使用Python检测文章抄袭及去重算法原理解析
在互联网出现之前,“抄”很不方便,一是“源”少,而是发布渠道少;而在互联网出现之后,“抄”变得很简单,铺天盖地的“源”源源不断,发布渠道也数不胜数,博客论坛甚至是自建网站,而爬虫还可以让“抄”完全自动化不费劲。这就导致了互联网上的“文章”重复性很高。这里的“文章”只新闻、博客等文字占据绝大部分内容的网页。

中文新闻网站的“转载”(其实就是抄)现象非常严重,这种“转载”几乎是全文照抄,或改下标题,或是改下编辑姓名,或是文字个别字修改。所以,对新闻网页的去重很有必要。
一、去重算法原理
文章去重(或叫网页去重)是根据文章(或网页)的文字内容来判断多个文章之间是否重复。这是爬虫爬取大量的文本行网页(新闻网页、博客网页等)后要进行的非常重要的一项操作,也是搜索引擎非常关心的一个问题。搜索引擎中抓取的网页是海量的,海量文本的去重算法也出现了很多,比如minihash, simhash等等。
在工程实践中,对simhash使用了很长一段时间,有些缺点,一是算法比较复杂、效率较差;二是准确率一般。
网上也流传着百度采用的一种方法,用文章最长句子的hash值作为文章的标识,hash相同的文章(网页)就认为其内容一样,是重复的文章(网页)。
这个所谓的“百度算法”对工程很友好,但是实际中还是会有很多问题。中文网页的一大特点就是“天下文章一大抄”,各种博文、新闻几乎一字不改或稍作修改就被网站发表了。这个特点,很适合这个“百度算法”。但是,实际中个别字的修改,会导致被转载的最长的那句话不一样,从而其hash值也不一样了,最终结果是,准确率很高,召回率较低。
为了解决这个问题,我提出了nshash(top-n longest sentences hash)算法,即:取文章的最长n句话(实践下来,n=5效果不错)分别做hash值,这n个hash值作为文章的指纹,就像是人的5个手指的指纹,每个指纹都可以唯一确认文章的唯一性。这是对“百度算法”的延伸,准确率还是很高,但是召回率大大提高,原先一个指纹来确定,现在有n个指纹来招回了。
二、算法实现
该算法的原理简单,实现起来也不难。比较复杂一点的是对于一篇文章(网页)返回一个similar_id,只要该ID相同则文章相似,通过groupby similar_id即可达到去重目的。
为了记录文章指纹和similar_id的关系,我们需要一个key-value数据库,本算法实现了内存和硬盘两种key-value数据库类来记录这种关系:
HashDBLeveldb 类:基于leveldb实现, 可用于海量文本的去重;
HashDBMemory 类:基于Python的dict实现,可用于中等数量(只要Python的dict不报内存错误)的文本去重。
这两个类都具有get()和put()两个方法,如果你想用Redis或MySQL等其它数据库来实现HashDB,可以参照这两个类的实现进行实现。

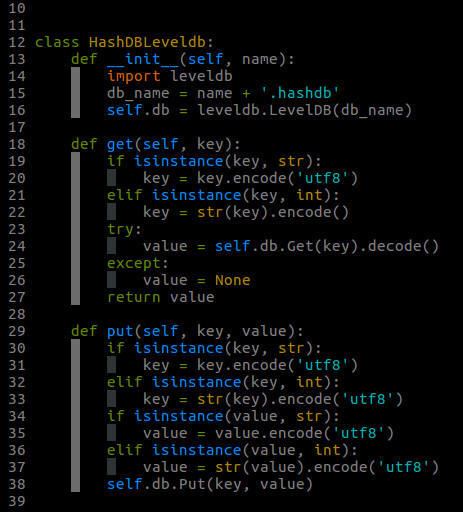
HashDBLeveldb类的实现

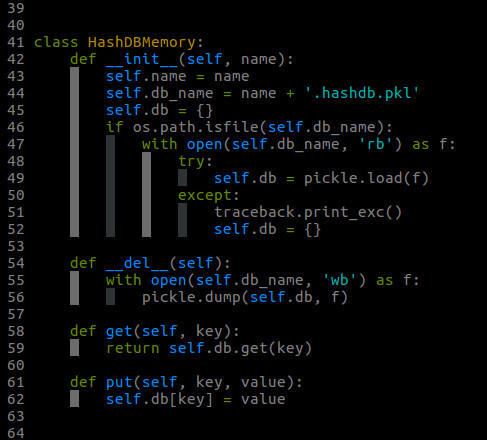
HashDBMemory类的实现
从效率上看,肯定是HashDBMemory速度更快。利用nshash对17400篇新闻网页内容的测试结果如下:
HashDBLeveldb: 耗时2.47秒; HashDBMemory: 耗时1.6秒;
具体测试代码请看 example/test.py。
有了这两个类,就可以实现nshash的核心算法了。
首先,对文本进行分句,以句号、感叹号、问号、换行符作为句子的结尾标识,一个正在表达式就可以分好句了。
其次,挑选最长的n句话,分别进行hash计算。hash函数可以用Python自带模块hashlib中的md5, sha等等,也可以用我在爬虫教程中多次提到的farmhash。
