Python如何利用pandas读取csv数据并绘图
目录
- 如何利用pandas读取csv数据并绘图
- 绘制图像
- 展示结果
- pandas画pearson相关系数热力图
- pearson相关系数计算函数
如何利用pandas读取csv数据并绘图
导包,常用的numpy和pandas,绘图模块matplotlib,
import matplotlib.pyplot as plt import pandas as pd import numpy as np fig = plt.figure() ax = fig.add_subplot(111)
读取csv文件的数据,保存到numpy数组内
path_csv = "E:\\python\\python\\2021\\202104\\04091\\path_data.csv" xa = np.array([42.0, 44.4, 43.1, 40.6]) ya = np.array([21.6, 21.2, 13.5, 14.0]) xa1 = np.array([10, 40]) ya1 = np.array([10, 40]) path_data_x = pd.read_csv(path_csv, header=None, usecols=[0]) path_data_y = pd.read_csv(path_csv, header=None, usecols=[1]) path_x = np.array(path_data_x)[:, 0] path_y = np.array(path_data_y)[:, 0]
绘制图像
print(path_x[0]) print(path_y[0]) ax.plot(xa1, ya1, color='g', linestyle='', marker='.') ax.plot(xa, ya, color='g', linestyle='-', marker='.') ax.plot(path_x, path_y, color='m', linestyle='', marker='.') plt.show()
展示结果
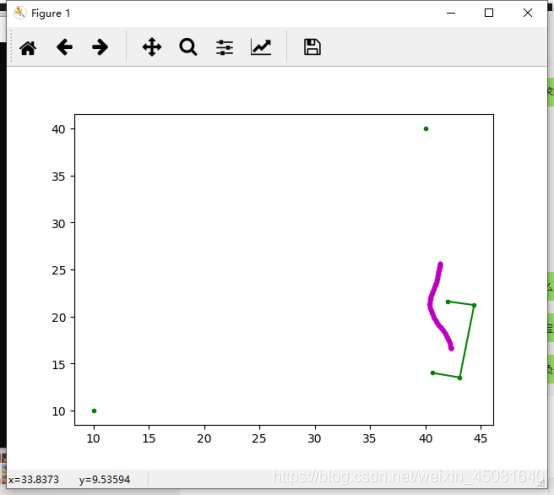
pandas画pearson相关系数热力图
pearson相关系数计算函数
data.corr()
该方法支持空值:np.nan
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
data = pd.DataFrame({"A":[np.nan,2,9], "B":[4,14,6], "c":[987,8,9]})
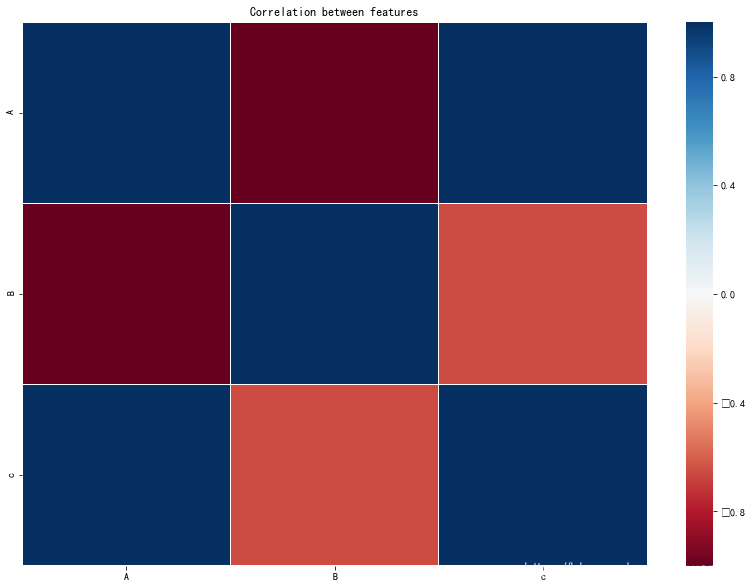
f, ax= plt.subplots(figsize = (14, 10))
corr = data.corr()
# print(corr)
sns.heatmap(corr,cmap='RdBu', linewidths = 0.05, ax = ax)
# 设置Axes的标题
ax.set_title('Correlation between features')
plt.show()
plt.close()
f.savefig('sns_style_origin.jpg', dpi=100, bbox_inches='tight')
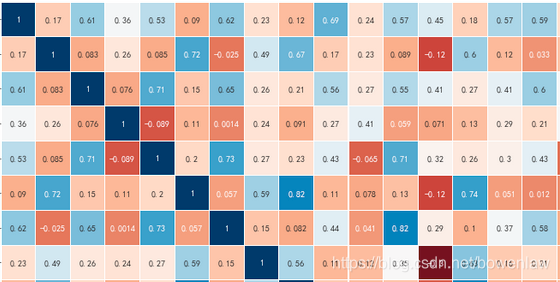
其中heatmap()方法中有annot参数,默认为False,不显示每个颜色的数字,如果设置为:annot=True, 则在每个热力图上显示数字。
效果如下:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Pandas对CSV文件读写操作详解
