取的实现
目录 前言 源码展示 效果展示 前言 这期分享的是使用opencv提取印章,很多时候我们需要电子版的章,所以今天就带大家使用代码提取出来! Photoshop虽然强大,但是奈何小编不会使啊,昨天就有一个小伙伴问我能不能帮忙,这不? PS虽然我不会,但是我会写代码呀!这可难不倒我!安排安排~ (特别提醒:所有爱好设计和喜欢做图的小伙伴们,切记千万不要帮着老板或者朋友PS伪造公章,刑法第280条特别指出,伪造证件印章,是可以追究刑事责任的,违法的事情不要做哦.) 源码展示 import cv2 im
-
Python+OpenCV图片局部区域像素值处理详解
背景故事:我需要对一张图片做一些处理,是在图像像素级别上的数值处理,以此来反映图片中特定区域的图像特征,网上查了很多,大多关于opencv的应用教程帖子基本是停留在打开图片,提取像素重新写入图片啊之类的基本操作,我是要取图片中的特定区域再提取它的像素值,作为一个初学者开始接触opencv简直一脸懵,慢慢摸索着知道了opencv的一些函数是可以实现的像SetImageROI()函数设置ROI区域,即感兴趣区域,就很好用啊,总之最后是实现了自己想要的功能.现在看个程序确实是有点挫,也有好多多余的没必
-
Python+OpenCV实现车牌字符分割和识别
最近做一个车牌识别项目,入门级别的,十分简单. 车牌识别总体分成两个大的步骤: 一.车牌定位:从照片中圈出车牌 二.车牌字符识别 这里只说第二个步骤,字符识别包括两个步骤: 1.图像处理 原本的图像每个像素点都是RGB定义的,或者称为有R/G/B三个通道.在这种情况下,很难区分谁是背景,谁是字符,所以需要对图像进行一些处理,把每个RGB定义的像素点都转化成一个bit位(即0-1代码),具体方法如下: ①将图片灰度化 名字拗口,但是意思很好理解,就是把每个像素的RGB都变成灰色的RGB值,而灰色的