为什么RedisCluster设计成16384个槽
目录
- 一、数据分片策略
- 二、Redis的分片机制
- 三、Redis 虚拟槽分区的特点
- 四、 Redis 集群伸缩的原理
- 1.集群扩容
- 2.集群收缩
- 五、总结
- 面试问题:为什么RedisCluster会设计成16384个槽呢?
亲爱的同学们,你是否使用过Redis集群呢?那Redis集群的原理又是什么呢?记住下面两句话:
- Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
- Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
一、数据分片策略
布式数据存储方案中最为重要的一点就是数据分片,也就是所谓的 Sharding。为了使得集群能够水平扩展,首要解决的问题就是如何将整个数据集按照一定的规则分配到多个节点上,常用的数据分片的方法有:范围分片,哈希分片,一致性哈希算法和虚拟哈希槽等。
范围分片假设数据集是有序,将顺序相临近的数据放在一起,可以很好的支持遍历操作。范围分片的缺点是面对顺序写时,会存在热点。比如日志类型的写入,一般日志的顺序都是和时间相关的,时间是单调递增的,因此写入的热点永远在最后一个分片。对于关系型的数据库,因为经常性的需要表扫描或者索引扫描,基本上都会使用范围的分片策略。
我们为了将不同的 key 分散放置到不同的 redis 节点,通常的做法是获取 key 的哈希值,然后根据节点数来求模,但这种做法有其明显的弊端,当我们需要增加或减少一个节点时,会造成大量的 key 无法命中,这种比例是相当高的,所以就有人提出了一致性哈希的概念。
一致性哈希有四个重要特征:
- 均衡性:也有人把它定义为平衡性,是指哈希的结果能够尽可能分布到所有的节点中去,这样可以有效的利用每个节点上的资源。
- 单调性:当节点数量变化时哈希的结果应尽可能的保护已分配的内容不会被重新分派到新的节点。
- 分散性和负载:这两个其实是差不多的意思,就是要求一致性哈希算法对 key 哈希应尽可能的避免重复。
二、Redis的分片机制
但是:Redis 集群没有使用一致性hash, 而是引入了哈希槽的概念。
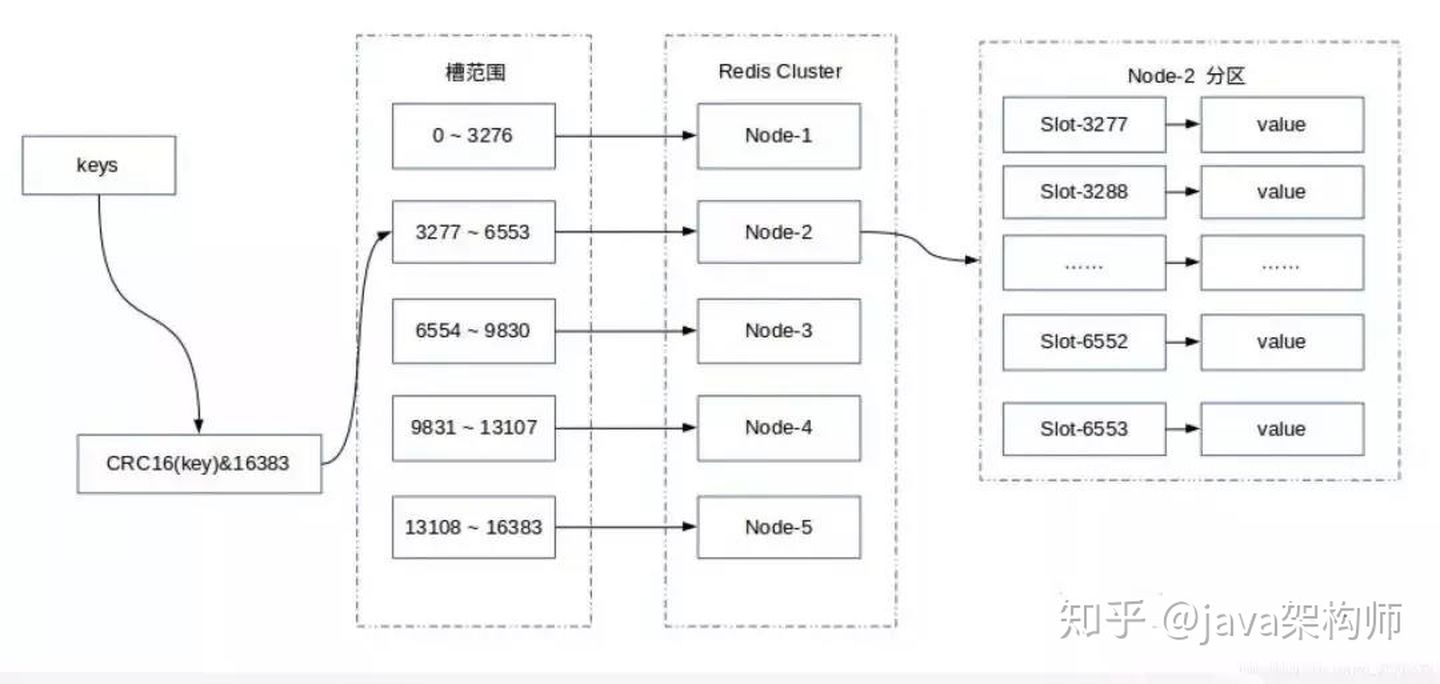
