java无锁hashmap原理与实现详解
java多线程环境中应用HashMap,主要有以下几种选择:使用线程安全的java.util.Hashtable作为替代使用java.util.Collections.synchronizedMap方法,将已有的HashMap对象包装为线程安全的。使用java.util.concurrent.ConcurrentHashMap类作为替代,它具有非常好的性能。
而以上几种方法在实现的具体细节上,都或多或少地用到了互斥锁。互斥锁会造成线程阻塞,降低运行效率,并有可能产生死锁、优先级翻转等一系列问题。
CAS(Compare And Swap)是一种底层硬件提供的功能,它可以将判断并更改一个值的操作原子化。
Java中的原子操作
在java.util.concurrent.atomic包中,Java为我们提供了很多方便的原子类型,它们底层完全基于CAS操作。
例如我们希望实现一个全局公用的计数器,那么可以:
privateAtomicInteger counter =newAtomicInteger(3);
publicvoidaddCounter() {
for(;;) {
intoldValue = counter.get();
intnewValue = oldValue +1;
if(counter.compareAndSet(oldValue, newValue))
return;
}
}
其中,compareAndSet方法会检查counter现有的值是否为oldValue,如果是,则将其设置为新值newValue,操作成功并返回true;否则操作失败并返回false。
当计算counter新值时,若其他线程将counter的值改变,compareAndSwap就会失败。此时我们只需在外面加一层循环,不断尝试这个过程,那么最终一定会成功将counter值+1。(其实AtomicInteger已经为常用的+1/-1操作定义了 incrementAndGet与decrementAndGet方法,以后我们只需简单调用它即可)
除了AtomicInteger外,java.util.concurrent.atomic包还提供了AtomicReference和AtomicReferenceArray类型,它们分别代表原子性的引用和原子性的引用数组(引用的数组)。
无锁链表的实现
在实现无锁HashMap之前,让我们先来看一下比较简单的无锁链表的实现方法。
以插入操作为例:
首先我们需要找到待插入位置前面的节点A和后面的节点B。
然后新建一个节点C,并使其next指针指向节点B。(见图1)
最后使节点A的next指针指向节点C。(见图2)

但在操作中途,有可能其他线程在A与B直接也插入了一些节点(假设为D),如果我们不做任何判断,可能造成其他线程插入节点的丢失。(见图3)我们可以利用CAS操作,在为节点A的next指针赋值时,判断其是否仍然指向B,如果节点A的next指针发生了变化则重试整个插入操作。大致代码如下:
privatevoidlistInsert(Node head, Node c) {
for(;;) {
Node a = findInsertionPlace(head), b = a.next.get();
c.next.set(b);
if(a.next.compareAndSwap(b,c))
return;
}
}
(Node类的next字段为AtomicReference<Node>类型,即指向Node类型的原子性引用)
无锁链表的查找操作与普通链表没有区别。而其删除操作,则需要找到待删除节点前方的节点A和后方的节点B,利用CAS操作验证并更新节点A的next指针,使其指向节点B。
无锁HashMap的难点与突破
HashMap主要有插入、删除、查找以及ReHash四种基本操作。一个典型的HashMap实现,会用到一个数组,数组的每项元素为一个节点的链表。对于此链表,我们可以利用上文提到的操作方法,执行插入、删除以及查找操作,但对于ReHash操作则比较困难。
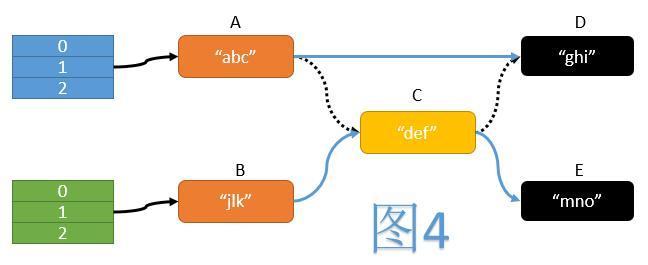
如图4,在ReHash过程中,一个典型的操作是遍历旧表中的每个节点,计算其在新表中的位置,然后将其移动至新表中。期间我们需要操纵3次指针:
将A的next指针指向D
将B的next指针指向C
将C的next指针指向E
而这三次指针操作必须同时完成,才能保证移动操作的原子性。但我们不难看出,CAS操作每次只能保证一个变量的值被原子性地验证并更新,无法满足同时验证并更新三个指针的需求。
于是我们不妨换一个思路,既然移动节点的操作如此困难,我们可以使所有节点始终保持有序状态,从而避免了移动操作。在典型的HashMap实现中,数组的长度始终保持为2i,而从Hash值映射为数组下标的过程,只是简单地对数组长度执行取模运算(即仅保留Hash二进制的后i位)。当ReHash时,数组长度加倍变为2i+1,旧数组第j项链表中的每个节点,要么移动到新数组中第j项,要么移动到新数组中第j+2i项,而它们的唯一区别在于Hash值第i+1位的不同(第i+1位为0则仍为第j项,否则为第j+2i项)。
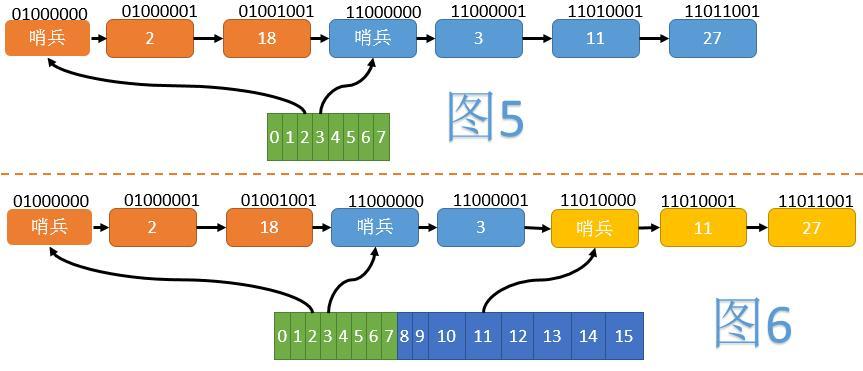
