python 性能优化方法小结
提高性能有如下方法
1、Cython,用于合并python和c语言静态编译泛型
2、IPython.parallel,用于在本地或者集群上并行执行代码
3、numexpr,用于快速数值运算
4、multiprocessing,python内建的并行处理模块
5、Numba,用于为cpu动态编译python代码
6、NumbaPro,用于为多核cpu和gpu动态编译python代码
为了验证相同算法在上面不同实现上的的性能差异,我们先定义一个测试性能的函数
def perf_comp_data(func_list, data_list, rep=3, number=1):
'''Function to compare the performance of different functions.
Parameters
func_list : list
list with function names as strings
data_list : list
list with data set names as strings
rep : int
number of repetitions of the whole comparison
number : int
number ofexecutions for every function
'''
from timeit import repeat
res_list = {}
for name in enumerate(func_list):
stmt = name[1] + '(' + data_list[name[0]] + ')'
setup = "from __main__ import " + name[1] + ','+ data_list[name[0]]
results = repeat(stmt=stmt, setup=setup, repeat=rep, number=number)
res_list[name[1]] = sum(results) / rep
res_sort = sorted(res_list.items(), key = lambda item : item[1])
for item in res_sort:
rel = item[1] / res_sort[0][1]
print ('function: ' + item[0] + ', av. time sec: %9.5f, ' % item[1] + 'relative: %6.1f' % rel)
定义执行的算法如下
from math import * def f(x): return abs(cos(x)) ** 0.5 + sin(2 + 3 * x)
对应的数学公式是
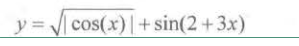
生成数据如下
i=500000 a_py = range(i)
第一个实现f1是在内部循环执行f函数,然后将每次的计算结果添加到列表中,实现如下
def f1(a):
res = []
for x in a:
res.append(f(x))
return res
当然实现这种方案的方法不止一种,可以使用迭代器或eval函数,我自己加入了使用生成器和map方法的测试,发现结果有明显差距,不知道是否科学:
迭代器实现
def f2(a): return [f(x) for x in a]
eval实现
def f3(a): ex = 'abs(cos(x)) **0.5+ sin(2 + 3 * x)' return [eval(ex) for x in a]
生成器实现
def f7(a): return (f(x) for x in a)
map实现
def f8(a): return map(f, a)
接下来是使用numpy的narray结构的几种实现
import numpy as np a_np = np.arange(i) def f4(a): return (np.abs(np.cos(a)) ** 0.5 + np.sin(2 + 3 * a)) import numexpr as ne def f5(a): ex = 'abs(cos(a)) ** 0.5 + sin( 2 + 3 * a)' ne.set_num_threads(1) return ne.evaluate(ex) def f6(a): ex = 'abs(cos(a)) ** 0.5 + sin(2 + 3 * a)' ne.set_num_threads(2) return ne.evaluate(ex)
上面的f5和f6只是使用的处理器个数不同,可以根据自己电脑cpu的数目进行修改,也不是越大越好
下面进行测试
func_list = ['f1', 'f2', 'f3', 'f4', 'f5', 'f6', 'f7', 'f8'] data_list = ['a_py', 'a_py', 'a_py', 'a_np', 'a_np', 'a_np', 'a_py', 'a_py'] perf_comp_data(func_list, data_list)
测试结果如下
function: f8, av. time sec: 0.00000, relative: 1.0 function: f7, av. time sec: 0.00001, relative: 1.7 function: f6, av. time sec: 0.03787, relative: 11982.7 function: f5, av. time sec: 0.05838, relative: 18472.4 function: f4, av. time sec: 0.09711, relative: 30726.8 function: f2, av. time sec: 0.82343, relative: 260537.0 function: f1, av. time sec: 0.92557, relative: 292855.2 function: f3, av. time sec: 32.80889, relative: 10380938.6
发现f8的时间最短,调大一下时间精度再测一次
