MySQL排序原理和案例详析
前言
排序是数据库中的一个基本功能,MySQL也不例外。用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序。本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个“奇怪”排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因。
1.排序优化与索引使用
为了优化SQL语句的排序性能,最好的情况是避免排序,合理利用索引是一个不错的方法。因为索引本身也是有序的,如果在需要排序的字段上面建立了合适的索引,那么就可以跳过排序的过程,提高SQL的查询速度。下面我通过一些典型的SQL来说明哪些SQL可以利用索引减少排序,哪些SQL不能。假设t1表存在索引key1(key_part1,key_part2),key2(key2)
a.可以利用索引避免排序的SQL
SELECT * FROM t1 ORDER BY key_part1,key_part2; SELECT * FROM t1 WHERE key_part1 = constant ORDER BY key_part2; SELECT * FROM t1 WHERE key_part1 > constant ORDER BY key_part1 ASC; SELECT * FROM t1 WHERE key_part1 = constant1 AND key_part2 > constant2 ORDER BY key_part2;
b.不能利用索引避免排序的SQL
//排序字段在多个索引中,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part1,key_part2, key2; //排序键顺序与索引中列顺序不一致,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part2, key_part1; //升降序不一致,无法使用索引排序 SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC; //key_part1是范围查询,key_part2无法使用索引排序 SELECT * FROM t1 WHERE key_part1> constant ORDER BY key_part2;
2.排序实现的算法
对于不能利用索引避免排序的SQL,数据库不得不自己实现排序功能以满足用户需求,此时SQL的执行计划中会出现“Using filesort”,这里需要注意的是filesort并不意味着就是文件排序,其实也有可能是内存排序,这个主要由sort_buffer_size参数与结果集大小确定。MySQL内部实现排序主要有3种方式,常规排序,优化排序和优先队列排序,主要涉及3种排序算法:快速排序、归并排序和堆排序。假设表结构和SQL语句如下:
CREATE TABLE t1(id int, col1 varchar(64), col2 varchar(64), col3 varchar(64), PRIMARY KEY(id),key(col1,col2)); SELECT col1,col2,col3 FROM t1 WHERE col1>100 ORDER BY col2;
a.常规排序
(1).从表t1中获取满足WHERE条件的记录
(2).对于每条记录,将记录的主键+排序键(id,col2)取出放入sort buffer
(3).如果sort buffer可以存放所有满足条件的(id,col2)对,则进行排序;否则sort buffer满后,进行排序并固化到临时文件中。(排序算法采用的是快速排序算法)
(4).若排序中产生了临时文件,需要利用归并排序算法,保证临时文件中记录是有序的
(5).循环执行上述过程,直到所有满足条件的记录全部参与排序
(6).扫描排好序的(id,col2)对,并利用id去捞取SELECT需要返回的列(col1,col2,col3)
(7).将获取的结果集返回给用户。
从上述流程来看,是否使用文件排序主要看sort buffer是否能容下需要排序的(id,col2)对,这个buffer的大小由sort_buffer_size参数控制。此外一次排序需要两次IO,一次是捞(id,col2),第二次是捞(col1,col2,col3),由于返回的结果集是按col2排序,因此id是乱序的,通过乱序的id去捞(col1,col2,col3)时会产生大量的随机IO。对于第二次MySQL本身一个优化,即在捞之前首先将id排序,并放入缓冲区,这个缓存区大小由参数read_rnd_buffer_size控制,然后有序去捞记录,将随机IO转为顺序IO。