如图5,我们将所有节点按照Hash值的翻转位序(如1101->1011)由小到大排列。当数组大小为8时,2、18在一个组内;3、 11、27在另一个组内。每组的开始,插入一个哨兵节点,以方便后续操作。为了使哨兵节点正确排在组的最前方,我们将正常节点Hash的最高位(翻转后变为最低位)置为1,而哨兵节点不设置这一位。
当数组扩容至16时(见图6),第二组分裂为一个只含3的组和一个含有11、27的组,但节点之间的相对顺序并未改变。这样在ReHash时,我们就不需要移动节点了。

实现细节
由于扩容时数组的复制会占用大量的时间,这里我们采用了将整个数组分块,懒惰建立的方法。这样,当访问到某下标时,仅需判断此下标所在块是否已建立完毕(如果没有则建立)。
另外定义size为当前已使用的下标范围,其初始值为2,数组扩容时仅需将size加倍即可;定义count代表目前HashMap中包含的总节点个数(不算哨兵节点)。
初始时,数组中除第0项外,所有项都为null。第0项指向一个仅有一个哨兵节点的链表,代表整条链的起点。初始时全貌见图7,其中浅绿色代表当前未使用的下标范围,虚线箭头代表逻辑上存在,但实际未建立的块。
初始化下标操作
数组中为null的项都认为处于未初始化状态,初始化某个下标即代表建立其对应的哨兵节点。初始化是递归进行的,即若其父下标未初始化,则先初始化其父下标。(一个下标的父下标是其移除最高二进制位后得到的下标)大致代码如下:
privatevoidinitializeBucket(intbucketIdx) {
intparentIdx = bucketIdx ^ Integer.highestOneBit(bucketIdx);
if(getBucket(parentIdx) ==null)
initializeBucket(parentIdx);
Node dummy =newNode();
dummy.hash = Integer.reverse(bucketIdx);
dummy.next =newAtomicReference<>();
setBucket(bucketIdx, listInsert(getBucket(parentIdx), dummy));
}
其中getBucket即封装过的获取数组某下标内容的方法,setBucket同理。listInsert将从指定位置开始查找适合插入的位置插入给定的节点,若链表中已存在hash相同的节点则返回那个已存在的节点;否则返回新插入的节点。
插入操作
首先用HashMap的size对键的hashCode取模,得到应插入的数组下标。
然后判断该下标处是否为null,如果为null则初始化此下标。
构造一个新的节点,并插入到适当位置,注意节点中的hash值应为原hashCode经过位翻转并将最低位置1之后的值。
将节点个数计数器加1,若加1后节点过多,则仅需将size改为size*2,代表对数组扩容(ReHash)。
查找操作
找出待查找节点在数组中的下标。
判断该下标处是否为null,如果为null则返回查找失败。
从相应位置进入链表,顺次寻找,直至找出待查找节点或超出本组节点范围。
删除操作
找出应删除节点在数组中的下标。
判断该下标处是否为null,如果为null则初始化此下标。
找到待删除节点,并从链表中删除。(注意由于哨兵节点的存在,任何正常元素只被其唯一的前驱节点所引用,不存在被前驱节点与数组中指针同时引用的情况,从而不会出现需要同时修改多个指针的情况)
将节点个数计数器减1。
相关推荐
-
举例详解Java编程中HashMap的初始化以及遍历的方法
一.HashMap的初始化 1.HashMap 初始化的文艺写法 HashMap 是一种常用的数据结构,一般用来做数据字典或者 Hash 查找的容器.普通青年一般会这么初始化: HashMap<String, String> map = new HashMap<String, String>(); map.put("Name", "June"); map.put("QQ", "2572073701"
-
java HashMap通过value反查key的代码示例
复制代码 代码如下: import java.util.ArrayList;import java.util.HashMap;import java.util.Iterator;import java.util.Map;import java.util.Set;public class MapValueGetKey { public static void main(String[] args) { Map map = new HashMap<>(); map.put(1,&qu
-
Java中HashMap和TreeMap的区别深入理解
首先介绍一下什么是Map.在数组中我们是通过数组下标来对其内容索引的,而在Map中我们通过对象来对对象进行索引,用来索引的对象叫做key,其对应的对象叫做value.这就是我们平时说的键值对. HashMap通过hashcode对其内容进行快速查找,而 TreeMap中所有的元素都保持着某种固定的顺序,如果你需要得到一个有序的结果你就应该使用TreeMap(HashMap中元素的排列顺序是不固定的). HashMap 非线程安全 TreeMap 非线程安全 线程安全 在Java里,线程安全一般体
-
java遍历HashMap简单的方法
