OpenCV Python身份证信息识别过程详解
目录
- 前置环境
- 识别过程
- 身份证区域查找
- 原始图像
- 灰度处理
- 中值滤波
- 二值处理
- 边缘检测
- 边缘膨胀
- 轮廓检测
- 轮廓排序
- 透视变换
- 固定图像大小
- 检测身份证文本位置
- 极度膨胀
- 轮廓查找文本区域
- 筛选出文本区域
- 对文本区域进行排序
- 识别文本
- 结语
- 代码
本篇文章使用OpenCV-Python和CnOcr来实现身份证信息识别的案例。想要识别身份证中的文本信息,总共分为三大步骤:一、通过预处理身份证区域检测查找;二、身份证文本信息提取;三、身份证文本信息识别。下面来看一下识别的具体过程CnOcr官网。识别过程视频
前置环境
这里的环境需要安装OpenCV-Python,Numpy和CnOcr。本篇文章使用的Python版本为3.6,OpenCV-Python版本为3.4.1.15,如果是4.x版本的同学,可能会有一些Api操作不同。这些依赖的安装和介绍,我就不在这里赘述了,均是使用Pip进行安装。
识别过程
首先,导入所需要的依赖cv2,numpy,cnocr并创建一个show图像的函数,方便后面使用:
import cv2
import numpy as np
from cnocr import CnOcr
def show(image, window_name):
cv2.namedWindow(window_name, 0)
cv2.imshow(window_name, image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 加载CnOcr的模型
ocr = CnOcr(model_name='densenet_lite_136-gru')
身份证区域查找
通过对加载图像的灰度处理–>滤波处理–>二值处理–>边缘检测–>膨胀处理–>轮廓查找–>透视变换(校正)–>图像旋转–>固定图像大小一系列处理之后,我们便可以清晰的裁剪出身份证的具体区域。
原始图像
使用OpenCV的imread方法读取本地图片。
image = cv2.imread('card.png')
show(image, "image")

灰度处理
将三通道BGR图像转化为灰度图像,因为一下OpenCV操作都是需要基于灰度图像进行的。
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) show(gray, "gray")

中值滤波
使用滤波处理,也就是模糊处理,这样可以减少一些不需要的噪点。
blur = cv2.medianBlur(gray, 7) show(blur, "blur")

二值处理
二值处理,非黑即白。这里通过cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU,使用OpenCV的大津法二值化,对图像进行处理,经过处理后的图像,更加清晰的分辨出了背景和身份证的区域。
threshold = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1] show(threshold, "threshold")

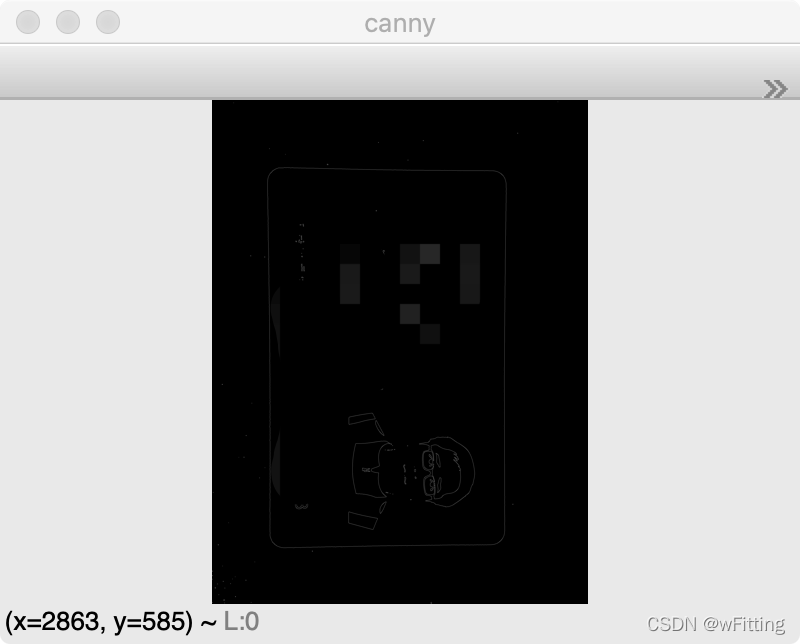
边缘检测
使用OpenCV中最常用的边缘检测方法,Canny,检测出图像中的边缘。
canny = cv2.Canny(threshold, 100, 150) show(canny, "canny")
边缘膨胀
为了使上一步边缘检测的边缘更加连贯,使用膨胀处理,对白色的边缘膨胀,即边缘线条变得更加粗一些。
kernel = np.ones((3, 3), np.uint8) dilate = cv2.dilate(canny, kernel, iterations=5) show(dilate, "dilate")

