详解Python数据可视化编程 - 词云生成并保存(jieba+WordCloud)
思维导图:
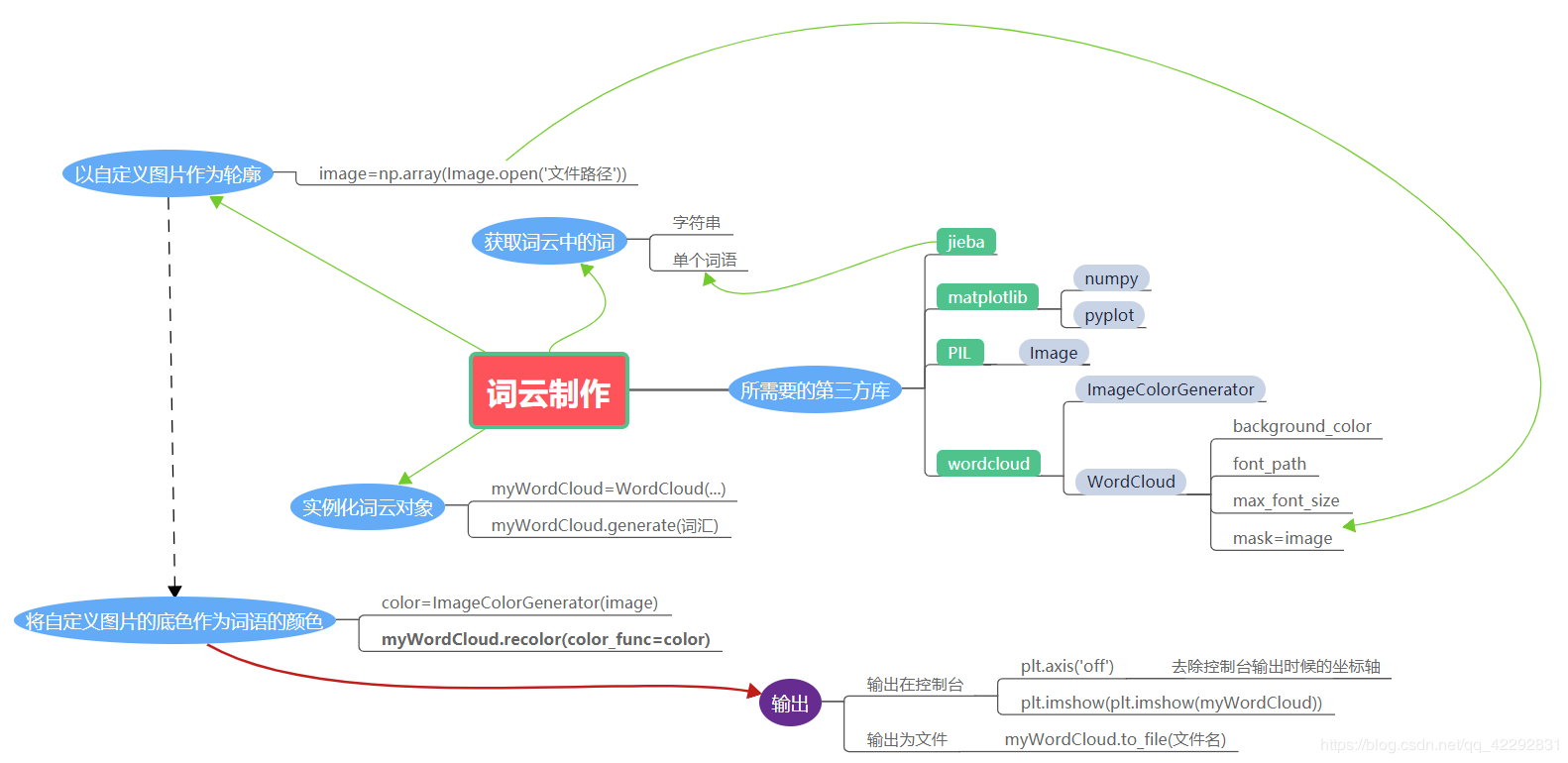
效果(语句版):

源码:
# -*- coding: utf-8 -*-
"""
Created on Tue Mar 5 17:59:29 2019
@author: dell
"""
# =============================================================================
# 步骤:
# 分割aaa = jieba.cut(str,cut_all=True/False)
# 连接bbb = " ".join(aaa)
# 制作xxx = WordCloud(background_color,font_path).generate(bbb) #bbb为字符串
# 显示plt.imshow(xxx) #不能用plt.show()
# 取消坐标轴的显示Matplotlib.pyplot.axis("off")
# 存为图片xxx.to_file(path)
# =============================================================================
from wordcloud import WordCloud
from matplotlib import pyplot as plt
import jieba
with open("pythonTest.txt",encoding="utf-8") as f:
text = f.read()
#textFromFile = open("pythonTest",encoding = "UTF-8").read()
word_list = jieba.cut("ABVDEFG",cut_all=True) #切成了一个个的字符串
xxx = " ".join(word_list) #"分隔符".join(需要被连接的数据) 将内容连接为字符串
myWordCloud = WordCloud(background_color="white",font_path='C:\windows\Fonts\STZHONGS.TTF').generate(text)
#myWordCloud = WordCloud(background_color="white",width=1000,height=860,font_path='C:\windows\Fonts\STZHONGS.TTF').generate(text)
plt.axis("off")
#plt.show(myWordCloud) #没有实际显示,只有背景!!!
