MySQL中的redo log和undo log日志详解
MySQL日志系统中最重要的日志为重做日志redo log和归档日志bin log,后者为MySQL Server层的日志,前者为InnoDB存储引擎层的日志。
1 重做日志redo log
1.1 什么是redo log
redo log用于保证事务的持久性,即ACID中的D。
持久性:指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
redo log有两种类型,分别为物理重做日志和逻辑重做日志。在InnoDB中redo log大多数情况下是一个物理日志,记录数据页面的物理变化(实际的数据值)。
1.2 redo log的功能
redo log的主要功能是用于数据库崩溃时的数据恢复。
1.3 redo log的组成
redo log可以分为以下两部分
存储在内存中的重做日志缓冲区存储在磁盘上的重做日志文件
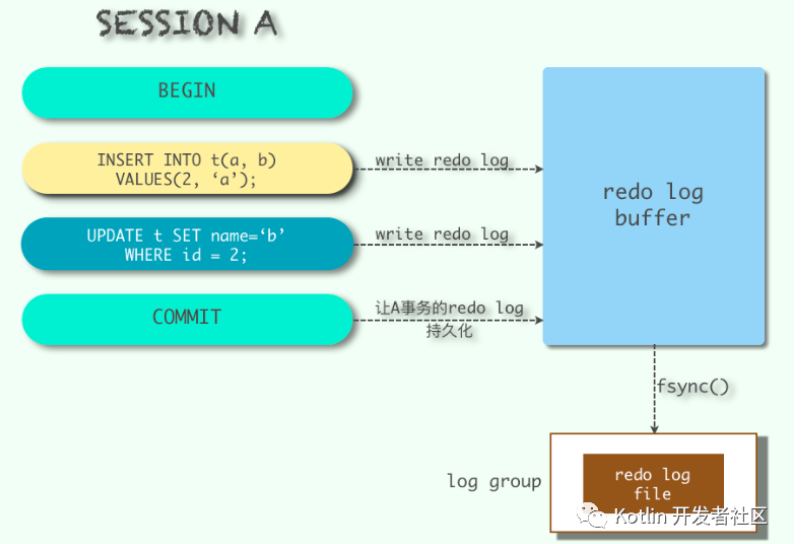
1.4 记录redo log的时机
在完成数据的修改之后,脏页刷入磁盘之前写入重做日志缓冲区。即先修改,再写入。
脏页:内存中与磁盘上不一致的数据(并不是坏的!)
在以下情况下,redo log由重做日志缓冲区写入磁盘上的重做日志文件。
- redo log buffer的日志占据redo log buffer总容量的一半时,将redo log写入磁盘。
- 一个事务提交时,他的redo log都刷入磁盘,这样可以保证数据绝不丢失(最常见的情况)。注意这时内存中的脏页可能尚未全部写入磁盘。
- 后台线程定时刷新,有一个后台线程每过一秒就将redo log写入磁盘。
- MySQL关闭时,redo log都被写入磁盘。
第一种情况和第四种情况一定会执行redo log的写入,第二种情况和第三种情况的执行要根据参数innodb_flush_log_at_trx_commit的设定值,在下文会有详细描述。
索引的创建也需要记录redo log。
1.5 一个重做全过程的示例
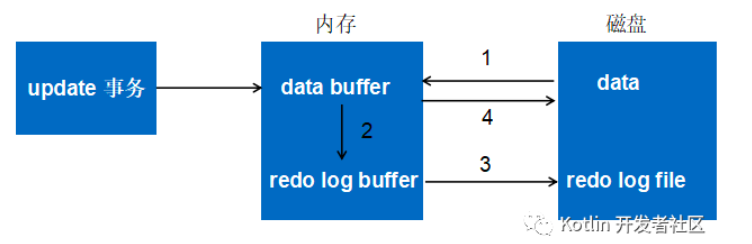
以更新事务为例。
- 将原始数据读入内存,修改数据的内存副本。
- 生成redo log并写入重做日志缓冲区,redo log中存储的是修改后的新值。
- 事务提交时,将重做日志缓冲区中的内容刷新到重做日志文件。
- 随后正常将内存中的脏页刷回磁盘。
1.6 持久性的保证
1.6.1 Force Log at Commit机制
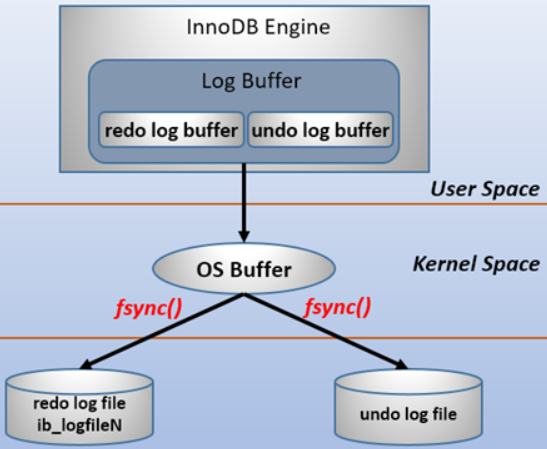
Force Log at Commit机制实现了事务的持久性。在内存中操作时,日志被写入重做日志缓冲区。但在事务提交之前,必须首先将所有日志写入磁盘上的重做日志文件。
为了确保每个日志都写入重做日志文件,必须使用一个fsync系统调用,确保OS buffer中的日志被完整地写入磁盘上的log file。
fsync系统调用:需要你在入参的位置上传递给他一个fd,然后系统调用就会对这个fd指向的文件起作用。fsync会确保一直到写磁盘操作结束才会返回,所以当你的程序使用这个函数并且它成功返回时,就说明数据肯定已经安全的落盘了。所以fsync适合数据库这种程序。
1.6.2 innodb_flush_log_at_trx_commit参数
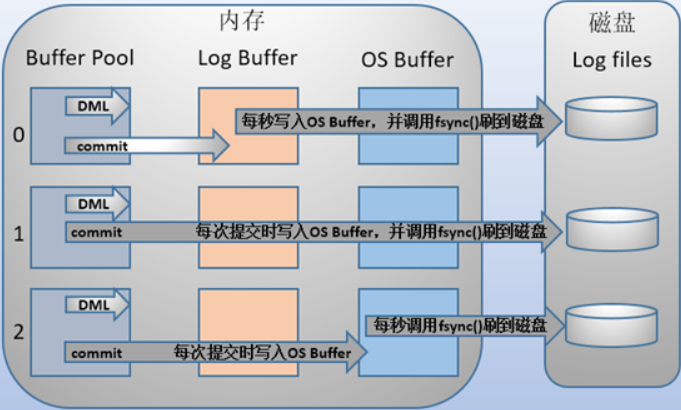
InnoDB提供了一个参数innodb_flush_log_at_trx_commit控制日志刷新到磁盘的策略。
