Python爬取新型冠状病毒“谣言”新闻进行数据分析
一、爬取数据
话不多说了,直接上代码( copy即可用 )
import requests
import pandas as pd
class SpiderRumor(object):
def __init__(self):
self.url = "https://vp.fact.qq.com/loadmore?artnum=0&page=%s"
self.header = {
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1",
}
def spider_run(self):
df_all = list()
for url in [self.url % i for i in range(30)]:
data_list = requests.get(url, headers=self.header).json()["content"]
temp_data = [[df["title"], df["date"], df["result"], df["explain"], df["tag"]] for df in data_list]
df_all.extend(temp_data)
print(temp_data[0])
pd.DataFrame(df_all, columns=["title", "date", "result", "explain", "tag"]).to_csv("冠状病毒谣言数据.csv", encoding="utf_8_sig")
if __name__ == '__main__':
spider = SpiderRumor()
spider.spider_run()
爬虫过程

二、数据分析
数据展示

每日谣言数量
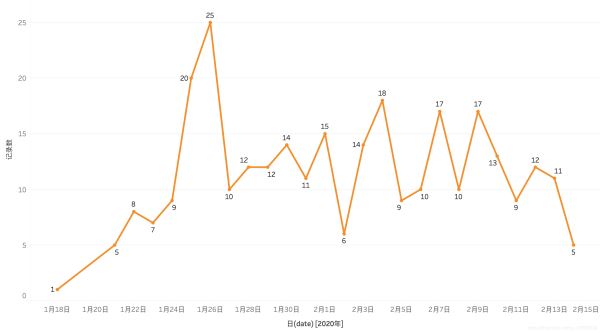
由图可得:1月24日和1月25日是谣言的高峰期,让我们来看看这两天的数据:
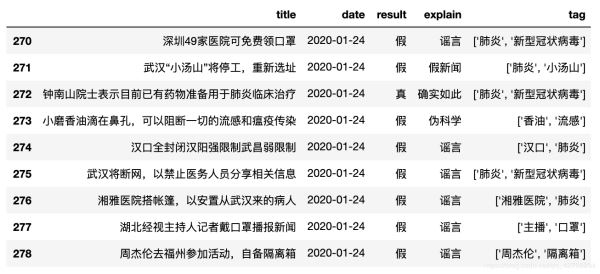

由上图得知 一月二十四号和二十号传播的 29 条谣言中 96.55% 都是假的
谣言是否属实占比
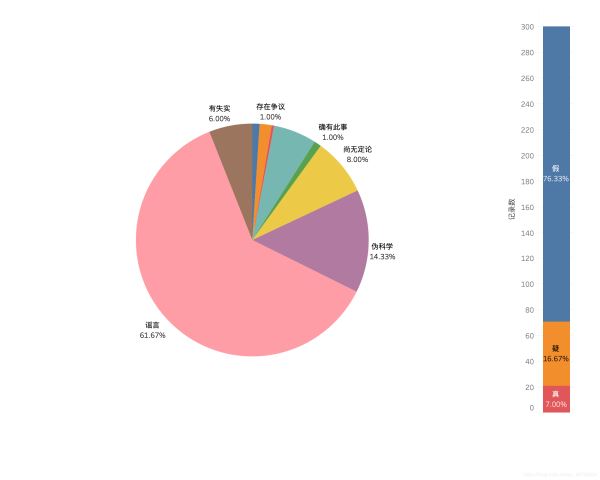
从1月18日到今日截止2月14日共发现了300条谣言,右上图可得:76.33% 都是假的,只要 7.00% 是属实的,其中 14.33% 的谣言属于 伪科学 而且 还有 8.00% 属于尚无定论凭空捏造出的,需要多注意⚠️
谣言的关键字展示

