python模拟哔哩哔哩滑块登入验证的实现
准备工具
- pip3 install PIL
- pip3 install opencv-python
- pip3 install numpy
- 谷歌驱动
建议指定清华源下载速度会更快点
使用方法 : pip3 install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple/opencv-python/
谷歌驱动
谷歌驱动下载链接 :http://npm.taobao.org/mirrors/chromedriver/
前言
本篇文章采用的是cv2的Canny边缘检测算法进行图像识别匹配。
Canny边缘检测算法参考链接:https://www.jb51.net/article/185336.htm
具体使用的是Canny的matchTemplate方法进行模糊匹配,匹配方法用CV_TM_CCOEFF_NORMED归一化相关系数匹配。得出的max_loc就是匹配出来的位置信息。从而达到位置的距离。
难点
- 由于图像采用放大的效果匹配出的距离偏大,难以把真实距离,并存在误差。
- 由于哔哩哔哩滑块验证进一步采取做了措施,如果滑动时间过短,会导致验证登入失败。所以我这里采用变速的方法,在相同时间内滑动不同的距离。
- 误差的存在是必不可少的,有时会导致验证失败,这都是正常现象。
流程
1.实例化谷歌浏览器 ,并打开哔哩哔哩登入页面。
2.点击登陆,弹出滑动验证框。
3.全屏截图、后按照尺寸裁剪各两张。
5.模糊匹配两张图片,从而获取匹配结果以及位置信息 。
6.将位置信息与页面上的位移距离转化,并尽可能少的减少误差 。
7.变速的拖动滑块到指定位置,从而达到模拟登入。
效果图
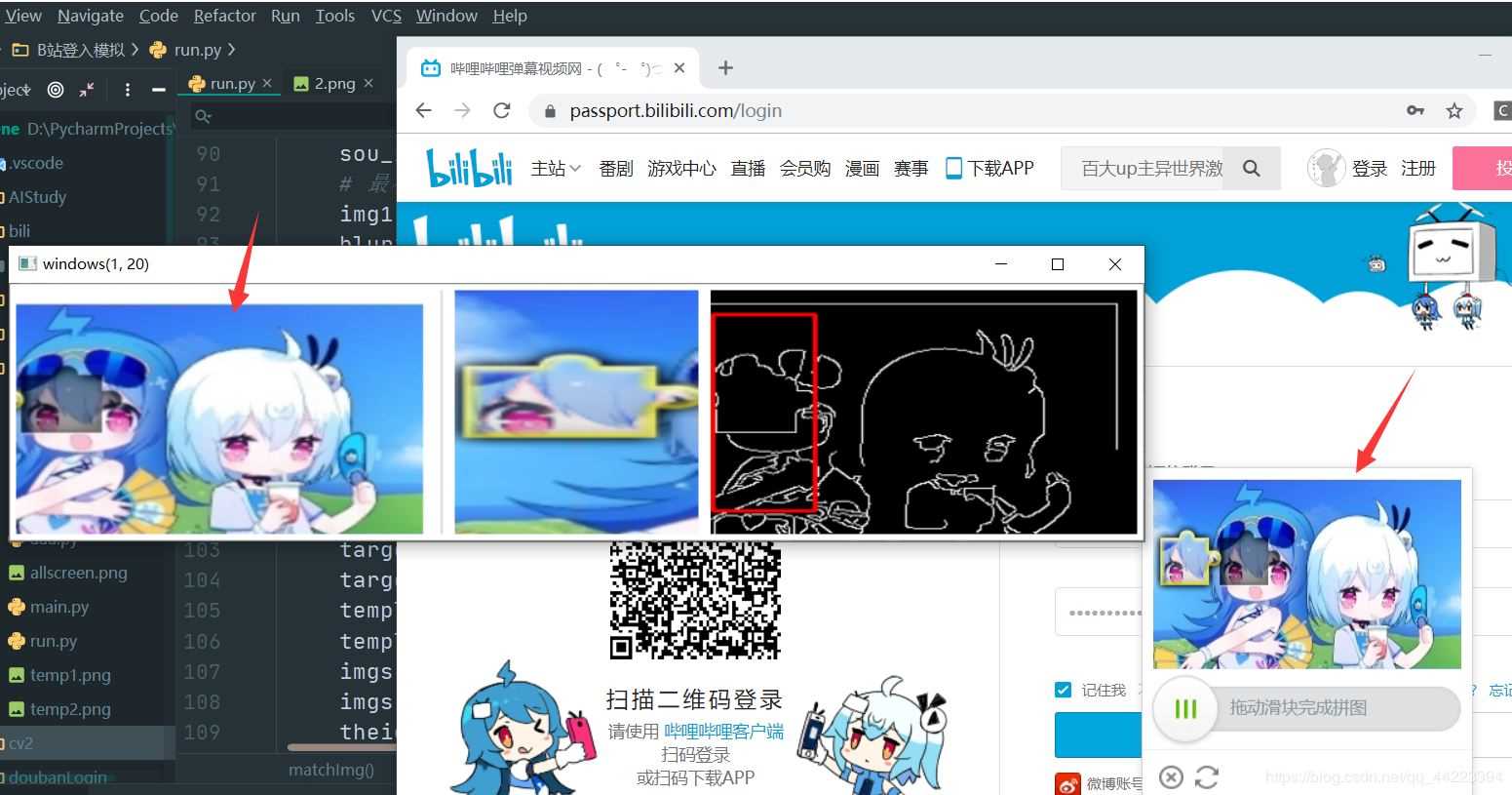
代码实例
库安装好后,然后填写配置区域后即可运行。
from PIL import Image
from time import sleep
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import cv2
import numpy as np
import math
############ 配置区域 #########
zh='' #账号
pwd='' #密码
# chromedriver的路径
chromedriver_path = "C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe"
####### end #########
options = webdriver.ChromeOptions()
options.add_argument('--no-sandbox')
options.add_argument('--window-size=1020,720')
# options.add_argument('--start-maximized') # 浏览器窗口最大化
options.add_argument('--disable-gpu')
options.add_argument('--hide-scrollbars')
options.add_argument('test-type')
options.add_experimental_option("excludeSwitches", ["ignore-certificate-errors",
"enable-automation"]) # 设置为开发者模式
driver = webdriver.Chrome(options=options, executable_path=chromedriver_path)
driver.get('https://passport.bilibili.com/login')
# 登入
def login():
driver.find_element_by_id("login-username").send_keys(zh)
driver.find_element_by_id("login-passwd").send_keys(pwd)
driver.find_element_by_css_selector("#geetest-wrap > div > div.btn-box > a.btn.btn-login").click()
print("点击登入")
# 整个图,跟滑块整个图
def screen(screenXpath):
img = WebDriverWait(driver, 20).until(
EC.visibility_of_element_located((By.XPATH, screenXpath))
)
driver.save_screenshot("allscreen.png") # 对整个浏览器页面进行截图
left = img.location['x']+160 #往右
top = img.location['y']+60 # 往下
right = img.location['x'] + img.size['width']+230 # 往左
bottom = img.location['y'] + img.size['height']+110 # 往上
im = Image.open('allscreen.png')
im = im.crop((left, top, right, bottom)) # 对浏览器截图进行裁剪
