python实现基于朴素贝叶斯的垃圾分类算法
一、模型方法
本工程采用的模型方法为朴素贝叶斯分类算法,它的核心算法思想基于概率论。我们称之为“朴素”,是因为整个形式化过程只做最原始、最简单的假设。朴素贝叶斯是贝叶斯决策理论的一部分,所以讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论。假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示。
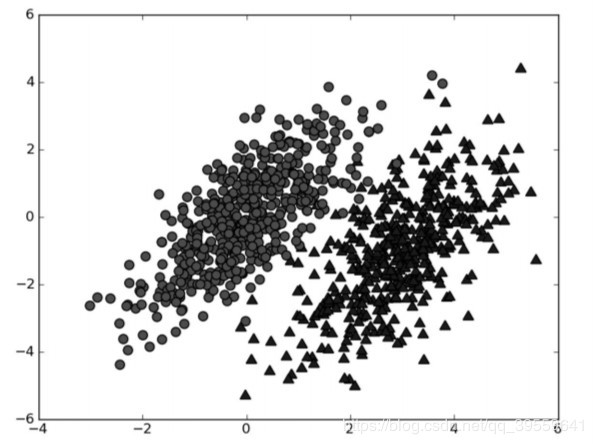
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中用圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中用三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
如果 p1(x,y) > p2(x,y),那么类别为1。
如果 p2(x,y) > p1(x,y),那么类别为2。
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
在本工程中我们可以使用条件概率来进行分类。其条件概率公式如下:
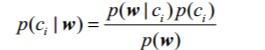
其中粗体w表示这是一个向量,它是有多个值组成。对于类别i表示分类的个数,在本工程中i=0时,c0表示非垃圾邮件。i=1时,c1表示垃圾邮件。w展开为一个个独立特征,那么就可以将上述概率写作p(w0,w1,w2..wN|ci)。这里假设所有词都互相独立,该假设也称作条件独立性假设,它意味着可以使用p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)来计算上述概率,这就极大地简化了计算的过程,这也是被称为朴素贝叶斯的原因。在本工程中wj代表第i个单词特征,而p(wj|ci)则代表了在垃圾邮件(或非垃圾邮件)中,第j个单词出现的概率;而p(w|ci)则表示在垃圾邮件(或非垃圾邮件)中的全体向量特征(单词向量特征)出现的概率;而p(ci| w)则表示在全体向量特征(单词向量特征)下是垃圾邮件(或非垃圾邮件)的概率。本工程项目主要是计算p(ci|w);p(ci)则表示是垃圾邮件(或非垃圾邮件)的概率。
二、系统设计

数据的收集及保存
邮件的收集来源于网上,保存在email文件夹中。其中email分两个子文件,一个为ham文件夹(保存非垃圾邮件),另一个为spam文件夹(保存垃圾邮件)。ham与spam中各保存25各邮件,保存格式为x.txt(x为1到25)。
训练集和测试集的选取
由于收集的邮件个数有限,故选取80%的邮件作为训练集,其方式为随机选取。剩余20%邮件作为测试集。
特征向量构建
特征向量的构建分为两种,一个为对训练集的特征向量构建。一个为测试集的特征向量构建。对于训练集特征向量只需要分为两类,因为邮件只分为垃圾邮件和非垃圾邮件。特征向量分为对训练集中所有垃圾邮件中构成的特征向量(记做w)和训练集中所有非垃圾邮件构成特征向量(记做w')。对于w的计算实际就是统计所有训练集中垃圾邮件中的每个单词的出现情况,出现则次数加1。其计数初值为1,按照正常情况应为0,因为用的朴素贝叶斯算法,假设所有词都互相独立 ,就有p(w|ci) = p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)。所以当第i个单词wi在其特征向量中没有出现,则有p(wi|ci) =0,这就导致了p(w|ci)导致结果的不正确性。所以我们索性将所有单词默认出现1遍,所以从1开始计数。对于w'的计算和w的计算方法相同,这里就不在赘述。
对于测试集的特征向量构建就是对每个邮件中单词出现的次数进行统计,其单词表可以来源于50个邮件中的所有单词。对于每一个邮件中单词如果出现就加1,其计数初值为0。每个测试集的邮件都需构建特征向量。其特征向量在python中可用列表表示。
构建贝叶斯分类器