b.优化排序
常规排序方式除了排序本身,还需要额外两次IO。优化的排序方式相对于常规排序,减少了第二次IO。主要区别在于,放入sort buffer不是(id,col2),而是(col1,col2,col3)。由于sort buffer中包含了查询需要的所有字段,因此排序完成后可以直接返回,无需二次捞数据。这种方式的代价在于,同样大小的sort buffer,能存放的(col1,col2,col3)数目要小于(id,col2),如果sort buffer不够大,可能导致需要写临时文件,造成额外的IO。当然MySQL提供了参数max_length_for_sort_data,只有当排序元组小于max_length_for_sort_data时,才能利用优化排序方式,否则只能用常规排序方式。
c.优先队列排序
为了得到最终的排序结果,无论怎样,我们都需要将所有满足条件的记录进行排序才能返回。那么相对于优化排序方式,是否还有优化空间呢?5.6版本针对Order by limit M,N语句,在空间层面做了优化,加入了一种新的排序方式--优先队列,这种方式采用堆排序实现。堆排序算法特征正好可以解limit M,N 这类排序的问题,虽然仍然需要所有元素参与排序,但是只需要M+N个元组的sort buffer空间即可,对于M,N很小的场景,基本不会因为sort buffer不够而导致需要临时文件进行归并排序的问题。对于升序,采用大顶堆,最终堆中的元素组成了最小的N个元素,对于降序,采用小顶堆,最终堆中的元素组成了最大的N的元素。
3.排序不一致问题
案例1
Mysql从5.5迁移到5.6以后,发现分页出现了重复值。
测试表与数据:
create table t1(id int primary key, c1 int, c2 varchar(128)); insert into t1 values(1,1,'a'); insert into t1 values(2,2,'b'); insert into t1 values(3,2,'c'); insert into t1 values(4,2,'d'); insert into t1 values(5,3,'e'); insert into t1 values(6,4,'f'); insert into t1 values(7,5,'g');
假设每页3条记录,第一页limit 0,3和第二页limit 3,3查询结果如下:

我们可以看到 id为4的这条记录居然同时出现在两次查询中,这明显是不符合预期的,而且在5.5版本中没有这个问题。产生这个现象的原因就是5.6针对limit M,N的语句采用了优先队列,而优先队列采用堆实现,比如上述的例子order by c1 asc limit 0,3 需要采用大小为3的大顶堆;limit 3,3需要采用大小为6的大顶堆。由于c1为2的记录有3条,而堆排序是非稳定的(对于相同的key值,无法保证排序后与排序前的位置一致),所以导致分页重复的现象。为了避免这个问题,我们可以在排序中加上唯一值,比如主键id,这样由于id是唯一的,确保参与排序的key值不相同。将SQL写成如下:
select * from t1 order by c1,id asc limit 0,3; select * from t1 order by c1,id asc limit 3,3;
案例2
两个类似的查询语句,除了返回列不同,其它都相同,但排序的结果不一致。
测试表与数据:
create table t2(id int primary key, status int, c1 varchar(255),c2 varchar(255),c3 varchar(255),key(c1));
insert into t2 values(7,1,'a',repeat('a',255),repeat('a',255));
insert into t2 values(6,2,'b',repeat('a',255),repeat('a',255));
insert into t2 values(5,2,'c',repeat('a',255),repeat('a',255));
insert into t2 values(4,2,'a',repeat('a',255),repeat('a',255));
