Datawhale练习之二手车价格预测
数据探索性分析(EDA)
1. 总览数据概况
数据库载入
#coding:utf-8
#导入warnings包,利用过滤器来实现忽略警告语句。
import warnings
warnings.filterwarnings('ignore')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import missingno as msno
数据载入
## 1) 载入训练集和测试集; path = './' Train_data = pd.read_csv(path+'car_train_0110.csv', sep=' ') Test_data = pd.read_csv(path+'car_testA_0110.csv', sep=' ')
确定path,如果是在notebook环境,我通常使用 !dir查看当前目录
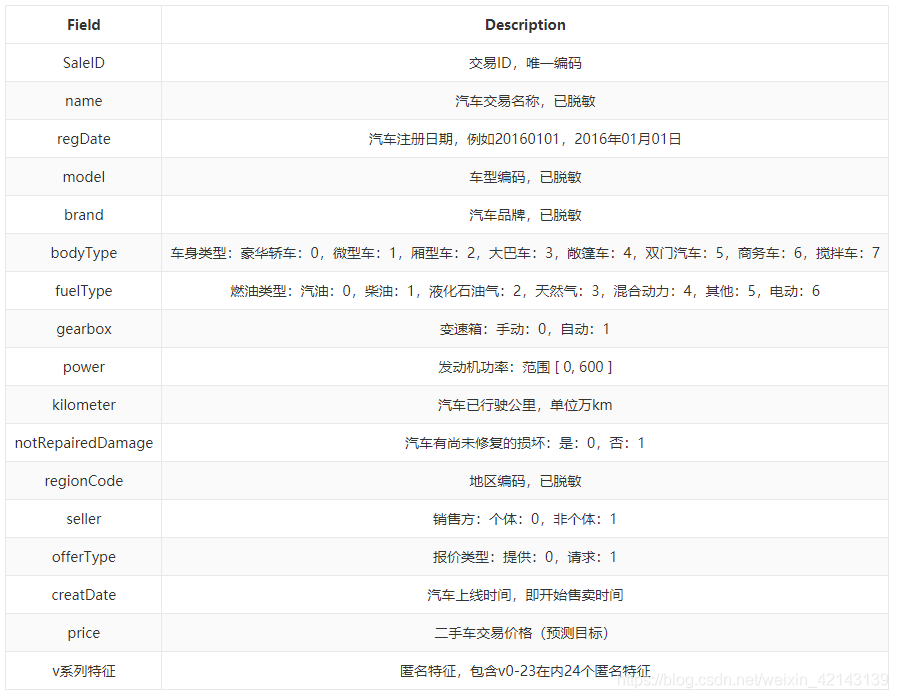
特征说明
新技能:使用.append()同时观察前5行与后5行
## 2) 简略观察数据(head()+shape) Train_data.head().append(Train_data.tail())
观察数据维度
Train_data.shape,Test_data.shape
总览概况: .describe()查看统计量,.info()查看数据类型
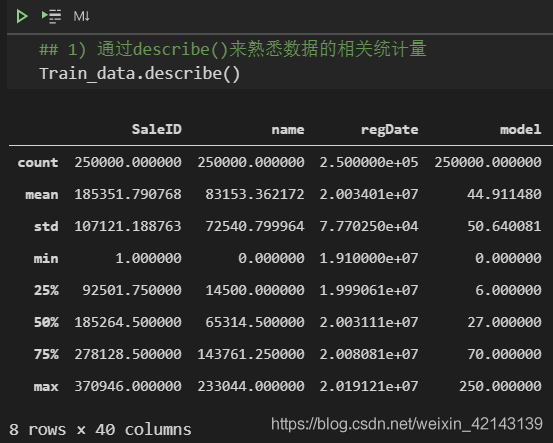
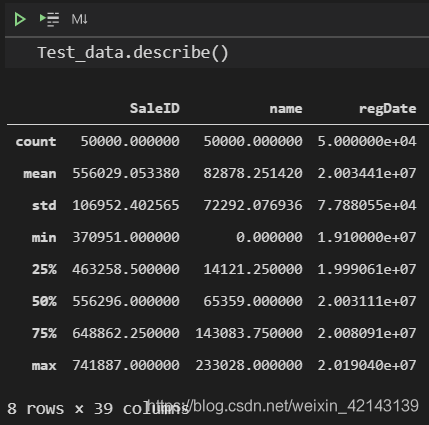
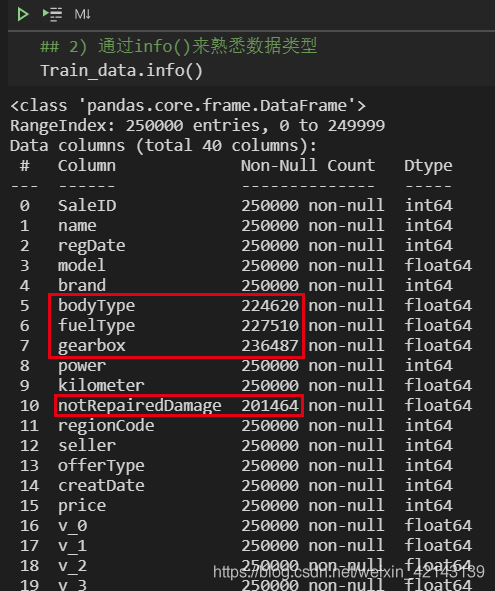
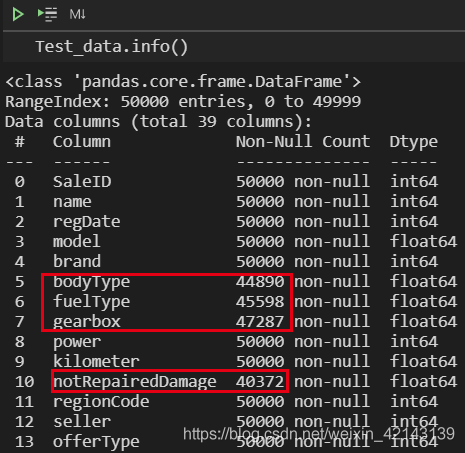
1.1 判断数据缺失和异常
1.1.1 查看nan
Train_data.shape,Test_data.shape
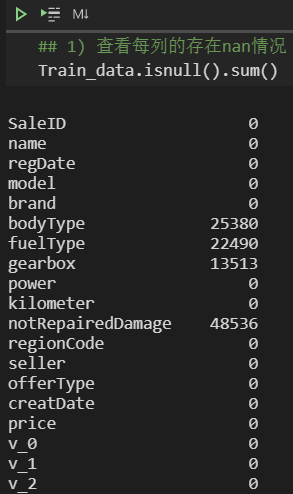
也可直接查看nan,有以下两种方式 ↓ :
Train_data.isnull().sum()
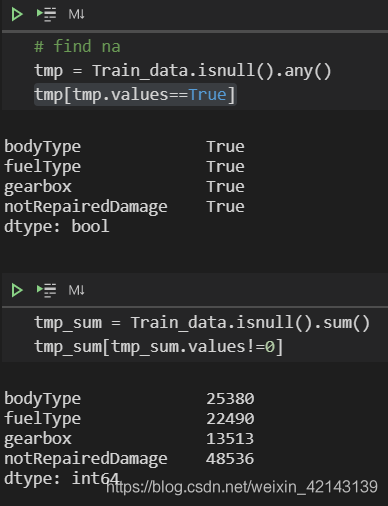
可视化na更直观
# find na tmp = df_train.isnull().any() tmp[tmp.values==True]
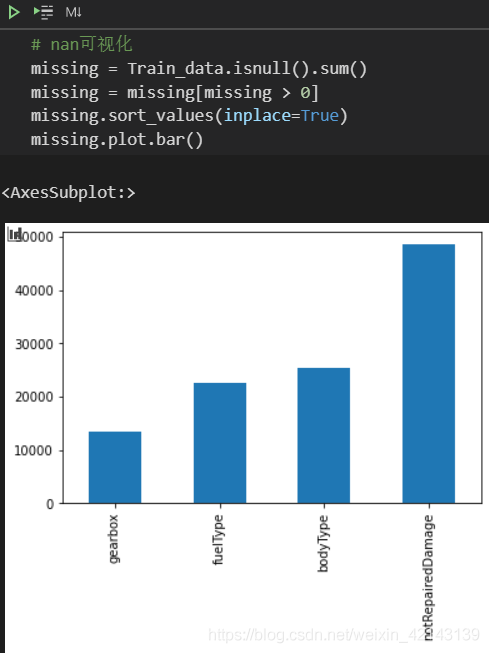
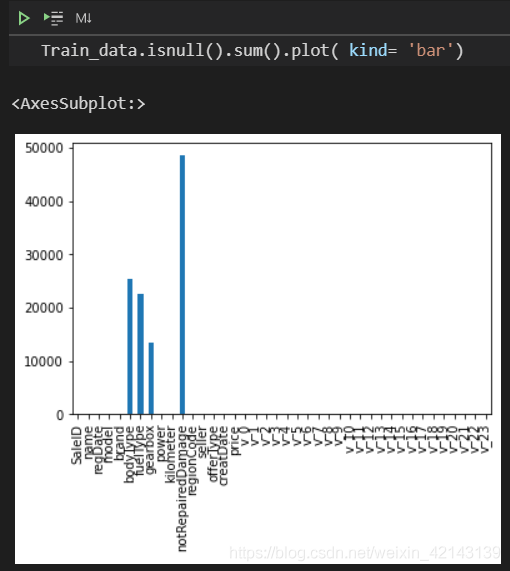
新技能: msno库(缺失值可视化)的使用
Train_data.isnull().sum().plot( kind= 'bar')
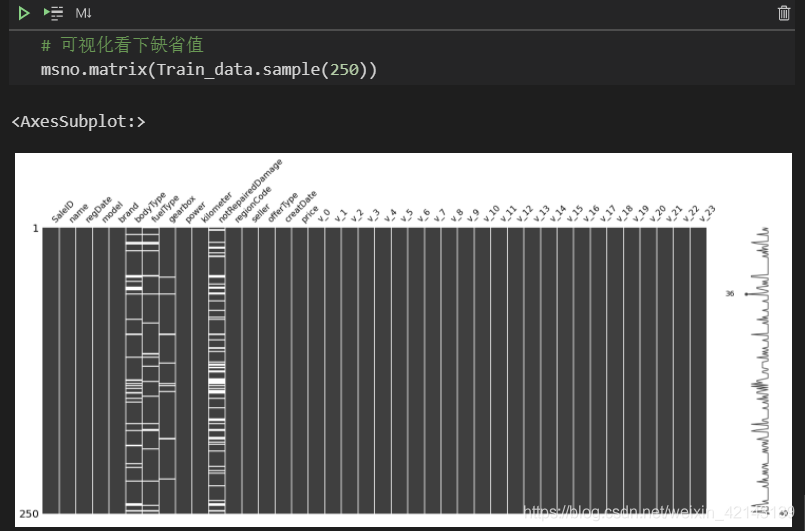
可视化看下缺省值
msno.matrix(Train_data.sample(250))
其中,Train_data.sample(250)表示随机抽样250行,白色条纹表示缺失
