教你用PyTorch部署模型的方法
目录
- 导读
- 使用Docker安装
- Handlers
- 导出你的模型
- 用模型进行服务
- 总结
导读
演示了使用PyTorch最近发布的新工具torchserve来进行PyTorch模型的部署。

最近,PyTorch推出了名为torchserve.的新生产框架来为模型提供服务。我们看一下今天的roadmap:
1、使用Docker安装
2、导出模型
3、定义handler
4、保存模型
为了展示torchserve,我们将提供一个经过全面训练的ResNet34进行图像分类的服务。
使用Docker安装
官方文档:https://github.com/pytorch/serve/blob/master/README.md##install-torchserve
安装torchserve最好的方法是使用docker。你只需要把镜像拉下来。
可以使用以下命令保存最新的镜像。
docker pull pytorch/torchserve:latest
所有可用的tags:https://hub.docker.com/r/pytorch/torchserve/tags
关于docker和torchserve的更多信息:https://github.com/pytorch/serve#quick-start-with-docker
Handlers
官方文档:https://github.com/pytorch/serve/blob/master/docs/custom_service.md
处理程序负责使用模型对一个或多个HTTP请求进行预测。
默认 handlers
Torchserve支持以下默认 handlers
image_classifierobject_detectortext_classifierimage_segmenter
但是请记住,它们都不支持batching请求!
自定义 handlers
torchserve提供了一个丰富的接口,可以做几乎所有你想做的事情。一个Handler是一个必须有三个函数的类。
- preprocess
- inference
- postprocess
你可以创建你自己的类或者子类BaseHandler。子类化BaseHandler 的主要优点是可以在self.model上访问加载的模型。下面的代码片段展示了如何子类化BaseHandler。

子类化BaseHandler以创建自己的handler
回到图像分类的例子。我们需要
- 从每个请求中获取图像并对其进行预处理
- 从模型中得到预测
- 发送回一个响应
预处理
.preprocess函数接受请求数组。假设我们正在向服务器发送一个图像,可以从请求的data或body字段访问序列化的图像。因此,我们可以遍历所有请求并单独预处理每个图像。完整的代码如下所示。

预处理每个请求中的每个图像
self.transform是我们的预处理变换,没什么花哨的。对于在ImageNet上训练的模型来说,这是一个经典的预处理步骤。

我们的transform
在我们对每个请求中的每个图像进行预处理之后,我们将它们连接起来创建一个pytorch张量。
推理
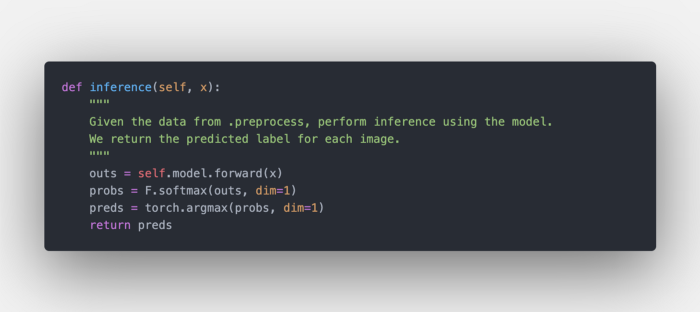
在模型上进行推理
这一步很简单,我们从 .preprocess得到张量。然后对每幅图像提取预测结果。
后处理
现在我们有了对每个图像的预测,我们需要向客户返回一些内容。Torchserve总是返回一个数组。BaseHandler也会自动打开一个.json 文件带有index -> label的映射(稍后我们将看到如何提供这样的文件),并将其存储self.mapping中。我们可以为每个预测返回一个字典数组,其中包含label和index 的类别。

把所有的东西打包到一起,我们的handler是这样的:

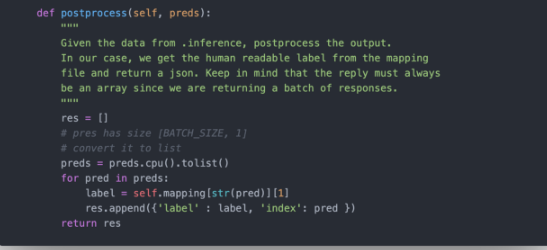
因为所有的处理逻辑都封装在一个类中,所以你可以轻松地对它进行单元测试!
导出你的模型
官方文档:https://github.com/pytorch/serve/tree/master/model-archiver#creating-a-model-archive
Torchserve 需要提供一个.mar文件,简而言之,该文件只是把你的模型和所有依赖打包在一起。要进行打包,首先需要导出经过训练的模型。
导出模型
有三种方法可以导出torchserve的模型。到目前为止,我发现的最好的方法是trace模型并存储结果。这样我们就不需要向torchserve添加任何额外的文件。
让我们来看一个例子,我们将部署一个经过充分训练的ResNet34模型。

按照顺序,我们:
- 加载模型
- 创建一个dummy输入
- 使用
torch.jit.trace来trace模型的输入 - 保存模型
创建 .mar 文件
官方文档:https://github.com/pytorch/serve/blob/master/model-archiver/README.md
你需要安装torch-model-archiver
git clone https://github.com/pytorch/serve.git cd serve/model-archiver pip install .
然后,我们准备好通过使用下面的命令来创建.mar文件。
torch-model-archiver --model-name resnet34 \--version 1.0 \--serialized-file resnet34.pt \--extra-files ./index_to_name.json,./MyHandler.py \--handler my_handler.py \--export-path model-store -f
按照顺序。变量--model-name定义了模型的最终名称。这是非常重要的,因为它将是endpoint的名称空间,负责进行预测。你还可以指定一个--version。--serialized-file指向我们之前创建的存储的 .pt模型。--handler 是一个python文件,我们在其中调用我们的自定义handler。一般来说,是这样的:
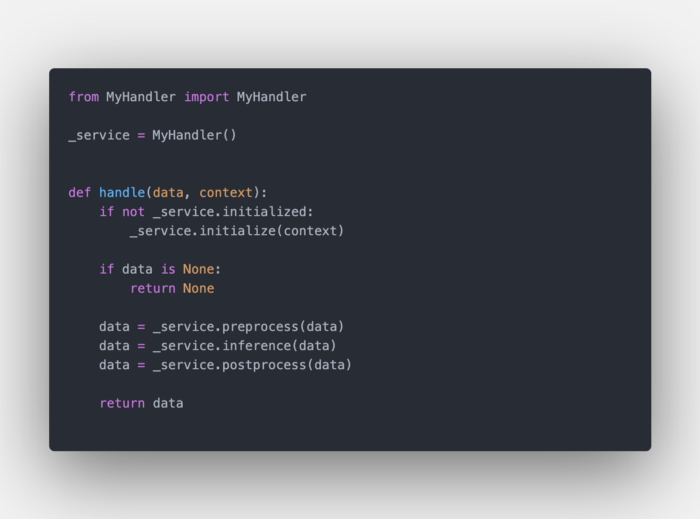
my_handler.py
它暴露了一个handle函数,我们从该函数调用自定义handler中的方法。你可以使用默认名称来使用默认handler(例如,--handler image_classifier)。
在--extra-files中,你需要将路径传递给你的handlers正在使用的所有文件。在本例中,我们必须向.json文件中添加路径。使用所有人类可读标签名称,并在MyHandler.py 中定义每个类别。
如果你传递一个index_to_name.json文件,它将自动加载到handler ,并通过self.mapping访问。
--export-path就是 .mar存放的地方,我还添加了-f来覆盖原有的文件。
如果一切顺利的话,你可以看到resnet34.mar存放在./model-store路径中。
用模型进行服务
这是一个简单的步骤,我们可以运行带有所有必需参数的torchserve docker容器。
docker run --rm -it \-p 3000:8080 -p 3001:8081 \-v $(pwd)/model-store:/home/model-server/model-store pytorch/torchserve:0.1-cpu \torchserve --start --model-store model-store --models resnet34=resnet34.mar
我将容器端口8080和8081分别绑定到3000和3001(8080/8081已经在我的机器中使用)。然后,我从./model-store 创建一个volume。最后,我通过padding model-store并通过key-value列表的方式指定模型的名称来调用torchserve。
这里,torchserve有一个endpoint /predictions/resnet34,我们可以通过发送图像来预测。这可以使用curl来实现。
curl -X POST http://127.0.0.1:3000/predictions/resnet34 -T inputs/kitten.jpg