insert into t2 values(3,3,'b',repeat('a',255),repeat('a',255));
insert into t2 values(2,4,'c',repeat('a',255),repeat('a',255));
insert into t2 values(1,5,'a',repeat('a',255),repeat('a',255));
分别执行SQL语句:
select id,status,c1,c2 from t2 force index(c1) where c1>='b' order by status; select id,status from t2 force index(c1) where c1>='b' order by status;
执行结果如下:
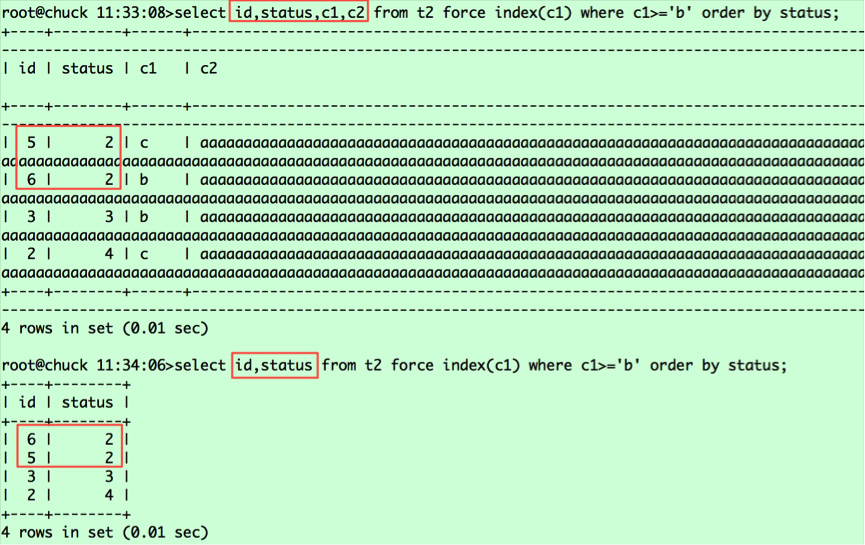
看看两者的执行计划是否相同

为了说明问题,我在语句中加了force index的hint,确保能走上c1列索引。语句通过c1列索引捞取id,然后去表中捞取返回的列。根据c1列值的大小,记录在c1索引中的相对位置如下:
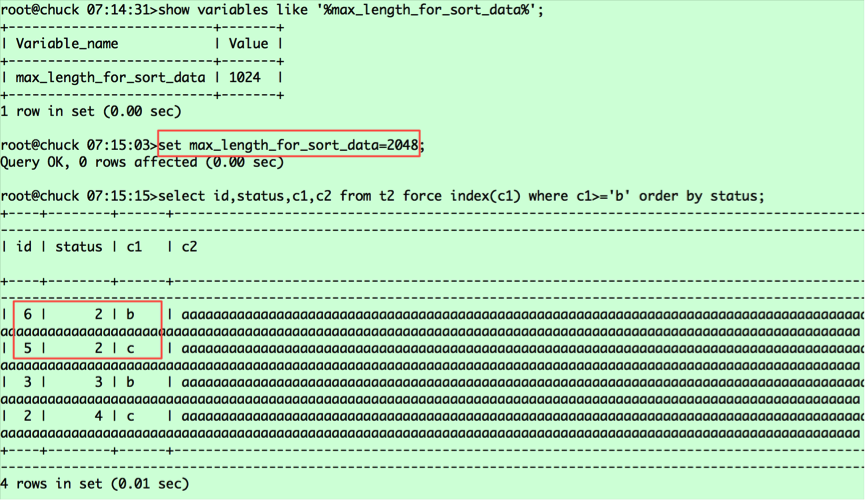
(c1,id)===(b,6),(b,3),(5,c),(c,2),对应的status值分别为2 3 2 4。从表中捞取数据并按status排序,则相对位置变为(6,2,b),(5,2,c),(3,3,c),(2,4,c),这就是第二条语句查询返回的结果,那么为什么第一条查询语句(6,2,b),(5,2,c)是调换顺序的呢?这里要看我之前提到的a.常规排序和b.优化排序中标红的部分,就可以明白原因了。由于第一条查询返回的列的字节数超过了max_length_for_sort_data,导致排序采用的是常规排序,而在这种情况下MYSQL将rowid排序,将随机IO转为顺序IO,所以返回的是5在前,6在后;而第二条查询采用的是优化排序,没有第二次捞取数据的过程,保持了排序后记录的相对位置。对于第一条语句,若想采用优化排序,我们将max_length_for_sort_data设置调大即可,比如2048。
4.参考文档
- http://dev.mysql.com/doc/refman/5.6/en/order-by-optimization.html
- http://mysql.taobao.org/monthly/2015/06/04/
- http://ifxoxo.com/mysql_order_by.html
到此这篇关于MySQL排序原理和案例详析的文章就介绍到这了,更多相关MySQL排序原理和案例内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
将MySQL查询结果按值排序的简要教程
MySQL查询结果如何排序呢?这是很多人都提过的问题,下面就教您如何对MySQL查询结果按某值排序,如果您感兴趣的话,不妨一看. 之前有一个功能修改,要求MySQL查询结果中: id name * * * 1 lucy ... 3 lucy ... 2 lily ... 4 lucy ... 名字为lucy的优先排在前面,百思不得其解,可能有人会说简单 union嘛 或者弄个临时表什么的,其实我也想过,但是本身SQL逻辑就很多了(上面只是简例),再union的话或者临时表可能绕很大的弯路,后来看
-
MySQL查询优化:连接查询排序浅谈
情况是这么一个情况:现在有两张表,team表和people表,每个people属于一个team,people中有个字段team_id. 下面给出建表语句: 复制代码 代码如下: create table t_team(id int primary key,tname varchar(100)); create table t_people(id int primary key,pname varchar(100),team_id int,foreign key (team_id) referen
-
mysql如何按照中文排序解决方案
Sql代码 复制代码 代码如下: /* Navicat MySQL Data Transfer Source Server : local Source Server Version : 50022 Source Host : localhost:3306 Source Database : test Target Server Type : MYSQL Target Server Version : 50022 File Encoding : 65001 Date: 2012-11-19 15