最后,我们需要根据这n个hash值给文本内容一个similar_id,通过上面两种HashDB的类的任意一种都可以比较容易实现。其原理就是,similar_id从0开始,从HashDB中查找这n个hash值是否有对应的similar_id,如果有就返回这个对应的similar_id;如果没有,就让当前similar_id加1作为这n个hash值对应的similar_id,将这种对应关系存入HashDB,并返回该similar_id即可。
这个算法实现为NSHash类:

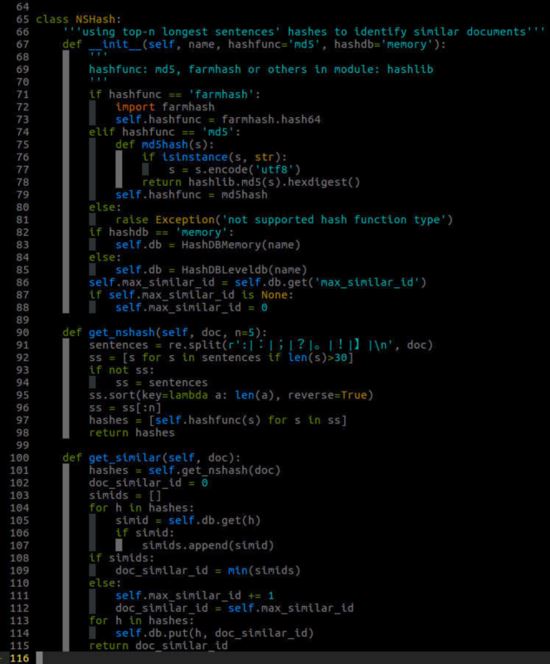
NSHash类的实现
三、使用方法
import nshash nsh = nshash.NSHash(name='test', hashfunc='farmhash', hashdb='memory') similar_id = nsh.get_similar(doc_text)
NSHash 类有三个参数:
- name : 用于hashdb保存到硬盘的文件名,如果hashdb是HashDBMemory, 则用pickle序列化到硬盘;如果是HashDBLeveldb,则leveldb目录名为:name+'.hashdb'。name按需随便起即可。
- hashfunc : 计算hash值的具体函数类别,目前实现两种类型: md5 和 farmhash 。默认是 md5 ,方便Windows上安装farmhash不方便。
- hashdb :默认是 memory 即选择HashDBMemory,否则是HashDBLeveldb。
至于如何利用similar_id进行海量文本的去重,这要结合你如何存储、索引这些海量文本。可参考 example/test.py 文件。这个test是对excel中保存的新闻网页进行去重的例子。
总结
以上所述是小编给大家介绍的使用Python检测文章抄袭及去重算法原理解析 ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python实现快速排序算法及去重的快速排序的简单示例
快速排序由于排序效率在同为O(N*logN)的几种排序方法中效率较高,因此经常被采用. 该方法的基本思想是: 1.先从数列中取出一个数作为基准数. 2.分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边. 3.再对左右区间重复第二步,直到各区间只有一个数. 现在通过一个实例来说明快排. 比如有一个数组: 6 2 4 5 3 第一步:选取一个基准数,不要被这个名词吓到了,你可以把它看作是一个比较大小的数,因为排序就是比较大小, 比如我选取最后一个数3为基准数,依次把数组的数和
-
python skimage 连通性区域检测方法
涉及到的函数为 import matplotlib.pyplot as plt from skimage import measure, color labels = measure.label(img4[:,:,0], connectivity=2) dst = color.label2rgb(labels) plt.imshow(dst) labels为整个灰度图像的坐标的类别标签,值为[0, max_label], 一个连通区域为一个 lable . 以上这篇python skimage
-
python检测文件夹变化,并拷贝有更新的文件到对应目录的方法
检测文件夹,拷贝有更新的文件到对应目录 2016.5.19 亲测可用,若有借鉴请修改下文件路径: 学习python小一个月后写的这个功能,属于初学,若有大神路过,求代码优化~ newcopy.py: 检测文件夹中最后修改时间变化的文件,并拷贝复制到相应路径下,拷贝目录会自动检测后输出:测试文件夹路径记得修改: pyinotify.py: 借用window接口,检测脚本所在目录下文件夹变化(更新.删除.添加等),输出日志到桌面上: # newcopy.py文件 # -*- coding:UTF-8