目录 什么是 CSV 文件 CSV 库解析 CSV 文件 读取 CSV 文件 CSV reader 参数 CSV 文件的写入 使用 pandas 库解析 CSV 文件 pandas 读取 CSV 文件 pandas 写入 CSV 文件 什么是 CSV 文件 CSV 文件(逗号分隔值文件)是一种纯文本文件,它使用特定的结构来排列表格数据.因为它是一个纯文本文件,所以只能包含实际的文本数据,换句话说就是可打印的 ASCII 或 Unicode 字符. 通常,CSV 文件的结构由其名称给出,使用逗号分
-
使用pandas生成/读取csv文件的方法实例
前言 csv是我接触的比较早的一种文件,比较好的是这种文件既能够以电子表格的形式查看又能够以文本的形式查看. 先引入pandas库 import pandas as pd 方法一: 1.我构造了一个cont_list,结构为列表嵌套字典,字典是每一个样本,类似于我们爬虫爬下来的数据的结构 2.利用pd.DataFrame方法先将数据转换成一个二维结构数据,如下方打印的内容所示,cloumns指定列表,列表必须是列表 3.to_csv方法可以直接保存csv文件,index=False表示csv文件
-
python读写数据读写csv文件(pandas用法)
python中数据处理是比较方便的,经常用的就是读写文件,提取数据等,本博客主要介绍其中的一些用法.Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能. 一.pandas读取csv文件 数据处理过程中csv文件用的比较多. import pandas as pd data = pd.read_csv('F:/Zhu/test/test.csv') 下面看一下pd.read_csv常用的参数: panda
-
使用pandas模块读取csv文件和excel表格,并用matplotlib画图的方法
如下所示: # coding=utf-8 import pandas as pd # 读取csv文件 3列取名为 name,sex,births,后面参数格式为names= names1880 = pd.read_csv("names_1880.txt", names=['name', 'sex', 'births']) print names1880 print names1880.groupby('sex').births.sum() 输出如下 最后一行是说按sex分组并计算bir
-
Python如何利用pandas读取csv数据并绘图
目录 如何利用pandas读取csv数据并绘图 绘制图像 展示结果 pandas画pearson相关系数热力图 pearson相关系数计算函数 如何利用pandas读取csv数据并绘图 导包,常用的numpy和pandas,绘图模块matplotlib, import matplotlib.pyplot as plt import pandas as pd import numpy as np fig = plt.figure() ax = fig.add_subplot(111) 读取csv文
-
利用Pandas读取文件路径或文件名称包含中文的csv文件方法
利用Pandas的read_csv函数导入数据文件时,若文件路径或文件名包含中文,会报错,无法导入: import pandas as pd df=pd.read_csv('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') 解决方法如下: import pandas as pd f=open('E:/学习相关/Python/数据样例/用户侧数据/账单.csv') df=pd.read_csv(f) 以上这篇利用Pandas读取文件路径或文件名称包含中文的csv文件方法就是小编
-
如何利用python在剪贴板上读取/写入数据
目录 读取剪贴板上的数据 将数据写入剪贴板 补充:python 剪切板写入文件,产生随机数写入剪切板 总结 读取剪贴板上的数据 先给大家介绍pandas.read_clipboard,从剪贴板读取文本并传递到Read_csv. pandas.read_clipboard(sep='\\s+', **kwargs) 其中参数sep是字段定界符,默认为’\s+’,也就是说将tab和多个空格都当成一样的分隔符. 接下来执行操作,打开表格→选中数据Ctrl+C复制→再执行以下代码 import pand