Redis Cluster 采用虚拟哈希槽分区,所有的键根据哈希函数映射到 0 ~ 16383 整数槽内,每个key通过CRC16校验后对16384取模来决定放置哪个槽(Slot),每一个节点负责维护一部分槽以及槽所映射的键值数据。
计算公式:slot = CRC16(key) & 16383。
这种结构很容易添加或者删除节点,并且无论是添加删除或者修改某一个节点,都不会造成集群不可用的状态。使用哈希槽的好处就在于可以方便的添加或移除节点。
- 当需要增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了;
- 当需要移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了。
三、Redis 虚拟槽分区的特点
- 解耦数据和节点之间的关系,简化了节点扩容和收缩难度。
- 节点自身维护槽的映射关系,不需要客户端或者代理服务维护槽分区元数据
- 支持节点、槽和键之间的映射查询,用于数据路由,在线集群伸缩等场景。
四、 Redis 集群伸缩的原理
Redis 集群提供了灵活的节点扩容和收缩方案。在不影响集群对外服务的情况下,可以为集群添加节点进行扩容也可以下线部分节点进行缩容。可以说,槽是 Redis 集群管理数据的基本单位,集群伸缩就是槽和数据在节点之间的移动。
1.集群扩容
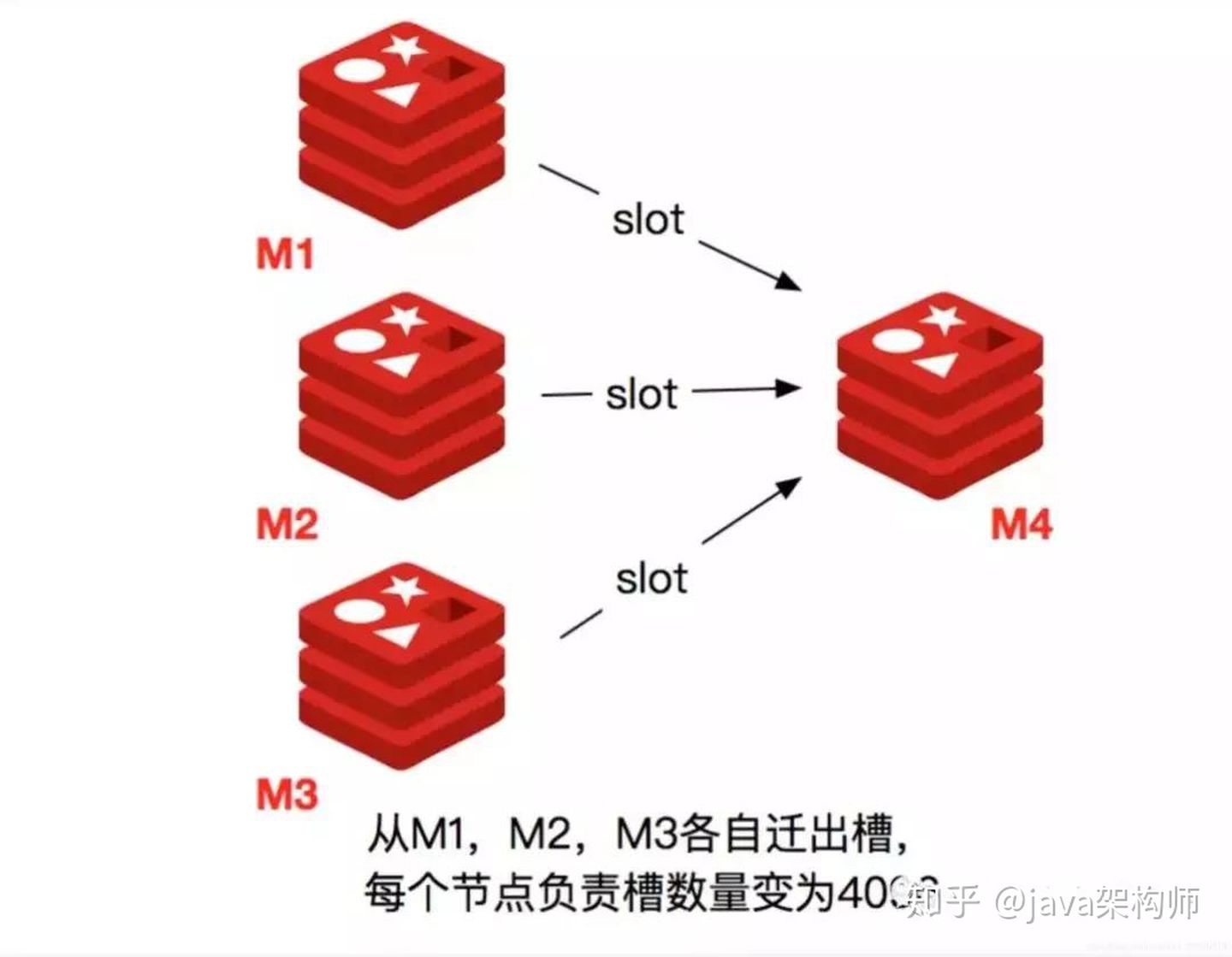
当一个 Redis 新节点运行并加入现有集群后,我们需要为其迁移槽和数据。首先要为新节点指定槽的迁移计划,确保迁移后每个节点负责相似数量的槽,从而保证这些节点的数据均匀。
- 首先启动一个 Redis 节点,记为 M4。
- 使用 cluster meet 命令,让新 Redis 节点加入到集群中。新节点刚开始都是主节点状态,由于没有负责的>槽,所以不能接受任何读写操作,后续我们就给他迁移槽和填充数据。
- 对 M4 节点发送 cluster setslot { slot } importing { sourceNodeId } 命令,让目标节点准备导入槽的数据。 >4) 对源节点,也就是 M1,M2,M3 节点发送 cluster setslot { slot } migrating { targetNodeId } 命令,让源节>点准备迁出槽的数据。