im.save('1.png')
print("截图完成1")
screen_two(screenXpath)
screen_th(screenXpath)
matchImg('3.png','2.png')
# 滑块部分图
def screen_two(screenXpath):
img = WebDriverWait(driver, 20).until(
EC.visibility_of_element_located((By.XPATH, screenXpath))
)
left = img.location['x'] + 160
top = img.location['y'] + 80
right = img.location['x'] + img.size['width']-30
bottom = img.location['y'] + img.size['height'] + 90
im = Image.open('allscreen.png')
im = im.crop((left, top, right, bottom)) # 对浏览器截图进行裁剪
im.save('2.png')
print("截图完成2")
# 滑块剩余部分图
def screen_th(screenXpath):
img = WebDriverWait(driver, 20).until(
EC.visibility_of_element_located((By.XPATH, screenXpath))
)
left = img.location['x'] + 220
top = img.location['y'] + 60
right = img.location['x'] + img.size['width']+230
bottom = img.location['y'] + img.size['height'] +110
im = Image.open('allscreen.png')
im = im.crop((left, top, right, bottom)) # 对浏览器截图进行裁剪
im.save('3.png')
print("截图完成3")
#图形匹配
def matchImg(imgPath1,imgPath2):
imgs = []
#展示
sou_img1= cv2.imread(imgPath1)
sou_img2 = cv2.imread(imgPath2)
# 最小阈值100,最大阈值500
img1 = cv2.imread(imgPath1, 0)
blur1 = cv2.GaussianBlur(img1, (3, 3), 0)
canny1 = cv2.Canny(blur1, 100, 500)
cv2.imwrite('temp1.png', canny1)
img2 = cv2.imread(imgPath2, 0)
blur2 = cv2.GaussianBlur(img2, (3, 3), 0)
canny2 = cv2.Canny(blur2, 100, 500)
cv2.imwrite('temp2.png', canny2)
target = cv2.imread('temp1.png')
template = cv2.imread('temp2.png')
# 调整大小
target_temp = cv2.resize(sou_img1, (350, 200))
target_temp = cv2.copyMakeBorder(target_temp, 5, 5, 5, 5, cv2.BORDER_CONSTANT, value=[255, 255, 255])
template_temp = cv2.resize(sou_img2, (200, 200))
template_temp = cv2.copyMakeBorder(template_temp, 5, 5, 5, 5, cv2.BORDER_CONSTANT, value=[255, 255, 255])
imgs.append(target_temp)
imgs.append(template_temp)
theight, twidth = template.shape[:2]
# 匹配跟拼图
result = cv2.matchTemplate(target, template, cv2.TM_CCOEFF_NORMED)
cv2.normalize( result, result, 0, 1, cv2.NORM_MINMAX, -1 )
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result)
# 画圈
cv2.rectangle(target,max_loc,(max_loc[0]+twidth,max_loc[1]+theight),(0,0,255),2)
target_temp_n = cv2.resize(target, (350, 200))
target_temp_n = cv2.copyMakeBorder(target_temp_n, 5, 5, 5, 5, cv2.BORDER_CONSTANT, value=[255, 255, 255])
imgs.append(target_temp_n)
imstack = np.hstack(imgs)