-
python开启摄像头以及深度学习实现目标检测方法
最近想做实时目标检测,需要用到python开启摄像头,我手上只有两个uvc免驱的摄像头,性能一般.利用python开启摄像头费了一番功夫,主要原因是我的摄像头都不能用cv2的VideCapture打开,这让我联想到原来opencv也打不开Android手机上的摄像头(后来采用QML的Camera模块实现的).看来opencv对于摄像头的兼容性仍然不是很完善. 我尝了几种办法:v4l2,v4l2_capture以及simpleCV,都打不开.最后采用pygame实现了摄像头的采集功能,这里直接给大
-

Python+OpenCV目标跟踪实现基本的运动检测
目标跟踪是对摄像头视频中的移动目标进行定位的过程,有着非常广泛的应用.实时目标跟踪是许多计算机视觉应用的重要任务,如监控.基于感知的用户界面.增强现实.基于对象的视频压缩以及辅助驾驶等. 有很多实现视频目标跟踪的方法,当跟踪所有移动目标时,帧之间的差异会变的有用:当跟踪视频中移动的手时,基于皮肤颜色的均值漂移方法是最好的解决方案:当知道跟踪对象的一方面时,模板匹配是不错的技术. 本文代码是做一个基本的运动检测 考虑的是"背景帧"与其它帧之间的差异 这种方法检测结果还是挺不错的,但是需要
-
使用Python检测文章抄袭及去重算法原理解析
在互联网出现之前,"抄"很不方便,一是"源"少,而是发布渠道少:而在互联网出现之后,"抄"变得很简单,铺天盖地的"源"源源不断,发布渠道也数不胜数,博客论坛甚至是自建网站,而爬虫还可以让"抄"完全自动化不费劲.这就导致了互联网上的"文章"重复性很高.这里的"文章"只新闻.博客等文字占据绝大部分内容的网页. 中文新闻网站的"转载"(其实就是抄)现象非
-
python实现CSF地面点滤波算法原理解析
目录 一.算法原理 二.读取las点云 三.算法源码 四.结果展示 五.CloudCompare实现 一.算法原理 布料模拟滤波处理流程: 1)利用点云滤波算法或者点云处理软件滤除异常点: 2)将激光雷达点云倒置: 3)设置模拟布料,设置布料网格分辨率 G R GR GR,确定模拟粒子数.布料的位置设置在点云最高点以上: 4)将布料模拟点和雷达点投影到水平面,为每个布料模拟点找到最相邻的激光点的高度值,将高度值设置为 I H V IHV IHV: 5)布料例子设置为可移动,布料粒子首先受到重力作
-
Python深度强化学习之DQN算法原理详解
目录 1 DQN算法简介 2 DQN算法原理 2.1 经验回放 2.2 目标网络 3 DQN算法伪代码 DQN算法是DeepMind团队提出的一种深度强化学习算法,在许多电动游戏中达到人类玩家甚至超越人类玩家的水准,本文就带领大家了解一下这个算法,论文的链接见下方. 论文:Human-level control through deep reinforcement learning | Nature 代码:后续会将代码上传到Github上... 1 DQN算法简介 Q-learning算法采用一
-
python中的函数递归和迭代原理解析
这篇文章主要介绍了python中的函数递归和迭代原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.递归 1.递归的介绍 什么是递归? 程序调用自身的编程技巧称为递归( recursion).递归做为一种算法在程序设计语言中广泛应用. 一个过程或函数在其定义或说明中有直接或间接调用自身的一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解,递归策略只需少量的程序就可描述出解题过程所需要的多次重复计算,大大