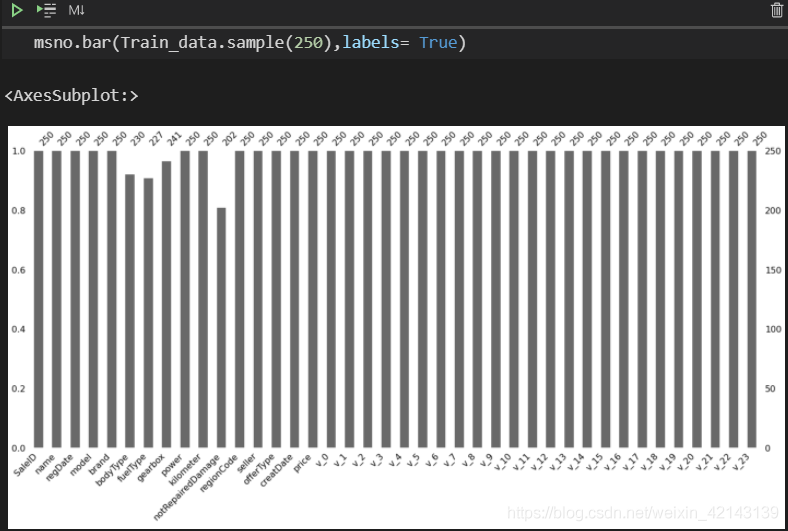
直接显示未缺失的样本数量/每特征
msno.bar(Train_data.sample(250),labels= True)
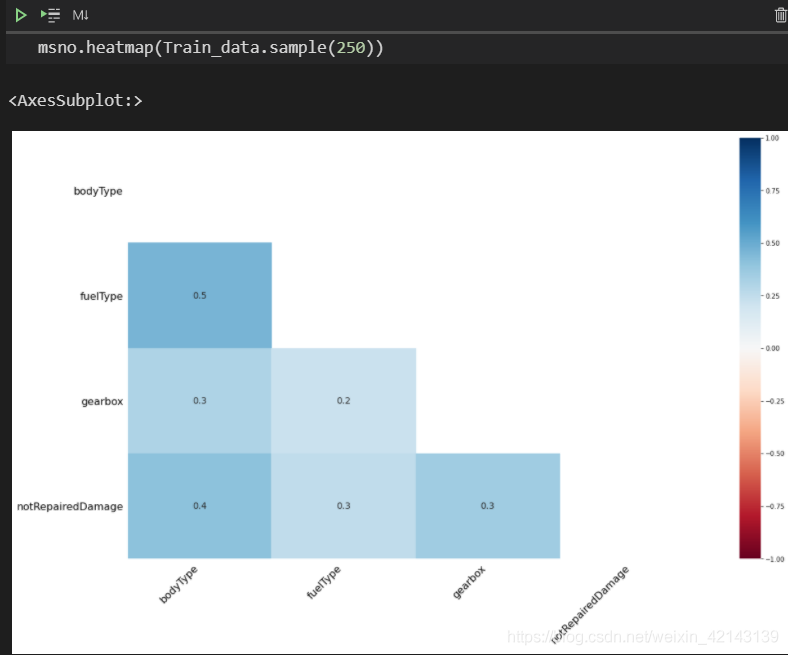
使用msno中的 .heatmap()查看缺失值之间的相关性
msno.heatmap(Train_data.sample(250))
1.1.2 *异常值检测(重要!易忽略)
通过Train_data.info()了解数据类型
Train_data.info()
1.2 了解预测值的分布
特征分为类别特征和数字特征
查看分布的意义在于:
a. 及时将非正态分布数据变化为正态分布数据
b. 异常检测
1.2.1 数字特征分析
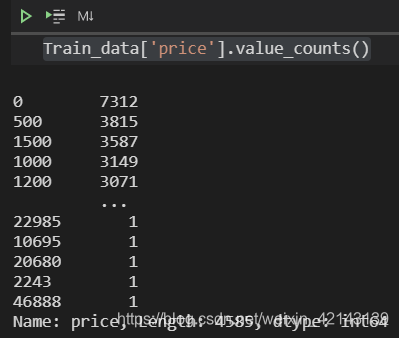
Train_data['price']
发现都是int
统计分布 ↓
Train_data['price'].value_counts()
## 1) 总体分布概况(无界约翰逊分布等)
import scipy.stats as st
y = Train_data['price']
plt.figure(1); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=st.johnsonsu)
plt.figure(2); plt.title('Normal')
sns.distplot(y, kde=False, fit=st.norm)
plt.figure(3); plt.title('Log Normal')
sns.distplot(y, kde=False, fit=st.lognorm)
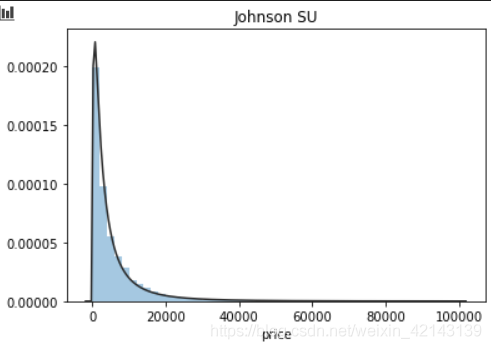
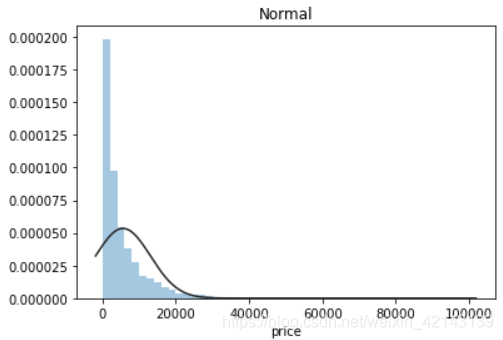
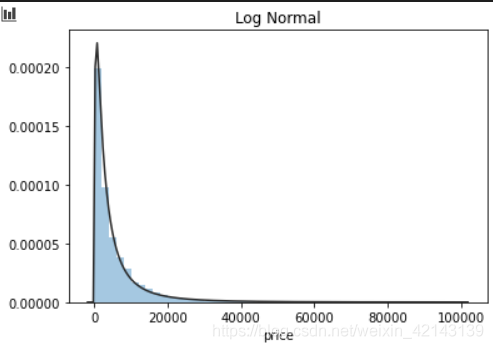
结论:price不服从正态分布,因此在进行回归之前,它必须进行转换。无界约翰逊分布拟合效果较好。
1.2.1.1 相关性分析
1.2.1.2 *偏度和峰值
偏度(skewness),统计数据分布偏斜方向和程度,是统计数据分布非对称程度的数字特征。定义上偏度是样本的三阶标准化矩。
峰度(peakedness;kurtosis)又称峰态系数。表征概率密度分布曲线在平均值处峰值高低的特征数。直观看来,峰度反映了峰部的尖度。
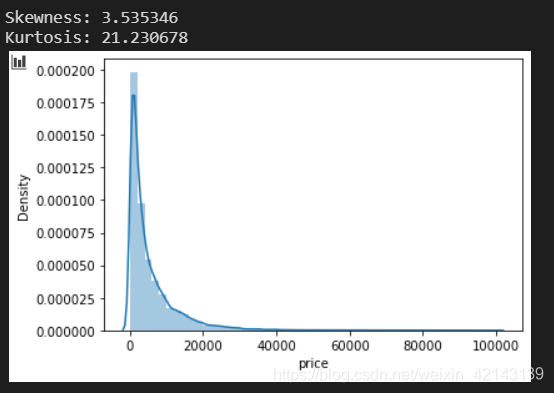
## 2) 查看skewness and kurtosis
sns.distplot(Train_data['price']);
print("Skewness: %f" % Train_data['price'].skew())
print("Kurtosis: %f" % Train_data['price'].kurt())
