详解Java七大阻塞队列之SynchronousQueue
目录
- 分析
其实SynchronousQueue 是一个特别有意思的阻塞队列,就我个人理解来说,它很重要的特点就是没有容量。
直接看一个例子:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
/**
* @author Dongguabai
* @description
* @date 2021-09-01 21:52
*/
public class TestSynchronousQueue {
public static void main(String[] args) {
SynchronousQueue synchronousQueue = new SynchronousQueue();
boolean add = synchronousQueue.add("1");
System.out.println(add);
}
}
代码很简单,就是往 SynchronousQueue 里放了一个元素,程序却抛异常了:
Exception in thread "main" java.lang.IllegalStateException: Queue full at java.util.AbstractQueue.add(AbstractQueue.java:98) at dongguabai.test.juc.test.TestSynchronousQueue.main(TestSynchronousQueue.java:14)
而异常原因是队列满了。刚刚使用的是 SynchronousQueue#add 方法,现在来看看 SynchronousQueue#put 方法:
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
synchronousQueue.put("1");
System.out.println("----");
}
看到 InterruptedException 其实就能猜出这个方法肯定会阻塞当前线程。
通过这两个例子,也就解释了 SynchronousQueue 队列是没有容量的,也就是说在往 SynchronousQueue 中添加元素之前,得先向 SynchronousQueue 中取出元素,这句话听着很别扭,那可以换个角度猜想其实现原理,调用取出方法的时候设置了一个“已经有线程在等待取出”的标识,线程等待,然后添加元素的时候,先看这个标识,如果有线程在等待取出,则添加成功,反之则抛出异常或者阻塞。
分析
接下来从 SynchronousQueue#put 方法开始进行分析:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
可以发现是调用的 Transferer#transfer 方法,这个 Transferer 是在构造 SynchronousQueue 的时候初始化的:
public SynchronousQueue(boolean fair) {
transferer = fair ? new TransferQueue<E>() : new TransferStack<E>();
}
SynchronousQueue 有两种模式,公平与非公平,默认是非公平,非公平使用的就是 TransferStack,是基于单向链表做的:
static final class SNode {
volatile SNode next; // next node in stack
volatile SNode match; // the node matched to this
volatile Thread waiter; // to control park/unpark
Object item; // data; or null for REQUESTs
int mode;
...
}
那么重点就是 SynchronousQueue.TransferStack#transfer 方法了,从方法名都可以看出这是用来做数据交换的,但是这个方法有好几十行,里面各种 Node 指针搞来搞去,这个地方我觉得没必要过于纠结细节,老规矩,抓大放小,而且队列这种,很方便进行 Debug 调试。
再理一下思路:
- 今天研究的是阻塞队列,关注阻塞的话,更应该关系的是
take和put方法; Transferer是一个抽象类,只有一个transfer方法,即take和put共用,那就肯定是基于入参进行功能的区分;take和put方法底层都调用的SynchronousQueue.TransferStack#transfer方法;
将上面 SynchronousQueue#put 使用的例子修改一下,再加一个线程take:
package dongguabai.test.juc.test;
import java.util.Date;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-01 21:52
*/
public class TestSynchronousQueue {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()->{
System.out.println(new Date().toLocaleString()+"::"+Thread.currentThread().getName()+"-put了数据:"+"1");
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
System.out.println("----");
new Thread(()->{
Object take = null;
try {
take = synchronousQueue.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(new Date().toLocaleString()+"::"+Thread.currentThread().getName()+"-take到了数据:"+take);
}).start();
TimeUnit.SECONDS.sleep(1);
System.out.println("结束...");
}
}
整个程序结束,并且输出:
----
2021-9-2 0:58:55::Thread-0-put了数据:1
2021-9-2 0:58:55::Thread-1-take到了数据:1
结束...