轮廓检测
使用findContours对边缘膨胀过的图片进行轮廓检测,可以清晰的看到背景部分还是有很多噪点的,所需要识别的身份证部分也被轮廓圈了起来。
binary, contours, hierarchy = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) image_copy = image.copy() res = cv2.drawContours(image_copy, contours, -1, (255, 0, 0), 20) show(res, "res")

轮廓排序
经过对轮廓的面积排序,我们可以准确的提取出身份证的轮廓。
contours = sorted(contours, key=cv2.contourArea, reverse=True)[0] image_copy = image.copy() res = cv2.drawContours(image_copy, contours, -1, (255, 0, 0), 20) show(res, "contours")

透视变换
通过对轮廓近似提取出轮廓的四个顶点,并按顺序进行排序,之后通过warpPerspective对所选图像区域进行透视变换,也就是对所选的图像进行校正处理。
epsilon = 0.02 * cv2.arcLength(contours, True)
approx = cv2.approxPolyDP(contours, epsilon, True)
n = []
for x, y in zip(approx[:, 0, 0], approx[:, 0, 1]):
n.append((x, y))
n = sorted(n)
sort_point = []
n_point1 = n[:2]
n_point1.sort(key=lambda x: x[1])
sort_point.extend(n_point1)
n_point2 = n[2:4]
n_point2.sort(key=lambda x: x[1])
n_point2.reverse()
sort_point.extend(n_point2)
p1 = np.array(sort_point, dtype=np.float32)
h = sort_point[1][1] - sort_point[0][1]
w = sort_point[2][0] - sort_point[1][0]
pts2 = np.array([[0, 0], [0, h], [w, h], [w, 0]], dtype=np.float32)
# 生成变换矩阵
M = cv2.getPerspectiveTransform(p1, pts2)
# 进行透视变换
dst = cv2.warpPerspective(image, M, (w, h))
# print(dst.shape)
show(dst, "dst")

固定图像大小
将图像变正,通过对图像的宽高进行判断,如果宽<高,就将图像旋转90°。并将图像resize到指定大小。方便之后对图像进行处理。
if w < h:
dst = np.rot90(dst)
resize = cv2.resize(dst, (1084, 669), interpolation=cv2.INTER_AREA)
show(resize, "resize")

检测身份证文本位置
经过灰度,二值滤波和开闭运算后,将图像中的文本区域主键显现出来。
temp_image = resize.copy() gray = cv2.cvtColor(resize, cv2.COLOR_BGR2GRAY) show(gray, "gray") threshold = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1] show(threshold, "threshold") blur = cv2.medianBlur(threshold, 5) show(blur, "blur") kernel = np.ones((3, 3), np.uint8) morph_open = cv2.morphologyEx(blur, cv2.MORPH_OPEN, kernel) show(morph_open, "morph_open")

极度膨胀
给定一个比较大的卷积盒,进行膨胀处理,使白色的区域加深加大。更加显现出文本的区域。
kernel = np.ones((7, 7), np.uint8) dilate = cv2.dilate(morph_open, kernel, iterations=6) show(dilate, "dilate")

轮廓查找文本区域
使用轮廓查找,将白色块状区域查找出来。
binary, contours, hierarchy = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) resize_copy = resize.copy() res = cv2.drawContours(resize_copy, contours, -1, (255, 0, 0), 2) show(res, "res")