- 当
innodb_flush_log_at_trx_commit值为1时(默认)。事务每次提交都必须将log buffer中的日志写入os buffer并调用fsync()写入磁盘中。
这种方式即使系统崩溃也不会丢失任何数据,但是因为每次提交都写入磁盘,IO性能较差。
- 当
innodb_flush_log_at_trx_commit值为0时。事务提交时不将log buffer写入到os buffer,而是每秒写入os buffer并调用fsync()写入到log file on disk中。
这实际上相当于在内存中维护了一个用户设计的缓冲区,它减少了和os buffer之间的数据传输,有更好的性能。
每秒写入磁盘,系统崩溃会丢失1s的数据。
- 当
innodb_flush_log_at_trx_commit值为2时。每次提交都仅写入os buffer,然后每秒调用fsync()将os buffer中的日志写入到log file on disk中。
虽然说我们是每秒调用fsync()将os buffer中的日志写入到log file on disk中,但是平时即使不调用fsync,数据也会2自主地逐渐进入磁盘。所以当发生系统崩溃,相比第二种情况,会丢失较少的数据。
但同时,由于每次提交都写入os buffer,所以相比第二种情况,性能会差一些,但还是比第一种好的。
无论是哪种情况
1.6.3 一个小的性能测试
几个选项之间的性能差距是极大的,下面做一个简单的测试。
#创建测试表
drop table if exists test_flush_log;
create table test_flush_log(id int,name char(50))engine=innodb;
#创建插入指定行数的记录到测试表中的存储过程
drop procedure if exists proc;
delimiter $$
create procedure proc(i int)
begin
declare s int default 1;
declare c char(50) default repeat('a',50);
while s<=i do
start transaction;
insert into test_flush_log values(null,c);
commit;
set s=s+1;
end while;
end$$
delimiter ;
下面均插入十万条记录。
Ⅰ 当innodb_flush_log_at_trx_commit值为1时
test> call proc(100000) [2021-07-25 13:22:02] completed in 27 s 350 ms
需要长达27.35s。
Ⅱ 当innodb_flush_log_at_trx_commit值为2时
test> set @@global.innodb_flush_log_at_trx_commit=2; test> truncate test_flush_log; test> call proc(100000) [2021-07-25 13:27:33] completed in 5 s 774 ms
只需5.774s,性能大大提升。
Ⅲ 当innodb_flush_log_at_trx_commit值为0时
test> set @@global.innodb_flush_log_at_trx_commit=0; test> truncate test_flush_log; test> call proc(100000) [2021-07-25 13:30:34] completed in 3 s 537 ms
