在Pytorch中简单使用tensorboard
一、tensorboard的简要介绍
TensorBoard是一个独立的包(不是pytorch中的),这个包的作用就是可视化您模型中的各种参数和结果。
下面是安装:
pip install tensorboard
安装 TensorBoard 后,这些实用程序使您可以将 PyTorch 模型和指标记录到目录中,以便在 TensorBoard UI 中进行可视化。 PyTorch 模型和张量以及 Caffe2 网络和 Blob 均支持标量,图像,直方图,图形和嵌入可视化。
SummaryWriter 类是您用来记录数据以供 TensorBoard 使用和可视化的主要入口。
看一个例子,在这个例子中,您重点关注代码中的注释部分:
import torch
import torchvision
from torchvision import datasets, transforms
# 可视化工具, SummaryWriter的作用就是,将数据以特定的格式存储到上面得到的那个日志文件夹中
from torch.utils.tensorboard import SummaryWriter
# 第一步:实例化对象。注:不写路径,则默认写入到 ./runs/ 目录
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# 让 ResNet 模型采用灰度而不是 RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
# 第二步:调用对象的方法,给文件夹存数据
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
点击运行之后,我们就可以在文件夹下看到我们保存的数据了,然后我们就可以使用 TensorBoard 对其进行可视化,该 TensorBoard 应该可通过以下方式运行(在命令行):
tensorboard --logdir=runs
运行结果:

把上述的地址,粘贴到浏览器就可以看到可视化的结果了,如下所示:

接着看:
一个实验可以记录很多信息。 为了避免 UI 混乱和更好地将结果聚类,我们可以通过对图进行分层命名来对图进行分组。 例如,“损失/训练”和“损失/测试”将被分组在一起,而“准确性/训练”和“准确性/测试”将在 TensorBoard 界面中分别分组。
我们再看一个更简单的例子来理解上面的话:
from torch.utils.tensorboard import SummaryWriter
import numpy as np
# 第一步:实例化对象。注:不写参数默认是 ./run/ 文件夹下
writer = SummaryWriter()
for n_iter in range(100):
# 第二步:调用对象的方法,给文件夹存数据
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
writer.close()
点击运行(保存数据); 在命令行输入tensorboard --logdir=run(run是保存的数据的所在路径)
实验结果:

好了,现在你对tensorboard有了初步的认识,也知道了怎么在pytorch中 保存模型在运行过程中的一些数据了,还知道了怎么把tensorboard运行起来了。
但是,我们还没有细讲前面提到的几个函数,因此接下来我们看这几个函数的具体使用。
二、torch.utils.tensorboard涉及的几个函数
2.1 SummaryWriter()类
API:
class torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
作用:将数据保存到 log_dir 文件夹下 以供 TensorBoard 使用。
SummaryWriter 类提供了一个高级 API,用于在给定目录中创建事件文件并向其中添加摘要和事件。 该类异步更新文件内容。 这允许训练程序从训练循环中调用直接将数据添加到文件的方法,而不会减慢训练速度。
下面是SummaryWriter()类的构造函数:
def __init__(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')
作用:创建一个 SummaryWriter 对象,它将事件和摘要写到事件文件中。
参数说明:
log_dir(字符串):保存目录位置。 默认值为 run/CURRENT_DATETIME_HOSTNAME ,每次运行后都会更改。 使用分层文件夹结构可以轻松比较运行情况。 例如 为每个新实验传递“ runs / exp1”,“ runs / exp2”等,以便在它们之间进行比较。comment(字符串):注释 log_dir 后缀附加到默认值log_dir。 如果分配了log_dir,则此参数无效。purge_step(python:int ):当日志记录在步骤 T + X T+X T+X 崩溃并在步骤 T T T 重新启动时,将清除 global_step 大于或等于的所有事件, 隐藏在 TensorBoard 中。 请注意,崩溃的实验和恢复的实验应具有相同的log_dir。max_queue(python:int ):在“添加”调用之一强行刷新到磁盘之前,未决事件和摘要的队列大小。 默认值为十个项目。flush_secs(python:int ):将挂起的事件和摘要刷新到磁盘的频率(以秒为单位)。 默认值为每两分钟一次。filename_suffix(字符串):后缀添加到 log_dir 目录中的所有事件文件名中。 在 tensorboard.summary.writer.event_file_writer.EventFileWriter 中有关文件名构造的更多详细信息。
例子:
from torch.utils.tensorboard import SummaryWriter
# 使用自动生成的文件夹名称创建summary writer
writer = SummaryWriter()
# folder location: runs/May04_22-14-54_s-MacBook-Pro.local/
# 使用指定的文件夹名称创建summary writer
writer = SummaryWriter("my_experiment")
# folder location: my_experiment
# 创建一个附加注释的 summary writer
writer = SummaryWriter(comment="LR_0.1_BATCH_16")
# folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
2.2 add_scalar()函数
API:
add_scalar(tag, scalar_value, global_step=None, walltime=None)
作用:将标量数据添加到summary
参数说明:
tag(string) : 数据标识符scalar_value(float or string/blobname) : 要保存的值global_step(int) :要记录的全局步长值,理解成 x坐标walltime(float):可选,以事件发生后的秒数覆盖默认的 walltime(time.time())
例子:
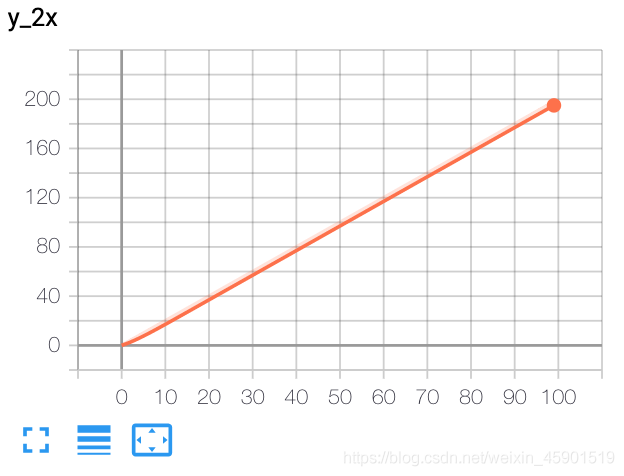
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
x = range(100)
for i in x:
writer.add_scalar('y_2x', i * 2, i)
writer.close()
结果:
2.3 add_scalars()函数
API:
add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)
作用:将许多标量数据添加到 summary 中。
参数说明:
main_tag(string) :标记的父名称tag_scalar_dict(dict) :存储标签和对应值的键值对global_step(int) :要记录的全局步长值walltime(float) :可选的替代默认时间 Walltime(time.time())秒
例子:
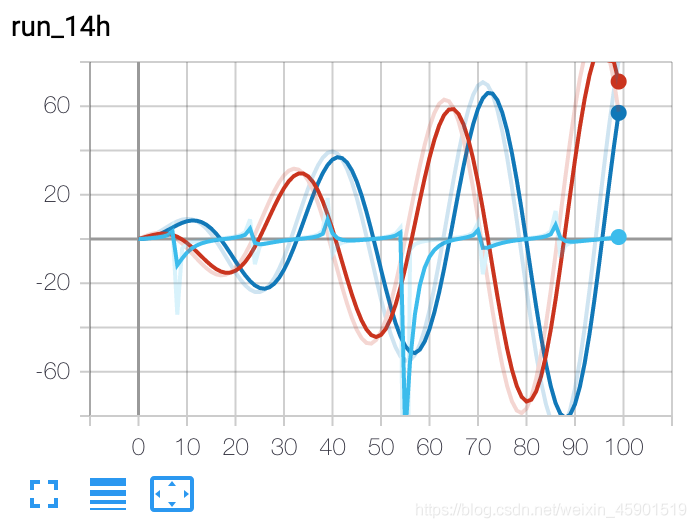
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
r = 5
for i in range(100):
writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r),
'xcosx':i*np.cos(i/r),
'tanx': np.tan(i/r)}, i)
writer.close()
# 此调用将三个值添加到带有标记的同一个标量图中
# 'run_14h' 在 TensorBoard 的标量部分
结果:
2.4 add_histogram()
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
作用:将直方图添加到 summary 中。
参数说明:
tag(string): 数据标识符values(torch.Tensor, numpy.array, or string/blobname) :建立直方图的值global_step(int) :要记录的全局步长值bins(string) : One of {‘tensorflow','auto', ‘fd', …}. 这决定了垃圾箱的制作方式。您可以在以下位置找到其他选项:https://docs.scipy.org/doc/numpy/reference/generated/numpy.histogram.htmlwalltime(float) – Optional override default walltime (time.time()) seconds after epoch of event
例子:
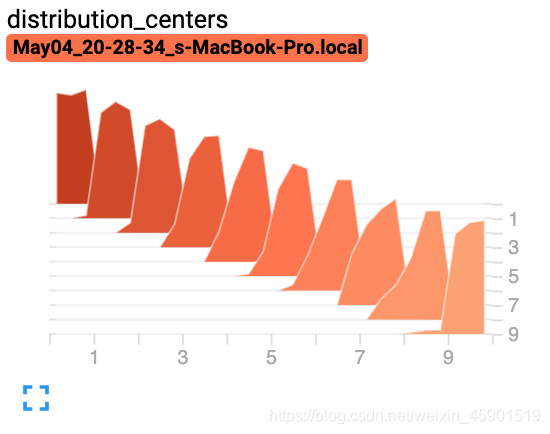
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for i in range(10):
x = np.random.random(1000)
writer.add_histogram('distribution centers', x + i, i)
writer.close()
结果:
我用到了上面的这些,关于更多的函数说明 ,请点击这里查看:https://pytorch.org/docs/stable/tensorboard.html#torch-utils-tensorboard
到此这篇关于在Pytorch中简单使用tensorboard的文章就介绍到这了,更多相关Pytorch使用tensorboard内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch使用tensorboardX进行loss可视化实例
最近pytorch出了visdom,也没有怎么去研究它,主要是觉得tensorboardX已经够用,而且用起来也十分的简单 pip install tensorboardX 然后在代码里导入 from tensorboardX import SummaryWriter 然后声明一下自己将loss写到哪个路径下面 writer = SummaryWriter('./log') 然后就可以愉快的写loss到你得这个writer了 niter = epoch * len(train_loader) +
-

Pytorch中TensorBoard及torchsummary的使用详解
1.TensorBoard神经网络可视化工具 TensorBoard是一个强大的可视化工具,在pytorch中有两种调用方法: 1.from tensorboardX import SummaryWriter 这种方法是在官方还不支持tensorboard时网上有大神写的 2.from torch.utils.tensorboard import SummaryWriter 这种方法是后来更新官方加入的 1.1 调用方法 1.1.1 创建接口SummaryWriter 功能:创建接口 调用方法:
-
在Pytorch中简单使用tensorboard
一.tensorboard的简要介绍 TensorBoard是一个独立的包(不是pytorch中的),这个包的作用就是可视化您模型中的各种参数和结果. 下面是安装: pip install tensorboard 安装 TensorBoard 后,这些实用程序使您可以将 PyTorch 模型和指标记录到目录中,以便在 TensorBoard UI 中进行可视化. PyTorch 模型和张量以及 Caffe2 网络和 Blob 均支持标量,图像,直方图,图形和嵌入可视化. SummaryWrite
-
教你如何在Pytorch中使用TensorBoard
什么是TensorboardX Tensorboard 是 TensorFlow 的一个附加工具,可以记录训练过程的数字.图像等内容,以方便研究人员观察神经网络训练过程.可是对于 PyTorch 等其他神经网络训练框架并没有功能像 Tensorboard 一样全面的类似工具,一些已有的工具功能有限或使用起来比较困难 (tensorboard_logger, visdom等) .TensorboardX 这个工具使得 TensorFlow 外的其他神经网络框架也可以使用到 Tensorboard
