python构建指数平滑预测模型示例
指数平滑法
其实我想说自己百度的…
只有懂的人才会找到这篇文章…
不懂的人…看了我的文章…还是不懂哈哈哈
指数平滑法相比于移动平均法,它是一种特殊的加权平均方法。简单移动平均法用的是算术平均数,近期数据对预测值的影响比远期数据要大一些,而且越近的数据影响越大。指数平滑法正是考虑了这一点,并将其权值按指数递减的规律进行分配,越接近当前的数据,权重越大;反之,远离当前的数据,其权重越小。指数平滑法按照平滑的次数,一般可分为一次指数平滑法、二次指数平滑法和三次指数平滑法等。然而一次指数平滑法适用于无趋势效应、呈平滑趋势的时间序列的预测和分析,二次指数平滑法多适用于呈线性变化的时间序列预测。
具体公式还是百度吧…
材料
1.python3.5
2.numpy
3.matplotlib
4.国家社科基金1995-2015年立项数据
需求
预测2016年和2017年国家社科基金项目立项数量
数据
#year time_id number 1994 1 10 1995 2 3 1996 3 27 1997 4 13 1998 5 12 1999 6 13 2000 7 14 2001 8 23 2002 9 32 2003 10 30 2004 11 36 2005 12 40 2006 13 58 2007 14 51 2008 15 73 2009 16 80 2010 17 106 2011 18 127 2012 19 135 2013 20 161 2014 21 149 2015 22 142
代码
# -*- coding: utf-8 -*-
# @Date : 2017-04-11 21:27:00
# @Author : Alan Lau (rlalan@outlook.com)
# @Language : Python3.5
import numpy as np
from matplotlib import pyplot as plt
#指数平滑公式
def exponential_smoothing(alpha, s):
s2 = np.zeros(s.shape)
s2[0] = s[0]
for i in range(1, len(s2)):
s2[i] = alpha*s[i]+(1-alpha)*s2[i-1]
return s2
#绘制预测曲线
def show_data(new_year, pre_year, data, s_pre_double, s_pre_triple):
year, time_id, number = data.T
plt.figure(figsize=(14, 6), dpi=80)#设置绘图区域的大小和像素
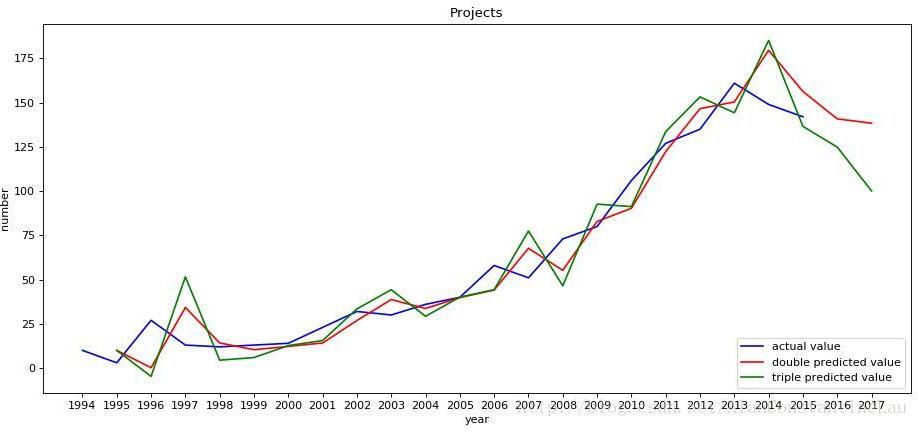
plt.plot(year, number, color='blue', label="actual value")#将实际值的折线设置为蓝色
plt.plot(new_year[1:], s_pre_double[2:],color='red', label="double predicted value")#将二次指数平滑法计算的预测值的折线设置为红色
plt.plot(new_year[1:], s_pre_triple[2:],color='green', label="triple predicted value")#将三次指数平滑法计算的预测值的折线设置为绿色
plt.legend(loc='lower right')#显示图例的位置,这里为右下方
plt.title('Projects')
plt.xlabel('year')#x轴标签
plt.ylabel('number')#y轴标签
plt.xticks(new_year)#设置x轴的刻度线为new_year
plt.show()
def main():
alpha = .70#设置alphe,即平滑系数
pre_year = np.array([2016, 2017])#将需要预测的两年存入numpy的array对象里
data_path = r'data1.txt'#设置数据路径
data = np.loadtxt(data_path)#用numpy读取数据
year, time_id, number = data.T#将数据分别赋值给year, time_id, number