下面介绍 matplotlib 绘制饼图的代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("/冠状病毒谣言数据.csv"")
labels = data["explain"].value_counts().index.tolist()
sizes = data["explain"].value_counts().values.tolist()
colors = ['lightgreen', 'gold', 'lightskyblue', 'lightcoral']
plt.figure(figsize=(15,8))
plt.pie(sizes, labels=labels,
colors=colors, autopct='%1.1f%%', shadow=True, startangle=50) # shadow=True 表示阴影
plt.axis('equal') # 使图居中
plt.show()
绘制谣言关键字分布图(观察 tag 这个字段)
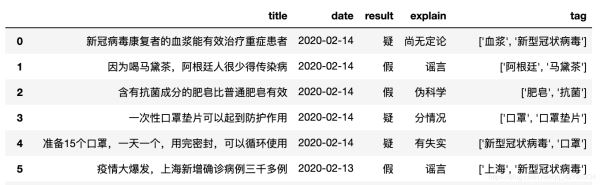
由于 tag 这个字段内容是列表,我们取出来后是列表嵌套列表:[[a, b], [b, c], [c, d]] 我们要使用一行列表生成式快速的将所以的关键字取出来 [j for i in a for j in i]
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# Windows系统设置中文字体
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
data = pd.read_csv("/冠状病毒谣言数据.csv"")
df = pd.Series([j for i in [eval(i) for i in data["tag"].tolist()] for j in i]).value_counts()[:20]
X = df.index.tolist()
y = df.values.tolist()
plt.figure(figsize=(15, 8)) # 设置画布
plt.bar(X, y, color="orange")
plt.tight_layout()
# plt.grid(axis="y")
plt.grid(ls='-.')
plt.show()
总结
以上所述是小编给大家介绍的Python爬取新型冠状病毒“谣言”新闻进行数据分析,希望对大家有所帮助!
相关推荐
-