也就是说当一个线程在 put 的时候,如果有线程 take ,那么 put 线程可以正常运行,不会被阻塞。
基于这个例子,再结合上文的猜想,也就是说核心点就是找到 put 的时候现在已经有线程在 take 的标识,或者 take 的时候已经有线程在 put,这个标识不一定是变量,结合 AQS 的原理来看,很可能是根据链表中的 Node 进行判断。
接下来看 SynchronousQueue.put 方法:
public void put(E e) throws InterruptedException {
if (e == null) throw new NullPointerException();
if (transferer.transfer(e, false, 0) == null) {
Thread.interrupted();
throw new InterruptedException();
}
}
它底层也是调用的 SynchronousQueue.TransferStack#transfer 方法,但是传入参数是当前 put 的元素、false 和 0。再回过头看 SynchronousQueue.TransferStack#transfer 方法:
E transfer(E e, boolean timed, long nanos) {
SNode s = null; // constructed/reused as needed
//这里的参数e就是要put的元素,显然不为null,也就是说是DATA模式,根据注释,DATA模式就说明当前线程是producer
int mode = (e == null) ? REQUEST : DATA;
for (;;) {
SNode h = head;
if (h == null || h.mode == mode) { // empty or same-mode
if (timed && nanos <= 0) { // can't wait
if (h != null && h.isCancelled())
casHead(h, h.next); // pop cancelled node
else
return null;
} else if (casHead(h, s = snode(s, e, h, mode))) {
//因为第一次put那么h肯定为null,这里入参timed为false,所以会到这里,执行awaitFulfill方法,根据名称可以猜想出是一个阻塞方法
SNode m = awaitFulfill(s, timed, nanos);
if (m == s) { // wait was cancelled
clean(s);
return null;
}
....
}
这里首先会构造一个 SNode,然后执行 casHead 函数,其实最终栈结构就是:
head->put_e
就是 head 会指向 put 的元素对应的 SNode。
然后会执行 awaitFulfill 方法:
SNode awaitFulfill(SNode s, boolean timed, long nanos) {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
Thread w = Thread.currentThread();
int spins = (shouldSpin(s) ?
(timed ? maxTimedSpins : maxUntimedSpins) : 0);
for (;;) {
if (w.isInterrupted())
s.tryCancel();
SNode m = s.match;