筛选出文本区域
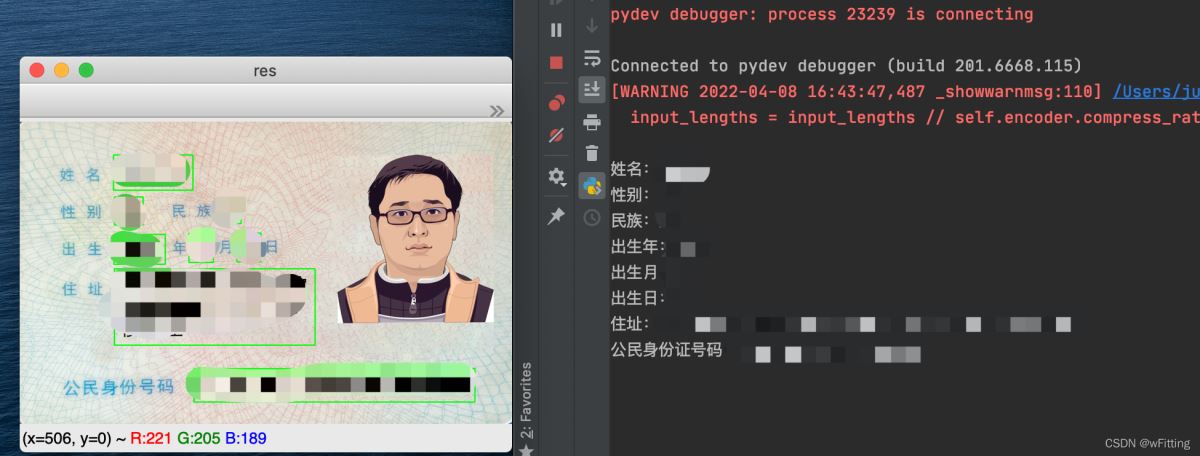
经过上一步轮廓检测,我们发现,选中的轮廓中有一些噪点,通过对图像的观察,使用近似轮廓,然后用以下逻辑筛选出文本区域。并定义文本描述信息,将文本区域位置信息加入到指定集合中。到这一步,可以清晰的看到,所需要的文本区域统统都被提取了出来。
labels = ['姓名', '性别', '民族', '出生年', '出生月', '出生日', '住址', '公民身份证号码']
positions = []
data_areas = {}
resize_copy = resize.copy()
for contour in contours:
epsilon = 0.002 * cv2.arcLength(contour, True)
approx = cv2.approxPolyDP(contour, epsilon, True)
x, y, w, h = cv2.boundingRect(approx)
if h > 50 and x < 670:
res = cv2.rectangle(resize_copy, (x, y), (x + w, y + h), (0, 255, 0), 2)
area = gray[y:(y + h), x:(x + w)]
blur = cv2.medianBlur(area, 3)
data_area = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
positions.append((x, y))
data_areas['{}-{}'.format(x, y)] = data_area
show(res, "res")