- 源节点执行 cluster getkeysinslot { slot } { count } 命令,获取 count 个属于槽 { slot } 的键,然后执行步骤>六的操作进行迁移键值数据。
- 在源节点上执行 migrate { targetNodeIp} " " 0 { timeout } keys { key... } 命令,把获取的键通过 pipeline 机制>批量迁移到目标节点,批量迁移版本的 migrate 命令在 Redis 3.0.6 以上版本提供。
- 重复执行步骤 5 和步骤 6 直到槽下所有的键值数据迁移到目标节点。
- 向集群内所有主节点发送 cluster setslot { slot } node { targetNodeId } 命令,通知槽分配给目标节点。为了>保证槽节点映射变更及时传播,需要遍历发送给所有主节点更新被迁移的槽执行新节点。
2.集群收缩
收缩节点就是将 Redis 节点下线,整个流程需要如下操作流程。
- 首先需要确认下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。
- 当下线节点不再负责槽或者本身是从节点时,就可以通知集群内其他节点忘记下线节点,当所有的节点忘记改节点后可以正常关闭。
下线节点需要将节点自己负责的槽迁移到其他节点,原理与之前节点扩容的迁移槽过程一致。
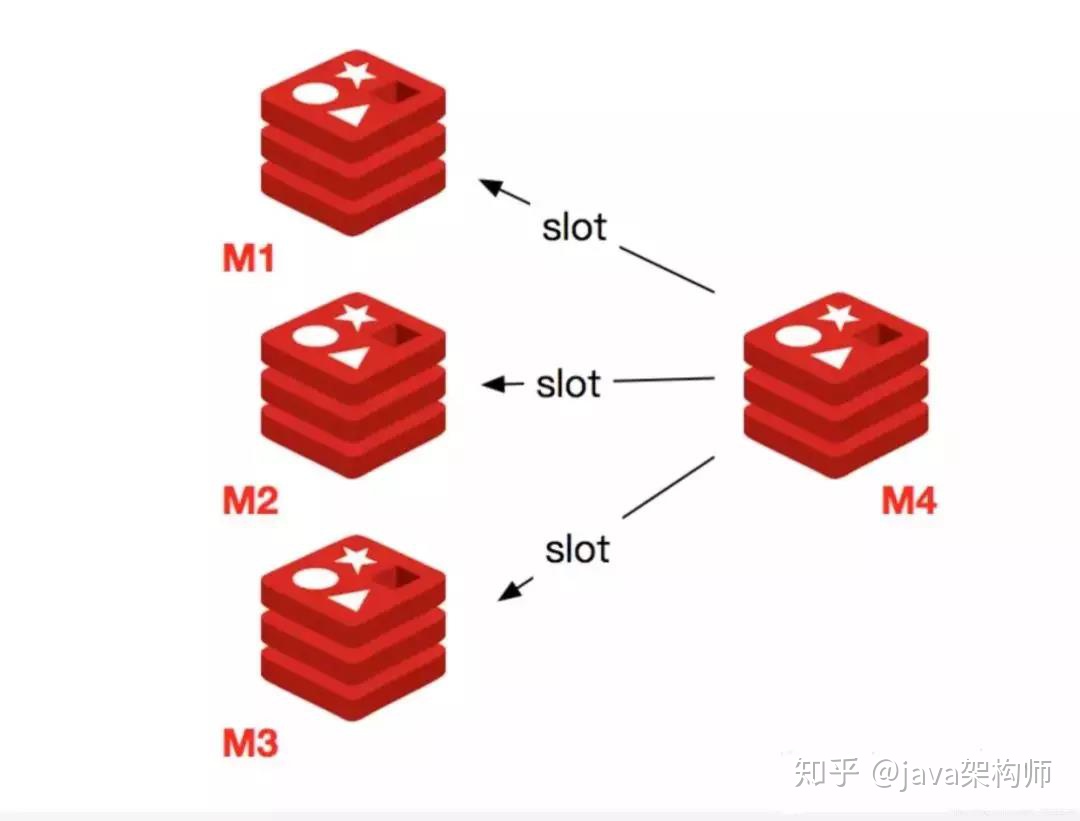
迁移完槽后,还需要通知集群内所有节点忘记下线的节点,也就是说让其他节点不再与要下线的节点进行 Gossip 消息交换。
Redis 集群使用 cluster forget { downNodeId } 命令来讲指定的节点加入到禁用列表中,在禁用列表内的节点不再发送 Gossip 消息。
五、总结
Redis Cluster 是Redis的集群实现,内置数据自动分片机制,集群内部将所有的key映射到16384个Slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写。集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明。一个Key到底属于哪个Slot由crc16(key) % 16384 决定。
面试问题:为什么RedisCluster会设计成16384个槽呢?
这个问题,作者是给出了回答的!
地址如下:https://github.com/antirez/redis/issues/2576
作者原版回答如下: The reason is:
Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with16k slots, but would use a prohibitive 8k of space using 65k slots.At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.
1.如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
如上所述,在消息头中,最占空间的是myslots[CLUSTER_SLOTS/8]。 当槽位为65536时,这块的大小是:65536÷8÷1024=8kb因为每秒钟,redis节点需要发送一定数量的ping消息作为心跳包,如果槽位为65536,这个ping消息的消息头太大了,浪费带宽。
2.redis的集群主节点数量基本不可能超过1000个。
如上所述,集群节点越多,心跳包的消息体内携带的数据越多。如果节点过1000个,也会导致网络拥堵。因此redis作者,不建议redis cluster节点数量超过1000个。 那么,对于节点数在1000以内的redis cluster集群,16384个槽位够用了。没有必要拓展到65536个。
3.槽位越小,节点少的情况下,压缩率高
Redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话(N表示节点数),bitmap的压缩率就很低。 如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。
而16384÷8÷1024=2kb,怎么样,神奇不!
综上所述,作者决定取16384个槽,不多不少,刚刚好!
