零基础写Java知乎爬虫之抓取知乎答案
前期我们抓取标题是在该链接下:
http://www.zhihu.com/explore/recommendations
但是显然这个页面是无法获取答案的。
一个完整问题的页面应该是这样的链接:
http://www.zhihu.com/question/22355264
仔细一看,啊哈我们的封装类还需要进一步包装下,至少需要个questionDescription来存储问题描述:
import java.util.ArrayList;public class Zhihu { public String question;// 问题 public String questionDescription;// 问题描述 public String zhihuUrl;// 网页链接 public ArrayList<String> answers;// 存储所有回答的数组 // 构造方法初始化数据 public Zhihu() { question = ""; questionDescription = ""; zhihuUrl = ""; answers = new ArrayList<String>(); } @Override public String toString() { return "问题:" + question + "\n" + "描述:" + questionDescription + "\n" + "链接:" + zhihuUrl + "\n回答:" + answers + "\n"; }}
我们给知乎的构造函数加上一个参数,用来设定url值,因为url确定了,这个问题的描述和答案也就都能抓到了。
我们将Spider的获取知乎对象的方法改一下,只获取url即可:
static ArrayList<Zhihu> GetZhihu(String content) { // 预定义一个ArrayList来存储结果 ArrayList<Zhihu> results = new ArrayList<Zhihu>(); // 用来匹配url,也就是问题的链接 Pattern urlPattern = Pattern.compile("<h2>.+?question_link.+?href=\"(.+?)\".+?</h2>"); Matcher urlMatcher = urlPattern.matcher(content); // 是否存在匹配成功的对象 boolean isFind = urlMatcher.find(); while (isFind) { // 定义一个知乎对象来存储抓取到的信息 Zhihu zhihuTemp = new Zhihu(urlMatcher.group(1)); // 添加成功匹配的结果 results.add(zhihuTemp); // 继续查找下一个匹配对象 isFind = urlMatcher.find(); } return results; }
接下来,就是在Zhihu的构造方法里面,通过url获取所有的详细数据。
我们先要对url进行一个处理,因为有的针对回答的,它的url是:
http://www.zhihu.com/question/22355264/answer/21102139
有的针对问题的,它的url是:
http://www.zhihu.com/question/22355264
那么我们显然需要的是第二种,所以需要用正则把第一种链接裁切成第二种,这个在Zhihu中写个函数即可。
// 处理url boolean getRealUrl(String url) { // 将http://www.zhihu.com/question/22355264/answer/21102139 // 转化成http://www.zhihu.com/question/22355264 // 否则不变 Pattern pattern = Pattern.compile("question/(.*?)/"); Matcher matcher = pattern.matcher(url); if (matcher.find()) { zhihuUrl = "http://www.zhihu.com/question/" + matcher.group(1); } else { return false; } return true; }
接下来就是各个部分的获取工作了。
先看下标题:
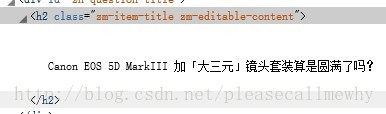
正则把握住那个class即可,正则语句可以写成:zm-editable-content\">(.+?)<
运行下看看结果:

哎哟不错哦。
接下来抓取问题描述:
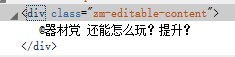
啊哈一样的原理,抓住class,因为它应该是这个的唯一标识。
验证方法:右击查看页面源代码,ctrl+F看看页面中有没有其他的这个字符串。
后来经过验证,还真出了问题:
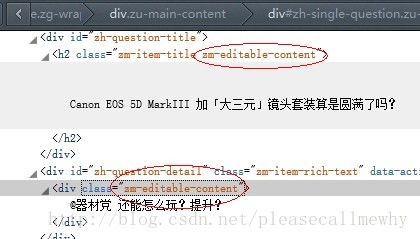
标题和描述内容前面的class是一样的。
那只能通过修改正则的方式来重新抓取:
// 匹配标题 pattern = Pattern.compile("zh-question-title.+?<h2.+?>(.+?)</h2>"); matcher = pattern.matcher(content); if (matcher.find()) { question = matcher.group(1); } // 匹配描述 pattern = Pattern .compile("zh-question-detail.+?<div.+?>(.*?)</div>"); matcher = pattern.matcher(content); if (matcher.find()) { questionDescription = matcher.group(1); }