-
让MySQL支持中文排序的实现方法
让MySQL支持中文排序 编绎MySQL时一般以ISO-8859字符集作为默认的字符集,因此在比较过程中中文编码字符大小写转换造成了这种现象,一种解决方法是对于包含中文的字段加上"binary"属性,使之作为二进制比较,例如将"name char(10)"改成"name char(10)binary". 编译MySQL时使用--with--charset=gbk 参数,这样MySQL就会直接支持中文查找和排序了. mysql order by 中
-
MySQL中按照多字段排序及问题解决
因为在做一个项目需要筛选掉一部分产品列表中的产品,使其在列表显示时排在最后,但是所有产品都要按照更新时间排序. 研究了一下系统的数据库结构后,决定将要排除到后面的产品加为粗体,这样在数据库中的"ifbold"就会被标记为1,而其他产品就默认标记为0,然后就打算使用MySQL在Order By时进行多字段排序. Order by的多条件分割一般使用英文逗号分割,所以我测试的SQL如下: 复制代码 代码如下: select * from {P}_product_con where $scl
-

浅谈MySQL排序原理与案例分析
前言 排序是数据库中的一个基本功能,MySQL也不例外.用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序.本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个"奇怪"排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因. 1.排序优化与索引使用 为了优化SQL语句的排序性能,最好的情况是避免排序,合理利
-
mysql 按中文字段排序
如果这个问题不解决,那么MySQL将无法实际处理中文. 出现这个问题的原因是因为MySQL在查询字符串时是大小写不敏感的,在编绎MySQL时一般以ISO-8859字符集作为默认的字符集,因此在比较过程中中文编码字符大小写转换造成了这种现象. 解决方法: 对于包含中文的字段加上"binary"属性,使之作为二进制比较,例如将"name char(10)"改成"name char(10)binary". 如果你使用源码编译MySQL,可以编译MySQ
-
mysql如何根据汉字首字母排序
复制代码 代码如下: select areaName from area order by convert(areaName USING gbk) COLLATE gbk_chinese_ci asc 说明:areaName为列名 area为表名 PS:这里再为大家推荐一款本站的相关在线工具供大家参考: 在线中英文根据首字母排序工具: http://tools.jb51.net/aideddesign/zh_paixu
-
mysql自定义排序顺序语句
mysql 自定义排序顺序 实例如:在sql语句中加入ORDER BY FIELD(status,3,4,0,2,1)语句可定义排序顺序 说明:status为排序字段,后面为该字段的相关值
-
MySQL排序原理和案例详析
前言 排序是数据库中的一个基本功能,MySQL也不例外.用户通过Order by语句即能达到将指定的结果集排序的目的,其实不仅仅是Order by语句,Group by语句,Distinct语句都会隐含使用排序.本文首先会简单介绍SQL如何利用索引避免排序代价,然后会介绍MySQL实现排序的内部原理,并介绍与排序相关的参数,最后会给出几个"奇怪"排序例子,来谈谈排序一致性问题,并说明产生现象的本质原因. 1.排序优化与索引使用 为了优化SQL语句的排序性能,最好的情况是避免排序,合理利
-
SpringBoot实战之高效使用枚举参数(原理篇)案例详解
找入口 对 Spring 有一定基础的同学一定知道,请求入口是DispatcherServlet,所有的请求最终都会落到doDispatch方法中的ha.handle(processedRequest, response, mappedHandler.getHandler())逻辑.我们从这里出发,一层一层向里扒. 跟着代码深入,我们会找到org.springframework.web.method.support.InvocableHandlerMethod#invokeForRequest的