到此这篇关于为什么RedisCluster设计成16384个槽的文章就介绍到这了,更多相关RedisCluster 16384槽内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Redis Cluster 集群搭建你会吗
三台机器 201.202.203,每台机器装两个 redis 实例,构建 redis cluster 集群. 1. 安装 添加 redis-cluster 目录,将 redis 压缩包拷贝到该目录下,解压压缩包. 解压完后,将文件夹 redis-5.0.3 重命名为 redis1. [root@test201 redis-cluster]# mv redis-5.0.3 redis1 需要在 redis1 目录下使用 make 命令进行编译. [root@test201 redis-cluste
-
Redis Cluster 字段模糊匹配及删除
Questions 在数据库内我们可以通过like关键字.%.*或者REGEX关键字进行模糊匹配.而在Redis内我们如何进行模糊匹配呢?集群情况Redis Cluster的情况是否和单机一致呢?前段时间我对于这个议题进行了调查和研究. 单节点的情况 Jedis 参考stackoverflow上的解答,在Java内使用Jedis主要有如下2中写法: ### 方法1 Set<String> keys = jedis.keys(pattern); for (String key : keys) {
-
Redis cluster集群模式的原理解析
redis cluster redis cluster是Redis的分布式解决方案,在3.0版本推出后有效地解决了redis分布式方面的需求 自动将数据进行分片,每个master上放一部分数据 提供内置的高可用支持,部分master不可用时,还是可以继续工作的 支撑N个redis master node,每个master node都可以挂载多个slave node 高可用,因为每个master都有salve节点,那么如果mater挂掉,redis cluster这套机制,就会自动将某个slave
-
Redis Cluster集群动态扩容的实现
目录 一.引言 二.Cluster集群增加操作 1.动态增加Master主服务器节点 2.动态增加Slave从服务器节点 三.Cluster集群删除操作 1.动态删除Slave从服务器节点 2.动态删除Master主服务器节点 四.总结 一.引言 上一篇文章我们一步一步的教大家搭建了Redis的Cluster集群环境,形成了3个主节点和3个从节点的Cluster的环境.当然,大家可以使用 Cluster info 命令查看Cluster集群的状态,也可以使用Cluster Nodes 命令来详细
-
Redis的Cluster集群搭建的实现步骤
目录 一.引言 二.Redis的Cluster模式介绍 1.Redis群集101 2.Redis群集TCP端口 3.Redis集群和Docker 4.Redis集群数据分片 5.Redis集群之主从模型 6.Redis集群一致性保证 7.Redis群集配置参数 三.创建和使用Redis群集 四.使用创建群集脚本创建Redis群集 五.测试故障转移 六.手动故障转移 七.总结 一.引言 本文档只对Redis的Cluster集群做简单的介绍,并没有对分布式系统的所涉及到的概念做深入的探讨.本文只是针
-
为什么RedisCluster设计成16384个槽
目录 一.数据分片策略 二.Redis的分片机制 三.Redis 虚拟槽分区的特点 四. Redis 集群伸缩的原理 1.集群扩容 2.集群收缩 五.总结 面试问题:为什么RedisCluster会设计成16384个槽呢? 亲爱的同学们,你是否使用过Redis集群呢?那Redis集群的原理又是什么呢?记住下面两句话: Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务. Redis Cluster着眼于扩展性,在单个redis内存不足
-
为什么Java要把字符串设计成不可变的
String是Java中一个不可变的类,所以他一旦被实例化就无法被修改.不可变类的实例一旦创建,其成员变量的值就不能被修改.不可变类有很多优势.本文总结了为什么字符串被设计成不可变的.将涉及到内存.同步和数据结构相关的知识. 字符串池 字符串池是方法区中的一部分特殊存储.当一个字符串被被创建的时候,首先会去这个字符串池中查找,如果找到,直接返回对该字符串的引用. 下面的代码只会在堆中创建一个字符串 String string1 = "abcd"; String string2 = &q
-
jdk中String类设计成final的原由
