服务器常用磁盘阵列RAID原理、种类及性能优缺点对比
磁盘阵列(Redundant Arrays of Independent Disks,RAID)
1. 存储的数据一定分片;
2. 分基于软件的软RAID(如mdadm)和基于硬件的硬RAID(如RAID卡);
3. RAID卡如同网卡一样有集成板载的也有独立的(PCI-e),一般独立RAID卡性能相对较好,淘宝一搜便可看到他们的原形;
4. 现在基本上服务器都原生硬件支持几种常用的RAID;
5. 当然还有更加高大上的专用于存储的磁盘阵列柜产品,有专用存储技术,规格有如12/24/48盘一柜等,盘可选机械/固态,3.5/2.5寸等。
| 级别 | 特征 | 原理 | 单元 | 冗余 | 性能 | 利用率 | 最多坏 | 用途 | 缺陷 |
| RAID0 | 条带 | 分片分散存入2块硬盘 | 2 | 否 | 读写速度2倍 | 100% | 0/2 | SWAP/TMP | 不冗余,数据难恢复 |
| RAID1 | 镜像 | 相同数据存入2块硬盘 | 2 | 是 | 写速度不变 读速度2倍 | 50% | 1/2 | 数据备份 | 读写速度没加,利用率低 |
| RAID4 | 校验 | 分片分散存入2块硬盘 校验码存入第3块硬盘 | 3 | 是 | 读写速度2倍 | 2/3=66% | 1/3 | 用的很少 | 1. 坏盘时另外2块需要重新计算还原坏盘数据 2. 校验码盘压力大成为瓶颈 |
| RAID5 | 校验 | 分片和校验码混合存储 | 3 | 是 | 读写速度2倍 | 2/3=66% | 1/3 | 用的不多 | 坏盘时另外2块需要重新计算还原坏盘数据 |
| RAID6 | 校验 | 分片盘校验码盘分别2个 数据分片校验码计算2次 | 4 | 是 | 读写速度2倍 | 2/4 | 2/4 1∈2 | 用的很少 | “部队中有一半是搞后勤的,感觉还是不太爽。” |
| RAID10 | 1+0 | 2块硬盘1组先做RAID1 多组RAID1再做RAID0 | 4 | 是 | 读写速度N倍 N为组数 | 2/4 | 2/4 1∈2 | 用的最多 | - |
| RAID50 | 5+0 | 3块硬盘1组先做RAID5 多组再做RAID0 | 6 | 是 | 读写数读2N倍 N为组数 | 4/6 | 2/6 1∈3 | 土豪用的 | “好是好,就是贵!” |
近来想建立一个私有云系统,涉及到安装使用一台网络存储服务器。对于服务器中硬盘的连接,选用哪种RAID模式能准确满足需求收集了资料,简单整理后记录如下:
一、RAID模式优缺点的简要介绍
目前被运用较多的RAID模式其优缺点大致是这样的:
1、RAID0模式
优点:在RAID 0状态下,存储数据被分割成两部分,分别存储在两块硬盘上,此时移动硬盘的理论存储速度是单块硬盘的2倍,实际容量等于两块硬盘中较小一块硬盘的容量的2倍。
缺点:任何一块硬盘发生故障,整个RAID上的数据将不可恢复。
备注:存储高清电影比较适合。
2、RAID1模式
优点:此模式下,两块硬盘互为镜像。当一个硬盘受损时,换上一块全新硬盘(大于或等于原硬盘容量)替代原硬盘即可自动恢复资料和继续使用,移动硬盘的实际容量等于较小一块硬盘的容量,存储速度与单块硬盘相同。RAID 1的优势在于任何一块硬盘出现故障是,所存储的数据都不会丢失。
缺点:该模式可使用的硬盘实际容量比较小,仅仅为两颗硬盘中最小硬盘的容量。
备注:非常重要的资料,如数据库,个人资料,是万无一失的存储方案。
3、RAID 0+1模式