-
mysql存储过程原理与用法详解
本文实例讲述了mysql存储过程原理与用法.分享给大家供大家参考,具体如下: 本文内容: 什么是存储过程 存储过程的创建 存储过程的使用 查看存储过程 修改存储过程 删除存储过程 首发日期:2018-04-17 什么是存储过程: 存储过程存储了一系列sql语句 存储过程的需求场景:下边是一个经典的需求场景,很多Mysql的书都有: 存储过程存储了一系列sql语句,使得简化了操作,不要求重复执行一系列操作.只需要在需要的时候调用一下存储过程就行了. 一般来说,可以认为存储过程的功能与函数的功能类似
-
MySQL 主从复制原理与实践详解
本文实例讲述了MySQL 主从复制原理与实践.分享给大家供大家参考,具体如下: 简介 MySQL 的主从复制又叫 Replication.AB 复制.至少需要两个 MySQL 服务(可以是同一台机器,也可以是不同机器之间进行). 比如A服务器做主服务器,B服务器做从服务器,在A服务器上进行数据的更新,通过 binlog 日志记录同步到B服务器上,并重新执行同步过来的 binlog 数据,从而达到两台服务器数据一致. MySQL 数据库的主从复制方案,与使用 scp/rsync 等命令进行的文件级
-
MySQL主从原理及配置详解
MySQL主从配置及原理,供大家参考,具体内容如下 一.环境选择: 1.Centos 6.5 2.MySQL 5.7 二.什么是MySQL主从复制 MySQL主从复制是其最重要的功能之一.主从复制是指一台服务器充当主数据库服务器,另一台或多台服务器充当从数据库服务器,主服务器中的数据自动复制到从服务器之中.对于多级复制,数据库服务器即可充当主机,也可充当从机.MySQL主从复制的基础是主服务器对数据库修改记录二进制日志,从服务器通过主服务器的二进制日志自动执行更新. 三.MySQL主从复制的类型
-
MySql escape的使用案例详解
MySQL转义 转义即表示转义字符原来的语义,一个转义字符的目的是开始一个字符序列,使得转义字符开头的该字符序列具有不同于该字符序列单独出现时的语义. 在sql like语句中,比如 select * from user where username like '%nihao%',select * from user where username like '_nihao', 其中%做为通配符通配多个,_作为通配符通配一个 如果要真的去查询username中中含有 % _ 的,需要使他们不再作为
-
PostgreSQL事务回卷实战案例详析
目录 背景 XID基础原理 XID 定义 XID 发行机制 XID 回卷机制 XID 回卷预防 解决方案 问题分析 问题定位 问题解决 友情提示 总结 背景 前阵子某个客户反馈他的RDS PostgreSQL无法写入,报错信息如下: postgres=# select * from test; id ----(0 rows) postgres=# insert into test select 1;ERROR: database is not accepting commands to avo
-
MySQL查询缓存优化示例详析
目录 一.概述 二.查询优化内容 1.查询缓存的原理 2.查询缓存的优缺点 3.不能应用查询缓存的内容 4.查询缓存相关的服务器变量 5.SELECT语句的缓存控制 6.查询缓存相关的状态变量 7.查询的优化的检查路线 8.命中率和内存使用率估算 9.版本差异 三.总结 一.概述 在日常使用数据库中,80%的数据请求都是查询,而余下的20%是更新或者增加数据.如何提升查询性能,便是提高数据库处理能力的关键. 二.查询优化内容 1.查询缓存的原理 查询的路线图: 缓存SELECT操作或预处理查询的
-
Java JDK动态代理(AOP)的实现原理与使用详析
本文主要给大家介绍了关于Java JDK动态代理(AOP)实现原理与使用的相关内容,分享出来供大家参考学习,下面来一起看看详细的介绍: 一.什么是代理? 代理是一种常用的设计模式,其目的就是为其他对象提供一个代理以控制对某个对象的访问.代理类负责为委托类预处理消息,过滤消息并转发消息,以及进行消息被委托类执行后的后续处理. 代理模式UML图: 简单结构示意图: 为了保持行为的一致性,代理类和委托类通常会实现相同的接口,所以在访问者看来两者没有丝毫的区别.通过代理类这中间一层,能有效控制对委托类对