只需3.537s,性能更高。
显然,innodb_flush_log_at_trx_commit值为1时性能差得非常明显,改为0和2后性能都有大幅提升,其中0更快但相比2提升不大。
虽然改为0和2可以大幅提升性能,但会严重影响安全性。我们可以通过修改存储过程,将事务的创建和提交放到循环外,统一提交,减少了IO频率。
drop procedure if exists proc;
delimiter $$
create procedure proc(i int)
begin
declare s int default 1;
declare c char(50) default repeat('a',50);
start transaction;
while s<=i DO
insert into test_flush_log values(null,c);
set s=s+1;
end while;
commit;
end$$
delimiter ;
1.6.4 迷你事务mini-transaction
mini-trasaction是InnoDB处理小型事务时使用的一种机制,它可以确保并发事务操作和数据库异常发生时,数据页中的数据一致性。
迷你事务必须遵循下面三个协议:
- FIX规则。写时必须使用独占锁,读时必须使用共享锁。反正就是要锁住。
- 预写日志。预写日志即WAL,Write-Ahead Log。持久化数据之前,必须先持久化内存中的日志。每个页面都有一个LSN(日志序列号)。在将数据写入磁盘前,要先将内存中序列号小于LSN的日志写入磁盘。WAL提供三种持久化模式
最严格的是full-sync,fsync保证在返回之前将记录刷新到磁盘,最大化了数据的安全性。
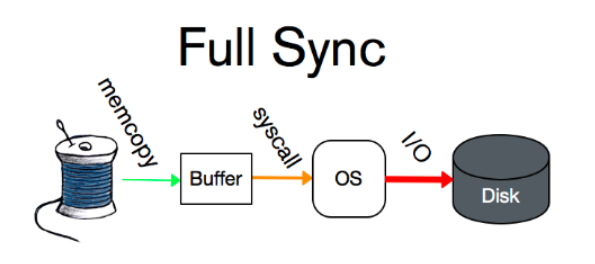
第二个级别是write-only,保证记录写入操作系统。这允许数据在进程级别的崩溃后幸存。
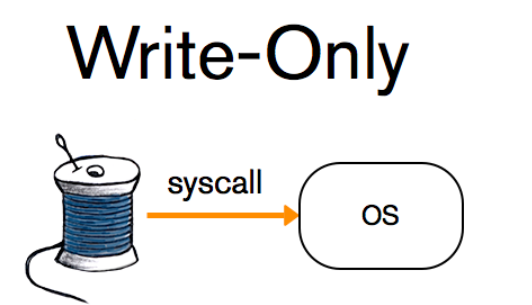
最不严格的是no-sync,将记录保存在内存缓冲区中,不保证立即写入文件系统。
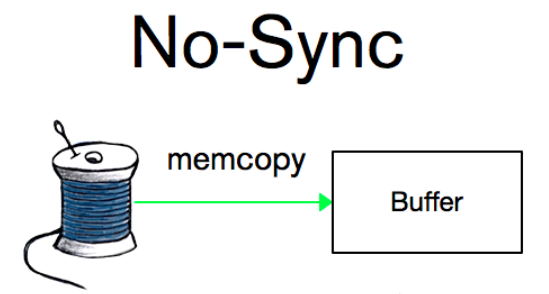
强制日志再提交。即Force-log-at-commit,它要求提交事务时必须把所有迷你事务日志刷新到磁盘。
1.7 写redo log的过程
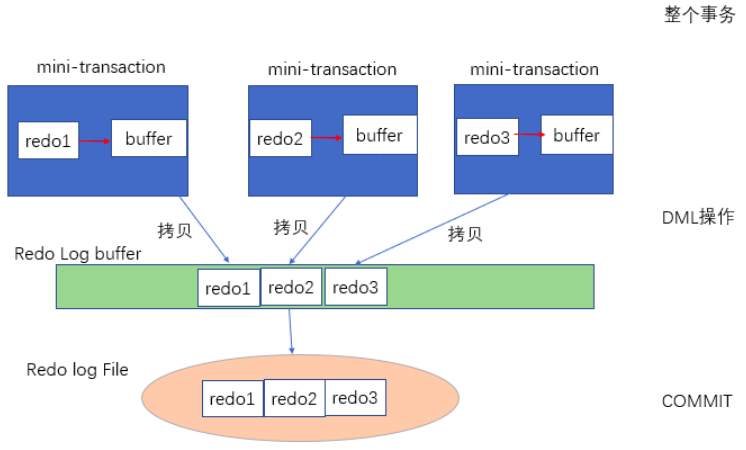
如上图,展示了redo log是如何被写入log buffer的。每个mini-trasaction对应于每个DML操作,例如更新语句等。
- 每个数据修改后被写入迷你事务私有缓冲区。
- 当更新语句完成,redo log从迷你事务私有缓冲区被写入内存中的公共日志缓冲区。
- 提交外部事务时,会将重做日志缓冲区刷入重做日志文件。
1.8 日志块 log block
redo log以块为单位进行存储,每个块大小为512字节。无论是在内存重做日志缓冲区、操作系统缓冲区还是重做日志文件中,都是以这样的512字节大小的块进行存储的。
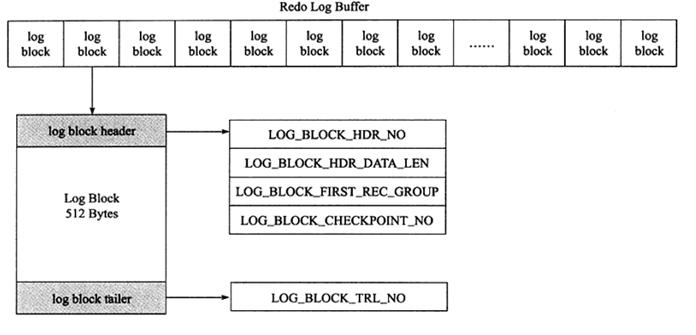
每个日志块头由以下四个部分组成
- log_block_hdr_no:(4字节)该日志块在redo log buffer中的位置ID。
- log_block_hdr_data_len:(2字节)该log block中已记录的log大小。写满该log block时为0x200,表示512字节。
