Python提取频域特征知识点浅析
在多数的现代语音识别系统中,人们都会用到频域特征。梅尔频率倒谱系数(MFCC),首先计算信号的功率谱,然后用滤波器和离散余弦变换的变换来提取特征。本文重点介绍如何提取MFCC特征。
首先创建有一个Python文件,并导入库文件: from scipy.io import wavfile from python_speech_features import mfcc, logfbank import matplotlib.pylab as plt1、首先创建有一个Python文件,并导入库文件: from scipy.io import wavfile from python_speech_features import mfcc, logfbank import matplotlib.pylab as plt
读取音频文件:
samplimg_freq, audio = wavfile.read("data/input_freq.wav")
提取MFCC特征和过滤器特征:
mfcc_features = mfcc(audio, samplimg_freq)
filterbank_features = logfbank(audio, samplimg_freq)


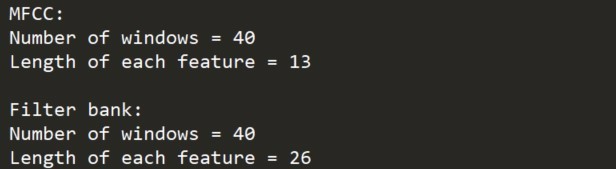
打印参数,查看可生成多少个窗体:
print('\nMFCC:\nNumber of windows =', mfcc_features.shape[0])
print('Length of each feature =', mfcc_features.shape[1])
print('\nFilter bank:\nNumber of windows=', filterbank_features.shape [0])
print('Length of each feature =', filterbank_features.shape[1])
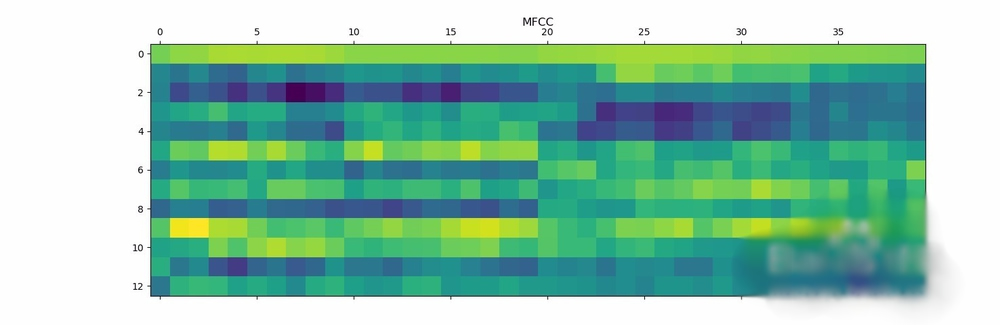
将MFCC特征可视化。转换矩阵,使得时域是水平的:
mfcc_features = mfcc_features.T
plt.matshow(mfcc_features)
plt.title('MFCC')
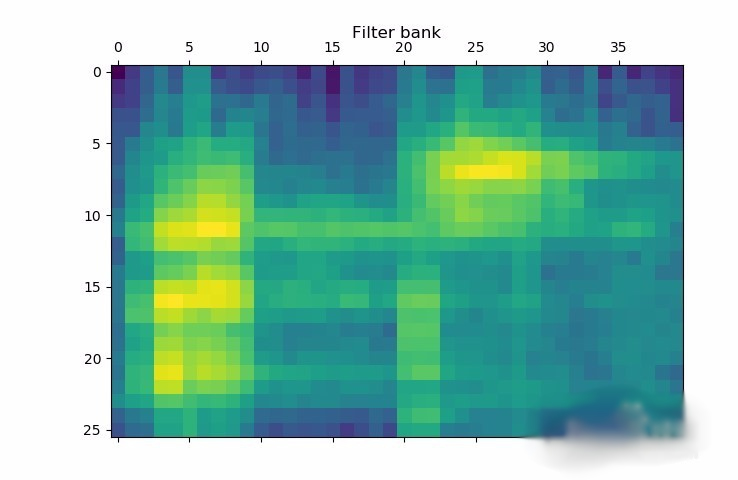
将滤波器组特征可视化。转化矩阵,使得时域是水平的:
filterbank_features = filterbank_features.T
plt.matshow(filterbank_features)
plt.title('Filter bank')
plt.show()
相关推荐
-
python多进程读图提取特征存npy
本文实例为大家分享了python多进程读图提取特征存npy的具体代码,供大家参考,具体内容如下 import multiprocessing import os, time, random import numpy as np import cv2 import os import sys from time import ctime import tensorflow as tf image_dir = r"D:/sxl/处理图片/汉字分类/train10/" #图像文件夹路径 da
-
使用python进行文本预处理和提取特征的实例
如下所示: <strong><span style="font-size:14px;">文本过滤</span></strong> result = re.sub(r'[^\u4e00-\u9fa5,.?!,.::" "' '( )< >〈 〉]', "", content)#只保留中文和标点 result = re.sub(r'[^\u4e00-\u9fa5]', ""
-
Python实现的特征提取操作示例