-
python教程网络爬虫及数据可视化原理解析
目录 1 项目背景 1.1Python的优势 1.2网络爬虫 1.3数据可视化 1.4Python环境介绍 1.4.1简介 1.4.2特点 1.5扩展库介绍 1.5.1安装模块 1.5.2主要模块介绍 2需求分析 2.1 网络爬虫需求 2.2 数据可视化需求 3总体设计 3.1 网页分析 3.2 数据可视化设计 4方案实施 4.1网络爬虫代码 4.2 数据可视化代码 5 效果展示 5.1 网络爬虫 5.1.1 爬取近五年主要城市数据 5.1.2 爬取2019年各省GDP 5.1.3 爬取豆瓣电影
-
Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下: python [-bBdEhiIOqsSuvVWx?] [-c command | -m module-name | script | - ] [args] 本文想要聊聊比较特殊的"-m"选项: 关于它的典型用法.原理解析与发展演变的过程. 首先,让我们用"--help"来看看它的解释: -m mod run library module as a script (ter
-
Python While循环语句实例演示及原理解析
这篇文章主要介绍了Python While循环语句实例演示及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python 编程中 while 语句用于循环执行程序,即在某条件下,循环执行某段程序,以处理需要重复处理的相同任务.其基本形式为: while 判断条件: 执行语句-- 执行语句可以是单个语句或语句块.判断条件可以是任何表达式,任何非零.或非空(null)的值均为true. 当判断条件假false时,循环结束. 执行流程图如下:
-
使用Redis实现令牌桶算法原理解析
在限流算法中有一种令牌桶算法,该算法可以应对短暂的突发流量,这对于现实环境中流量不怎么均匀的情况特别有用,不会频繁的触发限流,对调用方比较友好. 例如,当前限制10qps,大多数情况下不会超过此数量,但偶尔会达到30qps,然后很快就会恢复正常,假设这种突发流量不会对系统稳定性产生影响,我们可以在一定程度上允许这种瞬时突发流量,从而为用户带来更好的可用性体验.这就是使用令牌桶算法的地方. 令牌桶算法原理 如下图所示,该算法的基本原理是:有一个容量为X的令牌桶,每Y单位时间内将Z个令牌放入该桶.如
-
python 并发编程 非阻塞IO模型原理解析
非阻塞IO(non-blocking IO) Linux下,可以通过设置socket使其变为non-blocking.当对一个non-blocking socket执行读操作时,流程是这个样子: 从图中可以看出,当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error.从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果.用户进程判断结果是一个error时,它就知道数据还没有准备好,于是用户就可
-
Python可变对象与不可变对象原理解析
一.原理 可变对象:list dict set 不可变对象:tuple string int float bool 1. python不允许程序员选择采用传值还是传引用.Python参数传递采用的肯定是"传对象引用"的方式.实际上,这种方式相当于传值和传引用的一种综合.如果函数收到的是一个可变对象的引用,就能修改对象的原始值--相当于通过"传引用"来传递对象.如果函数收到的是一个不可变对象的引用,就不能直接修改原始对象--相当于通过"传值'来传递对象. 2