- log_block_first_rec_group:(2字节)该log block中第一个log的开始偏移位置。
- lock_block_checkpoint_no:(4字节)写入检查点信息的位置。
1.9 log group
log group代表redo log的分组,由多个大小相同的redo log file组成。由一个参数innodb_log_files_group决定,默认为2。
[外链图片转存失败,源站可能有防盗img-qAyaSeL3543740G:61311akw89MySQL[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-h01w68EG-1627284031849)(G:\markdown\MySQL\image-20210726131134489.png)].png)]
这个group是逻辑上的概念,但可以通过变量 innodb_log_group_home_dir 来定义组的目录,redo log file都放在这个目录下,默认是在datadir下。
2 撤销日志undo log
2.1 关于undo log
undo log存在的意义是确保数据库事务的原子性。
原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
- edo log记录了事务的行为,可以很好地保证一致性,对数据进行“重做”操作。但事务有时还需要进行“回滚”操作,这时就需要undo log。当我们对记录做了变更操作的时候就需要产生undo log,其中记录的是老版本的数据,当旧事务需要读取数据时,可以顺着undo链找到满足其可见性地记录。
- undo log通常以逻辑日志的形式存在。我们可以认为当delete一条记录时,undo log会产生一条对应的insert记录,反之亦然。当update一条记录时,会产生一条相反的update记录。
- undo log采用段segment的方式来记录,每个undo操作在记录的时候占用一个undo log segment。
- undo log也会产生redo log,因为undo log也要实现持久性保护。
undo log通常以逻辑日志的形式存在。我们可以认为当delete一条记录时,undo log会产生一条对应的insert记录,反之亦然。当update一条记录时,会产生一条相反的update记录。
undo log采用段segment的方式来记录,每个undo操作在记录的时候占用一个undo log segment。
undo log也会产生redo log,因为undo log也要实现持久性保护。
2.2 undo log segment
为了保证事务并发操作时,写各自的undo log时不发生冲突,nnodb用段的方式管理undo log。rollback segment称为回滚段,每个回滚段中有1024个undo log segment。MySQL5.5以后的版本支持128个rollback segment,就可以存储128*1024个操作,还可以通过innodb_undo_logs参数定义盯梢个rollback segment。
2.3 purge
在聚集索引列的操作中,MySQL是这样设计的。对一条delete语句
delete from t where a = 1
假如a有聚集索引(主键),那么不会进行真正的删除,而是在主键列等于1的记录处设置delete flag为1,即把记录保存在B+树中。同理,对于update操作,不是直接更新记录,而是把旧纪录标识为删除,再创建一条新记录。
那么,旧版本记录什么时候真正的删除呢?