本文实例讲述了Python实现的特征提取操作.分享给大家供大家参考,具体如下: # -*- coding: utf-8 -*- """ Created on Mon Aug 21 10:57:29 2017 @author: 飘的心 """ #过滤式特征选择 #根据方差进行选择,方差越小,代表该属性识别能力很差,可以剔除 from sklearn.feature_selection import VarianceThreshold x=[[100
-
使用python实现语音文件的特征提取方法
概述 语音识别是当前人工智能的比较热门的方向,技术也比较成熟,各大公司也相继推出了各自的语音助手机器人,如百度的小度机器人.阿里的天猫精灵等.语音识别算法当前主要是由RNN.LSTM.DNN-HMM等机器学习和深度学习技术做支撑.但训练这些模型的第一步就是将音频文件数据化,提取当中的语音特征. MP3文件转化为WAV文件 录制音频文件的软件大多数都是以mp3格式输出的,但mp3格式文件对语音的压缩比例较重,因此首先利用ffmpeg将转化为wav原始文件有利于语音特征的提取.其转化代码如下: fr
-
python利用小波分析进行特征提取的实例
如下所示: #利用小波分析进行特征分析 #参数初始化 inputfile= 'C:/Users/Administrator/Desktop/demo/data/leleccum.mat' #提取自Matlab的信号文件 from scipy.io import loadmat #mat是MATLAB专用格式,需要用loadmat读取它 mat = loadmat(inputfile) signal = mat['leleccum'][0] import pywt #导入PyWavelets co
-

python实现图片处理和特征提取详解
这是一张灵异事件图...开个玩笑,这就是一张普通的图片. 毫无疑问,上面的那副图画看起来像一幅电脑背景图片.这些都归功于我的妹妹,她能够将一些看上去奇怪的东西变得十分吸引眼球.然而,我们生活在数字图片的年代,我们也很少去想这些图片是在怎么存储在存储器上的或者去想这些图片是如何通过各种变化生成的. 在这篇文章中,我将带着你了解一些基本的图片特征处理.data massaging 依然是一样的:特征提取,但是这里我们还需要对跟多的密集数据进行处理,但同时数据清理是在数据库.表.文本等中进行.这是如何
-
Python提取频域特征知识点浅析
在多数的现代语音识别系统中,人们都会用到频域特征.梅尔频率倒谱系数(MFCC),首先计算信号的功率谱,然后用滤波器和离散余弦变换的变换来提取特征.本文重点介绍如何提取MFCC特征. 首先创建有一个Python文件,并导入库文件: from scipy.io import wavfile from python_speech_features import mfcc, logfbank import matplotlib.pylab as plt1.首先创建有一个Pytho
-
python中count函数知识点浅析
python中,count函数的作用是进行python中的数量计算.count函数用于统计字符串.列表或元祖中某个字符出现的次数,是一个很好用的统计函数.具体介绍请看本文. 1.count函数 统计列表ls中value元素出现的次数 2.语法 str.count("char", start,end) 或 str.count("char") -> int 返回整数 3.参数 str -- 为要统计的字符(可以是单字符,也可以是多字符). star -- 为索引字
-
Python中提取人脸特征的三种方法详解
目录 1.直接使用dlib 2.使用深度学习方法查找人脸,dlib提取特征 3.使用insightface提取人脸特征 安装InsightFace 提取特征 1.直接使用dlib 安装dlib方法: Win10安装dlib GPU过程详解 思路: 1.使用dlib.get_frontal_face_detector()方法检测人脸的位置. 2.使用 dlib.shape_predictor()方法得到人脸的关键点. 3.使用dlib.face_recognition_model_v1()方法提取
-
关于Python面向对象编程的知识点总结
前言 如果你以前没有接触过面向对象的编程语言,那你可能需要先了解一些面向对象语言的一些基本特征,在头脑里头形成一个基本的面向对象的概念,这样有助于你更容易的学习Python的面向对象编程. 接下来我们就来了解关于Python面向对象编程的知识点吧. 类与实例 类是对象的定义,而实例是"真正的实物",它存放了类中所定义的对象的具体信息. 类.属性和方法命名规范 类名通常由大写字母打头.这是标准惯例,可以帮助你识别类,特别是在实例化过程中(有时看起来像函数调用).还有,数据属性(变量或常量
-
python urllib和urllib3知识点总结
在python数据请求中,我们有一个标准库专门处理这方面的问题,那就是urllib库.在不同的python版本中,urllib也有着版本上的变化.本篇就urllib和urllib3这两种库为大家带来介绍,分析其基本的用法.不同点.使用注意和实例,希望能对大家在数据请求的学习有所帮助. 1.说明 在可供使用的网络库中,urllib和urllib3可能是投入产出比最高的两个.它们能让你通过网络访问文件,就像这些文件位于你的计算机中一样.只需一个简单的函数调用,就几乎可将统一资源定位符(URL)可指向
-
Python提取PDF指定内容并生成新文件
在之前的Python办公自动化案专题中,我们已经介绍了如何有选择的提取某些页面进行合并. 但是很多时候,我们并不会预知希望提取的页号,而是希望将包含指定内容的页面提取合并为新PDF,本文就以两个真实需求为例进行讲解. 01需求描述 数据是一份有286页的上市公司公开年报PDF,大致如下 现在需要利用 Python 完成以下两个需求 " 需求一:提取所有包含 战略 二字的页面并合并新PDF 需求二:提取所有包含图片的页面,并分别保存为 PDF 文件 " 02前置知识和逻辑梳理 2.1 P
-
教你使用Python提取视频中的美女图片
目录 前言 安装模块 you-get OpenCV 结束 前言 人类都是视觉动物,不管是男生还是女生看到漂亮的小姐姐.小哥哥就想截图保存下来.可是截图会对画质会产生损耗,截取的 画面不规整,像素不高等问题. 用 Python 写一个逐帧无损保存视频画面的小脚本大致可以分为三个步骤: 1.在 cmd 中使用 you-get 下载视频 2.OpenCV 读取并处理视频 3.将视频画面保存为图片 安装模块 1.you-get 模块用于下载视频,它需要 ffmpeg 模块配合使用. pip3 insta
-
python文件操作相关知识点总结整理
本文汇总了python文件操作相关知识点.分享给大家供大家参考,具体如下: 总是记不住API.昨晚写的时候用到了这些,但是没记住,于是就索性整理一下吧: python中对文件.文件夹(文件操作函数)的操作需要涉及到os模块和shutil模块. 得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd() 返回指定目录下的所有文件和目录名:os.listdir() 函数用来删除一个文件:os.remove() 删除多个目录:os.removedirs(r"c:\python&q
-
python提取字典key列表的方法
本文实例讲述了python提取字典key列表的方法.分享给大家供大家参考.具体如下: 这段代码可以把字典的所有key输出为一个数组 d2 = {'spam': 2, 'ham': 1, 'eggs': 3} # make a dictionary print d2 # order is scrambled print d2.keys() # create a new list of my keys 希望本文所述对大家的Python程序设计有所帮助.
-
python遍历序列enumerate函数浅析
enumerate函数用于遍历序列中的元素以及它们的下标. enumerate函数说明: 函数原型:enumerate(sequence, [start=0]) 功能:将可循环序列sequence以start开始分别列出序列数据和数据下标 即对一个可遍历的数据对象(如列表.元组或字符串),enumerate会将该数据对象组合为一个索引序列,同时列出数据和数据下标. 举例说明: 存在一个sequence,对其使用enumerate将会得到如下结果: start sequence[0]