initial_line = np.array([0, 0, number[0]])#初始化,由于平滑指数是根据上一期的数值进行预测的,原始数据中的最早数据为1995,没有1994年的数据,这里定义1994年的数据和1995年数据相同
initial_data = np.insert(data, 0, values=initial_line, axis=0)#插入初始化数据
initial_year, initial_time_id, initial_number = initial_data.T#插入初始化年
s_single = exponential_smoothing(alpha, initial_number)#计算一次指数平滑
s_double = exponential_smoothing(alpha, s_single)#计算二次平滑字数,二次平滑指数是在一次指数平滑的基础上进行的,三次指数平滑以此类推
a_double = 2*s_single-s_double#计算二次指数平滑的a
b_double = (alpha/(1-alpha))*(s_single-s_double)#计算二次指数平滑的b
s_pre_double = np.zeros(s_double.shape)#建立预测轴
for i in range(1, len(initial_time_id)):
s_pre_double[i] = a_double[i-1]+b_double[i-1]#循环计算每一年的二次指数平滑法的预测值,下面三次指数平滑法原理相同
pre_next_year = a_double[-1]+b_double[-1]*1#预测下一年
pre_next_two_year = a_double[-1]+b_double[-1]*2#预测下两年
insert_year = np.array([pre_next_year, pre_next_two_year])
s_pre_double = np.insert(s_pre_double, len(s_pre_double), values=np.array([pre_next_year, pre_next_two_year]), axis=0)#组合预测值
s_triple = exponential_smoothing(alpha, s_double)
a_triple = 3*s_single-3*s_double+s_triple
b_triple = (alpha/(2*((1-alpha)**2)))*((6-5*alpha)*s_single -2*((5-4*alpha)*s_double)+(4-3*alpha)*s_triple)
c_triple = ((alpha**2)/(2*((1-alpha)**2)))*(s_single-2*s_double+s_triple)
s_pre_triple = np.zeros(s_triple.shape)
for i in range(1, len(initial_time_id)):
s_pre_triple[i] = a_triple[i-1]+b_triple[i-1]*1 + c_triple[i-1]*(1**2)
pre_next_year = a_triple[-1]+b_triple[-1]*1 + c_triple[-1]*(1**2)
pre_next_two_year = a_triple[-1]+b_triple[-1]*2 + c_triple[-1]*(2**2)
insert_year = np.array([pre_next_year, pre_next_two_year])
s_pre_triple = np.insert(s_pre_triple, len(s_pre_triple), values=np.array([pre_next_year, pre_next_two_year]), axis=0)
new_year = np.insert(year, len(year), values=pre_year, axis=0)
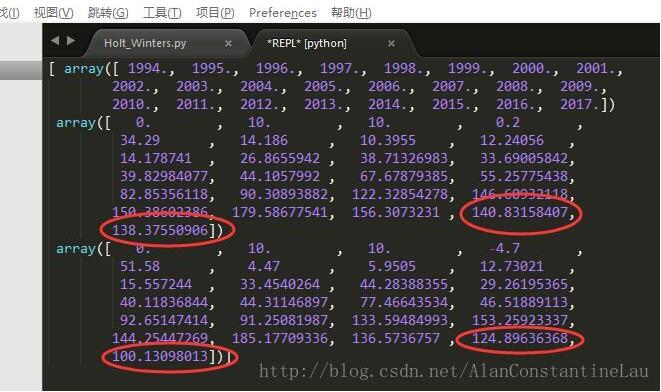
output = np.array([new_year, s_pre_double, s_pre_triple])
print(output)
show_data(new_year, pre_year, data, s_pre_double, s_pre_triple)#传入预测值和数据