InnoDB使用undo日志进行旧版本的删除操作,这个操作称为purge操作。InnoDB开辟了purge线程进行purge操作,并且可以控制purge线程的数量,每个purge线程每10s 进行一次purge操作。
InnoDB的undo log设计
一个页上允许多个事务的undo log存在,undo log的存储顺序是随时的。InnoDB维护了一个history链表,按照事务提交的顺序将undo log进行连接。
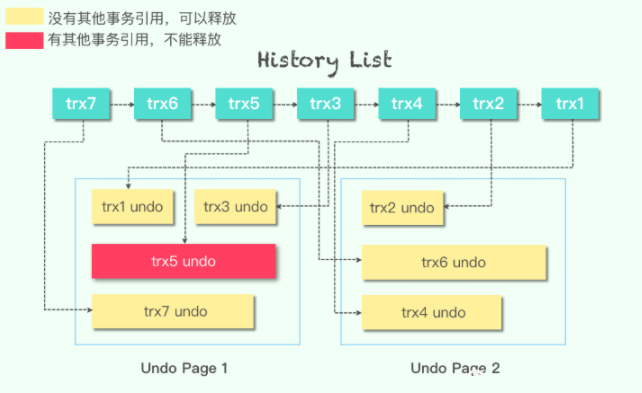
在执行purge过程中,InnoDB存储引擎首先从history list中找到第一个需要被清理的记录,这里为trx1,清理之后InnoDB存储引擎会在trx1所在的Undo page中继续寻找是否存在可以被清理的记录,这里会找到事务trx3,接着找到trx5,但是发现trx5被其他事务所引用而不能清理,故再去history list中取查找,发现最尾端的记录时trx2,接着找到trx2所在的Undo page,依次把trx6、trx4清理,由于Undo page2中所有的记录都被清理了,因此该Undo page可以进行重用。
InnoDB存储引擎这种先从history list中找undo log,然后再从Undo page中找undo log的设计模式是为了避免大量随机读操作,从而提高purge的效率。
3 InnoDB的恢复操作
3.1 数据页刷盘的规则和checkpoint
内存中(buffer pool)未刷到磁盘的数据称为脏数据(dirty data)。由于数据和日志都以页的形式存在,所以脏页表示脏数据和脏日志。
在InnoDB中,checkpoint是数据刷盘的唯一规则。checkpoint触发后,会将内存中的脏数据刷到磁盘。
innodb存储引擎中checkpoint分为两种:
- sharp checkpoint:在重用redo log文件(例如切换日志文件)的时候,将所有已记录到redo log中对应的脏数据刷到磁盘。
- fuzzy checkpoint:一次只刷一小部分的日志到磁盘,而非将所有脏日志刷盘。有以下几种情况会触发该检查点:
master thread checkpoint。由master线程控制,每秒或每10秒刷入一定比例的脏页到磁盘。
flush_lru_list checkpoint。从MySQL5.6开始可通过 innodb_page_cleaners 变量指定专门负责脏页刷盘的page cleaner线程的个数,该线程的目的是为了保证lru列表有可用的空闲页。
async/sync flush checkpoint。同步刷盘还是异步刷盘。例如还有非常多的脏页没刷到磁盘(非常多是多少,有比例控制),这时候会选择同步刷到磁盘,但这很少出现;如果脏页不是很多,可以选择异步刷到磁盘,如果脏页很少,可以暂时不刷脏页到磁盘
dirty page too much checkpoint。脏页太多时强制触发检查点,目的是为了保证缓存有足够的空闲空间。too much的比例由变量 innodb_max_dirty_pages_pct 控制,MySQL 5.6默认的值为75,即当脏页占缓冲池的百分之75后,就强制刷一部分脏页到磁盘。
由于刷脏页需要一定的时间来完成,所以记录检查点的位置是在每次刷盘结束之后才在redo log中标记的。
3.2 LSN
3.2.1 LSN概念
LSN称为日志的逻辑序列号,在InnoDB中占用8个字节
我们可以通过LSN了解到下面这些信息:
- 数据页的版本信息。
- 写入的日志总量。
- 检查点的位置。
在下面两个位置存在LSN:
- redo log的记录中。
- 每个数据页的头部有一个变量
fil_page_lsn记录了本页最终的LSN值是多少。
显然,如果页中的LSN值小于redo log中的LSN值,说明数据出现了丢失。
通过show engine innodb status可以查看当前InnoDB的运行信息,其中有一栏log中有关于lsn的记录。
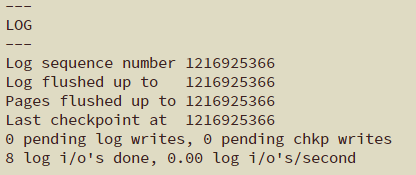
- log sequence number记录了当前的redo log(in buffer)中的LSN。
- log flushed up to是刷到磁盘重做日志文件中的LSN。
- pages flushed up to是已经刷到磁盘数据页上的LSN。
- last checkpoint at是上一次检查点所在位置的LSN。
3.2.2 LSN处理流程
(1).首先修改内存中的数据页,并在数据页中记录LSN,暂且称之为data_in_buffer_lsn;
(2).并且在修改数据页的同时(几乎是同时)向redo log in buffer中写入redo log,并记录下对应的LSN,暂且称之为redo_log_in_buffer_lsn;
(3).写完buffer中的日志后,当触发了日志刷盘的几种规则时,会向redo log file on disk刷入重做日志,并在该文件中记下对应的LSN,暂且称之为redo_log_on_disk_lsn;