对文本区域进行排序
发现文本的区域是由下到上的顺序,并且x轴从左到右的的区域是无序的,所以使用以下逻辑,对文本区域进行排序
positions.sort(key=lambda p: p[1])
result = []
index = 0
while index < len(positions) - 1:
if positions[index + 1][1] - positions[index][1] < 10:
temp_list = [positions[index + 1], positions[index]]
for i in range(index + 1, len(positions)):
if positions[i + 1][1] - positions[i][1] < 10:
temp_list.append(positions[i + 1])
else:
break
temp_list.sort(key=lambda p: p[0])
positions[index:(index + len(temp_list))] = temp_list
index = index + len(temp_list) - 1
else:
index += 1
识别文本
对文本区域使用CnOcr一一进行识别,最后将识别结果进行输出。
positions.sort(key=lambda p: p[1])
result = []
index = 0
while index < len(positions) - 1:
if positions[index + 1][1] - positions[index][1] < 10:
temp_list = [positions[index + 1], positions[index]]
for i in range(index + 1, len(positions)):
if positions[i + 1][1] - positions[i][1] < 10:
temp_list.append(positions[i + 1])
else:
break
temp_list.sort(key=lambda p: p[0])
positions[index:(index + len(temp_list))] = temp_list
index = index + len(temp_list) - 1
else:
index += 1
结语
通过以上的步骤,便成功的将身份证信息进行了提取,过程中的一些数字参数,可能会在不同的场景中有些许的调整。
以下放上所有的代码:
代码
import cv2
import numpy as np
from cnocr import CnOcr
def show(image, window_name):
cv2.namedWindow(window_name, 0)
cv2.imshow(window_name, image)
# 0任意键终止窗口
cv2.waitKey(0)
cv2.destroyAllWindows()
ocr = CnOcr(model_name='densenet_lite_136-gru')
image = cv2.imread('card.png')
show(image, "image")
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
show(gray, "gray")
blur = cv2.medianBlur(gray, 7)
show(blur, "blur")
threshold = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
show(threshold, "threshold")
canny = cv2.Canny(threshold, 100, 150)
show(canny, "canny")
kernel = np.ones((3, 3), np.uint8)
dilate = cv2.dilate(canny, kernel, iterations=5)
show(dilate, "dilate")
binary, contours, hierarchy = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
image_copy = image.copy()
res = cv2.drawContours(image_copy, contours, -1, (255, 0, 0), 20)
show(res, "res")
contours = sorted(contours, key=cv2.contourArea, reverse=True)[0]
image_copy = image.copy()
res = cv2.drawContours(image_copy, contours, -1, (255, 0, 0), 20)
show(res, "contours")
epsilon = 0.02 * cv2.arcLength(contours, True)
approx = cv2.approxPolyDP(contours, epsilon, True)
n = []
for x, y in zip(approx[:, 0, 0], approx[:, 0, 1]):
n.append((x, y))
n = sorted(n)
sort_point = []
n_point1 = n[:2]
n_point1.sort(key=lambda x: x[1])
sort_point.extend(n_point1)
n_point2 = n[2:4]
n_point2.sort(key=lambda x: x[1])
n_point2.reverse()
sort_point.extend(n_point2)
p1 = np.array(sort_point, dtype=np.float32)
h = sort_point[1][1] - sort_point[0][1]
w = sort_point[2][0] - sort_point[1][0]
pts2 = np.array([[0, 0], [0, h], [w, h], [w, 0]], dtype=np.float32)
M = cv2.getPerspectiveTransform(p1, pts2)
dst = cv2.warpPerspective(image, M, (w, h))
# print(dst.shape)
show(dst, "dst")
if w < h:
dst = np.rot90(dst)