plt.imshow(myWordCloud)
myWordCloud.to_file("词云图片.jpg") #保存为图片
注意事项:
<一> jieba分词
- 分词后的返回值类型
- 分词后的返回值
- 如何去除所要分离文本的中英文符号,还有空格符
import jieba
wordList = jieba.cut("机器学习,算法对新鲜样本!的适应能力:叫泛化能力",cut_all=False)
print(type(wordList)) #类型是一个生成器generator
print(wordList) #本身是一个生成器对象generator Object
for list in wordList:
if list in ",./;'[]~!@#$%^&*()_+,。、;‘ 【】~!@#¥%……&*()——+《 》?:“{}<>?:\n\r":
None
else:
print(list)
<二> 对词图进行重新上色的注意事项
- recolor(color_func=color) 正确
- recolor(color) 错误
<三> 读取图片时候的注意事项
a = np.array(Image.open(路径))
<四> python中文件路径注意事项
- 使用 \\
- 使用 /
<五> Spyder中的注释快捷键
- 单行注释:Ctrl+1
- 块注释:Ctrl+4
以上所述是小编给大家介绍的Python数据可视化编程 - 词云生成并保存(jieba+WordCloud)详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

python生成词云的实现方法(推荐)
期末复习比较忙过段时间来专门写scrapy框架使用,今天介绍如何用python生成词云,虽然网上有很多词云生成工具,不过自己用python来写是不是更有成就感. 今天要生成的是励志歌曲的词云,百度文库里面找了20来首,如<倔强>,海阔天空是,什么的大家熟悉的. 所要用到的python库有 jieba(一个中文分词库).wordcould .matplotlib.PIL.numpy. 首先我们要做的是读取歌词.我将歌词存在了文件目录下励志歌曲文本中. 现在来读取他 #encoding=gbk l
-
用Python和WordCloud绘制词云的实现方法(内附让字体清晰的秘笈)
环境及模块: Win7 64位 Python 3.6.4 WordCloud 1.5.0 Pillow 5.0.0 Jieba 0.39 目标: 绘制安徽省2018年某些科技项目的词云,直观展示热点. 思路: 先提取项目的名称,再用Jieba分词后提取词汇:过滤掉"研发"."系列"等无意义的词:最后用WordCloud 绘制词云. 扩展: 词云默认是矩形的,本代码采用图片作为蒙版,产生异形词云图.这里用的图片是安徽省地图. 秘笈: 用网上的常规方法绘制的词云,字体有
-
用python结合jieba和wordcloud实现词云效果
0x00 前言 突然想做一个漏洞词云,看看哪些漏洞比较高频,如果某些厂商有漏洞公开(比如ly),也好针对性挖掘.就选x云吧(镜像站 http://wy.hxsec.com/bugs.php ).用jieba和wordcloud两个强大的第三方库,就可以轻松打造出x云漏洞词云. github地址: https://github.com/theLSA/wooyun_wordcloud 本站下载地址:wooyun_wordcloud 0x01 爬取标题 直接上代码: #coding:utf-8 #Au
-
详解Python数据可视化编程 - 词云生成并保存(jieba+WordCloud)
思维导图: 效果(语句版): 源码: # -*- coding: utf-8 -*- """ Created on Tue Mar 5 17:59:29 2019 @author: dell """ # ============================================================================= # 步骤: # 分割aaa = jieba.cut(str,cut_all=True/Fa
-
详解python实现可视化的MD5、sha256哈希加密小工具
本文主要介绍了详解python实现可视化的MD5.sha256哈希加密小工具,分享给大家,具体如下: 效果图: 刚启动的状态 输入文本.触发加密按钮后支持复制 超过十条不全量显示 代码 import hashlib import tkinter as tk #窗口控制 windowss=tk.Tk() windowss.title('Python_md5')#窗口title,并非第一行 windowss.geometry('820x550') windowss.resizable(width=T
-
python数据可视化自制职位分析生成岗位分析数据报表
