pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
代码如下,步骤流程在代码注释中可见:
# -*- coding: utf-8 -*-
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql import SQLContext
from pyspark import SparkContext
#初始化数据
#初始化pandas DataFrame
df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1', 'row2'], columns=['c1', 'c2', 'c3'])
#打印数据
print df
#初始化spark DataFrame
sc = SparkContext()
if __name__ == "__main__":
spark = SparkSession\
.builder\
.appName("testDataFrame")\
.getOrCreate()
sentenceData = spark.createDataFrame([
(0.0, "I like Spark"),
(1.0, "Pandas is useful"),
(2.0, "They are coded by Python ")
], ["label", "sentence"])
#显示数据
sentenceData.select("label").show()
#spark.DataFrame 转换成 pandas.DataFrame
sqlContest = SQLContext(sc)
spark_df = sqlContest.createDataFrame(df)
#显示数据
spark_df.select("c1").show()
# pandas.DataFrame 转换成 spark.DataFrame
pandas_df = sentenceData.toPandas()
#打印数据
print pandas_df
程序结果:
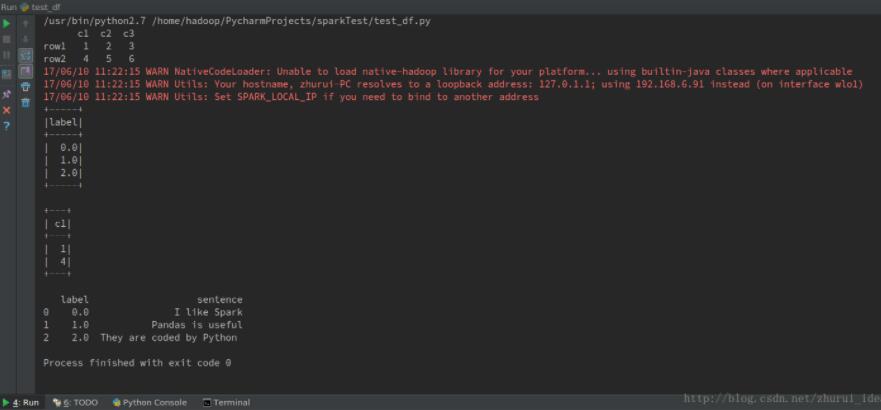
以上这篇pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python读取文本中数据并转化为DataFrame的实例
在技术问答中看到一个这样的问题,感觉相对比较常见,就单开一篇文章写下来. 从纯文本格式文件 "file_in"中读取数据,格式如下: 需要输出成"file_out",格式如下: 数据的原格式是"类别:内容",以空行"\n"为分条目,转换后变成一个条目一行,按照类别顺序依次写出内容. 建议读取后,使用pandas,把数据建立称DataFrame的表格.这样方便以后处理数据.但是原格式并不是通常的表格格式,所以要先做一些简单的处理
-
Python基于pandas实现json格式转换成dataframe的方法
本文实例讲述了Python基于pandas实现json格式转换成dataframe的方法.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import re import json from bs4 import BeautifulSoup import pandas as pd import requests import os from pandas.io.json import json_normalize class image_str
-
spark: RDD与DataFrame之间的相互转换方法
DataFrame是一个组织成命名列的数据集.它在概念上等同于关系数据库中的表或R/Python中的数据框架,但其经过了优化.DataFrames可以从各种各样的源构建,例如:结构化数据文件,Hive中的表,外部数据库或现有RDD. DataFrame API 可以被Scala,Java,Python和R调用. 在Scala和Java中,DataFrame由Rows的数据集表示. 在Scala API中,DataFrame只是一个类型别名Dataset[Row].而在Java API中,用户需要
-
pyspark 读取csv文件创建DataFrame的两种方法
方法一:用pandas辅助 from pyspark import SparkContext from pyspark.sql import SQLContext import pandas as pd sc = SparkContext() sqlContext=SQLContext(sc) df=pd.read_csv(r'game-clicks.csv') sdf=sqlc.createDataFrame(df) 方法二:纯spark from pyspark import SparkCo
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
代码如下,步骤流程在代码注释中可见: # -*- coding: utf-8 -*- import pandas as pd from pyspark.sql import SparkSession from pyspark.sql import SQLContext from pyspark import SparkContext #初始化数据 #初始化pandas DataFrame df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1
-
java 日期各种格式之间的相互转换实例代码
