特征脸(Eigenface)理论基础之PCA主成分分析法
在之前的博客 人脸识别经典算法一:特征脸方法(Eigenface)里面介绍了特征脸方法的原理,但是并没有对它用到的理论基础PCA做介绍,现在做补充。请将这两篇博文结合起来阅读。以下内容大部分参考自斯坦福机器学习课程:http://cs229.stanford.edu/materials.html
假设我们有一个关于机动车属性的数据集{x(i);i=1,...,m}(m代表机动车的属性个数),例如最大速度,最大转弯半径等。假设x(i)本质上是n维的空间的一个元素,其中n<<m,但是n对我们来说是未知的。假设xi和xj分别代表车以英里和公里为单位的最大速度。显然这两个属性是冗余的,因为它们两个是有线性关系而且可以相互转化的。因此如果仅以xi和xj来考虑的话,这个数据集是属于m-1维而不是m维空间的,所以n=m-1。推广之,我们该用什么方法降低数据冗余性呢?
首先考虑一个例子,假设有一份对遥控直升机操作员的调查,用x(i)1(1是下标,原谅我这操蛋的排版吧)表示飞行员i的飞行技能,x(i)2表示飞行员i喜欢飞行的程度。通常遥控直升飞机是很难操作的,只有那些非常坚持而且真正喜欢驾驶的人才能熟练操作。所以这两个属性x(i)1和x(i)2相关性是非常强的。我们可以假设两者的关系是按正比关系变化的,如下图里的u1所示,数据散布在u1两侧是因为有少许噪声。
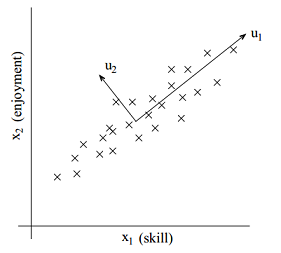
接下来就是如何计算u1的方向了。首先我们需要预处理数据。
1.令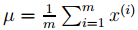
2.用x(i)-μ替代x(i)
3.求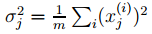
4.用x(i)j/σj替代x(i)j
步骤1-2其实是将数据集的均值归零,也就是只取数据的偏差部分,对于本身均值为零的数据可以忽略这两步。步骤3-4是按照每个属性的方差将数据重新度量,也可以理解为归一化。因为对于不同的属性(比如车的速度和车座数目)如果不归一化是不具有比较性的,两者不在一个量级上。如果将pca应用到图像上的话是不需要步骤3-4的,因为每个像素(相当于不同的属性)的取值范围都是一样的。
数据经过如上处理之后,接下来就是寻找数据大致的走向了。一种方法是找到一个单位向量u,使所有数据在u上的投影之和最大,当然数据并不是严格按照u的方向分布的,而是分布在其周围。考虑下图的数据分布(这些数据已经做了前期的预处理)。
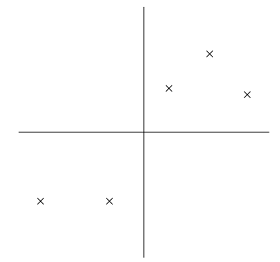
下图中,星号代表数据,原点代表数据在单位向量u上的投影(|x||u|cosΘ)
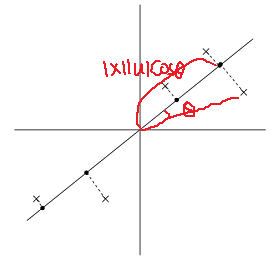
从上图可以看到,投影得到的数据仍然有很大的方差,而且投影点离原点很远。如果采取与上图u垂直的方向,则可以得到下图:
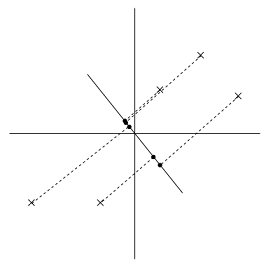
这里得到的投影方差比较小,而且离原点也更近。
上述u的方向只是感性的选择出来的,为了将选择u的步骤正式确定下来,可以假定在给定单位向量u和数据点x的情况下,投影的长度是xTu。举个例子,如果x(i)是数据集中的一个点(上图中的一个星号),那它在u上的投影xTu就是圆点到原点的距离(是标量哦)。所以,为了最大化投影的方差,我们需要选择一个单位向量u来最大化下式:
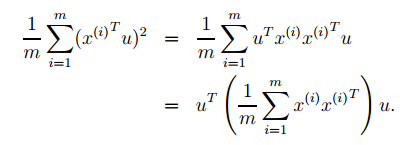
明显,按照||u||2=1(确保u是单位向量)来最大化上式就是求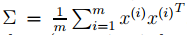 的主特征向量。而其实是数据集的协方差矩阵。
的主特征向量。而其实是数据集的协方差矩阵。
做个总结,如果我们要找数据集分布的一维子空间(就是将m维的数据用一维数据来表示),我们要选择协方差矩阵的主特征向量。推广之,如果要找k维的子空间,那就应该选择协方差矩阵的k个特征向量u1,u2,...,uk。ui(i=1,2,...,k)就是用来表征数据集的新坐标系。
为了在u1,u2,...,uk的基础上表示x(i),我们只需要计算
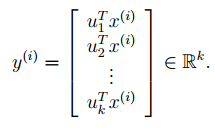
其中x(i)是属于n维空间的向量,而y(i)给出了基于k维空间的表示。因此说,PCA是一个数据降维算法。u1,u2,...,uk称为数据的k个主成分。
介绍到这里,还需要注意一些为题:
1、为什么u要选择单位向量
选择单位向量是为了统一表示数据,不选成单位的也可以,但各个向量长度必须统一,比如统一长度为2、3等等。
2、各个u要相互正交
如果u不正交,那么在各个u上的投影将含有冗余成分
2、为什么要最大化投影的方差
举个例子,如果在某个u上的投影方差为0,那这个u显然无法表示原数据,降维就没有意义了。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python使用三种方法实现PCA算法
- 在Python中使用swapCase()方法转换大小写的教程
- python结合opencv实现人脸检测与跟踪
- Python 40行代码实现人脸识别功能
- python中使用OpenCV进行人脸检测的例子
- python使用opencv进行人脸识别
- python实现人脸识别代码
- python+opencv实现的简单人脸识别代码示例
- 详解如何用OpenCV + Python 实现人脸识别
- Python+OpenCV人脸检测原理及示例详解
相关推荐
-

python使用opencv进行人脸识别
环境 ubuntu 12.04 LTS python 2.7.3 opencv 2.3.1-7 安装依赖 sudo apt-get install libopencv-* sudo apt-get install python-opencv sudo apt-get install python-numpy 示例代码 #!/usr/bin/env python #coding=utf-8 import os from PIL import Image, ImageDraw import cv d