if (m != null)
return m;
if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {
s.tryCancel();
continue;
}
}
if (spins > 0)
spins = shouldSpin(s) ? (spins-1) : 0; //自旋机制
else if (s.waiter == null)
s.waiter = w; // establish waiter so can park next iter
else if (!timed)
LockSupport.park(this); //阻塞
else if (nanos > spinForTimeoutThreshold)
LockSupport.parkNanos(this, nanos);
}
}
最终还是会使用 LockSupport 进行阻塞,等待唤醒。
已经大致过了一遍流程了,细节方面就不再纠结了,那么假如再put 一个元素呢,其实结合源码已经可以分析出此时栈的结果为:
head-->put_e_1-->put_e
避免分析出错,写个 Debug 的代码验证一下:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-02 02:15
*/
public class DebugPut2E {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()-> {
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
TimeUnit.SECONDS.sleep(1);
new Thread(()-> {
try {
synchronousQueue.put("2");
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
在 SynchronousQueue.TransferStack#awaitFulfill 方法的 LockSupport.park(this); 处打上断点,运行上面的代码,再看看现在的 head:
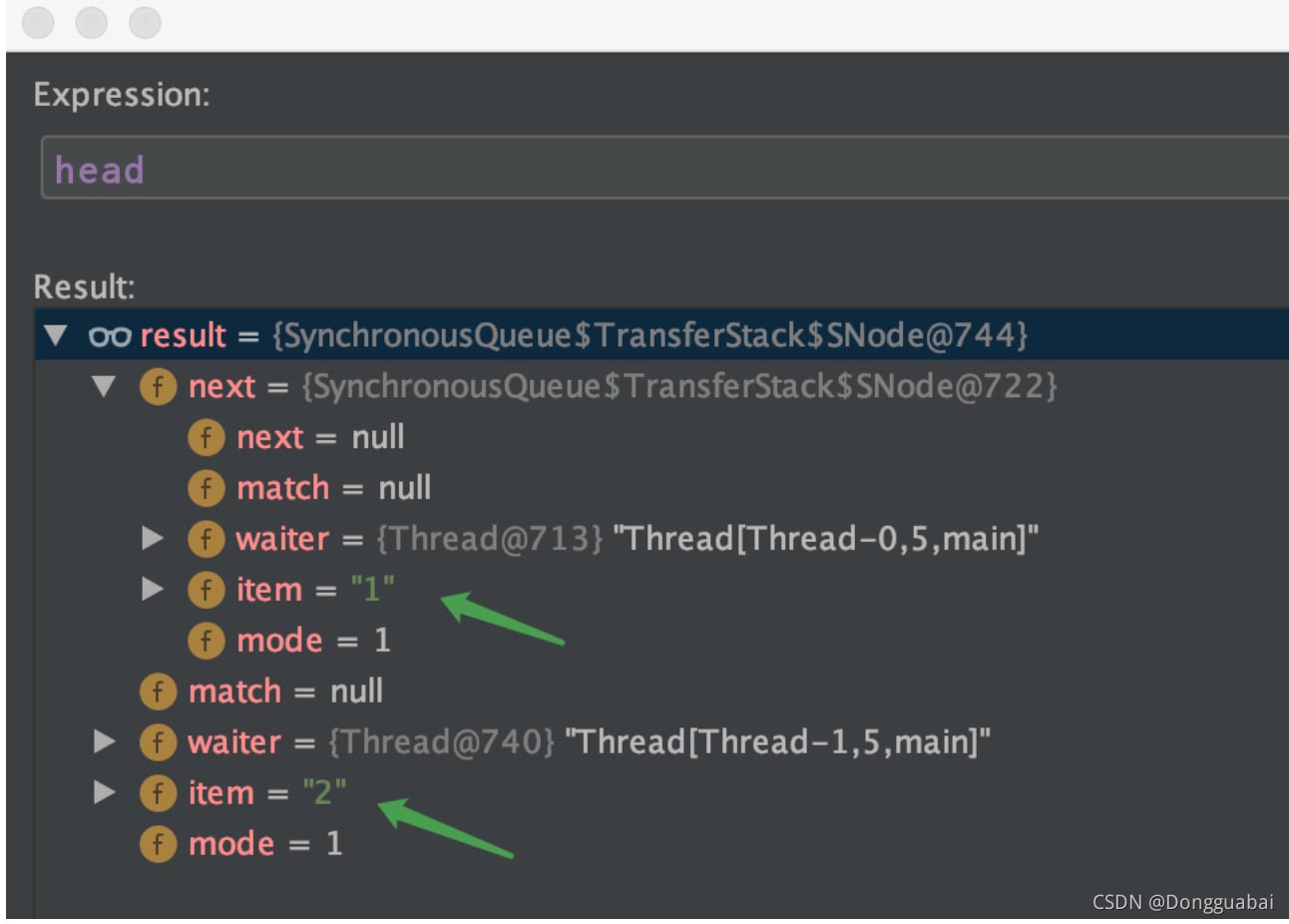
的确与分析的一致。
也就是先进后出。再看 take 方法:
public E take() throws InterruptedException {
E e = transferer.transfer(null, false, 0);
if (e != null)
return e;
Thread.interrupted();
throw new InterruptedException();
}
调用的 SynchronousQueue.TransferStack#transfer 方法,但是传入参数是 null、false 和 0。
偷个懒就不分析源码了,直接 Debug 走一遍,代码如下:
package dongguabai.test.juc.test;
import java.util.concurrent.SynchronousQueue;
import java.util.concurrent.TimeUnit;
/**
* @author Dongguabai
* @description
* @date 2021-09-02 02:24
*/
public class DebugTake {
public static void main(String[] args) throws InterruptedException {
SynchronousQueue synchronousQueue = new SynchronousQueue();
new Thread(()-> {
try {
synchronousQueue.put("1");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-put-1").start();
TimeUnit.SECONDS.sleep(1);
new Thread(()-> {
try {
synchronousQueue.put("2");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-put-2").start();
TimeUnit.SECONDS.sleep(1);
new Thread(()->{
try {
Object take = synchronousQueue.take();
System.out.println("======take:"+take);
} catch (InterruptedException e) {
e.printStackTrace();
}
},"Thread-Take").start();
}
}
在 SynchronousQueue#take 方法中打上断点,运行上面的代码:
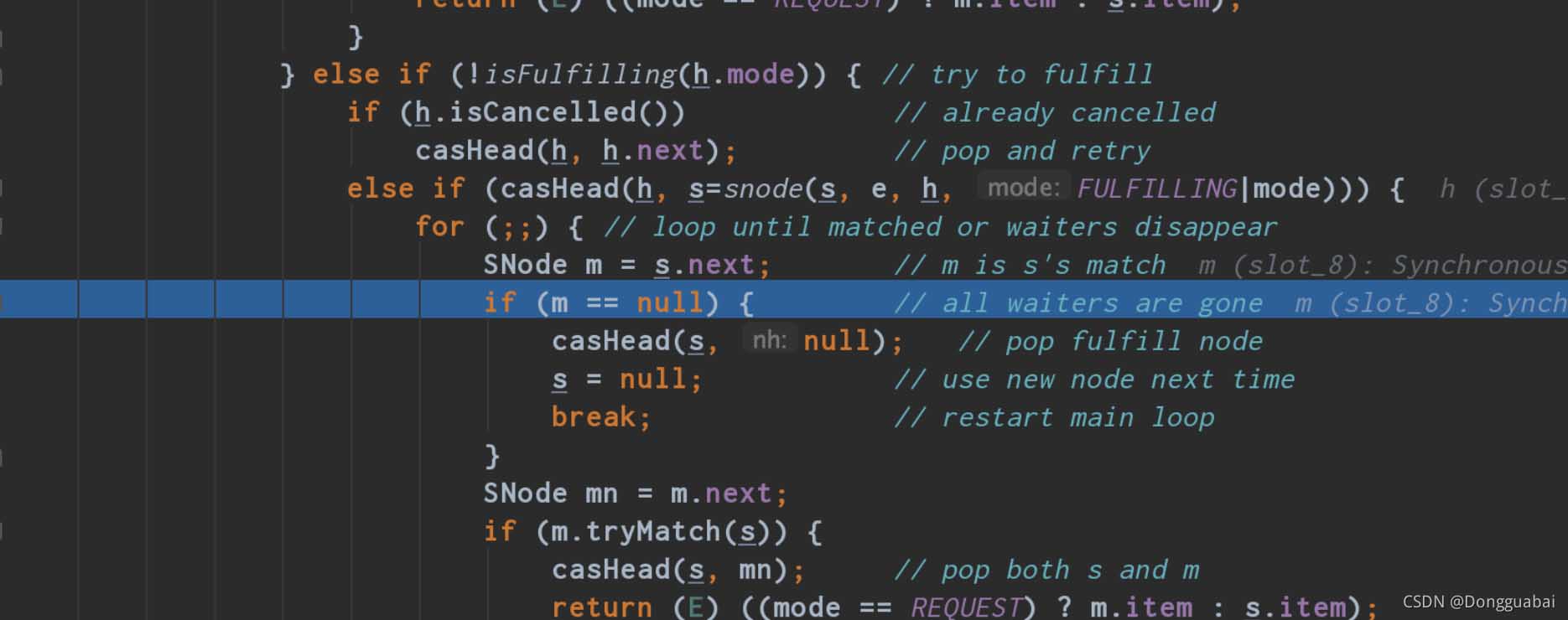
这里的 s 就是 head,m 就是栈顶的元素,也是最近一次 put 的元素。说白了 take 就是取的栈顶的元素,最后再匹配一下,符合条件就直接取出来。take 之后 head 为:

栈的结构为:
head-->put_e
最后再把整个流程梳理一遍:
执行 put 操作的时候,每次压入栈顶;take 的时候就取栈顶的元素,即先进后出;这也就实现了非公平;
至于公平模式,结合 TransferStack 的实现,可以猜测实现就是 put 的时候放入队列,take 的时候从队列头部开始取,先进先出。
那么这个队列设计的优势使用场景在哪里呢?个人感觉它的优势就是完全不会产生对队列中数据的争抢,因为说白了队列是空的,从某种程度上来说消费速率是很快的。
至于使用场景,我这边的确没有想到比较好的使用场景。结合组内同学的使用来看,他选择使用这个队列的原因是因为它不会在内存中生成任务队列,当服务宕机后不用担心内存中任务的丢失(非优雅停机的情况)。经过讨论后发现即使使用了 SynchronousQueue 也无法有效的避免任务丢失,但这的确是一个思路,没准以后在其他场景中用得上。
到此这篇关于详解Java七大阻塞队列之SynchronousQueue的文章就介绍到这了,更多相关Java阻塞队列 SynchronousQueue内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
java 同步器SynchronousQueue详解及实例
同步器简介 学习以来对线程的操作有很大的改观,从c/c++的mutex到java的各种锁(当然不是嫌麻烦,java读写锁的实现还是带来不少好处的,但是sokcet的设计我就不敢恭维了,tcp和udp是两个类,弄得我现在对udp也不怎么熟悉).其中最让我感到特别刚需的设计就是同步器,除了countdownlatch,剩下的都比较刚需,cyclicbarrier我现在唯一能感觉他的好用处就是循环打印a,b,exchanger和SynchronousQueue我一直没发现什么作用,两个就适合生产者消费
-
Java中的阻塞队列详细介绍
Java中的阻塞队列 1. 什么是阻塞队列? 阻塞队列(BlockingQueue)是一个支持两个附加操作的队列.这两个附加的操作是: 在队列为空时,获取元素的线程会等待队列变为非空. 当队列满时,存储元素的线程会等待队列可用. 阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程.阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素. 2.Java里的阻塞队列 JDK中提供了七个阻塞队列: ArrayBlockingQueue :一个由数组结
-
Java常见的阻塞队列总结
Java阻塞队列 阻塞队列和普通队列主要区别在阻塞二字: 阻塞添加:队列已满时,添加元素线程会阻塞,直到队列不满时才唤醒线程执行添加操作 阻塞删除:队列元素为空时,删除元素线程会阻塞,直到队列不为空再执行删除操作 常见的阻塞队列有 LinkedBlockingQueue 和 ArrayBlockingQueue,其中它们都实现 BlockingQueue 接口,该接口定义了阻塞队列需实现的核心方法: public interface BlockingQueue<E> extends Queue
-
详解java中的阻塞队列
阻塞队列简介 阻塞队列(BlockingQueue)首先是一个支持先进先出的队列,与普通的队列完全相同: 其次是一个支持阻塞操作的队列,即: 当队列满时,会阻塞执行插入操作的线程,直到队列不满. 当队列为空时,会阻塞执行获取操作的线程,直到队列不为空. 阻塞队列用在多线程的场景下,因此阻塞队列使用了锁机制来保证同步,这里使用的可重入锁: 而对于阻塞与唤醒机制则有与锁绑定的Condition实现 应用场景:生产者消费者模式 java中的阻塞队列 java中的阻塞队列根据容量可以分为有界队列和无界队
-

详解Java七大阻塞队列之SynchronousQueue
目录 分析 其实SynchronousQueue 是一个特别有意思的阻塞队列,就我个人理解来说,它很重要的特点就是没有容量. 直接看一个例子: package dongguabai.test.juc.test; import java.util.concurrent.SynchronousQueue; /** * @author Dongguabai * @description * @date 2021-09-01 21:52 */ public class TestSynchronousQu
-
详解Java线程池队列中的延迟队列DelayQueue
目录 DelayQueue延迟队列 DelayQueue使用场景 DelayQueue属性 DelayQueue构造方法 实现Delayed接口使用示例 DelayQueue总结 在阻塞队里中,除了对元素进行增加和删除外,我们可以把元素的删除做一个延迟的处理,即使用DelayQueue的方法.本文就来和大家聊聊Java线程池队列中的DelayQueue—延迟队列 public enum QueueTypeEnum { ARRAY_BLOCKING_QUEUE(1, "ArrayBlockingQ
-
java 中 阻塞队列BlockingQueue详解及实例
java 中 阻塞队列BlockingQueue详解及实例 BlockingQueue很好的解决了多线程中数据的传输,首先BlockingQueue是一个接口,它大致有四个实现类,这是一个很特殊的队列,如果BlockQueue是空的,从BlockingQueue取东西的操作将会被阻断进入等待状态,直到BlockingQueue进了东西才会被唤醒.同样,如果BlockingQueue是满的,任何试图往里存东西的操作也会被阻断进入等待状态,直到BlockingQueue里有空间才会被唤醒继续操作.
-
Java使用阻塞队列控制线程通信的方法实例详解
本文实例讲述了Java使用阻塞队列控制线程通信的方法.分享给大家供大家参考,具体如下: 一 点睛 阻塞队列主要用在生产者/消费者的场景,下面这幅图展示了一个线程生产.一个线程消费的场景: 负责生产的线程不断的制造新对象并插入到阻塞队列中,直到达到这个队列的上限值.队列达到上限值之后生产线程将会被阻塞,直到消费的线程对这个队列进行消费.同理,负责消费的线程不断的从队列中消费对象,直到这个队列为空,当队列为空时,消费线程将会被阻塞,除非队列中有新的对象被插入. BlockingQueue的核心方法:
-
详解Java中的延时队列 DelayQueue
当用户超时未支付时,给用户发提醒消息.另一种场景是,超时未付款,订单自动取消.通常,订单创建的时候可以向延迟队列种插入一条消息,到时间自动执行.其实,也可以用临时表,把这些未支付的订单放到一个临时表中,或者Redis,然后定时任务去扫描.这里我们用延时队列来做.RocketMQ有延时队列,RibbitMQ也可以实现,Java自带的也有延时队列,接下来就回顾一下各种队列. Queue 队列是一种集合.除了基本的集合操作以外,队列还提供了额外的插入.提取和检查操作.队列的每个方法都以两种形式存在:一
-
详解Java线程池和Executor原理的分析
详解Java线程池和Executor原理的分析 线程池作用与基本知识 在开始之前,我们先来讨论下"线程池"这个概念."线程池",顾名思义就是一个线程缓存.它是一个或者多个线程的集合,用户可以把需要执行的任务简单地扔给线程池,而不用过多的纠结与执行的细节.那么线程池有哪些作用?或者说与直接用Thread相比,有什么优势?我简单总结了以下几点: 减小线程创建和销毁带来的消耗 对于Java Thread的实现,我在前面的一篇blog中进行了分析.Java Thread与内
-
详解Java并发包基石AQS
一.概述 AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的.当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器. 本章我们就一起探究下这个神奇的东东,并对其实现原理进行剖析理解 二.基本实现原理 AQS使用一个int成员变量来表示同步状态,通
-
详解Java线程池是如何重复利用空闲线程的
在Java开发中,经常需要创建线程去执行一些任务,实现起来也非常方便,但如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间.此时,我们很自然会想到使用线程池来解决这个问题. 使用线程池的好处: 降低资源消耗.java中所有的池化技术都有一个好处,就是通过复用池中的对象,降低系统资源消耗.设想一下如果我们有n多个子任务需要执行,如果我们为每个子任务都创建一个执行线程,而创建线程的过程是需要一定的系统消耗
-
详解JAVA Spring 中的事件机制
说到事件机制,可能脑海中最先浮现的就是日常使用的各种 listener,listener去监听事件源,如果被监听的事件有变化就会通知listener,从而针对变化做相应的动作.这些listener是怎么实现的呢?说listener之前,我们先从设计模式开始讲起. 观察者模式 观察者模式一般包含以下几个对象: Subject:被观察的对象.它提供一系列方法来增加和删除观察者对象,同时它定义了通知方法notify().目标类可以是接口,也可以是抽象类或具体类. ConcreteSubject:具体的