-
Pytorch中使用TensorBoard详情
目录 前言 一. Introduction to TensorBoard 二.TensoBoard Pipeline 三.后端数据记录 1. SummaryWriter类 2. 添加数据 3. 关闭SummaryWriter 4. Summary 四.前端显示数据 1. 默认使用 2. 修改端口 五.Summary 1. SummaryWriter APIs 本文记录了如何在Pytorch中使用Tensorboard(主要是为了备忘) 前言 虽然我本身就会用TensorBoard,但是因为Ten
-
Pytorch中的Tensorboard与Transforms搭配使用
这章是结合之前学习的Tensforboard与Transforms的一个练习. 直接上代码: from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms import os root_path = "D:\\data\\basic\\Image" lable_path = "aligned" img_dir = o
-
PyTorch中的torch.cat简单介绍
目录 1.toych简单介绍 2.张量Tensors 3.torch.cat 1.toych简单介绍 包torch包含了多维疑是的数据结构及基于其上的多种数学操作. torch包含了多维张量的数据结构以及基于其上的多种数学运算.此外,它也提供了多种实用工具,其中一些可以更有效地对张量和任意类型进行序列化的工具. 它具有CUDA的对应实现,可以在NVIDIA GPU上进行张量运算(计算能力>=3.0) 2. 张量Tensors torch.is_tensor(obj):如果obj是一个pytorc
-
python神经网络Pytorch中Tensorboard函数使用
目录 所需库的安装 常用函数功能 1.SummaryWriter() 2.writer.add_graph() 3.writer.add_scalar() 4.tensorboard --logdir= 示例代码 所需库的安装 很多人问Pytorch要怎么可视化,于是决定搞一篇. tensorboardX==2.0 tensorflow==1.13.2 由于tensorboard原本是在tensorflow里面用的,所以需要装一个tensorflow.会自带一个tensorboard. 也可以不
-
PyTorch中torch.utils.data.DataLoader简单介绍与使用方法
目录 一.torch.utils.data.DataLoader 简介 二.实例 参考链接 总结 一.torch.utils.data.DataLoader 简介 作用:torch.utils.data.DataLoader 主要是对数据进行 batch 的划分. 数据加载器,结合了数据集和取样器,并且可以提供多个线程处理数据集. 在训练模型时使用到此函数,用来 把训练数据分成多个小组 ,此函数 每次抛出一组数据 .直至把所有的数据都抛出.就是做一个数据的初始化. 好处: 使用DataLoade
-
pytorch中如何使用DataLoader对数据集进行批处理的方法
最近搞了搞minist手写数据集的神经网络搭建,一个数据集里面很多个数据,不能一次喂入,所以需要分成一小块一小块喂入搭建好的网络. pytorch中有很方便的dataloader函数来方便我们进行批处理,做了简单的例子,过程很简单,就像把大象装进冰箱里一共需要几步? 第一步:打开冰箱门. 我们要创建torch能够识别的数据集类型(pytorch中也有很多现成的数据集类型,以后再说). 首先我们建立两个向量X和Y,一个作为输入的数据,一个作为正确的结果: 随后我们需要把X和Y组成一个完整的数据集,
-
pytorch中的embedding词向量的使用方法
Embedding 词嵌入在 pytorch 中非常简单,只需要调用 torch.nn.Embedding(m, n) 就可以了,m 表示单词的总数目,n 表示词嵌入的维度,其实词嵌入就相当于是一个大矩阵,矩阵的每一行表示一个单词. emdedding初始化 默认是随机初始化的 import torch from torch import nn from torch.autograd import Variable # 定义词嵌入 embeds = nn.Embedding(2, 5) # 2