RAID 0+1是磁盘分段及镜像的结合,采用2组RAID0的磁盘阵列互为镜像,它们之间又成为一个RAID1的阵列。硬盘使用率只有50%,但是提供最佳的速度及可靠度。
4、RAID 3模式
RAID3是把数据分成多个“块”,按照一定的容错算法,存放在N+1个硬盘上,实际数据占用的有效空间为N个硬盘的空间总和,而第N+1个硬盘存储的数据是校验容错信息,当这N+1个硬盘中的其中一个硬盘出现故障时,从其它N个硬盘中的数据也可以恢复原始数据。
5、RAID 5模式
RAID5不对存储的数据进行备份,而是把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复被损坏的数据。
6、RAID 10模式
RAID10最少需要4块硬盘才能完成。把2块硬盘组成一个RAID1,然后两组RAID1组成一个RAID0。虽然RAID10方案造成了50%的磁盘浪费,但是它提供了200%的速度和单磁盘损坏的数据安全性。
二、另外三种硬件快速硬件设置模式简介
在收集资料时看到有的硬件设备提供快速磁盘模式设置,也很方便大家的使用,具体情况如下:
1、Clone模式
克隆模式,磁盘全部数据一样,以最小硬盘的为准。
2、Large模式
硬盘容量简单相加,将几个硬盘变成一个硬盘,容量为几个硬盘容量之和,此模式下可以获得最大的硬盘空间。
3、Normal模式
硬盘分别处于正常、独立的状态,可以分别独立的写入或读取资料,能使用的实际容量分别为4个硬盘的容量。如果其中一个硬盘受损,其他几个硬盘不会受影响。
三、RAID使用简明注意事项
★使用前请先备份硬盘的资料,一旦进行RAID设定或是变更RAID模式,将会清除硬盘里的所有资料,以及无法恢复;
★建立RAID时,建议使用相同品牌、型号和容量的硬盘,以确保性能和稳定;
★请勿随意更换或取出硬盘,如果取出了硬盘,请记下硬盘放入两个仓位的顺序不得更改,以及请勿只插入某一块硬盘使用,以避免造成资料损坏或丢失;
★如果旧硬盘曾经在RAID模式下使用,请先进清除硬盘RAID信息,让硬盘回复至出厂状态,以免RAID建立失败;
★RAID0模式下,其中一个硬盘损坏时,其它硬盘所有资料都将丢失;
★RAID1模式下,如果某一块硬盘受损,可以用一块大于或等于受损硬盘容量的新硬盘替换坏硬盘然后开机即可自动恢复和修复资料以及RAID模式。此过程需要一定时间,请耐心等待
四、细数RAID模式
1、概念
磁盘阵列(Redundant Arrays of Inexpensive Disks,RAID),有“价格便宜且多余的磁盘阵列”之意。原理是利用数组方式来作磁盘组,配合数据分散排列的设计,提升数据的安全性。磁盘阵列是由很多便宜、容量较小、稳定性较高、速度较慢磁盘,组合成一个大型的磁盘组,利用个别磁盘提供数据所产生加成效果提升整个磁盘系统效能。同时利用这项技术,将数据切割成许多区段,分别存放在各个硬盘上。磁盘阵列还能利用同位检查(Parity Check)的观念,在数组中任一颗硬盘故障时,仍可读出数据,在数据重构时,将数据经计算后重新置入新硬盘中。
2、规范
RAID技术主要包含RAID 0~RAID 50等数个规范,它们的侧重点各不相同,常见的规范有如下几种:
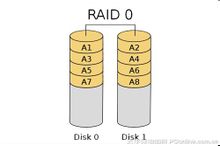
RAID 0:RAID 0连续以位或字节为单位分割数据,并行读/写于多个磁盘上,因此具有很高的数据传输率,但它没有数据冗余,因此并不能算是真正的RAID结构。RAID 0只是单纯地提高性能,并没有为数据的可靠性提供保证,而且其中的一个磁盘失效将影响到所有数据。因此,RAID 0不能应用于数据安全性要求高的场合。