function: f8, av. time sec: 0.000002483, relative: 1.0 function: f7, av. time sec: 0.000004741, relative: 1.9 function: f5, av. time sec: 0.028068110, relative: 11303.0 function: f6, av. time sec: 0.031389788, relative: 12640.6 function: f4, av. time sec: 0.053619114, relative: 21592.4 function: f1, av. time sec: 0.852619225, relative: 343348.7 function: f2, av. time sec: 1.009691877, relative: 406601.7 function: f3, av. time sec: 26.035869787, relative: 10484613.6
发现使用map的性能最高,生成器次之,其他方法的性能就差的很远了。但是使用narray数据的在一个数量级,使用python的list数据又在一个数量级。生成器的原理是并没有生成一个完整的列表,而是在内部维护一个next函数,通过一边循环迭代一遍生成下个元素的方法的实现的,所以他既不用在执行时遍历整个循环,也不用分配整个空间,它花费的时间和空间跟列表的大小是没有关系的,map与之类似,而其他实现都是跟列表大小有关系的。
内存布局
numpy的ndarray构造函数形式为
np.zeros(shape, dtype=float, order='C')
np.array(object, dtype=None, copy=True, order=None, subok=False, ndmin=0)
shape或object定义了数组的大小或是引用了另一个一个数组
dtype用于定于元素的数据类型,可以是int8,int32,float8,float64等等
order定义了元素在内存中的存储顺序,c表示行优先,F表示列优先
下面来比较一下内存布局在数组很大时的差异,先构造同样的的基于C和基于F的数组,代码如下:
x = np.random.standard_normal(( 3, 1500000)) c = np.array(x, order='C') f = np.array(x, order='F')
下面来测试性能
%timeit c.sum(axis=0) %timeit c.std(axis=0) %timeit f.sum(axis=0) %timeit f.std(axis=0) %timeit c.sum(axis=1) %timeit c.std(axis=1) %timeit f.sum(axis=1) %timeit f.std(axis=1)
输出如下
loops, best of 3: 12.1 ms per loop loops, best of 3: 83.3 ms per loop loops, best of 3: 70.2 ms per loop loop, best of 3: 235 ms per loop loops, best of 3: 7.11 ms per loop loops, best of 3: 37.2 ms per loop loops, best of 3: 54.7 ms per loop loops, best of 3: 193 ms per loop
可知,C内存布局要优于F内存布局
并行计算
未完,待续。。。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-
Python性能优化技巧
Python是一门非常酷的语言,因为很少的Python代码可以在短时间内做很多事情,并且,Python很容易就能支持多任务和多重处理. py 1.关键代码可以依赖于扩展包 Python使许多编程任务变得简单,但是对于很关键的任务并不总是提供最好的性能.使用C.C++或者机器语言扩展包来执行关键任务能极大改善性能.这些包是依赖于平台的,也就是说,你必须使用特定的.与你使用的平台相关的包.简而言之,该解决方案提供了一些应用程序的可移植性,以换取性能,您可以获得只有通过直接向底层主机编程.下面这些扩展
-
修改Python的pyxmpp2中的主循环使其提高性能
引子 之前clubot使用的pyxmpp2的默认mainloop也就是一个poll的主循环,但是clubot上线后资源占用非常厉害,使用strace跟踪发现clubot在不停的poll,查看pyxmpp2代码发现pyxmpp2的poll在使用超时阻塞时使用最小超时时间,而最小超时时间一直是0,所以会变成一个没有超时的非阻塞poll很浪费资源,不打算更改库代码,所以自己仿照poll的mainloop写了一个更加高效的epoll的mainloop 实现 #!/usr/bin/env python #
-
Python 性能优化技巧总结
1.使用测量工具,量化性能才能改进性能,常用的timeit和memory_profiler,此外还有profile.cProfile.hotshot等,memory_profiler用了psutil,所以不能跟踪cpython的扩展: 2.用C来解决费时的处理,c是效率的代名词,也是python用来解决效率问题的主要途径,甚至有时候我都觉得python是c的完美搭档.常用的是Cython,直接把py代码c化然后又能像使用py包一样使用,其次是ctypes,效率最最高的存在,最后还有CPython
-

Python 代码性能优化技巧分享
如何进行 Python 性能优化,是本文探讨的主要问题.本文会涉及常见的代码优化方法,性能优化工具的使用以及如何诊断代码的性能瓶颈等内容,希望可以给 Python 开发人员一定的参考. Python 代码优化常见技巧 代码优化能够让程序运行更快,它是在不改变程序运行结果的情况下使得程序的运行效率更高,根据 80/20 原则,实现程序的重构.优化.扩展以及文档相关的事情通常需要消耗 80% 的工作量.优化通常包含两方面的内容:减小代码的体积,提高代码的运行效率. 改进算法,选择合适的数据结构 一个
-
Python性能优化的20条建议
优化算法时间复杂度 算法的时间复杂度对程序的执行效率影响最大,在Python中可以通过选择合适的数据结构来优化时间复杂度,如list和set查找某一个元素的时间复杂度分别是O(n)和O(1).不同的场景有不同的优化方式,总得来说,一般有分治,分支界限,贪心,动态规划等思想. 减少冗余数据 如用上三角或下三角的方式去保存一个大的对称矩阵.在0元素占大多数的矩阵里使用稀疏矩阵表示. 合理使用copy与deepcopy 对于dict和list等数据结构的对象,直接赋值使用的是引用的方式.而有些情况下需