对于分类器的训练其目的训练三个参数为p1Vect(w中每个单词出现的概率构成的特征向量)、p0Vect(w'中每个单词出现的概率构成的特征向量)和pAbusive(训练集中垃圾邮件的概率)。对于p1Vect、p0Vect计算可能会造成下溢出,这 是 由 于 太 多 很 小 的 数 相 乘 造 成 的 。 当 计 算 乘 积p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)时,由于大部分因子都非常小,所以程序会下溢出或者得到不正确的答案。一种解决办法是对乘积取自然对数。在代数中有ln(a*b) = ln(a)+ln(b),于是通过求对数可以避免下溢出或者浮点数舍入导致的错误。同时,采用自然对数进行处理不会有任何损失。图1给出函数f(x)与ln(f(x))的曲线。检查这两条曲线,就会发现它们在相同区域内同时增加或者减少,并且在相同点上取到极值。它们的取值虽然不同,但不影响最终结果。
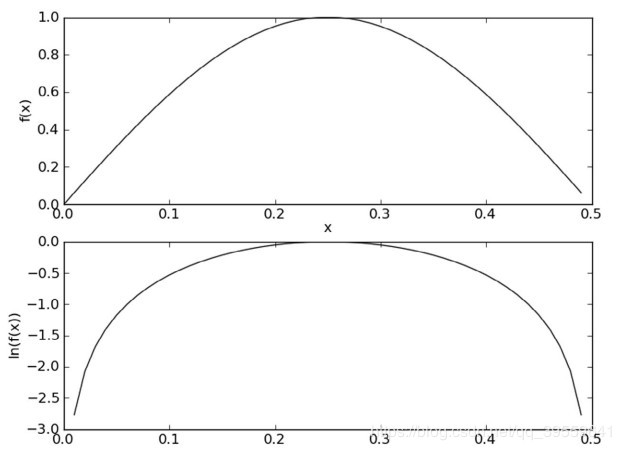
所以p1Vect = log(w/p1Denom),p0Vect = log(w'/p0Denom),其中p1Denom、p0Denom分别为垃圾邮件中单词的总数和非垃圾邮件中单词的总数。而pAbusive 就等于训练集中垃圾邮件总数与训练集中邮件总数之比。
测试集验证与评估
对于判断是否为垃圾邮件,只需对每个邮件判断p(c0|w)(不是垃圾邮件的概率)与p(c1|w)(是垃圾邮件的概率)。
q如果p(c0|w) > p(c1|w),那么该邮件为非垃圾邮件。
q如果 p(c0|w) < p(c1|w),那么该邮件为垃圾邮件。
然而p(ci|w)(i=0或1)的计算则依赖于p(w|ci)与p(ci)的计算,p(w)无需计算。所以最终结果依赖于pi = p(w|ci)·p(ci)。由于p(w|ci)很小,可能向下溢出。所以我们取以10为底的对数得log(pi) = log(p(w|ci))+log(p(ci)),所以可得以下结论:
q如果log(p0) > log(p1),那么该邮件为非垃圾邮件。
q如果log(p0) < log(p1),那么该邮件为垃圾邮件。
其中p(w|ci)为在垃圾邮件(或非垃圾邮件)中的全体向量特征(单词向量特征)出现的概率,p(ci)为训练集中垃圾邮件(或非垃圾邮件)的概率。
三、系统演示与实验结果分析对比
由训练集(40个)和测试集(个)的样本数目比较小,所以测试的分类结果正确性为90%-100%之间,如下图所示:


本工程只是对邮件进行二分类,贝叶斯算法也可以处理多分类问题,如新闻的分类,如分成军事、体育、科技等等。当然本工程只是对英文的垃圾邮件分类,但也可以对中文的垃圾邮件分类(可用python中的jieba的库模块进行对中文分词)。
四、代码实现
#coding=UTF-8
import random
from numpy import *
#解析英文文本,并返回列表
def textParse(bigString):
#将单词以空格划分
listOfTokens = bigString.split()
#去除单词长度小于2的无用单词
return [tok.lower() for tok in listOfTokens if len(tok)>2]
#去列表中重复元素,并以列表形式返回
def createVocaList(dataSet):
vocabSet = set({})
#去重复元素,取并集
for document in dataSet:
vocabSet = vocabSet | set(document)
return list(vocabSet)
#统计每一文档(或邮件)在单词表中出现的次数,并以列表形式返回
def setOfWordsToVec(vocabList,inputSet):
#创建0向量,其长度为单词量的总数
returnVec = [0]*len(vocabList)
#统计相应的词汇出现的数量
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
#朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix,trainCategory):
#获取训练文档数
numTrainDocs = len(trainMatrix)
#获取每一行词汇的数量
numWords = len(trainMatrix[0])
#侮辱性概率(计算p(Ci)),计算垃圾邮件的比率
pAbusive = sum(trainCategory)/float(numTrainDocs)
#统计非垃圾邮件中各单词在词数列表中出现的总数(向量形式)
p0Num = ones(numWords)
#统计垃圾邮件中各单词在词数列表中出现的总数(向量形式)
p1Num = ones(numWords)
#统计非垃圾邮件总单词的总数(数值形式)
p0Denom = 2.0
#统计垃圾邮件总单词的总数(数值形式)
p1Denom = 2.0
for i in range(numTrainDocs):
#如果是垃圾邮件
if trainCategory[i] == 1:
p1Num += trainMatrix[i]
p1Denom +=sum(trainMatrix[i])
#如果是非垃圾邮件
else:
p0Num += trainMatrix[i]
p0Denom +=sum(trainMatrix[i])
#计算每个单词在垃圾邮件出现的概率(向量形式)
p1Vect = log(p1Num/p1Denom)
#计算每个单词在非垃圾邮件出现的概率(向量形式)
p0Vect = log(p0Num/p0Denom)
return p0Vect,p1Vect,pAbusive
#朴素贝叶斯分类函数
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):
p1 = sum(vec2Classify*p1Vec)+log(pClass1)
p0 = sum(vec2Classify*p0Vec)+log(1.0 - pClass1)
if p1 > p0:
return 1
else :
return 0
#test
def spamtest():
#导入并解析文本文件
docList =[];classList=[];fullText = []
for i in range(1,26):
#读取第i篇垃圾文件,并以列表形式返回
wordList = textParse(open('email/spam/{0}.txt'.format(i)).read())
#转化成二维列表
docList.append(wordList)
#一维列表进行追加
fullText.extend(wordList)
#标记文档为垃圾文档
classList.append(1)
#读取第i篇非垃圾文件,并以列表形式返回
wordList = textParse(open('email/ham/{0}.txt'.format(i)).read())
#转化成二维列表
docList.append(wordList)
#一维列表进行追加
fullText.extend(wordList)
#标记文档为非垃圾文档
classList.append(0)
#去除重复的单词元素
vocabList = createVocaList(docList)
#训练集,选40篇doc
trainingSet = [x for x in range(50)]
#测试集,选10篇doc
testSet = []
#选出10篇doc作测试集
for i in range(10):
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del trainingSet[randIndex]
trainMat = [];trainClasses=[]
#选出40篇doc作训练集
for docIndex in trainingSet:
trainMat.append(setOfWordsToVec(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat), array(trainClasses))
#对测试集分类
errorCount = 0
for docIndex in testSet:
wordVector = setOfWordsToVec(vocabList,docList[docIndex])
if classifyNB(array(wordVector), p0V, p1V, pSpam)!=classList[docIndex]:
errorCount+=1
print("错误率为:{0}".format(float(errorCount)/len(testSet)))
spamtest()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
使用Python做垃圾分类的原理及实例代码
0 引言 纸巾再湿也是干垃圾?瓜子皮再干也是湿垃圾??最近大家都被垃圾分类折磨的不行,傻傻的你是否拎得清?