resize = cv2.resize(dst, (1084, 669), interpolation=cv2.INTER_AREA)
show(resize, "resize")
temp_image = resize.copy()
gray = cv2.cvtColor(resize, cv2.COLOR_BGR2GRAY)
show(gray, "gray")
threshold = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
show(threshold, "threshold")
blur = cv2.medianBlur(threshold, 5)
show(blur, "blur")
kernel = np.ones((3, 3), np.uint8)
morph_open = cv2.morphologyEx(blur, cv2.MORPH_OPEN, kernel)
show(morph_open, "morph_open")
kernel = np.ones((7, 7), np.uint8)
dilate = cv2.dilate(morph_open, kernel, iterations=6)
show(dilate, "dilate")
binary, contours, hierarchy = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
resize_copy = resize.copy()
res = cv2.drawContours(resize_copy, contours, -1, (255, 0, 0), 2)
show(res, "res")
labels = ['姓名', '性别', '民族', '出生年', '出生月', '出生日', '住址', '公民身份证号码']
positions = []
data_areas = {}
resize_copy = resize.copy()
for contour in contours:
epsilon = 0.002 * cv2.arcLength(contour, True)
approx = cv2.approxPolyDP(contour, epsilon, True)
x, y, w, h = cv2.boundingRect(approx)
if h > 50 and x < 670:
res = cv2.rectangle(resize_copy, (x, y), (x + w, y + h), (0, 255, 0), 2)
area = gray[y:(y + h), x:(x + w)]
blur = cv2.medianBlur(area, 3)
data_area = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
positions.append((x, y))
data_areas['{}-{}'.format(x, y)] = data_area
show(res, "res")
positions.sort(key=lambda p: p[1])
result = []
index = 0
while index < len(positions) - 1:
if positions[index + 1][1] - positions[index][1] < 10:
temp_list = [positions[index + 1], positions[index]]
for i in range(index + 1, len(positions)):
if positions[i + 1][1] - positions[i][1] < 10:
temp_list.append(positions[i + 1])
else:
break
temp_list.sort(key=lambda p: p[0])
positions[index:(index + len(temp_list))] = temp_list
index = index + len(temp_list) - 1
else:
index += 1
for index in range(len(positions)):
position = positions[index]
data_area = data_areas['{}-{}'.format(position[0], position[1])]
ocr_data = ocr.ocr(data_area)
ocr_result = ''.join([''.join(result[0]) for result in ocr_data]).replace(' ', '')
# print('{}:{}'.format(labels[index], ocr_result))
result.append('{}:{}'.format(labels[index], ocr_result))
show(data_area, "data_area")
for item in result:
print(item)
show(res, "res")
到此这篇关于OpenCV Python身份证信息识别的文章就介绍到这了,更多相关Python身份证信息识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python+Opencv身份证号码区域提取及识别实现
前端时间智能信息处理实训,我选择的课题为身份证号码识别,对中华人民共和国公民身份证进行识别,提取并识别其中的身份证号码,将身份证号码识别为字符串的形式输出.现在实训结束了将代码发布出来供大家参考,识别的方式并不复杂,并加了一些注释,如果有什么问题可共同讨论.最后重要的事情说三遍:请勿直接抄袭,请勿直接抄袭,请勿直接抄袭!尤其是我的学弟学妹们,还是要自己做的,小心直接拿我的用被老师发现了挨批^_^. 实训环境:CentOS-7.5.1804 + Python-3.6.6 + Opencv-3.4.
-
基于Python的身份证验证识别和数据处理详解
根据GB11643-1999公民身份证号码是特征组合码,由十七位数字本体码和一位数字校验码组成,排列顺序从左至右依次为: 六位数字地址码八位数字出生日期码三位数字顺序码一位数字校验码(数字10用罗马X表示) 校验系统: 校验码采用ISO7064:1983,MOD11-2校验码系统(图为校验规则样例) 用身份证号的前17位的每一位号码字符值分别乘上对应的加权因子值,得到的结果求和后对11进行取余,最后的结果放到表2检验码字符值..换算关系表中得出最后的一位身份证号码 代码: # coding=ut
-