kitten.jpg
回复:
{
"label": "tiger_cat",
"index": 282
}
工作正常!
总结
使用docker安装torchserve
默认以及自定义handlers
模型打包生成
使用docker提供模型服务到此这篇关于用PyTorch部署模型的文章就介绍到这了,更多相关PyTorch部署模型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于Pytorch中模型的保存与迁移问题
目录 1 引言 2 模型的保存与复用 2.1 查看网络模型参数 2.2 载入模型进行推断 2.3 载入模型进行训练 2.4 载入模型进行迁移 3 总结 1 引言 各位朋友大家好,欢迎来到月来客栈.今天要和大家介绍的内容是如何在Pytorch框架中对模型进行保存和载入.以及模型的迁移和再训练.一般来说,最常见的场景就是模型完成训练后的推断过程.一个网络模型在完成训练后通常都需要对新样本进行预测,此时就只需要构建模型的前向传播过程,然后载入已训练好的参数初始化网络即可. 第2个场景就是模型的再训练过
-

如何将pytorch模型部署到安卓上的方法示例
目录 模型转化 安卓部署 新建项目 导入包 页面文件 模型推理 这篇文章演示如何将训练好的pytorch模型部署到安卓设备上.我也是刚开始学安卓,代码写的简单. 环境: pytorch版本:1.10.0 模型转化 pytorch_android支持的模型是.pt模型,我们训练出来的模型是.pth.所以需要转化才可以用.先看官网上给的转化方式: import torch import torchvision from torch.utils.mobile_optimizer import opti
-
pytorch 使用半精度模型部署的操作
背景 pytorch作为深度学习的计算框架正得到越来越多的应用. 我们除了在模型训练阶段应用外,最近也把pytorch应用在了部署上. 在部署时,为了减少计算量,可以考虑使用16位浮点模型,而训练时涉及到梯度计算,需要使用32位浮点,这种精度的不一致经过测试,模型性能下降有限,可以接受. 但是推断时计算量可以降低一半,同等计算资源下,并发度可提升近一倍 具体方法 在pytorch中,一般模型定义都继承torch.nn.Moudle,torch.nn.Module基类的half()方法会把所有参数
-
教你用PyTorch部署模型的方法
目录 导读 使用Docker安装 Handlers 导出你的模型 用模型进行服务 总结 导读 演示了使用PyTorch最近发布的新工具torchserve来进行PyTorch模型的部署. 最近,PyTorch推出了名为torchserve.的新生产框架来为模型提供服务.我们看一下今天的roadmap: 1.使用Docker安装 2.导出模型 3.定义handler 4.保存模型 为了展示torchserve,我们将提供一个经过全面训练的ResNet34进行图像分类的服务. 使用Docker安装
-
在C++中加载TorchScript模型的方法
本教程已更新为可与PyTorch 1.2一起使用 顾名思义,PyTorch的主要接口是Python编程语言.尽管Python是合适于许多需要动态性和易于迭代的场景,并且是首选的语言,但同样的,在许多情况下,Python的这些属性恰恰是不利的.后者通常适用的一种环境是要求生产-低延迟和严格部署.对于生产场景,即使只将C ++绑定到Java,Rust或Go之类的另一种语言中,它也是经常选择的语言.以下各段将概述PyTorch提供的从现有Python模型到可以完全从C ++加载和执行的序列化表示形式的
-
如何使用Pytorch搭建模型
1 模型定义 和TF很像,Pytorch也通过继承父类来搭建模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化模型内部结构和进行推理.其它功能比如计算loss和训练函数,你也可以继承在里面,当然这是可选的.下面搭建一个判别MNIST手写字的Demo,首先给出模型代码: import numpy as np import matplotlib.pyplot as plt import