java 日期各种格式之间的相互转换实例代码 java日期各种格式之间的相互转换,直接调用静态方法 实例代码: java日期各种格式之间的相互转换,直接调用静态方法 package com.hxhk.cc.util; import java.text.SimpleDateFormat; import java.util.Date; import com.lowagie.text.pdf.codec.postscript.ParseException; public class DateUtil
-
pytorch numpy list类型之间的相互转换实例
如下所示: import torch from torch.autograd import Variable import numpy as np ''' pytorch中Variable与torch.Tensor类型的相互转换 ''' # 1.torch.Tensor转换成Variablea=torch.randn((5,3)) b=Variable(a) print('a',a.type(),a.shape) print('b',type(b),b.shape) # 2.Variable转换
-
Python实现从SQL型数据库读写dataframe型数据的方法【基于pandas】
本文实例讲述了Python实现从SQL型数据库读写dataframe型数据的方法.分享给大家供大家参考,具体如下: Python的pandas包对表格化的数据处理能力很强,而SQL数据库的数据就是以表格的形式储存,因此经常将sql数据库里的数据直接读取为dataframe,分析操作以后再将dataframe存到sql数据库中.而pandas中的read_sql和to_sql函数就可以很方便得从sql数据库中读写数据. read_sql 参见pandas.read_sql的文档,read_sql主
-
Python pandas DataFrame操作的实现代码
1. 从字典创建Dataframe >>> import pandas as pd >>> dict1 = {'col1':[1,2,5,7],'col2':['a','b','c','d']} >>> df = pd.DataFrame(dict1) >>> df col1 col2 0 1 a 1 2 b 2 5 c 3 7 d 2. 从列表创建Dataframe (先把列表转化为字典,再把字典转化为DataFrame) >
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=
-
python pandas dataframe 行列选择,切片操作方法
SQL中的select是根据列的名称来选取:Pandas则更为灵活,不但可根据列名称选取,还可以根据列所在的position(数字,在第几行第几列,注意pandas行列的position是从0开始)选取.相关函数如下: 1)loc,基于列label,可选取特定行(根据行index): 2)iloc,基于行/列的position: 3)at,根据指定行index及列label,快速定位DataFrame的元素: 4)iat,与at类似,不同的是根据position来定位的: 5)ix,为loc与i
-
将pandas.dataframe的数据写入到文件中的方法
导入实验常用的python包.如图2所示. [import pandas as pd]pandas用来做数据处理.[import numpy as np]numpy用来做高维度矩阵运算.[import matplotlib.pyplot as plt]matplotlib用来做数据可视化. pandas数据写入到csv文件中: [names = ['Bob','Jessica','Mary','John','Mel']]创建一个names列表[ births = [968,155,77,578,
-
pandas.DataFrame的pivot()和unstack()实现行转列
示例:有如下表需要进行行转列: 代码如下: # -*- coding:utf-8 -*- import pandas as pd import MySQLdb from warnings import filterwarnings # 由于create table if not exists总会抛出warning,因此使用filterwarnings消除 filterwarnings('ignore', category = MySQLdb.Warning) from sqlalchemy im
随机推荐
- JSONP之我见
- 在JavaScript中访问字符串的子串
- Dreamweaver常见设计疑难解答
- java中 利用正则表达式提取( )内内容
- Java RSA加密解密实现方法分析【附BASE64 jar包下载】
- 根据mysql慢日志监控SQL语句执行效率
- Python生成不重复随机值的方法
- ECMAScript6中Map/WeakMap详解
- php判断文件上传类型及过滤不安全数据的方法
- Android实现地理定位功能
- python高手之路python处理excel文件(方法汇总)
- 十分钟内学会 避免用户刷新导致重复POST提交
- Boa服务器下的ajax与cgi通信
- 花生壳与Windows2003 建立WEB服务器的图文教程第1/2页
- Linux:文件命令精通指南
- 解析Java中的Field类和Method类
- C++ 数据结构之布隆过滤器
- java实现 二叉搜索树功能
- Vue2.0实现组件之间数据交互和通信操作示例
- Python学习笔记之读取文件、OS模块、异常处理、with as语法示例