(4).数据页不可能永远只停留在内存中,在某些情况下,会触发checkpoint来将内存中的脏页(数据脏页和日志脏页)刷到磁盘,所以会在本次checkpoint脏页刷盘结束时,在redo log中记录checkpoint的LSN位置,暂且称之为checkpoint_lsn。
(5).要记录checkpoint所在位置很快,只需简单的设置一个标志即可,但是刷数据页并不一定很快,例如这一次checkpoint要刷入的数据页非常多。也就是说要刷入所有的数据页需要一定的时间来完成,中途刷入的每个数据页都会记下当前页所在的LSN,暂且称之为data_page_on_disk_lsn。
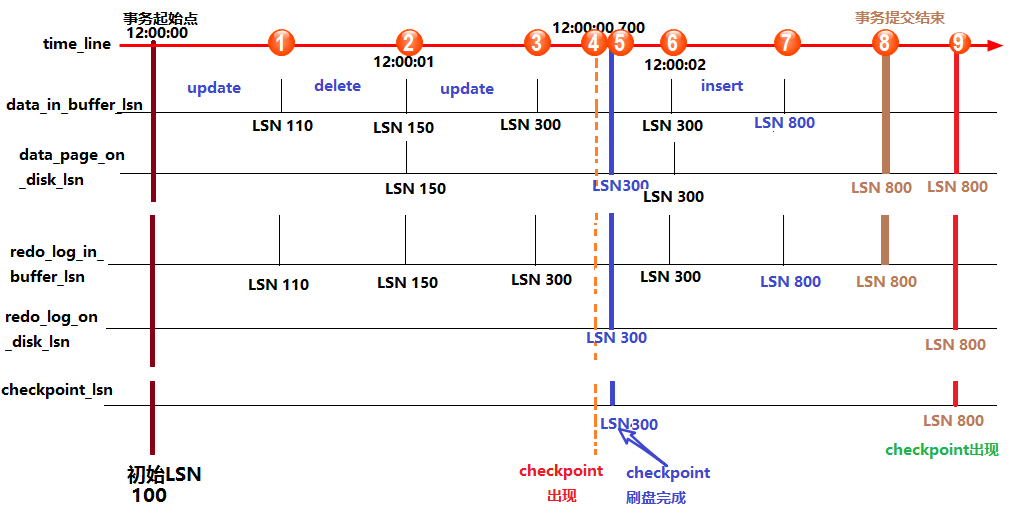
上图中,从上到下的横线分别代表:时间轴、buffer中数据页中记录的LSN(data_in_buffer_lsn)、磁盘中数据页中记录的LSN(data_page_on_disk_lsn)、buffer中重做日志记录的LSN(redo_log_in_buffer_lsn)、磁盘中重做日志文件中记录的LSN(redo_log_on_disk_lsn)以及检查点记录的LSN(checkpoint_lsn)。
假设在最初时(12:0:00)所有的日志页和数据页都完成了刷盘,也记录好了检查点的LSN,这时它们的LSN都是完全一致的。
假设此时开启了一个事务,并立刻执行了一个update操作,执行完成后,buffer中的数据页和redo log都记录好了更新后的LSN值,假设为110。这时候如果执行 show engine innodb status 查看各LSN的值,即图中①处的位置状态,结果会是:
log sequence number(110) > log flushed up to(100) = pages flushed up to = last checkpoint at
之后又执行了一个delete语句,LSN增长到150。等到12:00:01时,触发redo log刷盘的规则(其中有一个规则是 innodb_flush_log_at_timeout 控制的默认日志刷盘频率为1秒),这时redo log file on disk中的LSN会更新到和redo log in buffer的LSN一样,所以都等于150,这时 show engine innodb status ,即图中②的位置,结果将会是:
log sequence number(150) = log flushed up to > pages flushed up to(100) = last checkpoint at
再之后,执行了一个update语句,缓存中的LSN将增长到300,即图中③的位置。
假设随后检查点出现,即图中④的位置,正如前面所说,检查点会触发数据页和日志页刷盘,但需要一定的时间来完成,所以在数据页刷盘还未完成时,检查点的LSN还是上一次检查点的LSN,但此时磁盘上数据页和日志页的LSN已经增长了,即:
log sequence number > log flushed up to 和 pages flushed up to > last checkpoint at
但是log flushed up to和pages flushed up to的大小无法确定,因为日志刷盘可能快于数据刷盘,也可能等于,还可能是慢于。但是checkpoint机制有保护数据刷盘速度是慢于日志刷盘的:当数据刷盘速度超过日志刷盘时,将会暂时停止数据刷盘,等待日志刷盘进度超过数据刷盘。
等到数据页和日志页刷盘完毕,即到了位置⑤的时候,所有的LSN都等于300。
随着时间的推移到了12:00:02,即图中位置⑥,又触发了日志刷盘的规则,但此时buffer中的日志LSN和磁盘中的日志LSN是一致的,所以不执行日志刷盘,即此时 show engine innodb status 时各种lsn都相等。
随后执行了一个insert语句,假设buffer中的LSN增长到了800,即图中位置⑦。此时各种LSN的大小和位置①时一样。
随后执行了提交动作,即位置⑧。默认情况下,提交动作会触发日志刷盘,但不会触发数据刷盘,所以 show engine innodb status 的结果是:
log sequence number = log flushed up to > pages flushed up to = last checkpoint at
最后随着时间的推移,检查点再次出现,即图中位置⑨。但是这次检查点不会触发日志刷盘,因为日志的LSN在检查点出现之前已经同步了。假设这次数据刷盘速度极快,快到一瞬间内完成而无法捕捉到状态的变化,这时 show engine innodb status 的结果将是各种LSN相等。
3.3 InnoDB的恢复行为
启动InnoDB时,一定会进行恢复操作,无论上次是因为什么原因退出。
checkpoint表示已经完整刷到磁盘上data page上的LSN,因此恢复时仅需要恢复从checkpoint开始的日志部分。例如,当数据库在上一次checkpoint的LSN为10000时宕机,且事务是已经提交过的状态。启动数据库时会检查磁盘中数据页的LSN,如果数据页的LSN小于日志中的LSN,则会从检查点开始恢复。