if __name__ == '__main__':
main()
预测结果
以上这篇python构建指数平滑预测模型示例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python编程实现使用线性回归预测数据
本文中,我们将进行大量的编程--但在这之前,我们先介绍一下我们今天要解决的实例问题. 1) 预测房子价格 房价大概是我们中国每一个普通老百姓比较关心的问题,最近几年保障啊,小编这点微末工资着实有点受不了. 我们想预测特定房子的价值,预测依据是房屋面积. 2) 预测下周哪个电视节目会有更多的观众 闪电侠和绿箭侠是我最喜欢的电视节目,特别是绿箭侠,当初追的昏天黑地的,不过后来由于一些原因,没有接着往下看.我想看看下周哪个节目会有更多的观众. 3) 替换数据集中的缺失值 我们经常要和带有缺失值的数据集
-
使用python实现画AR模型时序图
背景: 用python画AR模型的时序图. 结果: 代码: import numpy as np import matplotlib.pyplot as plt """ AR(1)的时序图:x[t]=a*x[t-1]+e """ num = 2000 e = np.random.rand(num) x = np.empty(num) """ 平稳AR(1) """ a = -0.5 x[
-
Tensorflow模型实现预测或识别单张图片
利用Tensorflow训练好的模型,图片进行预测和识别,并输出相应的标签和预测概率. 如果想要多张图片,可以进行批次加载和预测,这里仅用单张图片进行演示. 模型文件: 预测图片: 这里直接贴代码,都有注释,应该很好理解 import tensorflow as tf import inference image_size = 128 # 输入层图片大小 # 模型保存的路径和文件名 MODEL_SAVE_PATH = "model/" MODEL_NAME = "model.
-

python实现BP神经网络回归预测模型
神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位.模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数.这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大.模型修改如下: 代码如下: #coding: utf8 '''' author: Huangyuliang ''' import json import random impo
-
python构建指数平滑预测模型示例
指数平滑法 其实我想说自己百度的- 只有懂的人才会找到这篇文章- 不懂的人-看了我的文章-还是不懂哈哈哈 指数平滑法相比于移动平均法,它是一种特殊的加权平均方法.简单移动平均法用的是算术平均数,近期数据对预测值的影响比远期数据要大一些,而且越近的数据影响越大.指数平滑法正是考虑了这一点,并将其权值按指数递减的规律进行分配,越接近当前的数据,权重越大:反之,远离当前的数据,其权重越小.指数平滑法按照平滑的次数,一般可分为一次指数平滑法.二次指数平滑法和三次指数平滑法等.然而一次指数平滑法适用于无趋
-
Python程序包的构建和发布过程示例详解
关于我 编程界的一名小程序猿,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. 联系:hylinux1024@gmail.com 当我们开发了一个开源项目时,就希望把这个项目打包然后发布到 pypi.org 上,别人就可以通过 pip install 的命令进行安装.本文的教程来自于 Python 官方文档 , 如有不正确的地方欢迎评论拍砖. 0x00 创建项目 本文使用到的项目目录为 ➜ packaging-tuto
-
Python实现构建一个仪表板的示例代码
目录 简介 内容 1.创建一个Python文件 2.在终端上运行该文件,在本地机器上显示 3.在Heroku上部署仪表板 总结 这将为我们的团队节省每天重复的数据处理时间...... 简介 如果你目前在一个数据或商业智能团队工作,你的任务之一可能是制作一些每日.每周或每月的报告. 虽然获得这些报告并不困难,但还是需要花费不少时间.我们的宝贵时间应该花在更困难的任务上,如训练神经网络或建立数据管道架构. 因此,对于这些平凡的重复性报告,节省我们时间的最好方法是建立一个网络应用程序,其他团队可以自己