用Python识别人脸,人种等各种信息
最近几天了解了一下人脸识别,应用场景可以是图片标注,商品图和广告图中有没有模特,有几个模特,模特的性别,年龄,颜值,表情等数据的挖掘. 基础的识别用dlib来实现,dlib是一个机器学习的包,主要用C++写的,但是也有Python版本.其中最流行的一个功能是Facial Landmark Detection, 配备已经训练好的轮廓预测模型,叫shape_predictor_68_face_landmarks.dat, 从名字就可以看出,它可以检测出面部的68个关键点,包括五官和外轮廓等. 安装d
-
Python调用百度AI实现身份证识别
目录 一.安装baidu-aip模块 二.获取百度AI接口密钥 三.调用百度接口识别身份证 一.安装baidu-aip模块 按win+R打开cmd,在里面输入 pip3 install baidu-aip 若出现如下界面,即成功安装了baidu-aip模块: 如果想快速了解识别营业执照代码原理,可以跳过第二部分,先看第三部分的内容. 二.获取百度AI接口密钥 在应用python识别身份证的过程中,有三行代码使用了百度AI接口密钥,故先阐述如何获得该密钥.首先,进入如下百度AI官方网站:https
-
Python中AI图像识别实现身份证识别
目录 需求分析 步骤 申请华为云OCR接口 获取token 调用身份证识别接口 总结 图像识别说白了就是把一张照片上面的文字进行提取,提供工作效率 需求分析 身份证识别主要是把一张身份证照片上面的文字信息进行提取,不用再使用人工去手动抄写了,下面给大家说的这个身份识别主要是使用python+flask+华为云OCR进行实现的. 步骤 申请华为云OCR接口 获取token 调用身份证识别接口 提取身份证信息 申请华为云OCR接口 图像识别主要使用的就是华为云OCR平台申请的接口,申请地址为:"ht
-
OpenCV Python身份证信息识别过程详解
目录 前置环境 识别过程 身份证区域查找 原始图像 灰度处理 中值滤波 二值处理 边缘检测 边缘膨胀 轮廓检测 轮廓排序 透视变换 固定图像大小 检测身份证文本位置 极度膨胀 轮廓查找文本区域 筛选出文本区域 对文本区域进行排序 识别文本 结语 代码 本篇文章使用OpenCV-Python和CnOcr来实现身份证信息识别的案例.想要识别身份证中的文本信息,总共分为三大步骤:一.通过预处理身份证区域检测查找:二.身份证文本信息提取:三.身份证文本信息识别.下面来看一下识别的具体过程CnOcr官网.
-
Opencv创建车牌图片识别系统方法详解
目录 前言 包含功能 软件版本 软件架构 参考文档 效果图展示 车牌检测过程 图片车牌文字识别过程 部分核心代码 前言 这是一个基于spring boot + maven + opencv 实现的图像识别及训练的Demo项目 包含车牌识别.人脸识别等功能,贯穿样本处理.模型训练.图像处理.对象检测.对象识别等技术点 java语言的深度学习项目,在整个开源社区来说都相对较少: 拥有完整的训练过程.检测.识别过程的开源项目更是少之又少!! 包含功能 蓝.绿.黄车牌检测及车牌号码识别 网上常见的轮廓提
-
Android4.X中SIM卡信息初始化过程详解
本文实例讲述了Android4.X中SIM卡信息初始化过程详解.分享给大家供大家参考,具体如下: Phone 对象初始化的过程中,会加载SIM卡的部分数据信息,这些信息会保存在IccRecords 和 AdnRecordCache 中.SIM卡的数据信息的初始化过程主要分为如下几个步骤 1.RIL 和 UiccController 建立监听关系 ,SIM卡状态发生变化时,UiccController 第一个去处理. Phone 应用初始化 Phone 对象时会建立一个 RIL 和UiccCont
-
基于python实现雪花算法过程详解
这篇文章主要介绍了基于python实现雪花算法过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Snowflake是Twitter提出来的一个算法,其目的是生成一个64bit的整数: 1bit:一般是符号位,不做处理 41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了. 10bit:10bit用来记录机器ID
-
Python读取YAML文件过程详解
这篇文章主要介绍了Python读取YAML文件过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 YAML语法 学习手册 Python读取方法: import yaml with open('demo1.yaml', 'r', encoding='utf-8') as f: file_content = f.read() content = yaml.load(file_content, yaml.FullLoader) print(con
-
Python守护进程实现过程详解
这篇文章主要介绍了Python守护进程实现过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 如果你设置一个线程为守护线程,就表示你在说这个线程是不重要的,在进程退出的时候,不用等待这个线程退出.如果你的主线程在退出的时候,不用等待那些子线程完成,那就设置这些线程的daemon属性.即在线程开始(thread.start())之前,调用setDeamon()函数,设定线程的daemon标志.(thread.setDaemon(True))就
-
Python基于Opencv来快速实现人脸识别过程详解(完整版)
前言 随着人工智能的日益火热,计算机视觉领域发展迅速,尤其在人脸识别或物体检测方向更为广泛,今天就为大家带来最基础的人脸识别基础,从一个个函数开始走进这个奥妙的世界. 首先看一下本实验需要的数据集,为了简便我们只进行两个人的识别,选取了beyond乐队的主唱黄家驹和贝斯手黄家强,这哥俩长得有几分神似,这也是对人脸识别的一个考验: 两个文件夹,一个为训练数据集,一个为测试数据集,训练数据集中有两个文件夹0和1,之前看一些资料有说这里要遵循"slabel"命名规则,但后面处理起来比较麻烦,
-
python使用selenium打开chrome浏览器时带用户登录信息实现过程详解
导读 我们在使用selenium打开google浏览器的时候,默认打开的是一个新的浏览器窗口,而且里面不带有任何的浏览器缓存信息.当我们想要爬取某个网站信息或者做某些操作的时候就需要自己再去模拟登陆 selenium操作浏览器 这里我们就以CSDN为例,来展示如何让selenium在打开chrome浏览器的时候带上用户的登录信息 打开chrome浏览器 from selenium import webdriver from selenium.webdriver import ChromeOpti
-
Java OpenCV实现人脸识别过程详解
准备 : 下载openCV安装包 : https://opencv.org/ 安装包安装之后支持多种语言环境,此处使用Java,在Eclipse中引入 openCV目录下的java/opencv-320.jar,同时配置openCV库路径. Eclipse配置openCV 代码实现 : package test; import org.opencv.core.Core; import org.opencv.core.Mat; import org.opencv.core.MatOfRect;
-
如何用Python破解wifi密码过程详解
前言 Python真的是无所不能,原因就是因为Python有数目庞大的库,无数的现成的轮子,让你做很多很多应用都非常方便.wifi跟我们的生活息息相关,无处不在.今天从WiFi连接的原理,再结合代码为大家详细的出一期关于Python破译wifi密码的Python学习教程! 01.如何连接wifi 首先我们的电脑是如何连接wifi的呢?就拿我们的笔记本电脑来说,我们的笔记本电脑都有无线网卡,如下图所示: 当我们连接WiFi时,无线网卡会自动帮助我们扫描附近的WiFi信号,并且会返回WiFi信号的一