RAID 1:它是通过磁盘数据镜像实现数据冗余,在成对的独立磁盘上产生互为备份的数据。当原始数据繁忙时,可直接从镜像拷贝中读取数据,因此RAID 1可以提高读取性能。RAID 1是磁盘阵列中单位成本最高的,但提供了很高的数据安全性和可用性。当一个磁盘失效时,系统可以自动切换到镜像磁盘上读写,而不需要重组失效的数据。
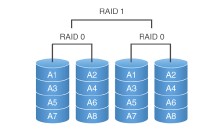
RAID 0+1: 也被称为RAID 10标准,实际是将RAID 0和RAID 1标准结合的产物,在连续地以位或字节为单位分割数据并且并行读/写多个磁盘的同时,为每一块磁盘作磁盘镜像进行冗余。它的优点是同时拥有RAID 0的超凡速度和RAID 1的数据高可靠性,但是CPU占用率同样也更高,而且磁盘的利用率比较低。
RAID 2:将数据条块化地分布于不同的硬盘上,条块单位为位或字节,并使用称为“加重平均纠错码(海明码)”的编码技术来提供错误检查及恢复。这种编码技术需要多个磁盘存放检查及恢复信息,使得RAID 2技术实施更复杂,因此在商业环境中很少使用。
RAID 3:它同RAID 2非常类似,都是将数据条块化分布于不同的硬盘上,区别在于RAID 3使用简单的奇偶校验,并用单块磁盘存放奇偶校验信息。如果一块磁盘失效,奇偶盘及其他数据盘可以重
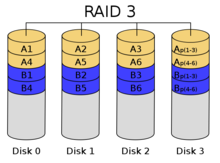
新产生数据;如果奇偶盘失效则不影响数据使用。RAID 3对于大量的连续数据可提供很好的传输率,但对于随机数据来说,奇偶盘会成为写操作的瓶颈。
RAID 4:RAID 4同样也将数据条块化并分布于不同的磁盘上,但条块单位为块或记录。RAID 4使用一块磁盘作为奇偶校验盘,每次写操作都需要访问奇偶盘,这时奇偶校验盘会成为写操作的瓶颈,因此RAID 4在商业环境中也很少使用。
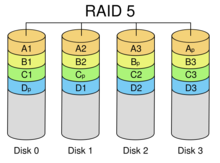
RAID 5:RAID 5不单独指定的奇偶盘,而是在所有磁盘上交叉地存取数据及奇偶校验信息。在RAID 5上,读/写指针可同时对阵列设备进行操作,提供了更高的数据流量。RAID 5更适合于小数据块和随机读写的数据。RAID 3与RAID 5相比,最主要的区别在于RAID 3每进行一次数据传输就需涉及到所有的阵列盘;而对于RAID 5来说,大部分数据传输只对一块磁盘操作,并可进行并行操作。在RAID 5中有“写损失”,即每一次写操作将产生四个实际的读/写操作,其中两次读旧的数据及奇偶信息,两次写新的数据及奇偶信息。
RAID 6:与RAID 5相比,RAID 6增加了第二个独立的奇偶校验信息块。两个独立的奇偶系统使用不同的算法,数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID 6需要分配给奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。较差的性能和复杂的实施方式使得RAID 6很少得到实际应用。
RAID 7:这是一种新的RAID标准,其自身带有智能化实时操作系统和用于存储管理的软件工具,可完全独立于主机运行,不占用主机CPU资源。RAID 7可以看作是一种存储计算机(Storage Computer),它与其他RAID标准有明显区别。除了以上的各种标准(如表1),我们可以如RAID 0+1那样结合多种RAID规范来构筑所需的RAID阵列,例如RAID 5+3(RAID 53)就是一种应用较为广泛的阵列形式。用户一般可以通过灵活配置磁盘阵列来获得更加符合其要求的磁盘存储系统。