最佳答案: 主要是为了 " 效率 " 和 " 安全性 " 的缘故. 若 String 允许被继承, 由于它的高度被使用率, 可能会降低程序的性能,所以 String 被定义成 final. 其它答案一: String 和其他基本类型不同 , 他是个对象类型. 既然是对象类型 , 如果是在静态方法下是必须调用静态方法或值的 , 如果是非静态的方法 , 就必须要实例化. main 函数是个 static 的. 所以 String 要能像其他的基本类型一样直接被调用. 这
-
Redis6.0搭建集群Redis-cluster的方法
此处以三台服务器部署为例,IP地址分别为192.168.124.23,192.168.124.24,192.168.124.25 使用普通用户ubuntu登录 总共三个主节点和三个从节点.每台服务器分配槽位不同的一主一从 从官网https://redis.io/download下载Redis6.0 Stable版安装包到/usr/local/redis-6.0.x.tar.gz(文件位置可自定义) 将安装包解压tar -zxvf redis-6.0.x.tar.gz 进入redis文件夹(cd
-
用户权限管理设计[图文说明]
最近在一个项目中设计的一个用户权限的设计,很乐意与大家一起讨论及分享. 设计思路 我的设计思路或者说是我想要实现的功能 1.用户的权限通过角色来控制,一个用户可以拥有多个角色. 2.用户拥有不同角色时,其权限应该是多个角色相互的补集. 3.一个角色拥有多个模块 4.用户的前台菜单显示根据角色所拥有的模块所决定,不同的用户在前端显示的操作菜单是不一样的. 5.页面中的功能按钮根据模块中所包含的功能所定义,通过模块及角色所拥有的权限进行控制 6.可看某个模块有哪些用户,哪些对应角色,并对其进行特殊权
-
数据库设计规范化的五个要求 推荐收藏
若符合这两个条件,则可以说明这个数据库的规范化水平还是比较高的.当然这是两个泛泛而谈的指标.为了达到数据库设计规范化的要求,一般来说,需要符合以下五个要求. 要求一:表中应该避免可为空的列. 虽然表中允许空列,但是,空字段是一种比较特殊的数据类型.数据库在处理的时候,需要进行特殊的处理.如此的话,就会增加数据库处理记录的复杂性.当表中有比较多的空字段时,在同等条件下,数据库处理的性能会降低许多. 所以,虽然在数据库表设计的时候,允许表中具有空字段,但是,我们应该尽量避免.若确实需要的话,我们可以
-
Dreamweaver网页设计制作技巧与提高 好东西
1.灵活运用样式 熟悉网页设计的网友就知道,调用Style的方法很多,我们可以单击鼠标右键选择Custon Style来调用Style标准,也可以在状态栏中的元素列表上单击右键来调用Style.虽然不同的方法达到的效果看似一样,但实际上产生的HTML代码则完全不同.比如用Custon Style来调用Style标准,在网页代码中就生成一个〈span〉标签,这样的标签一多就会使文件十分臃肿而且影响浏览器的解析速度,所以我们应尽量使用状态栏中的元素列表来调用Style. 2.活用Format Tab
-
浅谈java中OO的概念和设计原则(必看)
一.OO(面向对象)的设计基础 面向对象(OO):就是基于对象概念,以对象为中心,以类和继承为构造机制,充分利用接口和多态提供灵活性,来认识.理解.刻划客观世界和设计.构建相应的软件系统.面向对象的特征:虽然各种面向对象编程语言相互有别,但都能看到它们对面向对象基本特征的支持, 即 "抽象.封装.继承.多态" : – 抽象,先不考虑细节 – 封装,隐藏内部实现 – 继承,复用现有代码 – 多态,改写对象行为 面向对象设计模式:是"好的面向对象设计",所谓"
-
从豆瓣网站设计谈网站重构
douban.com非常精巧的应用了div+css,并且通过色系的运用,最大限度减少图片等等方式既使得网站页面清新可人,而且可以最大限度的压缩了网页的大小,从而使得访问的效率得到了最大化. 第一次看douban.com,有一种拿着"读书"杂志在手上阅读的感觉,很素雅,好像还有那么点书香气息.被中国式网站强奸得都习以为常,以为网站也就这样而且也只能这样,无疑好多人第一次看到douban.com的时候都会被他的网站的简洁所触动,都会感觉眼前一亮!为什么会这样呢,于是有些想法,来看看doub
-
70+漂亮且极具亲和力的导航菜单设计国外网站推荐
导航菜单应当足够简单以让用户快速了解它,但还要包含一些必要的元素来引导用户浏览整个网站--融入一些有创意且漂亮的设计. 向大家推荐的70款优秀的导航菜单,有些是基于CSS设计的,有些是基于CSS+JavaScript的菜单,还有些是基于Flash的导航菜单设计,它们都有一个共同点:那就是它们都极具创意.界面对用户有好的,且完美的与网站的整体风格融合在一起. 1.基于CSS的导航菜单设计 Loodo让网站更有感觉的华丽的菜单 Acko.netSteven将他网站的导航菜单设计成了不同寻常的透视效果