cv2.imshow('windows'+str(max_loc), imstack)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 计算距离
print(max_loc)
dis=str(max_loc).split()[0].split('(')[1].split(',')[0]
x_dis=int(dis)+135
t(x_dis)
#拖动滑块
def t(distances):
draggable = driver.find_element_by_css_selector('div.geetest_slider.geetest_ready > div.geetest_slider_button')
ActionChains(driver).click_and_hold(draggable).perform() #抓住
print(driver.title)
num=getNum(distances)
sleep(3)
for distance in range(1,int(num)):
print('移动的步数: ',distance)
ActionChains(driver).move_by_offset(xoffset=distance, yoffset=0).perform()
sleep(0.25)
ActionChains(driver).release().perform() #松开
# 计算步数
def getNum(distances):
p = 1+4*distances
x1 = (-1 + math.sqrt(p)) / 2
x2 = (-1 - math.sqrt(p)) / 2
print(x1,x2)
if x1>=0 and x2<0:
return x1+2
elif(x1<0 and x2>=0):
return x2+2
else:
return x1+2
def main():
login()
sleep(5)
screenXpath = '/html/body/div[2]/div[2]/div[6]/div/div[1]/div[1]/div/a/div[1]/div/canvas[2]'
screen(screenXpath)
sleep(5)
if __name__ == '__main__':
main()
有能力的可以研究一下思路,然后写出更好的解决办法。
到此这篇关于python模拟哔哩哔哩滑块登入验证的实现的文章就介绍到这了,更多相关python 滑块登入验证内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python滑块验证码的破解实现
破解滑块验证码的思路主要有2种: 获得一张完整的背景图和一张有缺口的图片,两张图片进行像素上的一一对比,找出不一样的坐标. 获得一张有缺口的图片和需要验证的小图,两张图片进行二极化以及归一化,确定小图在图片中间的坐标. 之后就要使用初中物理知识了,使用直线加速度模仿人手动操作 本次就使用第2种,第一种比较简单.废话不多说,直接上代码: 以下均利用无头浏览器进行获取 获得滑块验证的小图片 def get_image1(self,driver): """ 获取滑块验证缺口小图片
-
python3 破解 geetest(极验)的滑块验证码功能
下面一段代码给大家介绍python破解geetest 验证码功能,具体代码如下所示: from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.action_chains import ActionChains import PIL.Image as image import time,re, random import
-
Python破解BiliBili滑块验证码的思路详解(完美避开人机识别)
准备工作 B站登录页 https://passport.bilibili.com/login python3 pip install selenium (webdriver框架) pip install PIL (图片处理) chrome driver:http://chromedriver.storage.googleapis.com/index.html firefox driver:https://github.com/mozilla/geckodriver/releases B站的滑块验
-
Python模拟登录之滑块验证码的破解(实例代码)
模拟登录之滑块验证码的破解,具体代码如下所示: # 图像处理标准库 from PIL import Image # web测试 from selenium import webdriver # 鼠标操作 from selenium.webdriver.common.action_chains import ActionChains # 等待时间 产生随机数 import time, random # 滑块移动轨迹 def get_tracks1(distance): # 初速度 v = 0 #
-
python模拟哔哩哔哩滑块登入验证的实现
准备工具 pip3 install PIL pip3 install opencv-python pip3 install numpy 谷歌驱动 建议指定清华源下载速度会更快点 使用方法 : pip3 install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple/opencv-python/ 谷歌驱动 谷歌驱动下载链接 :http://npm.taobao.org/mirrors/chromedriver/ 前言 本篇文章采用