RAID 5E(RAID 5 Enhencement): RAID 5E是在RAID 5级别基础上的改进,与RAID 5类似,数据的校验信息均匀分布在各硬盘上,但是,在每个硬盘上都保留了一部分未使用的空间,这部分空间没有进行条带化,最多允许两块物理硬盘出现故障。看起来,RAID 5E和RAID 5加一块热备盘好象差不多,其实由于RAID 5E是把数据分布在所有的硬盘上,性能会比RAID5 加一块热备盘要好。当一块硬盘出现故障时,有故障硬盘上的数据会被压缩到其它硬盘上未使用的空间,逻辑盘保持RAID 5级别。
RAID 5EE: 与RAID 5E相比,RAID 5EE的数据分布更有效率,每个硬盘的一部分空间被用作分布的热备盘,它们是阵列的一部分,当阵列中一个物理硬盘出现故障时,数据重建的速度会更快。
RAID 50:RAID50是RAID5与RAID0的结合。此配置在RAID5的子磁盘组的每个磁盘上进行包括奇偶信息在内的数据的剥离。每个RAID5子磁盘组要求三个硬盘。RAID50具备更高的容错能力,因为它允许某个组内有一个磁盘出现故障,而不会造成数据丢失。而且因为奇偶位分部于RAID5子磁盘组上,故重建速度有很大提高。优势:更高的容错能力,具备更快数据读取速率的潜力。需要注意的是:磁盘故障会影响吞吐量。故障后重建信息的时间比镜像配置情况下要长。
3、优点
提高传输速率。RAID通过在多个磁盘上同时存储和读取数据来大幅提高存储系统的数据吞吐量(Throughput)。在RAID中,可以让很多磁盘驱动器同时传输数据,而这些磁盘驱动器在逻辑上又是一个磁盘驱动器,所以使用RAID可以达到单个磁盘驱动器几倍、几十倍甚至上百倍的速率。这也是RAID最初想要解决的问题。因为当时CPU的速度增长很快,而磁盘驱动器的数据传输速率无法大幅提高,所以需要有一种方案解决二者之间的矛盾。RAID最后成功了。
通过数据校验提供容错功能。普通磁盘驱动器无法提供容错功能,如果不包括写在磁盘上的CRC(循环冗余校验)码的话。RAID容错是建立在每个磁盘驱动器的硬件容错功能之上的,所以它提供更高的安全性。在很多RAID模式中都有较为完备的相互校验/恢复的措施,甚至是直接相互的镜像备份,从而大大提高了RAID系统的容错度,提高了系统的稳定冗余性。
4、实现
磁盘阵列有两种方式可以实现,那就是“软件阵列”与“硬件阵列”。
软件阵列是指通过网络操作系统自身提供的磁盘管理功能将连接的普通SCSI卡上的多块硬盘配置成逻辑盘,组成阵列。软件阵列可以提供数据冗余功能,但是磁盘子系统的性能会有所降低,有的降低幅度还比较大,达30%左右。
硬件阵列是使用专门的磁盘阵列卡来实现的。硬件阵列能够提供在线扩容、动态修改阵列级别、自动数据恢复、驱动器漫游、超高速缓冲等功能。它能提供性能、数据保护、可靠性、可用性和可管理性的解决方案。阵列卡专用的处理单元来进行操作,它的性能要远远高于常规非阵列硬盘,并且更安全更稳定。
磁盘阵列其实也分为软阵列 (Software Raid)和硬阵列 (Hardware Raid) 两种. 软阵列即通过软件程序并由计算机的 CPU提供运行能力所成. 由于软件程式不是一个完整系统故只能提供最基本的 RAID容错功能. 其他如热备用硬盘的设置, 远程管理等功能均一一欠奉. 硬阵列是由独立操作的硬件提供整个磁盘阵列的控制和计算功能. 不依靠系统的CPU资源.
