yolov5中head修改为decouple head详解
目录
- yolox的decoupled head结构
- 对于decouple head的改进
- 特点
- 疑问
- 总结
yolov5的head修改为decouple head
yolox的decoupled head结构
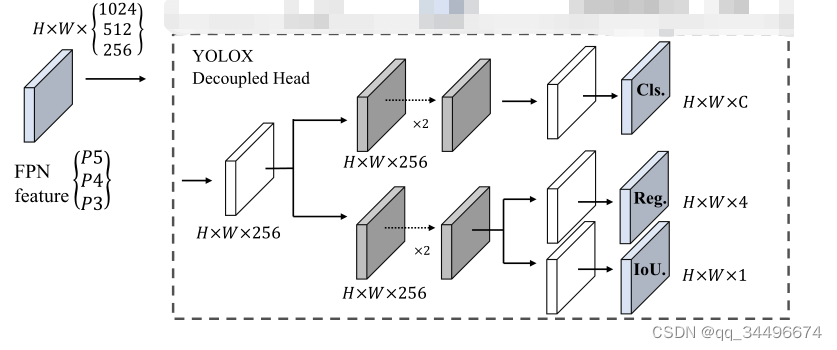
本来想将yolov5的head修改为decoupled head,与yolox的decouple head对齐,但是没注意,该成了如下结构:
感谢少年肩上杨柳依依的指出,如还有问题欢迎指出

1.修改models下的yolo.py文件中的Detect
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
# self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.m_box = nn.ModuleList(nn.Conv2d(256, 4 * self.na, 1) for x in ch) # output conv
self.m_conf = nn.ModuleList(nn.Conv2d(256, 1 * self.na, 1) for x in ch) # output conv
self.m_labels = nn.ModuleList(nn.Conv2d(256, self.nc * self.na, 1) for x in ch) # output conv
self.base_conv = nn.ModuleList(BaseConv(in_channels = x, out_channels = 256, ksize = 1, stride = 1) for x in ch)
self.cls_convs = nn.ModuleList(BaseConv(in_channels = 256, out_channels = 256, ksize = 3, stride = 1) for x in ch)
self.reg_convs = nn.ModuleList(BaseConv(in_channels = 256, out_channels = 256, ksize = 3, stride = 1) for x in ch)
# self.m = nn.ModuleList(nn.Conv2d(x, 4 * self.na, 1) for x in ch, nn.Conv2d(x, 1 * self.na, 1) for x in ch,nn.Conv2d(x, self.nc * self.na, 1) for x in ch)
self.inplace = inplace # use in-place ops (e.g. slice assignment)self.ch = ch
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
# # x[i] = self.m[i](x[i]) # convs
# print("&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&&", i)
# print(x[i].shape)
# print(self.base_conv[i])
# print("%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%")
x_feature = self.base_conv[i](x[i])
# x_feature = x[i]
cls_feature = self.cls_convs[i](x_feature)
reg_feature = self.reg_convs[i](x_feature)
# reg_feature = x_feature
m_box = self.m_box[i](reg_feature)
m_conf = self.m_conf[i](reg_feature)
m_labels = self.m_labels[i](cls_feature)
x[i] = torch.cat((m_box,m_conf, m_labels),1)
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
2.在yolo.py中添加
def get_activation(name="silu", inplace=True):
if name == "silu":
module = nn.SiLU(inplace=inplace)
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
class BaseConv(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
# print(self.bn(self.conv(x)).shape)
return self.act(self.bn(self.conv(x)))
# return self.bn(self.conv(x))
def fuseforward(self, x):
return self.act(self.conv(x))
decouple head的特点:
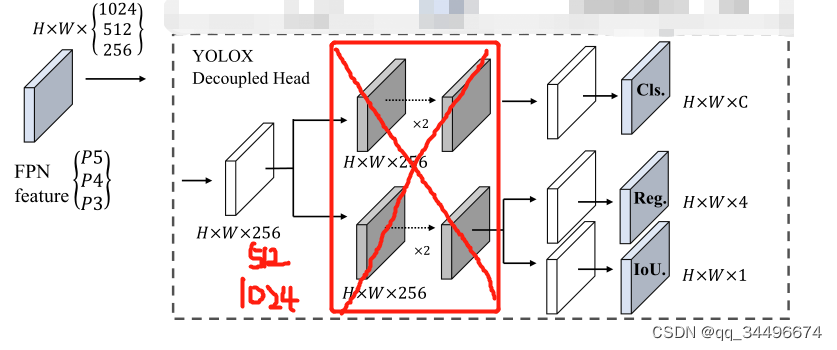
由于训练模型时,应该是channels = 256的地方改成了channels = x(失误),所以在decoupled head的部分参数量比yolox要大一些,以下的结果是在channels= x的情况下得出
比yolov5s参数多,计算量大,在我自己的2.5万的数据量下map提升了3%多
1.模型给出的目标cls较高,需要将conf的阈值设置较大(0.5),不然准确率较低
parser.add_argument('--conf-thres', type=float, default=0.5, help='confidence threshold')
2.对于少样本的检测效果较好,召回率的提升比准确率多
3.在conf设置为0.25时,召回率比yolov5s高,但是准确率低;在conf设置为0.5时,召回率与准确率比yolov5s高
4.比yolov5s参数多,计算量大,在2.5万的数据量下map提升了3%多
对于decouple head的改进
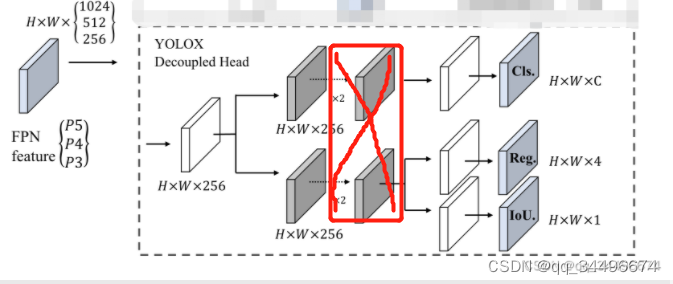
改进:
1.将红色框中的conv去掉,缩小参数量和计算量;
2.channels =256 ,512 ,1024是考虑不增加参数,不进行featuremap的信息压缩
class Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
特点
1.模型给出的目标cls较高,需要将conf的阈值设置较大(0.4),不然准确率较低
2.对于少样本的检测效果较好,准确率的提升比召回率多
3. 准确率的提升比召回率多,
该改进不如上面的模型提升多,但是参数量小,计算量小少9Gflop,占用显存少
decoupled head指标提升的原因:由于yolov5s原本的head不能完全的提取featuremap中的信息,decoupled head能够较为充分的提取featuremap的信息;
疑问
为什么decoupled head目标的cls会比较高,没想明白
为什么去掉base_conv,召回率要比准确率提升少
总结
到此这篇关于yolov5中head修改为decouple head的文章就介绍到这了,更多相关yolov5 head修改为decouple head内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Yolov5服务器环境搭建详细过程
目录 1 服务器搭建yolov5环境 1.1 创建环境 1.2 跟随官方指引 2 下载预训练权重 3 推理 4 测试 1 服务器搭建yolov5环境 1.1 创建环境 首先先的在本地环境下搭建一个我们的环境,名字设为yolo5-6 conda create -n yolov5-6 python=3.7#创建环境 conda activate yolov5-6#切换yolov5-6环境 创建包完成后,我们需要查看conda环境下是否有我们刚才创建的环境,通过以下的指令可以查看所有的环境. cond
-
win10+anaconda安装yolov5的方法及问题解决方案
对于yolo系列,应用广泛,在win10端也有很大的应用需求,所以这篇文章给出win10环境下的安装教程. 先给出系列文章win10+anacnda实现yolov3 YOLOV5-3.0/3.1版本 版本问题 python 3.7 torch 1.6.0 torchvision 0.7.0 cuda 10.1 注意:Yolov5-3.1只能使用torch 1.6.0 1.在网站下载对应版本的torch和torchvision的whl文件 https://download.pytorch.org/
-
yolov5 win10 CPU与GPU环境搭建过程
前言 最近实习任务为黑烟检测,想起了可以尝试用yolov5来跑下,之前一直都是用的RCNN系列,这次就试试yolo系列. 一.安装pytorch 1.创建新的环境 打开Anaconda Prompt命令行输入 创建一个新环境,并激活进入环境. # 创建了名叫yolov5的,python版本为3.8的新环境 conda create -n yolov5 python=3.8 # 激活名叫yolov5的环境 conda activate yolov5 2.下载YOLOv5 github项目 下载地址
-
yolov5特征图可视化的使用步骤
目录 前言 一.效果图 二.使用步骤 1.使用方法 2.注意事项 总结 参考 前言 最近写论文需要观察中间特征层的特征图,使用的是yolov5的代码仓库,但是苦于找不到很好的轮子,于是参考了很多,只找了这个,但是我觉得作者写的太复杂了(我之前就是这个作者的小粉丝),在参考了github的yolov5作者给出的issue建议后,自己写了个轮子,没有复杂的步骤,借助torchvision中的transforms将tensor转化为PIL,再通过matplotlib保存特图.希望能给大家带来一些帮助.
-
yolov5中head修改为decouple head详解
目录 yolox的decoupled head结构 对于decouple head的改进 特点 疑问 总结 yolov5的head修改为decouple head yolox的decoupled head结构 本来想将yolov5的head修改为decoupled head,与yolox的decouple head对齐,但是没注意,该成了如下结构: 感谢少年肩上杨柳依依的指出,如还有问题欢迎指出 1.修改models下的yolo.py文件中的Detect class Detect(nn.Modu
-
对python中词典的values值的修改或新增KEY详解
在python中,对词典的值,可以新增,或者修改,如下: 以上这篇对python中词典的values值的修改或新增KEY详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
vue-vuex中使用commit提交mutation来修改state的方法详解
在vuex中,关于修改state的方式,需要commit提交mutation.官方文档中有这么一句话: 更改 Vuex 的 store 中的状态的唯一方法是提交 mutation. 为了搞清楚其原因,查阅了很多资料,发现其它人在做vuex的源码解析的时候,并没有将这点说的很明白. 所以只好自己去查看vuex的源码,并且自己做demo进行验证. 但是试验后,发现直接修改state时,store中的state能够改变,并且是响应式的,并没有报错.跟commit提交mutation的方式没啥区别. 后
-
Vue.js中对css的操作(修改)具体方式详解
使用v-bind:class或者v-bind:style或者直接通过操作dom来对其样式进行更改: 1.v-bind:class || v-bind:style 其中v-bind是指令,: 后面的class 和style是参数,而class之后的指在vue的官方文档里被称为'指令预期值'(这个不必深究,反正个人觉得初学知道他叫啥名有啥用就好了)同v-bind的大多数指令(部分特殊指令如V-for除外)一样,除了可以绑定字符串类型的变量外,还支持一个单一的js表达式,也就是说v-bind:clas
-
YOLOv5中SPP/SPPF结构源码详析(内含注释分析)
目录 一.SPP的应用的背景 二.SPP结构分析 三.SPPF结构分析 四.YOLOv5中SPP/SPPF结构源码解析(内含注释分析) 总结 一.SPP的应用的背景 在卷积神经网络中我们经常看到固定输入的设计,但是如果我们输入的不能是固定尺寸的该怎么办呢? 通常来说,我们有以下几种方法: (1)对输入进行resize操作,让他们统统变成你设计的层的输入规格那样.但是这样过于暴力直接,可能会丢失很多信息或者多出很多不该有的信息(图片变形等),影响最终的结果. (2)替换网络中的全连接层,对最后的卷
-
AngularJS中使用three.js的实例详解
AngularJS中使用three.js的实例详解 一.轨迹球的引入问题 一开始我是用下面的方式引如轨迹球,但是会报Trackballcontrols is undefined的错. import * as THREE from 'three'; import * as Trackballcontrols from 'three'; 但其实我是能够在node_module下的threejs的包中找到Trackballcontrols的文件的,我一开始以为是引用的路径没对然后修改路径到对应包下Tr
-
PHP中的函数声明与使用详解
函数 1. 函数名是标识符之一,只能有字母数字下划线,开头不能是数字: 函数名的命名,必须符合"小驼峰法则"FUNC(),func(),Func(); 函数名不区分大小写; 函数名不能与已有函数同名,不能与内置函数名同名: 2. function_exists("func");用于检测函数是否已经声明: 注意传入的函数名,必须是字符串格式,返回结果为true/false: echo打印时,true为1,false不显示: [ph
-
java中Executor,ExecutorService,ThreadPoolExecutor详解
java中Executor,ExecutorService,ThreadPoolExecutor详解 1.Excutor 源码非常简单,只有一个execute(Runnable command)回调接口 public interface Executor { /** * Executes the given command at some time in the future. The command * may execute in a new thread, in a pooled thre
-
IOS开发中NSURL的基本操作及用法详解
NSURL其实就是我们在浏览器上看到的网站地址,这不就是一个字符串么,为什么还要在写一个NSURL呢,主要是因为网站地址的字符串都比较复杂,包括很多请求参数,这样在请求过程中需要解析出来每个部门,所以封装一个NSURL,操作很方便. 1.URL URL是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址.互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它. URL可能包含远程服务器上的资源的位置,本地磁盘上的文件的路径,甚
-
oracle中的procedure编写和使用详解
1.创建/修改 CREATE [OR REPLACE] PROCEDURE procedure_name [(parameter_list)] {IS|AS} [local_declarations] BEGIN executable_statements [EXCEPTION exception_handlers] END [procedure_name]; a.parameter_list格式如下 parameter_name1 [in | out | in out] type, param