批量计算skew
Train_data.skew()
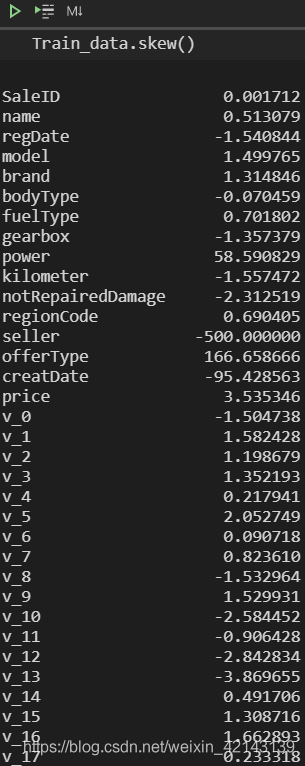
查看skew的分布情况
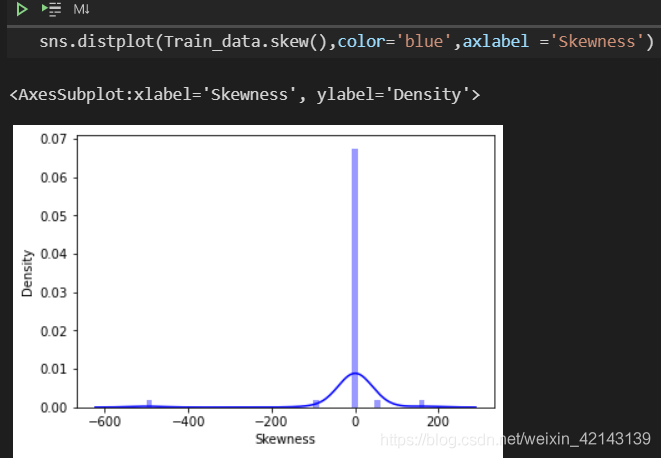
批量计算kurt
Train_data.kurt()
查看kurt的分布情况
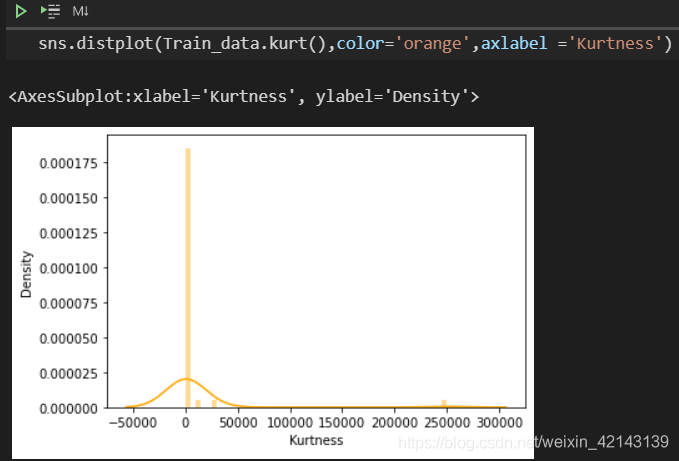
查看目标变量的分布
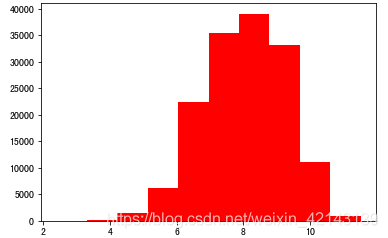
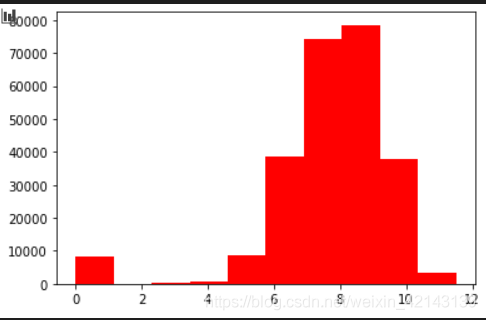
## 3) 查看预测值的具体频数 plt.hist(Train_data['price'], orientation = 'vertical',histtype = 'bar', color ='red') plt.show()

结论:大于20000得值极少,其实这里也可以把这些当作特殊得值(异常值)直接用填充或者删掉
由于np.log(0)==-inf,无法绘图,因此改用log(1+x)绘制分布bar,和教程里有出入,教程里用log绘图如下:(我画不出来,因为-inf会报错)
# log变换之后的分布较均匀,可以进行log变换进行预测,这也是预测问题常用的trick plt.hist(np.log(1+Train_data['price']), orientation = 'vertical',histtype = 'bar', color ='red') plt.show()
分离label即预测值
Y_train = Train_data['price']
#这个区别方式适用于没有直接label coding的数据
#这里不适用,需要人为根据实际含义来区分
#数字特征
numeric_features = Train_data.select_dtypes(include=[np.number])
numeric_features.columns
#类型特征
categorical_features = Train_data.select_dtypes(include=[np.object])
categorical_features.columns
numeric_features = ['power', 'kilometer', 'v_0', 'v_1', 'v_2', 'v_3', 'v_4', 'v_5', 'v_6', 'v_7', 'v_8', 'v_9', 'v_10', 'v_11', 'v_12', 'v_13','v_14' ] categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
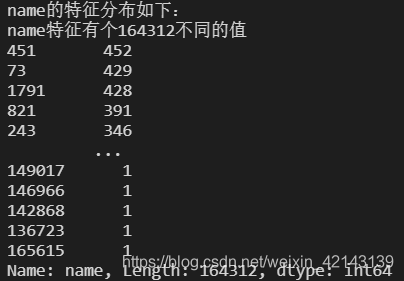
# 特征nunique分布
for cat_fea in categorical_features:
print(cat_fea + "的特征分布如下:")