-
使用Pytorch搭建模型的步骤
本来是只用Tenorflow的,但是因为TF有些Numpy特性并不支持,比如对数组使用列表进行切片,所以只能转战Pytorch了(pytorch是支持的).还好Pytorch比较容易上手,几乎完美复制了Numpy的特性(但还有一些特性不支持),怪不得热度上升得这么快. 1 模型定义 和TF很像,Pytorch也通过继承父类来搭建自定义模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化
-
PyTorch两种安装方法
本文安装的是pytorch1.4版本(cpu版本) 首先需要安装Anaconda 是否需要安装基于cuda的PyTorch版本呢? 对于普通笔记本来说即使有显卡性能也不高,跑不动层数较深的深度学习网络,所以就不用装cuda啦.实际应用时深度学习肯定离不开基于高性能GPU的cuda,作为一般的笔记本,基本都跑不动数据量较大的模型,所以安装CPU版的PyTorch即可.以后如果继续进行深度学习的研究或开发,都会基于高性能服务器,此时安装PyTorch版本肯定是选择有cuda的版本了. 然后进入PyT
-
教你利用PyTorch实现sin函数模拟
目录 一.简介 二.第一种方法 三.第二种方法 四.总结 一.简介 本文旨在使用两种方法来实现sin函数的模拟,具体的模拟方法是使用机器学习来实现的,我们使用Python的torch模块进行机器学习,从而为sin确定多项式的系数. 二.第一种方法 # 这个案例相当于是使用torch来模拟sin函数进行计算啦. # 通过3次函数来模拟sin函数,实现类似于机器学习的操作. import torch import math dtype = torch.float # 数据的类型 device = t
-
pytorch部署到jupyter中的问题及解决方案
目录 pytorch部署到jupyter中 两种解决方案 pytorch部署到jupyter中 在安装Aconda的同时,会将jupyter notebook一起安装,不过这里的jupyter notebook是base中的jupyter notebook二不是pytorch中的jupyter notebook,因此并不能在此jupyter notebook运行torch包.base中的jupyter: 两种解决方案 一.base中重新安装pytorch二.pytorch中安装jupyter n
-
五步教你用Nginx部署Vue项目及解决动态路由刷新404问题
目录 步骤一:改端口 步骤二: 打包 步骤三:将dist文件夹上传到服务器上 步骤四:修改nginx.conf(重中之重) 步骤五:重启nginx 总结 期末月前本来部署过一次,昨天部署的时候发现又给忘了,而且出了很多问题,在这统一汇总一下. 步骤一:改端口 在vue.config.js下的devServer把host改成服务器的地址 步骤二: 打包 用npm run build打包,最后是这样的,并且目录下多了个dist文件夹 步骤三:将dist文件夹上传到服务器上 我用的xshell,没办法
-
linux下部署kodexplorer的方法
环境为xampp. 首先将解压完的目录复制到我们的xampp中的应用的目录中,默认为htdocs目录: sudo cp -r ~/kodexplorer3.21/ /opt/lampp/htdocs/ 注意,要将其中路径换成你的目录 然后,为htdocs目录下的kodexplorer以及kodexplorer下的data目录添加写权限: sudo chmod +022 kodexplorer/ sudo chmod -R 777 kodexplorer/data/ 以上这篇linux下部署kod