-
利用pyecharts读取csv并进行数据统计可视化的实现
因为需要一个html形式的数据统计界面,所以做了一个基于pyecharts包的可视化程序,当然matplotlib还是常用的数据可视化包,只不过各有优劣:基本功能概述就是读取csv文件数据,对每列进行数据统计并可视化,最后形成html动态界面,选择pyecharts的最主要原因就是这个动态界面简直非常炫酷. 先上成品图: 数据读取和数据分析模块: #导入csv模块 import csv #导入可视化模块 from matplotlib import pyplot as plt from pyla
-
python 实现读取csv数据,分类求和 再写进 csv
这两天在测试过程中,遇到这样的问题: 数据量很大,一份csv文件的数据与另外一个文件的数据进行对比,但是csv中的文件数据量很大,并且进行统计 ,如果手动单个去对比,会很花时间,吃力不讨好,还容易出错. 比如说,这样的数据 需要对AskPrice值相同对应的AskQuantity 统计出来. 直接上脚本 : import pandas as pd import csv df=pd.read_csv('D:\test\orderBook.csv') df_sum = df.groupby('Ask
-
Python数据分析之pandas读取数据
一.三种数据文件的读取 二.csv.tsv.txt 文件读取 1)CSV文件读取: 语法格式:pandas.read_csv(文件路径) CSV文件内容如下: import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默认返回前5行数据 content.head(3) # 返回前3行数据 content.shape # 返回
-
使用Python pandas读取CSV文件应该注意什么?
示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3,周娟,女,1998-03-25,合肥,护士,音乐,跑步 4,赵盈盈,Female,2001-6-32,,学生,画画 5,郑强强,男,1991-03-05,南京(nanjing),律师,历史-政治 如果一切正常的话,在Jupyter Notebook 中应该显示以下内容:
-
Python pandas读取CSV文件的注意事项(适合新手)
目录 前言 示例文件 文件编码 空值 日期错误 函数映射 方法1:直接使用labmda表达式 方法二:使用自定义函数 方法三:使用数值字典映射 总结 前言 本文是给使用pandas的新手而写,主要列出一些常见的问题,根据笔者所踩过的坑,进行归纳总结,希望对读者有所帮助. 示例文件 将以下内容保存为文件 people.csv. id,姓名,性别,出生日期,出生地,职业,爱好 1,张小三,m,1992-10-03,北京,工程师,足球 2,李云义,m,1995-02-12,上海,程序员,读书 下棋 3
-
Python Pandas读取csv/tsv文件(read_csv,read_table)的区别
目录 前言 read_csv()和read_table()之间的区别 读取没有标题的CSV 读取有标题的CSV 读取有index的CSV 指定(选择)要读取的列 跳过(排除)行的读取 skiprows skipfooter nrows 通过指定类型dtype进行读取 NaN缺失值的处理 读取使用zip等压缩的文件 tsv的读取 总结 前言 要将csv和tsv文件读取为pandas.DataFrame格式,可以使用Pandas的函数read_csv()或read_table(). 在此 read_
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf