Python数据抓取爬虫代理防封IP方法
爬虫:一段自动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息,一般来说,Python爬虫程序很多时候都要使用(飞猪IP)代理的IP地址来爬取程序,但是默认的urlopen是无法使用代理的IP的,我就来分享一下Python爬虫怎样使用代理IP的经验。(推荐飞猪代理IP注册可免费使用,浏览器搜索可找到)

1、划重点,小编我用的是Python3哦,所以要导入urllib的request,然后我们调用ProxyHandler,它可以接收代理IP的参数。代理可以根据自己需要选择,当然免费的也是有的,但是可用率可想而知的。(飞猪IP)
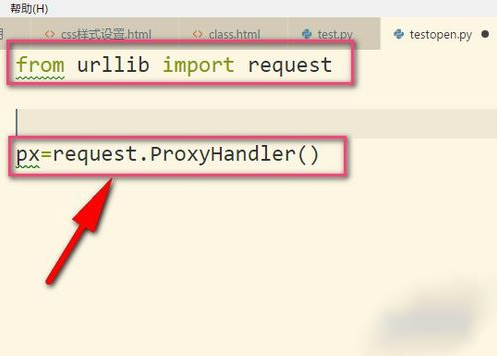
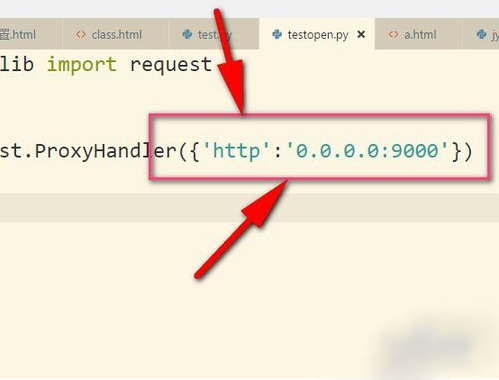
2、接着把IP地址以字典的形式放入其中,这个IP地址是我乱写的,只是用来举例。设置键为http,当然有些是https的,然后后面就是IP地址以及端口号(9000),具体看你的IP地址是什么类型的,不同IP端口号可能不同根据你在飞猪提取的端口为准。
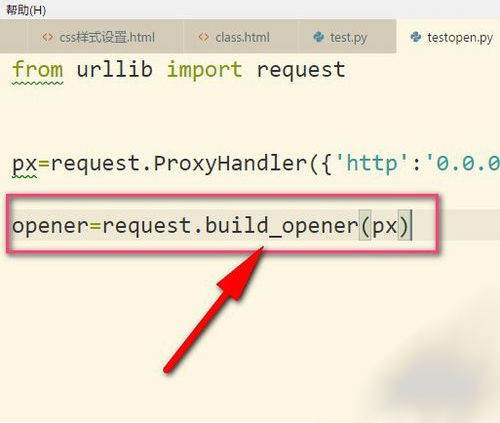
3、接着再用build_opener()来构建一个opener对象。
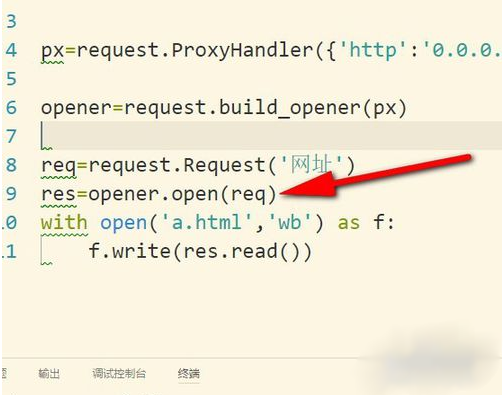
4、然后调用构建好的opener对象里面的open方法来发生请求。实际上urlopen也是类似这样使用内部定义好的opener.open(),这里就相当于我们自己重写。
5、当然了,如果我们使用install_opener(),就可以把之前自定义的opener设置成全局的。
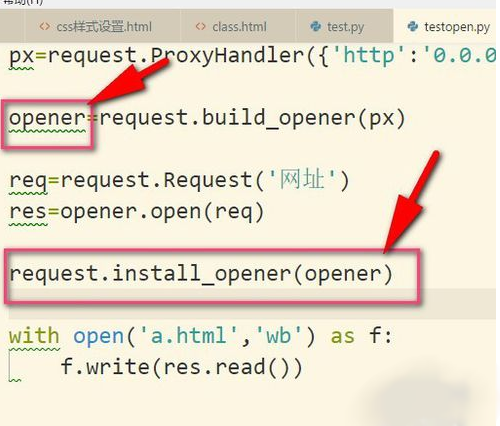
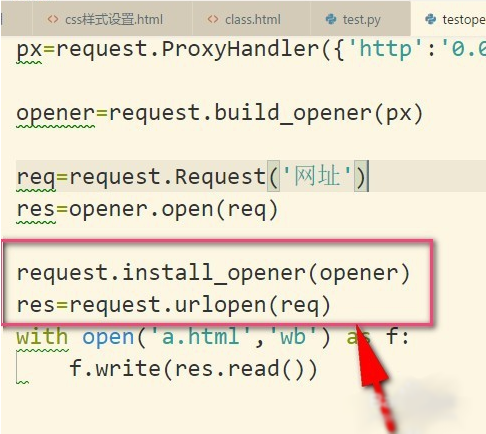
6、设置成全局之后,如果我们再使用urlopen来发送请求,那么发送请求使用的IP地址就是代理IP,而不是本机的IP地址了。
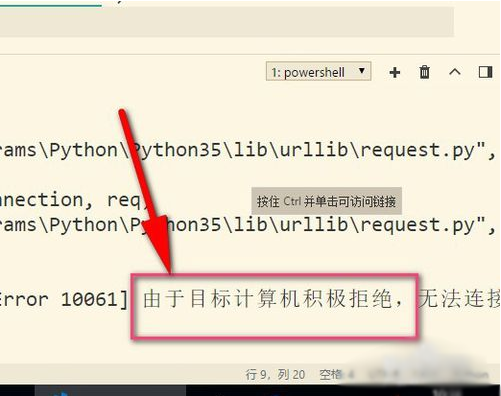
7、最后再来说说使用代理遇到的错误,提示目标计算机积极拒绝,这就说明可能是代理IP无效,或者端口号错误,这就需要使用有效的IP才行哦。(这边现在是乱填写的IP地址)可选择飞猪的代理IP。
总结:以上就是本次关于Python数据抓取爬虫代理防封IP方法,感谢大家的阅读和对我们的支持。
相关推荐
-

通过抓取淘宝评论为例讲解Python爬取ajax动态生成的数据(经典)
在学习python的时候,一定会遇到网站内容是通过 ajax动态请求.异步刷新生成的json数据 的情况,并且通过python使用之前爬取静态网页内容的方式是不可以实现的,所以这篇文章将要讲述如果在python中爬取ajax动态生成的数据. 至于读取静态网页内容的方式,有兴趣的可以查看本文内容. 这里我们以爬取淘宝评论为例子讲解一下如何去做到的. 这里主要分为了四步: 一 获取淘宝评论时,ajax请求链接(url) 二 获取该ajax请求返回的json数据 三 使用python解析json数据
-
python+mongodb数据抓取详细介绍
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: headers = { ..... } r = requests.get(url,headers,timeout=30) html = r.content soup = BeautifulSoup(html,"lxml") url = soup.find_all(正则表达式) for i
-
Python实现并行抓取整站40万条房价数据(可更换抓取城市)
写在前面 这次的爬虫是关于房价信息的抓取,目的在于练习10万以上的数据处理及整站式抓取. 数据量的提升最直观的感觉便是对函数逻辑要求的提高,针对Python的特性,谨慎的选择数据结构.以往小数据量的抓取,即使函数逻辑部分重复,I/O请求频率密集,循环套嵌过深,也不过是1~2s的差别,而随着数据规模的提高,这1~2s的差别就有可能扩展成为1~2h. 因此对于要抓取数据量较多的网站,可以从两方面着手降低抓取信息的时间成本. 1)优化函数逻辑,选择适当的数据结构,符合Pythonic的编程习惯.例如,
-
对python抓取需要登录网站数据的方法详解
scrapy.FormRequest login.py class LoginSpider(scrapy.Spider): name = 'login_spider' start_urls = ['http://www.login.com'] def parse(self, response): return [ scrapy.FormRequest.from_response( response, # username和password要根据实际页面的表单的name字段进行修改 formdat
-
Python学习笔记之抓取某只基金历史净值数据实战案例
本文实例讲述了Python抓取某只基金历史净值数据.分享给大家供大家参考,具体如下: http://fund.eastmoney.com/f10/jjjz_519961.html 1.接下来,我们需要动手把这些html抓取下来(这部分知识我们之前已经学过,现在不妨重温) # coding: utf-8 from selenium.webdriver.support.ui import WebDriverWait from selenium import webdriver from bs4 im
-
python抓取某汽车网数据解析html存入excel示例
1.某汽车网站地址 2.使用firefox查看后发现,此网站的信息未使用json数据,而是简单那的html页面而已 3.使用pyquery库中的PyQuery进行html的解析 页面样式: 复制代码 代码如下: def get_dealer_info(self): """获取经销商信息""" css_select = 'html body div.box div.news_wrapper div.main div.ne
-
Python基于多线程实现抓取数据存入数据库的方法
本文实例讲述了Python基于多线程实现抓取数据存入数据库的方法.分享给大家供大家参考,具体如下: 1. 数据库类 """ 使用须知: 代码中数据表名 aces ,需要更改该数据表名称的注意更改 """ import pymysql class Database(): # 设置本地数据库用户名和密码 host = "localhost" user = "root" password = "&quo
-
使用Python抓取豆瓣影评数据的方法
抓取豆瓣影评评分 正常的抓取 分析请求的url https://movie.douban.com/subject/26322642/comments?start=20&limit=20&sort=new_score&status=P&percent_type= 里面有用的也就是start和limit参数,我尝试过修改limit参数,但是没有效果,可以认为是默认的 start参数是用来设置从第几条数据开始查询的 设计查询列表,发现页面中有url中的查询部分,且指向下一个页面
-
Python抓取京东图书评论数据
京东图书评论有非常丰富的信息,这里面就包含了购买日期.书名.作者.好评.中评.差评等等.以购买日期为例,使用Python + Mysql的搭配进行实现,程序不大,才100行.相关的解释我都在程序里加注了: from selenium import webdriver from bs4 import BeautifulSoup import re import win32com.client import threading,time import MySQLdb def mydebug():
-
python采用requests库模拟登录和抓取数据的简单示例
如果你还在为python的各种urllib和urlibs,cookielib 头疼,或者还还在为python模拟登录和抓取数据而抓狂,那么来看看我们推荐的requests,python采集数据模拟登录必备利器! 这也是python推荐的HTTP客户端库: 本文就以一个模拟登录的例子来加以说明,至于采集大家就请自行发挥吧. 代码很简单,主要是展现python的requests库的简单至极,代码如下: s = requests.session() data = {'user':'用户名','pass