目录 前言 1. 核心功能设计 可视化展示岗位表格数据 分析岗位薪资情况 分析岗位公司情况 数据分析导出 2. GUI设计与实现 3. 功能实现 3.1 职位数据爬虫 3.2 数据预处理 3.3 岗位数据展示 3.4 薪资图表可视化 3.5 岗位公司情况统计 3.6 预览保存 前言 为什么要进行职位分析?职位分析是人力资源开发和管理的基础与核心,是企业人力资源规划.招聘.培训.薪酬制定.绩效评估.考核激励等各项人力资源管理工作的依据.其次我们可以根据不同岗位的职位分析,可视化展示各岗位的数据分析
-
详解Python基础random模块随机数的生成
随机数参与的应用场景大家一定不会陌生,比如密码加盐时会在原密码上关联一串随机数,蒙特卡洛算法会通过随机数采样等等.Python内置的random模块提供了生成随机数的方法,使用这些方法时需要导入random模块. import random 下面介绍下Python内置的random模块的几种生成随机数的方法. 1.random.random() 随机生成 0 到 1 之间的浮点数[0.0, 1.0) . print("random: ", random.random()) #rando
-
详解Python Socket网络编程
Socket 是进程间通信的一种方式,它与其他进程间通信的一个主要不同是:它能实现不同主机间的进程间通信,我们网络上各种各样的服务大多都是基于 Socket 来完成通信的,例如我们每天浏览网页.QQ 聊天.收发 email 等等.要解决网络上两台主机之间的进程通信问题,首先要唯一标识该进程,在 TCP/IP 网络协议中,就是通过 (IP地址,协议,端口号) 三元组来标识进程的,解决了进程标识问题,就有了通信的基础了. 本文主要介绍使用Python 进行TCP Socket 网络编程,假设你已经具
-
详解python的网络编程基础
目录 一.什么是网络编程 二.socket 1.socket的基本语法 2.与socket有关的一些函数 服务端函数 客户端函数 公共函数 三.程序需求 服务端分析 客户端分析 四.代码升级 加上通信循环 加上连接循环以及完善 总结 一.什么是网络编程 网络编程涉及到一些计算机基础知识,还跟你的电脑系统有关,mac os/Linux和windows是不同的,由于我用的是windows,所以以下所有都是windows操作系统的适用的,并且里面的字符编码windows和mac os也是不同的,这里我
-
Python数据可视化编程通过Matplotlib创建散点图代码示例
Matplotlib简述: Matplotlib是一个用于创建出高质量图表的桌面绘图包(主要是2D方面).该项目是由JohnHunter于2002年启动的,其目的是为Python构建一个MATLAB式的绘图接口.如果结合PythonIDE使用比如PyCharm,matplotlib还具有诸如缩放和平移等交互功能.它不仅支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF.SVG.JPG.PNG.BMP.GIF等.此外,matp
-
详解python之异步编程
目录 一.异步编程概述 二.python的异步框架模型 三.顺序执行多个可重叠的任务 四.异步化同步代码 五.使用多线程克服具体任务的异步限制 总结 一.异步编程概述 异步编程是一种并发编程的模式,其关注点是通过调度不同任务之间的执行和等待时间,通过减少处理器的闲置时间来达到减少整个程序的执行时间:异步编程跟同步编程模型最大的不同就是其任务的切换,当遇到一个需要等待长时间执行的任务的时候,我们可以切换到其他的任务执行: 与多线程和多进程编程模型相比,异步编程只是在同一个线程之内的的任务调度,无法
-
Python数据可视化处理库PyEcharts柱状图,饼图,线性图,词云图常用实例详解
python可以在处理各种数据时,如果可以将这些数据,利用图表将其可视化,这样在分析处理起来,将更加直观.清晰,以下是 利用 PyEcharts 常用图表的可视化Demo, 开发环境 python3 柱状图 基本柱状图 from pyecharts import Bar # 基本柱状图 bar = Bar("基本柱状图", "副标题") bar.use_theme('dark') # 暗黑色主题 bar.add('真实成本', # label ["1月&q
-
Python数据可视化之Pyecharts使用详解
目录 1. 安装Pyecharts 2. 图表基础 2.1 主题风格 2.2 图表标题 2.3 图例 2.4 提示框 2.5 视觉映射 2.6 工具箱 2.7 区域缩放 3. 柱状图 Bar模块 4. 折线图/面积图 Line模块 4.1 折线图 4.2 面积图 5.饼形图 5.1 饼形图 5.2 南丁格尔玫瑰图 6. 箱线图 Boxplot模块 7. 涟漪特效散点图 EffectScatter模块 8. 词云图 WordCloud模块 9. 热力图 HeatMap模块 10. 水球图 Liqu