本文实例讲述了java遍历HashMap简单的方法.分享给大家供大家参考.具体实现方法如下: import java.util.HashMap; import java.util.Iterator; import java.util.Set; public class HashSetTest { public static void main(String[] args) { HashMap map = new HashMap(); map.put("a", "aa"
-
Java中HashMap和Hashtable及HashSet的区别
Hashtable类 Hashtable继承Map接口,实现一个key-value映射的哈希表.任何非空(non-null)的对象都可作为key或者value. 添加数据使用put(key,value),取出数据使用get(key),这两个基本操作的时间开销为常数. Hashtable通过initial capacity和load factor两个参数调整性能.通常缺省的load factor 0.75较好地实现了时间和空间的均衡.增大load factor可以节省空间但
-

Java8 HashMap的实现原理分析
前言:Java8之后新增挺多新东西,在网上找了些相关资料,关于HashMap在自己被血虐之后痛定思痛决定整理一下相关知识方便自己看.图和有些内容参考的这个文章:http://www.jb51.net/article/80446.htm HashMap的存储结构如图:一个桶(bucket)上的节点多于8个则存储结构是红黑树,小于8个是单向链表. 1:HashMap的一些属性 public class HashMap<k,v> extends AbstractMap<k,v> impl
-
java使用hashMap缓存保存数据的方法
本文实例讲述了java使用hashMap缓存保存数据的方法.分享给大家供大家参考,具体如下: private static final HashMap<Long, XXX> sCache = new HashMap<Long, XXX>(); private static int sId = -1; public static void initAlbumArtCache() { try { //... if (id != sId) { clearCache(); sId = id
-
深入理解Java中的HashMap的实现机制
如果任何人让我描述一下HashMap的工作机制的话,我就简单的回答:"基于Hash的规则".这句话非常简单,但是要理解这句话之前,首先我们得了解什么是哈希,不是么? 什么是哈希 哈希简单的说就是对变量/对象的属性应用某种算法后得到的一个唯一的串,用这个串来确定变量/对象的唯一性.一个正确的哈希函数必须遵守这个准则. 当哈希函数应用在相同的对象或者equal的对象的时候,每次执行都应该返回相同的值.换句话说,两个相等的对象应该有相同的hashcode. 注:所有Java对象都从Objec
-
JAVA HashMap详细介绍和示例
第1部分 HashMap介绍HashMap简介HashMap 是一个散列表,它存储的内容是键值对(key-value)映射.HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.Serializable接口.HashMap 的实现不是同步的,这意味着它不是线程安全的.它的key.value都可以为null.此外,HashMap中的映射不是有序的.HashMap 的实例有两个参数影响其性能:"初始容量" 和 "加载因子".容量
-
Java中对HashMap的深度分析
在Java的世界里,无论类还是各种数据,其结构的处理是整个程序的逻辑以及性能的关键.由于本人接触了一个有关性能与逻辑同时并存的问题,于是就开始研究这方面的问题.找遍了大大小小的论坛,也把<Java 虚拟机规范>,<apress,.java.collections.(2001),.bm.ocr.6.0.shareconnector>,和<Thinking in Java>翻了也找不到很好的答案,于是一气之下把JDK的 src 解压出来研究,扩然开朗,遂写此文,跟大家分享感
-
Java集合之HashMap用法详解
本文实例讲述了Java集合之HashMap用法.分享给大家供大家参考,具体如下: HashMap是最常用的Map集合,它的键值对在存储时要根据键的哈希码来确定值放在哪里. HashMap 中作为键的对象必须重写Object的hashCode()方法和equals()方法 import java.util.Map; import java.util.HashMap; public class lzwCode { public static void main(String [] args) { M
-
Java HashMap的工作原理
大部分Java开发者都在使用Map,特别是HashMap.HashMap是一种简单但强大的方式去存储和获取数据.但有多少开发者知道HashMap内部如何工作呢?几天前,我阅读了java.util.HashMap的大量源代码(包括Java 7 和Java 8),来深入理解这个基础的数据结构.在这篇文章中,我会解释java.util.HashMap的实现,描述Java 8实现中添加的新特性,并讨论性能.内存以及使用HashMap时的一些已知问题. 内部存储 Java HashMap类实现了Map<K