Python抓新型冠状病毒肺炎疫情数据并绘制全国疫情分布的代码实例
运行结果(2020-2-4日数据) 数据来源 news.qq.com/zt2020/page/feiyan.htm 抓包分析 日报数据格式 "chinaDayList": [{ "date": "01.13", "confirm": "41", "suspect": "0", "dead": "1", "heal&qu
-
python+selenium定时爬取丁香园的新型冠状病毒数据并制作出类似的地图(部署到云服务器)
前言 硬要说这篇文章怎么来的,那得先从那几个吃野味的人开始说起-- 前天睡醒:假期还有几天:昨天睡醒:假期还有十几天:今天睡醒:假期还有一个月-- 每天过着几乎和每个假期一样的宅男生活,唯一不同的是玩手机已不再是看剧.看电影.打游戏了,而是每天都在关注着这次新冠肺炎疫情的新闻消息,真得希望这场战"疫"快点结束,让我们过上像以前一样的生活.武汉加油!中国加油!! 本次爬取的网站是丁香园点击跳转,相信大家平时都是看这个的吧. 一.准备 python3.7 selenium:自动化测试框架,
-
Python实现实时数据采集新型冠状病毒数据实例
Python实时数据采集-新型冠状病毒 源代码 来源:https://github.com/Programming-With-Love/2019-nCoV 疫情数据时间为:2020.2.1 项目相关截图: 全国数据展示 国内数据展示 国外数据展示 查看指定区域详细数据 源代码,注意安装所需模块(例如 pip install 模块名) import requests import re from bs4 import BeautifulSoup from time import sleep imp
-
python模拟预测一下新型冠状病毒肺炎的数据
大家还好吗? 背景就不用多说了吧?本来我是初四上班的,现在延长到2月10日了.这是我工作以来时间最长的一个假期了.可惜哪也去不了.待在家里,没啥事,就用python模拟预测一下新冠病毒肺炎的数据吧.要声明的是本文纯属个人自娱自乐,不代表真实情况. 采用SIR模型,S代表易感者,I表示感染者,R表示恢复者.染病人群为传染源,通过一定几率把传染病传给易感人群,ta自己也有一定的几率被治愈并免疫,或死亡.易感人群一旦感染即成为新的传染源. 模型假设: ①不考虑人口出生.死亡.流动等情况,即人口数量保持
-
Python爬取新型冠状病毒“谣言”新闻进行数据分析
一.爬取数据 话不多说了,直接上代码( copy即可用 ) import requests import pandas as pd class SpiderRumor(object): def __init__(self): self.url = "https://vp.fact.qq.com/loadmore?artnum=0&page=%s" self.header = { "User-Agent": "Mozilla/5.0 (iPhone;
-
node爬取新型冠状病毒的疫情实时动态
写在前面: 新型冠状病毒有多么可怕,我想大家都已经知道了.湖北爆发了新型冠状病毒,湖南前几天爆发了禽流感,四川发生地震,中国加油!昨天晚上我突发奇想地打算把疫情实时动态展示在自建站上,于是说干就干(先附上昨晚用puppeteer截的图片). 安装node_modules: 所需的node_modules:①puppeteer:②cheerio:③fs:④cron. 需要注意的是安装puppeteer的时候很容易安装失败,这里有俩个解决方法,都是用淘宝源(马云爸爸不是白叫的
-
如何用python爬取微博热搜数据并保存
主要用到requests和bf4两个库 将获得的信息保存在d://hotsearch.txt下 import requests; import bs4 mylist=[] r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10) print(r.status_code) # 获取返回状态 r.encoding=r.apparent_encoding demo
-
python爬取新闻门户网站的示例
项目地址: https://github.com/Python3Spiders/AllNewsSpider 如何使用 每个文件夹下的代码就是对应平台的新闻爬虫 py 文件直接运行 pyd 文件需要,假设为 pengpai_news_spider.pyd 将 pyd 文件下载到本地,新建项目,把 pyd 文件放进去 项目根目录下新建 runner.py,写入以下代码即可运行并抓取 import pengpai_news_spider pengpai_news_spider.main() 示例代码
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
Python爬取国外天气预报网站的方法
本文实例讲述了Python爬取国外天气预报网站的方法.分享给大家供大家参考.具体如下: crawl_weather.py如下: #encoding=utf-8 import httplib import urllib2 import time from threading import Thread import threading from Queue import Queue from time import sleep import re import copy lang = "fr&qu
-
python爬取51job中hr的邮箱
本文实例为大家分享了python爬取51job中hr的邮箱具体代码,供大家参考,具体内容如下 #encoding=utf8 import urllib2 import cookielib import re import lxml.html from _ast import TryExcept from warnings import catch_warnings f = open('/root/Desktop/51-01.txt','a+') def read(city): url = 'ht
-
Python爬取三国演义的实现方法
本文的爬虫教程分为四部: 1.从哪爬 where 2.爬什么 what 3.怎么爬 how 4.爬了之后信息如何保存 save 一.从哪爬 三国演义 二.爬什么 三国演义全文 三.怎么爬 在Chrome页面打开F12,就可以发现文章内容在节点 <div id="con" class="bookyuanjiao"> 只要找到这个节点,然后把内容写入到一个html文件即可. content = soup.find("div", {&quo
-
Python爬取京东的商品分类与链接
前言 本文主要的知识点是使用Python的BeautifulSoup进行多层的遍历. 如图所示.只是一个简单的哈,不是爬取里面的隐藏的东西. 示例代码 from bs4 import BeautifulSoup as bs import requests headers = { "host": "www.jd.com", "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWe
-
如何使用python爬取csdn博客访问量
最近学习了python和爬虫,想写一个程序练练手,所以我就想到了大家都比较关心的自己的博客访问量,使用python来获取自己博客的访问量,这也是后边我将要进行的项目的一部分,后边我会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问的情况,使自己能更加清楚自己的哪些博客更受关注,博客专家请勿喷,因为我不是专家,我听他们说专家本身就有这个功能. 一.网址分析 进入自己的博客页面,网址为:http://blog.csdn.net/xingjiarong 网址还是非常清晰的就是cs