最后就是循环抓取答案了:
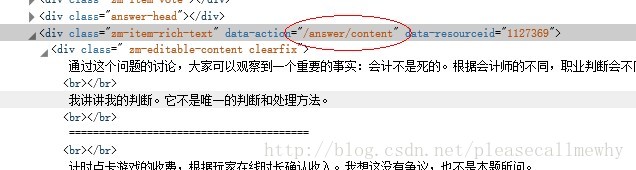
初步暂定正则语句:/answer/content.+?<div.+?>(.*?)</div>
改下代码之后我们会发现软件运行的速度明显变慢了,因为他需要访问每个网页并且把上面的内容抓下来。
比如说编辑推荐有20个问题,那么就需要访问网页20次,速度也就慢下来了。
试验一下,看上去效果不错:
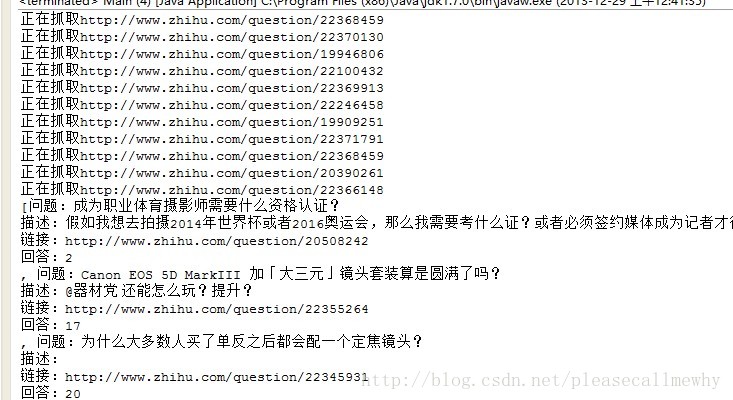
OK,那就先这样好了~下次继续进行一些细节的调整,比如多线程,IO流写入本地等等。
附项目源码:
Zhihu.java
import java.util.ArrayList;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Zhihu { public String question;// 问题 public String questionDescription;// 问题描述 public String zhihuUrl;// 网页链接 public ArrayList<String> answers;// 存储所有回答的数组 // 构造方法初始化数据 public Zhihu(String url) { // 初始化属性 question = ""; questionDescription = ""; zhihuUrl = ""; answers = new ArrayList<String>(); // 判断url是否合法 if (getRealUrl(url)) { System.out.println("正在抓取" + zhihuUrl); // 根据url获取该问答的细节 String content = Spider.SendGet(zhihuUrl); Pattern pattern; Matcher matcher; // 匹配标题 pattern = Pattern.compile("zh-question-title.+?<h2.+?>(.+?)</h2>"); matcher = pattern.matcher(content); if (matcher.find()) { question = matcher.group(1); } // 匹配描述 pattern = Pattern .compile("zh-question-detail.+?<div.+?>(.*?)</div>"); matcher = pattern.matcher(content); if (matcher.find()) { questionDescription = matcher.group(1); } // 匹配答案 pattern = Pattern.compile("/answer/content.+?<div.+?>(.*?)</div>"); matcher = pattern.matcher(content); boolean isFind = matcher.find(); while (isFind) { answers.add(matcher.group(1)); isFind = matcher.find(); } } } // 根据自己的url抓取自己的问题和描述和答案 public boolean getAll() { return true; } // 处理url boolean getRealUrl(String url) { // 将http://www.zhihu.com/question/22355264/answer/21102139 // 转化成http://www.zhihu.com/question/22355264 // 否则不变 Pattern pattern = Pattern.compile("question/(.*?)/"); Matcher matcher = pattern.matcher(url); if (matcher.find()) { zhihuUrl = "http://www.zhihu.com/question/" + matcher.group(1); } else { return false; } return true; } @Override public String toString() { return "问题:" + question + "\n" + "描述:" + questionDescription + "\n" + "链接:" + zhihuUrl + "\n回答:" + answers.size() + "\n"; }}
Spider.java
import java.io.BufferedReader;import java.io.InputStreamReader;import java.net.URL;import java.net.URLConnection;import java.util.ArrayList;import java.util.regex.Matcher;import java.util.regex.Pattern;public class Spider { static String SendGet(String url) { // 定义一个字符串用来存储网页内容 String result = ""; // 定义一个缓冲字符输入流 BufferedReader in = null; try { // 将string转成url对象 URL realUrl = new URL(url); // 初始化一个链接到那个url的连接 URLConnection connection = realUrl.openConnection(); // 开始实际的连接 connection.connect(); // 