由于硬阵列是一个完整的系统, 所有需要的功能均可以做进去. 所以硬阵列所提供的功能和性能均比软阵列好. 而且, 如果你想把系统也做到磁盘阵列中, 硬阵列是唯一的选择. 故我们可以看市场上 RAID 5 级的磁盘阵列均为硬阵列. 软 阵列只适用于 Raid 0 和 Raid 1. 对于我们做镜像用的镜像塔, 肯定不会用 Raid 0或 Raid 1。作为高性能的存储系统,已经得到了越来越广泛的应用。RAID的级别从RAID概念的提出到现在,已经发展了六个级别,其级别分别是0、1、2、3、4、5等。但是最常用的是0、1、3、5四个级别。
五、个人用户该选那种RAID模式
首先要分析清楚,我们需要存储的文件有什么样的属性。这其中需要大量存储的和占用存储量大的文件是两回事儿。
从使用角度粗略分,个人需要存储的文件大致有文本文件、照片录像、影音文件、应用程序等。
1、文本文件:大量长期存放,阶段性更新,但其占用空间小,安全性要求个别较高,大部分一般;
2、照片录像:大量长期存放,永久性记录,占用空间大,安全性要求高,一旦损失很难弥补;
3、影音文件:一部分大量长期存放,一部分大量短期存放,阶段性更新,占用空间大,安全性要求一般,即便损失了,也可以再从网络上下载恢复;
4、应用程序:这其中包括一些软件和硬件的驱动等,对于软件,目前基本可以从网络上获得,驱动程序有时需要预先备份,安装设备时随时可用,属于量少但要长期存放的,阶段性更新,安全性要求一般。
看看自己需要对哪种类型的文件进行存储,再选择自己需要的RAID模式即可。
本人的照片和私人录影资料较多,平时喜欢收集APE等无损格式的音乐文件,对于个人来说这都是至宝,不可有所损失,再有就是一些硬件的驱动程序,相对比较重要,另外会编辑少量的个人文件,阶段性比较重要,最后是影片,看完也就删除了,不太重要。而照片录像和无损音乐占用的空间又是巨大的,安全性要求又很高,权衡后,在节约资金确保安全的前提下,准备购置五块大容量硬盘,组成NAS存储服务器,选择RAID5模式。
顺便说,购置五快硬盘的原因还有一个,就是我使用的是老机箱改造NAS服务器,市面上有3转5的硬盘笼子可以简单将原有的3个光驱位变成5块硬盘的存储位,考虑到家用存储8T的容量已经足够了,10T基本上可以无忧了,所以选择了5块硬盘,每块2T容量。当然组成RAOD5后会少于10T,那也足够了!
NAS的好处很多,这里就不在赘述,有兴趣的朋友建议深入了解。它既可以完成集中存储还可以完成诸如自动BT下载,网络打印机,苹果媒体服务器等众多私有云功能,是很好的家庭网络应用解决方案。
相关推荐
-
浅谈带缓冲I/O 和不带缓冲I/O的区别与联系
这里搜集从网上看到的一些言论,自认为还是比较靠谱的,有些不靠谱的根据自己的理解进行了修正. 首先要明白不带缓冲的概念:所谓不带缓冲,并不是指内核不提供缓冲,而是只单纯的系统调用,不是函数库的调用.系统内核对磁盘的读写都会提供一个块缓冲(在有些地方也被称为内核高速缓存),当用write函数对其写数据时,直接调用系统调用,将数据写入到块缓冲进行排队,当块缓冲达到一定的量时,才会把数据写入磁盘.因此所谓的不带缓冲的I/O是指进程不提供缓冲功能(但内核还是提供缓冲的).每调用一次write或read函数
-
Python实现测试磁盘性能的方法
本文实例讲述了Python实现测试磁盘性能的方法.分享给大家供大家参考.具体如下: 该代码做了如下工作: create 300000 files (512B to 1536B) with data from /dev/urandom rewrite 30000 random files and change the size read 30000 sequential files read 30000 random files delete all files sync and drop cac
-
由注册表引起的 I/O 操作发生了不可恢复的错误修复方法
服务器出现此问题: 很多使用Windows Server 2003系统的用户都会收到如下错误: 事件类型: 错误 事件来源: Application Popup 事件种类: 无 事件 ID: 333 日期: 2007-8-11 事件: 8:48:03 用户: N/A 计算机: LZ_YQ 描述: 由注册表引起的 I/O 操作发生了不可恢复的错误. 注册表将不能读取.写出或刷新包含注册表系统图像的其中一个文件. 然后系统失去响应,需要重新启动. 事件ID是333,英文日志为 Event Type:
-
Java I/O深入学习之File和RandomAccessFile
前言 I/O系统即输入/输出系统,对于一门程序语言来说,创建一个好的输入/输出系统并非易事.因为不仅存在各种I/O源端和想要与之通信的接收端(文件.控制台.网络链接等),而且还需要支持多种不同方式的通信(顺序.随机存取.缓冲.二进制.按字符.按行.按字等). Java类库的设计者通过创建大量的类来解决这个难题,比如面向字节的类(字节流,InputStream.OutputStream).面向字符和基于Unicode的类(字节流,Reader.Writer).nio类(新I/O,为了改进性能及功能
-

解析NodeJS异步I/O的实现
在现在的项目开发中,任何一个大型项目绝对不是简简单单的采用一个种语言和一种框架,因为每种语言和框架各有优势,与其死守一个,不与取各家之所长,依次得到一个高性能.搞扩展的产品. 对于一个.NET开发者,尤其是主要从事Web开发的.NET程序员,个人觉得有必要学习一门性能优越的Web平台开发语言.一个开发者不能简简单单的只学习一门语言,思维应该开阔,从各个方面去看待同样的一个问题,这样或许会得到另一番效果和见解,个人认为应该学习一下其他的语言,这样有利于我们对比语言的优势和缺点,例如java.nod
-
windows磁盘I/O的性能评估方法详解
通常,我们很容易观察到数据库服务器的内存和CPU压力.但是对I/O压力没有直观的判断方法. 磁盘有两个重要的参数: Seek time. Rotational latency.正常的I/O计数为:①1000/(Seek time+Rotational latency)*0.75,在此范围内属正常.当达到85%的I/O计数以上时则基本认为已经存在I/O瓶劲. 理论情况下,磁盘的随机读计数为125.顺序读计数为225.对于数据文件而言是随机读写,日志文件是顺序读写.因此,数据文件建议存放于RAID5
-
服务器常用磁盘阵列RAID原理、种类及性能优缺点对比
磁盘阵列(Redundant Arrays of Independent Disks,RAID) 1. 存储的数据一定分片: 2. 分基于软件的软RAID(如mdadm)和基于硬件的硬RAID(如RAID卡): 3. RAID卡如同网卡一样有集成板载的也有独立的(PCI-e),一般独立RAID卡性能相对较好,淘宝一搜便可看到他们的原形: 4. 现在基本上服务器都原生硬件支持几种常用的RAID; 5. 当然还有更加高大上的专用于存储的磁盘阵列柜产品,有专用存储技术,规格有如12/24/48盘一柜等
-
Git使用基础篇(一些常用命令和原理)
Git是一个分布式的版本控制工具,本篇文章从介绍Git开始,重点在于介绍Git的基本命令和使用技巧,让你尝试使用Git的同时,体验到原来一个版本控制工具可以对开发产生如此之多的影响,文章分为两部分,第一部分介绍Git的一些常用命令,其中穿插介绍Git的基本概念和原理,第二篇重点介绍 Git的使用技巧,最后会在Git Hub上创建一个开源项目开启你的Git实战之旅 1.Git是什么 Git在Wikipedia上的定义:它是一个免费的.分布式的版本控制工具,或是一个强调了速度快的源代码管理工具.Gi
-
Java常用集合与原理解析
目录 迭代器 集合框架中的接口 具体集合 散列码 树集 队列 优先队列 映射 基本映射 映射视图 弱散列映射 链接散列集合映射 枚举集与映射 标识散列映射 Java 最初版本只为常用的数据结构提供了很少的一组类:Vector.Stack.Hashtable.BitSet 与 Enumeration 接口 迭代器 public interface Collection<E> { boolean add(E element); Iterator<E> iterator(); ... }
-
基于JS对象创建常用方式及原理分析