print("{}特征有个{}不同的值".format(cat_fea, Train_data[cat_fea].nunique()))
print(Train_data[cat_fea].value_counts())
每个特征情况都会逐个如下所示:
test data显示同理
numeric_features.append('price')
numeric_features
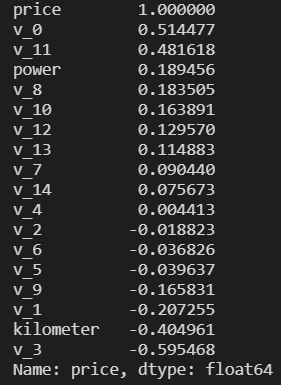
price_numeric = Train_data[numeric_features] correlation = price_numeric.corr() correlation
只截了一部分
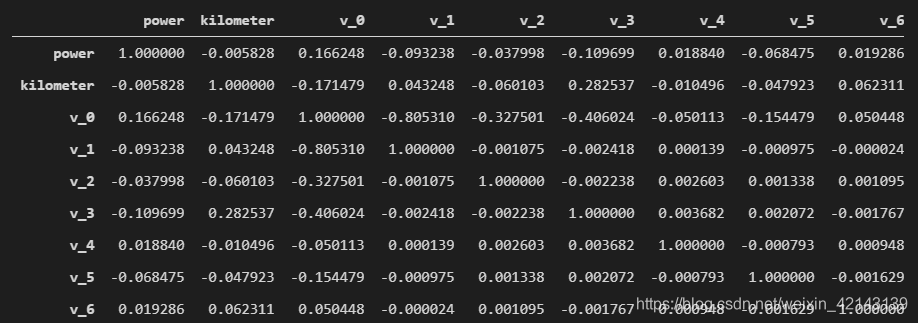
查看相关性(强->弱)
print(correlation['price'].sort_values(ascending = False),'\n')
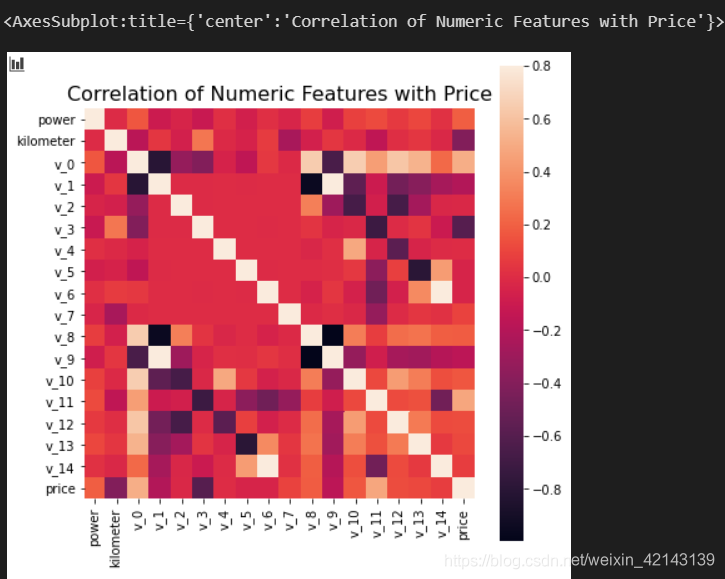
可视化correction
f , ax = plt.subplots(figsize = (7, 7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square = True, vmax=0.8)
price完成历史使命,删掉
del price_numeric['price']
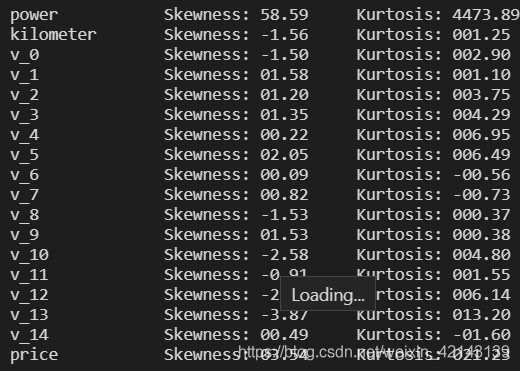
## 2) 查看几个特征得 偏度和峰值
for col in numeric_features:
print('{:15}'.format(col),
'Skewness: {:05.2f}'.format(Train_data[col].skew()) ,
' ' ,
'Kurtosis: {:06.2f}'.format(Train_data[col].kurt())
)
1.2.1.3 *每个数字特征的分布可视化(易忽略)
## 3) 每个数字特征得分布可视化 f = pd.melt(Train_data, value_vars=numeric_features) g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False) g = g.map(sns.distplot, "value")
只截了部分:
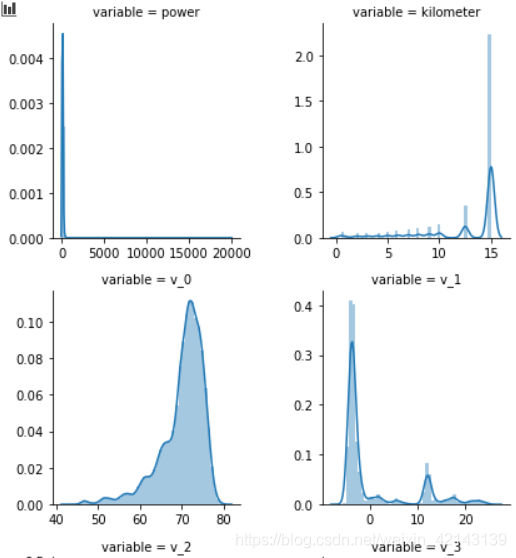
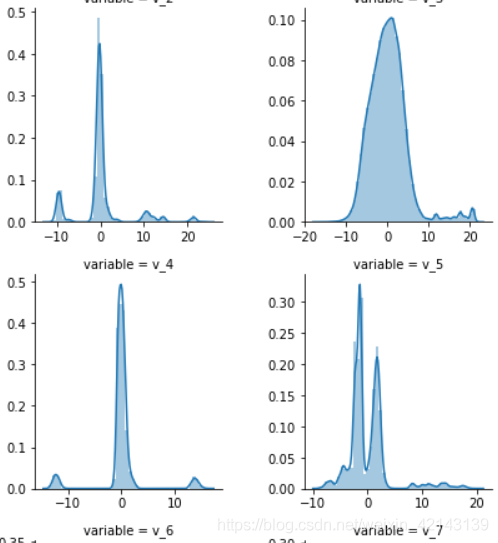
结论:匿名特征(v_*)相对分布均匀
1.2.1.4 *数字特征相互之间的关系可视化(易忽略)
## 4) 数字特征相互之间的关系可视化 sns.set() columns = ['price', 'v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14'] sns.pairplot(Train_data[columns],size = 2 ,kind ='scatter',diag_kind='kde') plt.show()
1.2.1.5 *多变量互相回归关系可视化(易忽略)