-
Python使用三种方法实现PCA算法
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目更少的k个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的k个特征互不相关.关于PCA的更多介绍,请参考:https://en.wikipedia.org/wiki/Principal_component_analysis. 主成分分析(PCA) vs 多元判别式分析(MD
-
在Python中使用swapCase()方法转换大小写的教程
swapCase()方法返回所有可大小写,基于字符大小写交换字符串的一个副本. 语法 以下是swapCase()方法的语法: str.swapcase(); 参数 NA 返回值 此方法返回其中所有基于大小写字符交换字符串的一个副本. 例子 下面的例子显示的swapCase()方法的使用. #!/usr/bin/python str = "this is string example....wow!!!"; print str.swapcase(); str = "THIS I
-
Python 40行代码实现人脸识别功能
前言 很多人都认为人脸识别是一项非常难以实现的工作,看到名字就害怕,然后心怀忐忑到网上一搜,看到网上N页的教程立马就放弃了.这些人里包括曾经的我自己.其实如果如果你不是非要深究其中的原理,只是要实现这一工作的话,人脸识别也没那么难.今天我们就来看看如何在40行代码以内简单地实现人脸识别. 一点区分 对于大部分人来说,区分人脸检测和人脸识别完全不是问题.但是网上有很多教程有无无意地把人脸检测说成是人脸识别,误导群众,造成一些人认为二者是相同的.其实,人脸检测解决的问题是确定一张图上有木有人脸,而人
-
python结合opencv实现人脸检测与跟踪
模式识别课上老师留了个实验,在VC++环境下利用OpenCV库编程实现人脸检测与跟踪. 然后就开始下载opencv和vs2012,再然后,配置了好几次还是配置不成功,这里不得不吐槽下微软,软件做这么大,这么难用真的好吗? 于是就尝试了一下使用python完成实验任务,大概过程就是这样子的: 首先,配置运行环境: 下载opencv和python的比较新的版本,推荐opencv2.4.X和python2.7.X. 直接去官网下载就ok了,python安装时一路next就行,下载的opencv.exe
-
python实现人脸识别代码
从实时视频流中识别出人脸区域,从原理上看,其依然属于机器学习的领域之一,本质上与谷歌利用深度学习识别出猫没有什么区别.程序通过大量的人脸图片数据进行训练,利用数学算法建立建立可靠的人脸特征模型,如此即可识别出人脸.幸运的是,这些工作OpenCV已经帮我们做了,我们只需调用对应的API函数即可,先给出代码: #-*- coding: utf-8 -*- import cv2 import sys from PIL import Image def CatchUsbVideo(window_name
-
python+opencv实现的简单人脸识别代码示例
# 源码如下: #!/usr/bin/env python #coding=utf-8 import os from PIL import Image, ImageDraw import cv def detect_object(image): '''检测图片,获取人脸在图片中的坐标''' grayscale = cv.CreateImage((image.width, image.height), 8, 1) cv.CvtColor(image, grayscale, cv.CV_BGR2GR
-
详解如何用OpenCV + Python 实现人脸识别
下午的时候,配好了OpenCV的Python环境,OpenCV的Python环境搭建.于是迫不及待的想体验一下opencv的人脸识别,如下文. 必备知识 Haar-like 通俗的来讲,就是作为人脸特征即可. Haar特征值反映了图像的灰度变化情况.例如:脸部的一些特征能由矩形特征简单的描述,如:眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色要深等. opencv api 要想使用opencv,就必须先知道其能干什么,怎么做.于是API的重要性便体现出来了.就本例而言,使用到的函数
-
Python+OpenCV人脸检测原理及示例详解
关于opencv OpenCV 是 Intel 开源计算机视觉库 (Computer Version) .它由一系列 C 函数和少量 C++ 类构成,实现了图像处理和计算机视觉方面的很多通用算法. OpenCV 拥有包括 300 多个 C 函数的跨平台的中.高层 API .它不依赖于其它的外部库 -- 尽管也可以使用某些外部库. OpenCV 对非商业应用和商业应用都是免费 的.同时 OpenCV 提供了对硬件的访问,可以直接访问摄像头,并且 opencv 还提供了一个简单的 GUI(graph
-
python中使用OpenCV进行人脸检测的例子
OpenCV的人脸检测功能在一般场合还是不错的.而ubuntu正好提供了python-opencv这个包,用它可以方便地实现人脸检测的代码. 写代码之前应该先安装python-opencv: 复制代码 代码如下: $ sudo apt-get install python-opencv 具体原理就不多说了,可以参考一下这篇文章.直接上源码. 复制代码 代码如下: #!/usr/bin/python# -*- coding: UTF-8 -*- # face_detect.py # Face De