前言 俗话说"在js语言中,一切都对象",而且创建对象的方式也有很多种,所以今天我们做一下梳理 最简单的方式 JavaScript创建对象最简单的方式是:对象字面量形式或使用Object构造函数 对象字面量形式 var person = new Object(); person.name = "jack"; person.sayName = function () { alert(this.name) } 使用Object构造函数 var person = { na
-
Java遍历集合方法分析(实现原理、算法性能、适用场合)
概述 Java语言中,提供了一套数据集合框架,其中定义了一些诸如List.Set等抽象数据类型,每个抽象数据类型的各个具体实现,底层又采用了不同的实现方式,比如ArrayList和LinkedList. 除此之外,Java对于数据集合的遍历,也提供了几种不同的方式.开发人员必须要清楚的明白每一种遍历方式的特点.适用场合.以及在不同底层实现上的表现.下面就详细分析一下这一块内容. 数据元素是怎样在内存中存放的? 数据元素在内存中,主要有2种存储方式: 1.顺序存储,Random Access(Di
-
JS常用的几种数组遍历方式以及性能分析对比实例详解
本文实例讲述了JS常用的几种数组遍历方式以及性能分析对比.分享给大家供大家参考,具体如下: 前言 这一篇与上一篇 JS几种变量交换方式以及性能分析对比 属于同一个系列,本文继续分析JS中几种常用的数组遍历方式以及各自的性能对比 起由 在上一次分析了JS几种常用变量交换方式以及各自性能后,觉得这种方式挺好的,于是抽取了核心逻辑,封装成了模板,打算拓展成一个系列,本文则是系列中的第二篇,JS数组遍历方式的分析对比 JS数组遍历的几种方式 JS数组遍历,基本就是for,forin,foreach,fo
-
Ubuntu服务器常用命令汇总
下面的命令大都需要在 控制台 / 终端 / shell 下输入. 任何一个使用 'sudo' 作为前缀的命令都需要拥有管理员 (或 root) 访问权限. 所以你会被提示输入你自己的密码. 查看软件xxx安装内容 查看显卡使用情况 nvidia-smi 查看硬盘使用情况 df -hl # 查看磁盘剩余空间 df -h # 查看每个根路径的分区大小 查看用户配额及使用情况 quota -uvs username 打开visdom python -m visdom.server 后面可加参数,如在9
-
详谈MySQL和MariaDB区别与性能全面对比
MariaDB数据库介绍 MariaDB数据库管理系统是MySQL的一个分支,主要由开源社区在维护,采用GPL授权许可.开发这个分支的原因之一是:甲骨文公司收购了MySQL后,有将MySQL闭源的潜在风险,因此社区采用分支的方式来避开这个风险. MariaDB的目的是完全兼容MySQL,包括API和命令行,使之能轻松成为MySQL的代替品. MariaDB由MySQL的创始人麦克尔·维德纽斯主导开发,他早前曾以10亿美元的价格,将自己创建的公司MySQL卖给了SUN,此后,随着SUN被甲骨文收购
-
java原生序列化和Kryo序列化性能实例对比分析
简介 最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括: 专门针对Java语言的:Kryo,FST等等 跨语言的:Protostuff,ProtoBuf,Thrift,Avro,MsgPack等等 这些序列化方式的性能多数都显著优于hessian2(甚至包括尚未成熟的dubbo序列化).有鉴于此,我们为dubbo引入Kryo和FST这 两种高效Java序列化实现,来逐步取代hessian2.其中,Kryo是一种非常成熟的序列化实现,已经在Twitter.Group
-
磁盘阵列RAID讲解
RAID定义 RAID(Redundant Array of Independent Disk 独立冗余磁盘阵列)技术是加州大学伯克利分校1987年提出,最初是为了组合小的廉价磁盘来代替大的昂贵磁盘,同时希望磁盘失效时不会使对数据的访问受损失而开发出一定水平的数据保护技术.RAID就是一种由多块廉价磁盘构成的冗余阵列,在操作系统下是作为一个独立的大型存储设备出现.RAID可以充分发挥出多块硬盘的优势,可以提升硬盘速度,增大容量,提供容错功能够确保数据安全性,易于管理的优点,在任何一块硬盘出现问题