## 5) 多变量互相回归关系可视化 fig, ((ax1, ax2), (ax3, ax4), (ax5, ax6), (ax7, ax8), (ax9, ax10)) = plt.subplots(nrows=5, ncols=2, figsize=(24, 20)) # ['v_12', 'v_8' , 'v_0', 'power', 'v_5', 'v_2', 'v_6', 'v_1', 'v_14'] v_12_scatter_plot = pd.concat([Y_train,Train_data['v_12']],axis = 1) sns.regplot(x='v_12',y = 'price', data = v_12_scatter_plot,scatter= True, fit_reg=True, ax=ax1) v_8_scatter_plot = pd.concat([Y_train,Train_data['v_8']],axis = 1) sns.regplot(x='v_8',y = 'price',data = v_8_scatter_plot,scatter= True, fit_reg=True, ax=ax2) v_0_scatter_plot = pd.concat([Y_train,Train_data['v_0']],axis = 1) sns.regplot(x='v_0',y = 'price',data = v_0_scatter_plot,scatter= True, fit_reg=True, ax=ax3) power_scatter_plot = pd.concat([Y_train,Train_data['power']],axis = 1) sns.regplot(x='power',y = 'price',data = power_scatter_plot,scatter= True, fit_reg=True, ax=ax4) v_5_scatter_plot = pd.concat([Y_train,Train_data['v_5']],axis = 1) sns.regplot(x='v_5',y = 'price',data = v_5_scatter_plot,scatter= True, fit_reg=True, ax=ax5) v_2_scatter_plot = pd.concat([Y_train,Train_data['v_2']],axis = 1) sns.regplot(x='v_2',y = 'price',data = v_2_scatter_plot,scatter= True, fit_reg=True, ax=ax6) v_6_scatter_plot = pd.concat([Y_train,Train_data['v_6']],axis = 1) sns.regplot(x='v_6',y = 'price',data = v_6_scatter_plot,scatter= True, fit_reg=True, ax=ax7) v_1_scatter_plot = pd.concat([Y_train,Train_data['v_1']],axis = 1) sns.regplot(x='v_1',y = 'price',data = v_1_scatter_plot,scatter= True, fit_reg=True, ax=ax8) v_14_scatter_plot = pd.concat([Y_train,Train_data['v_14']],axis = 1) sns.regplot(x='v_14',y = 'price',data = v_14_scatter_plot,scatter= True, fit_reg=True, ax=ax9) v_13_scatter_plot = pd.concat([Y_train,Train_data['v_13']],axis = 1) sns.regplot(x='v_13',y = 'price',data = v_13_scatter_plot,scatter= True, fit_reg=True, ax=ax10)
1.2.2 类别特征分析(会画,不会利用结果)
对类别特征查看unique分布
.value_counts()
## 1) unique分布
for fea in categorical_features:
print(Train_data[fea].nunique())
categorical_features
1.2.2.1 箱形图可视化
## 2) 类别特征箱形图可视化
# 因为 name和 regionCode的类别太稀疏了,这里我们把不稀疏的几类画一下
categorical_features = ['model',
'brand',
'bodyType',
'fuelType',
'gearbox',
'notRepairedDamage']
for c in categorical_features:
Train_data[c] = Train_data[c].astype('category')
if Train_data[c].isnull().any():
Train_data[c] = Train_data[c].cat.add_categories(['MISSING'])
Train_data[c] = Train_data[c].fillna('MISSING')
def boxplot(x, y, **kwargs):
sns.boxplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(boxplot, "value", "price")
Train_data.columns
1.2.2.2 小提琴图可视化