还有一种情况,在宕机前正处于checkpoint的刷盘过程,且数据页的刷盘进度超过了日志页的刷盘进度。这时候一宕机,数据页中记录的LSN就会大于日志页中的LSN,在重启的恢复过程中会检查到这一情况,这时超出日志进度的部分将不会重做,因为这本身就表示已经做过的事情,无需再重做。
另外,事务日志具有幂等性,所以多次操作得到同一结果的行为在日志中只记录一次。而二进制日志不具有幂等性,多次操作会全部记录下来,在恢复的时候会多次执行二进制日志中的记录,速度就慢得多。例如,某记录中id初始值为2,通过update将值设置为了3,后来又设置成了2,在事务日志中记录的将是无变化的页,根本无需恢复;而二进制会记录下两次update操作,恢复时也将执行这两次update操作,速度比事务日志恢复更慢。
到此这篇关于MySQL中的redo log和undo log的文章就介绍到这了,更多相关MySQL中的redo log和undo log内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL 8.0 redo log的深入解析
前言 最开始了解mysql实现的时候,总听到redo log, WAL(write-ahead logging),undo log这些关键词,了解到redo log主要是用于实现事务的持久化的.为了进一步了解redo log,看了下相关代码(源码版本: mysql 8.0.12),这里简单总结下,主要介绍redo log是如何产生,如何落盘,以及最终通知用户的. redo log的产生 读写事务在执行的过程中,会不断的产生redo log.申请数据页.修改数据页.记录undo log等,都会产生
-
MySQL系列之redo log、undo log和binlog详解
事务的实现 redo log保证事务的持久性,undo log用来帮助事务回滚及MVCC的功能. InnoDB存储引擎体系结构 redo log Write Ahead Log策略 事务提交时,先写重做日志再修改页:当由于发生宕机而导致数据丢失时,就可以通过重做日志来完成数据的恢复. InnoDB首先将重做日志信息先放到重做日志缓存 按一定频率刷新到重做日志文件 重做日志文件: 在默认情况,InnoDB存储引擎的数据目录下会有两个名为ib_logfile1和ib_logfile2的文件.每个In
-
详解MySQL 重做日志(redo log)与回滚日志(undo logo)
前言: 前面文章讲述了 MySQL 系统中常见的几种日志,其实还有事务相关日志 redo log 和 undo log 没有介绍.相对于其他几种日志而言, redo log 和 undo log 是更加神秘,难以观测的.本篇文章将主要介绍这两类事务日志的作用及运维方法. 1.重做日志(redo log) 我们都知道,事务的四大特性里面有一个是 持久性 ,具体来说就是只要事务提交成功,那么对数据库做的修改就被永久保存下来了,不可能因为任何原因再回到原来的状态.那么 MySQL 是如何保证一致性的呢
-
MySQL 撤销日志与重做日志(Undo Log与Redo Log)相关总结
Undo Log 数据库事务开始之前,会将要修改的记录存放到 Undo 日志里,当事务回滚时或者数据库崩溃时,可以利用 Undo 日志,撤销未提交事务对数据库产生的影响. Undo Log产生和销毁 Undo Log在事务开始前产生:事务在提交时,并不会立刻删除undo log,innodb会将该事务对应的undo log放入到删除列表中,后面会通过后台线程purge thread进行回收处理. Undo Log属于逻辑日志,记录一个变化过程.例如执行一个delete,undolog会记录一个i
-
浅谈MySQL中授权(grant)和撤销授权(revoke)用法详解
MySQL 赋予用户权限命令的简单格式可概括为: grant 权限 on 数据库对象 to 用户 一.grant 普通数据用户,查询.插入.更新.删除 数据库中所有表数据的权利 grant select on testdb.* to common_user@'%' grant insert on testdb.* to common_user@'%' grant update on testdb.* to common_user@'%' grant delete on testdb.* to c
-
MySQL中Decimal类型和Float Double的区别(详解)
MySQL中存在float,double等非标准数据类型,也有decimal这种标准数据类型. 其区别在于,float,double等非标准类型,在DB中保存的是近似值,而Decimal则以字符串的形式保存数值. float,double类型是可以存浮点数(即小数类型),但是float有个坏处,当你给定的数据是整数的时候,那么它就以整数给你处理.这样我们在存取货币值的时候自然遇到问题,我的default值为:0.00而实际存储是0,同样我存取货币为12.00,实际存储是12. 幸好mysql提供
-
MySql中的IFNULL、NULLIF和ISNULL用法详解