-
SpringBoot下token短信验证登入登出权限操作(token存放redis,ali短信接口)
SpringBoot下token短信验证登入登出(token存放redis) 不对SpringBoot进行介绍,具体的可以参考官方文档 介绍:token基本使用,redis基本使用 思路:获取短信(验证并限制发送次数,将code存放redis)-->登入(验证并限制错误次数,将用户信息及权限放token,token放redis)-->查询操作(略),主要将前两点,不足的希望指出,谢谢 步骤: 1.整合Redis需要的依赖,yml自行配置,ali短信接口依赖(使用引入外部包的方式) <de
-
Python爬虫模拟登陆哔哩哔哩(bilibili)并突破点选验证码功能
写在前面 今天带给大家一个突破点选验证码的案例,利用爬虫模拟登陆哔哩哔哩,并且把一些采坑的地方给大家强调一下,避免大家想我一样(唉,菜鸡本菜)还是老规矩在文末会附上完整代码,需要的小伙伴自取就好了,能帮助到你的话别忘了点赞关注喔~ 郑重声明:本人目前仅在CSDN这一个平台发布文章,其他小伙伴如果想转载 或者引用请注明引用来源,未经许可不得直接搬运,请尊重创作人的劳动成果,谢谢! 一.需求分析 模拟登陆哔哩哔哩 网站链接: https://passport.bilibili.com
-
Python爬虫破解登陆哔哩哔哩的方法
写在前面 作为一名找不到工作的爬虫菜鸡人士来说,登陆这一块肯定是个比较大的难题. 从今天开始准备一点点对大型网站进行逐个登陆破解.加深自己爬虫水平. 环境搭建 Python 3.7.7环境,Mac电脑测试 Python内置库 第三方库:rsa.urllib.requests PC端登陆 全部代码: '''PC登录哔哩哔哩''' class Bilibili_For_PC(): def __init__(self, **kwargs): for key, value in kwargs.item
-
Python模拟登入的N种方式(建议收藏)
这段时间在研究如何破解官网验证码,然后进行下一步的爬虫操作,然而一个多星期过去了,编写的代码去识别验证码的效率还是很低,尝试用了tesserorc库和百度的API接口,都无济于事,本以为追不上五月的小尾巴,突然想到我尝试了这么多方法何不为一篇破坑博客呢. 现在很多官网都会给出相应的反扒措施,就拿这个登入来说,如果你不登入账号那么你就只能获取微量的信息,甚至获取不了信息,这对我们爬虫来说是非常不友好的,但是我们总不可能每次都需要手动登入吧,一次二次你能接受,大工程呢?既然学了python,而不为用
-
python 模拟网站登录——滑块验证码的识别
普通滑动验证 以http://admin.emaotai.cn/login.aspx为例这类验证码只需要我们将滑块拖动指定位置,处理起来比较简单.拖动之前需要先将滚动条滚动到指定元素位置. import time from selenium import webdriver from selenium.webdriver import ActionChains # 新建selenium浏览器对象,后面是geckodriver.exe下载后本地路径 browser = webdriver.Fire
-
Python爬虫之爬取哔哩哔哩热门视频排行榜
一.bs4解析 import requests from bs4 import BeautifulSoup import datetime if __name__=='__main__': url = 'https://www.bilibili.com/v/popular/rank/all' headers = { //设置自己浏览器的请求头 } page_text=requests.get(url=url,headers=headers).text soup=BeautifulSoup(pag
-
写一个Python脚本下载哔哩哔哩舞蹈区的所有视频
一.抓取列表 首先点开舞蹈区先选择宅舞列表. 然后打开 F12 的控制面板,可以找到一条 https://api.bilibili.com/x/web-interface/newlist?rid=20&type=0&pn=1&ps=20&jsonp=jsonp&callback=jsonCallback_bili_57905715749828263 的 url,其中 rid 是 B 站的小分类,pn 是页数. 小编试着在浏览器将地址打开居然报了 404,可是在控制面
-
python 爬取哔哩哔哩up主信息和投稿视频
项目地址: https://github.com/cgDeepLearn/BilibiliCrawler 项目特点 采取了一定的反反爬策略. Bilibili更改了用户页面的api, 用户抓取解析程序需要重构. 快速开始 拉取项目, git clone https://github.com/cgDeepLearn/BilibiliCrawler.git 进入项目主目录,安装虚拟环境crawlenv(请参考使用说明里的虚拟环境安装). 激活环境并在主目录运行crawl,爬取结果将保存在data目录