## 3) 类别特征的小提琴图可视化
catg_list = categorical_features
target = 'price'
for catg in catg_list :
sns.violinplot(x=catg, y=target, data=Train_data)
plt.show()
categorical_features = ['model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage']
1.2.2.3 柱形图可视化类别
## 4) 类别特征的柱形图可视化
def bar_plot(x, y, **kwargs):
sns.barplot(x=x, y=y)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, id_vars=['price'], value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(bar_plot, "value", "price")
1.2.2.4 特征的每个类别频数可视化(count_plot)
## 5) 类别特征的每个类别频数可视化(count_plot)
def count_plot(x, **kwargs):
sns.countplot(x=x)
x=plt.xticks(rotation=90)
f = pd.melt(Train_data, value_vars=categorical_features)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False, size=5)
g = g.map(count_plot, "value")
2. *用pandas_profiling生成数据报告(新技能)
import pandas_profiling
pfr = pandas_profiling.ProfileReport(Train_data)
pfr.to_file("./example.html")
3. 小结
本次笔记虽然针对样本量较少的情况,但仍有一些可贵的思路:
a. 通过检查nan缺失情况,确定需要进一步处理的特征:
填充(填充方式是什么,均值填充,0填充,众数填充等);
舍去;
先做样本分类用不同的特征模型去预测。
b. 通过分布,进行异常检测
分析特征异常的label是否异常(或者偏离均值较远或者事特殊符号);
异常值是否应该剔除,还是用正常值填充,等。
c. 通过对laebl作图,分析标签的分布情况
d. 通过对特征作图,特征和label联合做图(统计图,离散图),直观了解特征的分布情况,通过这一步也可以发现数据之中的一些异常值等,通过箱型图分析一些特征值的偏离情况,对于特征和特征联合作图,对于特征和label联合作图,分析其中的一些关联性
到此这篇关于Datawhale练习的文章就介绍到这了,更多相关python预测内容请搜索我们以前的文章或继续浏览下面的相关文章,希望大家以后多多支持我们!