今天用到了MySql里的isnull才发现他和MSSQL里的还是有点区别,现在简单总结一下: mysql中isnull,ifnull,nullif的用法如下: isnull(expr) 的用法: 如expr 为null,那么isnull() 的返回值为 1,否则返回值为 0. mysql> select isnull(1+1); -> 0 mysql> select isnull(1/0); -> 1 使用= 的null 值对比通常是错误的. isnull() 函数同 is nul
-
MySQL中增删改查操作与常见陷阱详解
目录 本文导读 一.MySQL的增删改查 1.insert语句 2.delete语句 3.update语句原理 4.select 二.15种MySQL数据操作语句 1.REPLACE语句 2.CALL语句 3.TABLE语句 4.WITH语句 三.MySQL查询陷阱 总结 本文导读 本文作为MySQL系列第二篇文章,详细讲解了MySQL的增删改查的语句.语义和一些我们经常在开发工作中暴露的问题,MySQL的增删改查又叫数据操作语句,本文有讲些了一些常用的数据操作语句,select语句后续将作为一
-
MySQL中int(10)和int(11)的区别详解
目录 一.背景 二.MySQL整数类型 总结: 一.背景 在创建数据库表的时候,我们经常会用到int(x)来定义一个字段的类型,一直误以为这里的x表示存储数字的长度. 其实大错特错,这里的 x 指的是 最大显示宽度(最大有效显示宽度是255),且显示宽度与存储大小或类型包含的值的范围无关. 二.MySQL整数类型 类型 字节 取值范围 显示宽度 tinyint 1 -128 ~ 127 4 smallint 2 -32768 ~ 32767 6 mediumint 3 -8388608 ~ 83
-
mysql中替代null的IFNULL()与COALESCE()函数详解
在MySQL中isnull()函数不能作为替代null值! 如下: 首先有个名字为business的表: SELECT ISNULL(business_name,'no business_name') AS bus_isnull FROM business WHERE id=2 直接运行就会报错: 错误代码: 1582 Incorrect parameter count in the call to native function 'isnull' 所以,isnull()函数在mysql中就行不
-
MySQL中索引与视图的用法与区别详解
前言 本文主要给大家介绍了关于MySQL中索引与视图的使用与区别的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 索引 一.概述 所有的Mysql列类型都可以被索引. mysql支持BTREE索引.HASH索引.前缀索引.全文本索引(FULLTEXT)[只有MyISAM引擎支持,且仅限于char,varchar,text列].空间列索引[只有MyISAM引擎支持,且索引的字段必须非空],但不支持函数索引. MyISAM和InnoDB存储引擎的表默认创建BTREE索引,
-
MySQL中参数sql_safe_updates在生产环境的使用详解
前言 在应用 BUG或者 DBA误操作的情况下,会发生对全表进行更新:update delete 的情况.MySQL提供 sql_safe_updates 来限制次操作. set sql_safe_updates = 1; 设置之后,会限制update delete 中不带 where 条件的SQL 执行,较严格.会对已有线上环境带来不利影响.对新系统.应用做严格审核,可以确保不会发生全表更新的问题. CREATE TABLE working.test01 (id INT NOT NULL AU
-
mysql中find_in_set()函数的使用及in()用法详解
MySQL手册中find_in_set函数的语法解释: FIND_IN_SET(str,strlist) str 要查询的字符串 strlist 字段名 参数以","分隔 如 (1,2,6,8,10,22) 查询字段(strlist)中包含(str)的结果,返回结果为null或记录 假如字符串str在由N个子链组成的字符串列表strlist 中,则返回值的范围在 1 到 N 之间. 一个字符串列表就是一个由一些被 ',' 符号分开的子链组成的字符串.如果第一个参数是一个常数字符串,而第
-
MySQL中datetime和timestamp的区别及使用详解
一.MySQL中如何表示当前时间? 其实,表达方式还是蛮多的,汇总如下: CURRENT_TIMESTAMP CURRENT_TIMESTAMP() NOW() LOCALTIME LOCALTIME() LOCALTIMESTAMP LOCALTIMESTAMP() 二.关于TIMESTAMP和DATETIME的比较 一个完整的日期格式如下:YYYY-MM-DD HH:MM:SS[.fraction],它可分为两部分:date部分和time部分,其中,date部分对应格式中的"YYYY-MM-