-
Python中优化NumPy包使用性能的教程
NumPy是Python中众多科学软件包的基础.它提供了一个特殊的数据类型ndarray,其在向量计算上做了优化.这个对象是科学数值计算中大多数算法的核心. 相比于原生的Python,利用NumPy数组可以获得显著的性能加速,尤其是当你的计算遵循单指令多数据流(SIMD)范式时.然而,利用NumPy也有可能有意无意地写出未优化的代码. 在这篇文章中,我们将看到一些技巧,这些技巧可以帮助你编写高效的NumPy代码.我们首先看一下如何避免不必要的数组拷贝,以节省时间和内存.因此,我们将需要深入Num
-
python 性能优化方法小结
提高性能有如下方法 1.Cython,用于合并python和c语言静态编译泛型 2.IPython.parallel,用于在本地或者集群上并行执行代码 3.numexpr,用于快速数值运算 4.multiprocessing,python内建的并行处理模块 5.Numba,用于为cpu动态编译python代码 6.NumbaPro,用于为多核cpu和gpu动态编译python代码 为了验证相同算法在上面不同实现上的的性能差异,我们先定义一个测试性能的函数 def perf_comp_data(f
-
python保存文件方法小结
1>保存为二进制文件,pkl格式 import pickle pickle.dump(data,open('file_path','wb')) #后缀.pkl可加可不加 若文件过大 pickle.dump(data,open('file_path', 'wb'),protocol=4) 读取该文件: data= pickle.load(open('file_path','rb')) 2>保存为二进制文件,npz格式 import numpy as np np.savez('file_path/
-
SQL性能优化方法及性能测试
目录 笛卡尔连接 分页limit的sql优化的几种方法 count 优化方案 笛卡尔连接 例1: 没有携带on的条件字句,此条slq查询的结构集等价于,a表包含的条数*b表包含的乘积: select * from table a cross join table b; 例2:拥有携带on字句的sql,等价于inner join: select * from table a cross join table b on a.id=b.id; 分页limit的sql优化的几种方法 规则;表包含的数据较
-
React 性能优化方法总结
目录 前言 为什么页面会出现卡顿的现象? React 到底是在哪里出现了卡顿? React 有哪些场景会需要性能优化? 一:父组件刷新,而不波及子组件. 第一种:使用 PureComponent 第三种:函数组件如何判断props的变化的更新呢? 使用 React.memo函数 使用 React.useMemo来实现对子组件的缓冲 一:组件自己控制自己是否刷新 三:减少波及范围,无关刷新数据不存入state中 场景一:无意义重复调用setState,合并相关的state 场景二:和页面刷新没有相
-
优化Apache服务器性能的方法小结
测试与提高性能 Apache服务器已经被设计得尽可能的快,即使你用一台配置不高的机器,用不着进行太复杂的设置,它的响应内容就足以塞满以前的各种窄带连接.但随网站内容日益复杂和带宽的增加,对Apache进行优化以取得更好的性能变得日益重要起来. 如果优化的结果仅仅是极小的性能提升那真是浪费时间.试想一下,你花了好几个小时甚至几天调整Apache的各种参数但结果仅是几个百分点的性能提升?因此,在优化前你做的第一步应该是测试你目前的服务器的性能水平以便决定如何优化你的服务器并衡量优化的效果. 关于对A
-
正则表达式性能优化方法(高效正则表达式书写)
这里说的正则表达式优化,主要是针对目前常用的NFA模式正则表达式,详细可以参考:正则表达式匹配解析过程探讨分析(正则表达式匹配原理).从上面例子,我们可以推断出,影响NFA类正则表达式(常见语言:GNU Emacs,Java,ergp,less,more,.NET语言, PCRE library,Perl,PHP,Python,Ruby,sed,vi )其实主要是它的"回溯",减少"回溯"次数(减少循环查找同一个字符次数),是提高性能的主要方法. 我们来看个例子:
-
浅谈webpack 构建性能优化策略小结
背景 如今前端工程化的概念早已经深入人心,选择一款合适的编译和资源管理工具已经成为了所有前端工程中的标配,而在诸多的构建工具中,webpack以其丰富的功能和灵活的配置而深受业内吹捧,逐步取代了grunt和gulp成为大多数前端工程实践中的首选,React,Vue,Angular等诸多知名项目也都相继选用其作为官方构建工具,极受业内追捧.但是,随者工程开发的复杂程度和代码规模不断地增加,webpack暴露出来的各种性能问题也愈发明显,极大的影响着开发过程中的体验. 问题归纳 历经了多个web项目
-
mysql -参数thread_cache_size优化方法 小结
说明: 根据调查发现以上服务器线程缓存thread_cache_size没有进行设置,或者设置过小,这个值表示可以重新利用保存在缓存中线程的数量,当断开连接时如果缓存中还有空间,那么客户端的线程将被放到缓存中,如果线程重新被请求,那么请求将从缓存中读取,如果缓存中是空的或者是新的请求,那么这个线程将被重新创建,如果有很多新的线程,增加这个值可以改善系统性能.通过比较 Connections 和 Threads_created 状态的变量,可以看到这个变量的作用.(-->表示要调整的值) 根据物理
-
MySQL Index Condition Pushdown(ICP)性能优化方法实例
一 概念介绍 Index Condition Pushdown (ICP)是MySQL 5.6 版本中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式. a 当关闭ICP时,index 仅仅是data access 的一种访问方式,存储引擎通过索引回表获取的数据会传递到MySQL Server 层进行where条件过滤. b 当打开ICP时,如果部分where条件能使用索引中的字段,MySQL Server 会把这部分下推到引擎层,可以利用index过滤的where条件在存储引擎层进行