初始化 BufferedReader输入流来读取URL的响应 in = new BufferedReader(new InputStreamReader( connection.getInputStream(), "UTF-8")); // 用来临时存储抓取到的每一行的数据 String line; while ((line = in.readLine()) != null) { // 遍历抓取到的每一行并将其存储到result里面 result += line; } } catch (Exception e) { System.out.println("发送GET请求出现异常!" + e); e.printStackTrace(); } // 使用finally来关闭输入流 finally { try { if (in != null) { in.close(); } } catch (Exception e2) { e2.printStackTrace(); } } return result; } // 获取所有的编辑推荐的知乎内容 static ArrayList<Zhihu> GetRecommendations(String content) { // 预定义一个ArrayList来存储结果 ArrayList<Zhihu> results = new ArrayList<Zhihu>(); // 用来匹配url,也就是问题的链接 Pattern pattern = Pattern .compile("<h2>.+?question_link.+?href=\"(.+?)\".+?</h2>"); Matcher matcher = pattern.matcher(content); // 是否存在匹配成功的对象 Boolean isFind = matcher.find(); while (isFind) { // 定义一个知乎对象来存储抓取到的信息 Zhihu zhihuTemp = new Zhihu(matcher.group(1)); // 添加成功匹配的结果 results.add(zhihuTemp); // 继续查找下一个匹配对象 isFind = matcher.find(); } return results; }}
Main.java
import java.util.ArrayList;public class Main { public static void main(String[] args) { // 定义即将访问的链接 String url = "http://www.zhihu.com/explore/recommendations"; // 访问链接并获取页面内容 String content = Spider.SendGet(url); // 获取编辑推荐 ArrayList<Zhihu> myZhihu = Spider.GetRecommendations(content); // 打印结果 System.out.println(myZhihu); }}
以上就是抓取知乎答案的全部记录,非常的详尽,有需要的朋友可以参考下
相关推荐
-
java 爬虫详解及简单实例
Java爬虫 一.代码 爬虫的实质就是打开网页源代码进行匹配查找,然后获取查找到的结果. 打开网页: URL url = new URL(http://www.cnblogs.com/Renyi-Fan/p/6896901.html); 读取网页内容: BufferedReader bufr = new BufferedReader(new InputStreamReader(url.openStream())); 正则表达式进行匹配: tring mail_regex = "\\w+@\\w+
-

详解Java豆瓣电影爬虫——小爬虫成长记(附源码)
以前也用过爬虫,比如使用nutch爬取指定种子,基于爬到的数据做搜索,还大致看过一些源码.当然,nutch对于爬虫考虑的是十分全面和细致的.每当看到屏幕上唰唰过去的爬取到的网页信息以及处理信息的时候,总感觉这很黑科技.正好这次借助梳理Spring MVC的机会,想自己弄个小爬虫,简单没关系,有些小bug也无所谓,我需要的只是一个能针对某个种子网站能爬取我想要的信息就可以了.有Exception就去解决,可能是一些API使用不当,也可能是遇到了http请求状态异常,又或是数据库读写有问题,就是在这
-
零基础写Java知乎爬虫之先拿百度首页练练手
上一集中我们说到需要用Java来制作一个知乎爬虫,那么这一次,我们就来研究一下如何使用代码获取到网页的内容. 首先,没有HTML和CSS和JS和AJAX经验的建议先去W3C(点我点我)小小的了解一下. 说到HTML,这里就涉及到一个GET访问和POST访问的问题. 如果对这个方面缺乏了解可以阅读W3C的这篇:<GET对比POST>. 啊哈,在此不再赘述. 然后咧,接下来我们需要用Java来爬取一个网页的内容. 这时候,我们的百度就要派上用场了. 没错,他不再是那个默默无闻的网速测试器了,他即将
-
JAVA使用爬虫抓取网站网页内容的方法
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法.分享给大家供大家参考.具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下: // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar
-
零基础写Java知乎爬虫之进阶篇
说到爬虫,使用Java本身自带的URLConnection可以实现一些基本的抓取页面的功能,但是对于一些比较高级的功能,比如重定向的处理,HTML标记的去除,仅仅使用URLConnection还是不够的. 在这里我们可以使用HttpClient这个第三方jar包. 接下来我们使用HttpClient简单的写一个爬去百度的Demo: import java.io.FileOutputStream;import java.io.InputStream;import java.io.OutputStr