-
Python人工智能构建简单聊天机器人示例详解
目录 引言 什么是聊天机器人? 准备工作 创建聊天机器人 导入必要的库 定义响应集合 创建聊天机器人 运行聊天机器人 完整代码 结论 展望 引言 人工智能是计算机科学中一个非常热门的领域,近年来得到了越来越多的关注.它通过模拟人类思考过程和智能行为来实现对复杂任务的自主处理和学习,已经被广泛应用于许多领域,包括语音识别.自然语言处理.机器人技术.图像识别和推荐系统等. 本文将介绍如何使用Python构建一个简单的聊天机器人,以展示人工智能的基本原理和应用.我们将使用Python语言和自然语言处理
-
Python构建XML树结构的方法示例
本文实例讲述了Python构建XML树结构的方法.分享给大家供大家参考,具体如下: 1.构建XML元素 #encoding=utf-8 from xml.etree import ElementTree as ET import sys root=ET.Element('color') #用Element类构建标签 root.text=('black') #设置元素内容 tree=ET.ElementTree(root) #创建数对象,参数为根节点对象 tree.write(sys.stdout
-
python opencv之SIFT算法示例
本文介绍了python opencv之SIFT算法示例,分享给大家,具体如下: 目标: 学习SIFT算法的概念 学习在图像中查找SIFT关键的和描述符 原理: (原理部分自己找了不少文章,内容中有不少自己理解和整理的东西,为了方便快速理解内容和能够快速理解原理,本文尽量不使用数学公式,仅仅使用文字来描述.本文中有很多引用别人文章的内容,仅供个人记录使用,若有错误,请指正出来,万分感谢) 之前的harris算法和Shi-Tomasi 算法,由于算法原理所致,具有旋转不变性,在目标图片发生旋转时依然
-
Python构建网页爬虫原理分析
既然本篇文章说到的是Python构建网页爬虫原理分析,那么小编先给大家看一下Python中关于爬虫的精选文章: python实现简单爬虫功能的示例 python爬虫实战之最简单的网页爬虫教程 网络爬虫是当今最常用的系统之一.最流行的例子是 Google 使用爬虫从所有网站收集信息.除了搜索引擎之外,新闻网站还需要爬虫来聚合数据源.看来,只要你想聚合大量的信息,你可以考虑使用爬虫. 建立一个网络爬虫有很多因素,特别是当你想扩展系统时.这就是为什么这已经成为最流行的系统设计面试问题之一.在这篇文章中
-
python构建深度神经网络(续)
这篇文章在前一篇文章:python构建深度神经网络(DNN)的基础上,添加了一下几个内容: 1) 正则化项 2) 调出中间损失函数的输出 3) 构建了交叉损失函数 4) 将训练好的网络进行保存,并调用用来测试新数据 1 数据预处理 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017-03-12 15:11 # @Author : CC # @File : net_load_data.py from numpy import
-
python构建深度神经网络(DNN)
本文学习Neural Networks and Deep Learning 在线免费书籍,用python构建神经网络识别手写体的一个总结. 代码主要包括两三部分: 1).数据调用和预处理 2).神经网络类构建和方法建立 3).代码测试文件 1)数据调用: #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2017-03-12 15:11 # @Author : CC # @File : net_load_data.py # @Soft
-
python opencv之分水岭算法示例
本文介绍了python opencv之分水岭算法示例,分享给大家,具体如下: 目标 使用分水岭算法对基于标记的图像进行分割 使用函数cv2.watershed() 原理: 灰度图像可以被看成拓扑平面,灰度值高的区域可以看出山峰,灰度值低的区域可以看成是山谷.向每一个山谷当中灌不同颜色的水.水位升高,不同山谷的水会汇合,为防止不同山谷的水汇合,小在汇合处建立起堤坝.然后继续灌水,然后再建立堤坝,直到山峰都掩模.构建好的堤坝就是图像的分割. 此方法通常会得到过渡分割的结果,因为图像中的噪声以及其他因