相关推荐
-

利用机器学习预测房价
项目介绍 背景: DC竞赛比赛项目,运用回归模型进行房价预测. 数据介绍: 数据主要包括2014年5月至2015年5月美国King County的房屋销售价格以及房屋的基本信息. 其中训练数据主要包括10000条记录,14个字段,分别代表: 销售日期(date):2014年5月到2015年5月房屋出售时的日期: 销售价格(price):房屋交易价格,单位为美元,是目标预测值: 卧室数(bedroom_num):房屋中的卧室数目: 浴室数(bathroom_num):房屋中的浴室数目: 房屋面积(
-
如何用Python进行时间序列分解和预测
预测是一件复杂的事情,在这方面做得好的企业会在同行业中出类拔萃.时间序列预测的需求不仅存在于各类业务场景当中,而且通常需要对未来几年甚至几分钟之后的时间序列进行预测.如果你正要着手进行时间序列预测,那么本文将带你快速掌握一些必不可少的概念. 目录 什么是时间序列? 如何在Python中绘制时间序列数据? 时间序列的要素是什么? 如何分解时间序列? 经典分解法 如何获得季节性调整值? STL分解法 时间序列预测的基本方法: Python中的简单移动平均(SMA) 为什么使用简单移动平均? Pyth
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
利用keras使用神经网络预测销量操作
keras非常方便. 不解释,直接上实例. 数据格式如下: 序号 天气 是否周末 是否有促销 销量 1 坏 是 是 高 2 坏 是 是 高 3 坏 是 是 高 4 坏 否 是 高 5 坏 是 是 高 6 坏 否 是 高 7 坏 是 否 高 8 好 是 是 高 9 好 是 否 高 10 好 是 是 高 11 好 是 是 高 12 好 是 是 高 13 好 是 是 高 14 坏 是 是 低 15 好 否 是 高 16 好 否 是 高 17 好 否 是 高 18 好 否 是 高 19 好 否 否 高
-
Python实现新型冠状病毒传播模型及预测代码实例
1.传染及发病过程 一个健康人感染病毒后进入潜伏期(时间长度为Q天),潜伏期之后进入发病期(时间长度为D天),发病期之后该患者有三个可能去向,分别是自愈.接收隔离.死亡. 2.模型假设 潜伏期Q=7天,根据报道潜伏期为2~14天,取中间值:发病期D=10天,根据文献报告,WHO认定SARS发病期为10天,假设武汉肺炎与此相同:潜伏期的患者不具有将病毒传染给他人的能力:发病期的患者具有将病毒传染给他人的能力:患者在发病期之后不再具有将病毒传染他人的能力:假设处于发病期的患者平均每天密切接触1人,致
-
Datawhale练习之二手车价格预测
数据探索性分析(EDA) 1. 总览数据概况 数据库载入 #coding:utf-8 #导入warnings包,利用过滤器来实现忽略警告语句. import warnings warnings.filterwarnings('ignore') import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import missingno as msno 数据载入 ## 1)
-
scikit-learn线性回归,多元回归,多项式回归的实现
匹萨的直径与价格的数据 %matplotlib inline import matplotlib.pyplot as plt def runplt(): plt.figure() plt.title(u'diameter-cost curver') plt.xlabel(u'diameter') plt.ylabel(u'cost') plt.axis([0, 25, 0, 25]) plt.grid(True) return plt plt = runplt() X = [[6], [8],
-
Python机器学习之预测黄金价格
目录 读取黄金 ETF 数据 定义解释变量 定义因变量 将数据拆分为训练和测试数据集 创建线性回归模型 预测黄金ETF价格 绘制累积收益 预测每日价格 读取黄金 ETF 数据 本文使用机器学习方法来预测最重要的贵金属之一黄金的价格.我们将创建一个线性回归模型,该模型从过去的黄金 ETF (GLD) 价格中获取信息,并返回对第二天黄金 ETF 价格的预测.GLD是直接投资实物黄金的最大ETF.(扫描本文最下方二维码获取全部完整源码和Jupyter Notebook 文件打包下载.) 首先要做的是:
-
C#使用ML.Net完成人工智能预测
前言 Visual Studio2019 Preview中提供了图形界面的ML.Net,所以,只要我们安装Visual Studio2019 Preview就能简单的使用ML.Net了,因为我的电脑已经安装了Visual Studio2019,所以我不需要重头安装Visual Studio2019 Preview,只要更新即可. 安装 首先找到Visual Studio Installer安装包,如下图. 运行,然后选择如下: 创建项目 我们创建一下新项目,如下图: 然后选择. 然后添加机器学习
-
python基于机器学习预测股票交易信号
引言 近年来,随着技术的发展,机器学习和深度学习在金融资产量化研究上的应用越来越广泛和深入.目前,大量数据科学家在Kaggle网站上发布了使用机器学习/深度学习模型对股票.期货.比特币等金融资产做预测和分析的文章.从金融投资的角度看,这些文章可能缺乏一定的理论基础支撑(或交易思维),大都是基于数据挖掘.但从量化的角度看,有很多值得我们学习参考的地方,尤其是Pyhton的深入应用.数据可视化和机器学习模型的评估与优化等.下面借鉴Kaggle上的一篇文章<Building an Asset Trad
-
Python 实例进阶之预测房价走势
目录 项目描述 项目分析 Show Time Step 1 导入数据 Step 2 分析数据 基础统计运算 特征观察 Step 3 数据划分 Step 4 定义评价函数 Step 5 模型调优 学习曲线 小结 该分享源于 Udacity 机器学习进阶中的一个mini作业项目,用于入门非常合适,刨除了繁琐的部分,保留了最关键.基本的步骤,能够对机器学习基本流程有一个最清晰的认识.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 项目描述 利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并
-
vue2.0中vue-cli实现全选、单选计算总价格的实例代码
由于工作的需要并鉴于网上的vue2.0中vue-cli实现全选.单选方案不合适,自己写了一个简单实用的.就短短的126行代码. <template> <div> <table> <tr> <td><input type="checkbox" v-model="checkAll">全选({{checkedCount}})</td> <td>产品名称</td> &
-
vue.js实现价格格式化的方法
这里分享一个常用的价格格式化的一个方法,在电商的价格处理中非常的实用,我们可以看一个效果 这里在价格数据的地方使用了一个过滤器,通过这个过滤器对价格做了保留小数位的处理. HTML <div class="price"> <span v-html="goods.sale_price|format"></span> <span class="price-before">¥{{"这里是价格数据"}}&l