-
java正则表达式简单使用和网页爬虫的制作代码
正则表达式是一种专门用于对字符串的操作的规则. 1.在String类中就有一些方法是对字符串进行匹配,切割. 判断字符串是否与给出的正则表达式匹配的:boolean matches( String regex); 按照给定的正则表达式对字符串进行切割的:String[] split(String regex); 将符合正则表达式的字符串替换成我们想要的其他字符串:String replaceAll(String regex,String replacement) 2.下面介绍一下正则表
-
零基础写Java知乎爬虫之抓取知乎答案
前期我们抓取标题是在该链接下: http://www.zhihu.com/explore/recommendations 但是显然这个页面是无法获取答案的. 一个完整问题的页面应该是这样的链接: http://www.zhihu.com/question/22355264 仔细一看,啊哈我们的封装类还需要进一步包装下,至少需要个questionDescription来存储问题描述: import java.util.ArrayList;public class Zhihu { public St
-
零基础写Java知乎爬虫之准备工作
开篇我们还是和原来一样,讲一讲做爬虫的思路以及需要准备的知识吧,高手们请直接忽略. 首先我们来缕一缕思绪,想想到底要做什么,列个简单的需求. 需求如下: 1.模拟访问知乎官网(http://www.zhihu.com/) 2.下载指定的页面内容,包括:今日最热,本月最热,编辑推荐 3.下载指定分类中的所有问答,比如:投资,编程,挂科 4.下载指定回答者的所有回答 5.最好有个一键点赞的变态功能(这样我就可以一下子给雷伦的所有回答都点赞了我真是太机智了!) 那么需要解决的技术问题简单罗列如下: 1
-
零基础写Java知乎爬虫之获取知乎编辑推荐内容
知乎是一个真实的网络问答社区,社区氛围友好.理性.认真,连接各行各业的精英.他们分享着彼此的专业知识.经验和见解,为中文互联网源源不断地提供高质量的信息. 首先花个三五分钟设计一个Logo=.=作为一个程序员我一直有一颗做美工的心! 好吧做的有点小凑合,就先凑合着用咯. 接下来呢,我们开始制作知乎的爬虫. 首先,确定第一个目标:编辑推荐. 网页链接:http://www.zhihu.com/explore/recommendations 我们对上次的代码稍作修改,先实现能够获取该页面内容: im
-
零基础写Java知乎爬虫之将抓取的内容存储到本地
说到Java的本地存储,肯定使用IO流进行操作. 首先,我们需要一个创建文件的函数createNewFile: 复制代码 代码如下: public static boolean createNewFile(String filePath) { boolean isSuccess = true; // 如有则将"\\"转为"/",没有则不产生任何变化 String filePathTurn = filePath.r
-
零基础学Java:Java开发工具 Eclipse 安装过程创建第一个Java项目及Eclipse的一些基础使用技巧
一.下载https://www.eclipse.org/downloads/download.php?file=/oomph/epp/2020-06/R/eclipse-inst-win64.exe&mirror_id=1142 二.安装Eclipse 三.开始使用Eclipse,并创建第一个Java项目 src 鼠标右键 -- New --Class 四.一些基础操作 1.字体大小修改(咋一看感觉这字体太小了,看起来不舒服) Window -- Preferences 2.项目运行 3.当一些
-
Python使用Srapy框架爬虫模拟登陆并抓取知乎内容
一.Cookie原理 HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制 Cookie是http消息头中的一种属性,包括: Cookie名字(Name)Cookie的值(Value) Cookie的过期时间(Expires/Max-Age) Cookie作用路径(Path) Cookie所在域名(Domain),使用Cookie进行安全连接(Secure) 前两个参数是Cookie应用的必要条件,另外,还包括Cookie大小(Size,不同浏览器对Cookie个数及大
-
Java爬虫 信息抓取的实现
今天公司有个需求,需要做一些指定网站查询后的数据的抓取,于是花了点时间写了个demo供演示使用. 思想很简单:就是通过Java访问的链接,然后拿到html字符串,然后就是解析链接等需要的数据.技术上使用Jsoup方便页面的解析,当然Jsoup很方便,也很简单,一行代码就能知道怎么用了: Document doc = Jsoup.connect("http://www.oschina.net/") .data("query", "Java") //
-
百万级别知乎用户数据抓取与分析之PHP开发
这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04),在VMWare虚拟机下安装一个Ubuntu: 安装PHP5.6或以上版本: 安装curl.pcntl扩展. 使用PHP的curl扩展抓取页面数据 PHP的curl扩展是PHP支持的允许你与各种服务器使用各种类型的协议进行连接和通信的库. 本程序是抓取知乎的用户数据,要能访问用户个人页面,需要用户登录后的才能访问.当我们在浏览器的页面中点击一个用户头像链接进入用户个人中心页面的时候,之所以