-
Python实现的朴素贝叶斯分类器示例
本文实例讲述了Python实现的朴素贝叶斯分类器.分享给大家供大家参考,具体如下: 因工作中需要,自己写了一个朴素贝叶斯分类器. 对于未出现的属性,采取了拉普拉斯平滑,避免未出现的属性的概率为零导致整个条件概率都为零的情况出现. 朴素贝叶斯的基本原理网上很容易查到,这里不再叙述,直接附上代码 因工作中需要,自己写了一个朴素贝叶斯分类器.对于未出现的属性,采取了拉普拉斯平滑,避免未出现的属性的概率为零导致整个条件概率都为零的情况出现. class NBClassify(object): def _
-

python中如何使用朴素贝叶斯算法
这里再重复一下标题为什么是"使用"而不是"实现": 首先,专业人士提供的算法比我们自己写的算法无论是效率还是正确率上都要高. 其次,对于数学不好的人来说,为了实现算法而去研究一堆公式是很痛苦的事情. 再次,除非他人提供的算法满足不了自己的需求,否则没必要"重复造轮子". 下面言归正传,不了解贝叶斯算法的可以去查一下相关资料,这里只是简单介绍一下: 1.贝叶斯公式: P(A|B)=P(AB)/P(B) 2.贝叶斯推断: P(A|B)=P(A)×P(
-
Python编程之基于概率论的分类方法:朴素贝叶斯
概率论啊概率论,差不多忘完了. 基于概率论的分类方法:朴素贝叶斯 1. 概述 贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类.本章首先介绍贝叶斯分类算法的基础--贝叶斯定理.最后,我们通过实例来讨论贝叶斯分类的中最简单的一种: 朴素贝叶斯分类. 2. 贝叶斯理论 & 条件概率 2.1 贝叶斯理论 我们现在有一个数据集,它由两类数据组成,数据分布如下图所示: 我们现在用 p1(x,y) 表示数据点 (x,y) 属于类别 1(图中用圆点表示的类别)的概率,用 p2(
-
使用Python轻松完成垃圾分类(基于图像识别)
0 环境 Python版本:3.6.8 系统版本:macOS Mojave Python Jupyter Notebook 1 引言 七月了,大家最近一定被一项新的政策给折磨的焦头烂额,那就是垃圾分类.<上海市生活垃圾管理条例>已经正式实施了,相信还是有很多的小伙伴和我一样,还没有完全搞清楚哪些应该扔在哪个类别里.感觉每天都在学习一遍垃圾分类,真令人头大. 听说一杯没有喝完的珍珠奶茶应该这么扔 首先,没喝完的奶茶水要倒在水池里 珍珠,水果肉等残渣放进湿垃圾 把杯子要丢入干垃圾 接下来是盖子,如
-
python实现朴素贝叶斯分类器
本文用的是sciki-learn库的iris数据集进行测试.用的模型也是最简单的,就是用贝叶斯定理P(A|B) = P(B|A)*P(A)/P(B),计算每个类别在样本中概率(代码中是pLabel变量) 以及每个类下每个特征的概率(代码中是pNum变量). 写得比较粗糙,对于某个类下没有此特征的情况采用p=1/样本数量. 有什么错误有人发现麻烦提出,谢谢. [python] view plain copy # -*- coding:utf-8 -*- from numpy import * fr
-
朴素贝叶斯Python实例及解析
本文实例为大家分享了Python朴素贝叶斯实例代码,供大家参考,具体内容如下 #-*- coding: utf-8 -*- #添加中文注释 from numpy import * #过滤网站的恶意留言 #样本数据 def loadDataSet(): postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park'
-
Python实现的朴素贝叶斯算法经典示例【测试可用】
本文实例讲述了Python实现的朴素贝叶斯算法.分享给大家供大家参考,具体如下: 代码主要参考机器学习实战那本书,发现最近老外的书确实比中国人写的好,由浅入深,代码通俗易懂,不多说上代码: #encoding:utf-8 ''''' Created on 2015年9月6日 @author: ZHOUMEIXU204 朴素贝叶斯实现过程 ''' #在该算法中类标签为1和0,如果是多标签稍微改动代码既可 import numpy as np path=u"D:\\Users\\zhoumeixu2
-
朴素贝叶斯分类算法原理与Python实现与使用方法案例
本文实例讲述了朴素贝叶斯分类算法原理与Python实现与使用方法.分享给大家供大家参考,具体如下: 朴素贝叶斯分类算法 1.朴素贝叶斯分类算法原理 1.1.概述 贝叶斯分类算法是一大类分类算法的总称 贝叶斯分类算法以样本可能属于某类的概率来作为分类依据 朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一种 注:朴素的意思是条件概率独立性 P(A|x1x2x3x4)=p(A|x1)*p(A|x2)p(A|x3)p(A|x4)则为条件概率独立 P(xy|z)=p(xyz)/p(z)=p(xz)/p(z)
-
Python实现朴素贝叶斯分类器的方法详解
本文实例讲述了Python实现朴素贝叶斯分类器的方法.分享给大家供大家参考,具体如下: 贝叶斯定理 贝叶斯定理是通过对观测值概率分布的主观判断(即先验概率)进行修正的定理,在概率论中具有重要地位. 先验概率分布(边缘概率)是指基于主观判断而非样本分布的概率分布,后验概率(条件概率)是根据样本分布和未知参数的先验概率分布求得的条件概率分布. 贝叶斯公式: P(A∩B) = P(A)*P(B|A) = P(B)*P(A|B) 变形得: P(A|B)=P(B|A)*P(A)/P(B) 其中 P(A)是