python3获取url文件大小示例代码
在python3中,urllib2被替换为urllib.requeset,因此头文件中添加
import urllib.request as urllib2
def getRemoteFileSize(url, proxy=None):
""" 通过content-length头获取远程文件大小
url - 目标文件URL
proxy - 代理 """
opener = urllib2.build_opener()
if proxy:
if url.lower().startswith('https://'):
opener.add_handler(urllib2.ProxyHandler({'https' : proxy}))
else:
opener.add_handler(urllib2.ProxyHandler({'http' : proxy}))
try:
request = urllib2.Request(url)
request.get_method = lambda: 'HEAD'
response = opener.open(request)
response.read()
except Exception:
return 0
else:
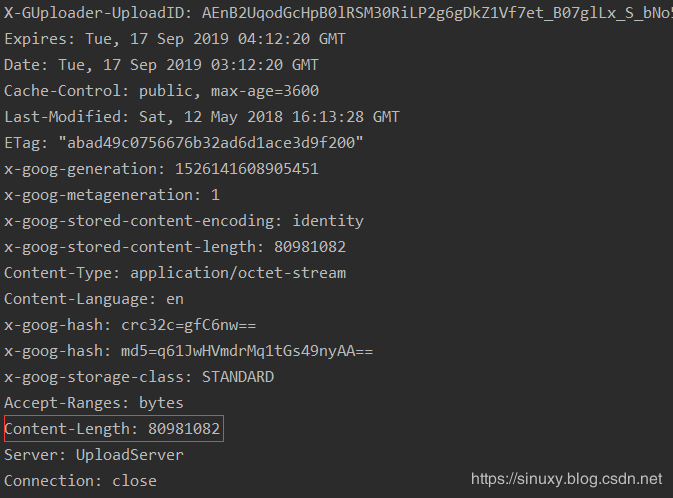
print(response.headers)
fileSize = dict(response.headers).get('content-length', 0)
return int(fileSize)
使用上段代码发现输出为0,考虑应该是没查询到content-length字段,打印response.headers字段后,发现content-length字段应改为Content-Length,改后正常
def getRemoteFileSize(url, proxy=None):
""" 通过content-length头获取远程文件大小
url - 目标文件URL
proxy - 代理 """
opener = urllib2.build_opener()
if proxy:
if url.lower().startswith('https://'):
opener.add_handler(urllib2.ProxyHandler({'https' : proxy}))
else:
opener.add_handler(urllib2.ProxyHandler({'http' : proxy}))
try:
request = urllib2.Request(url)
request.get_method = lambda: 'HEAD'
response = opener.open(request)
response.read()
except Exception:
return 0
else:
print(response.headers)
fileSize = dict(response.headers).get('Content-Length', 0)
return int(fileSize)
总结
以上所述是小编给大家介绍的python3获取url文件大小示例代码,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python根据文件大小打log日志
本文实例讲述了python根据文件大小打log日志的方法,分享给大家供大家参考.具体方法如下: import glob import logging import logging.handlers LOG_FILENAME='logging_rotatingfile_example.out' # Set up a specific logger with our desired output level my_logger = logging.getLogger('MyLogger') my_l
-

python 生成目录树及显示文件大小的代码
比如 1--1 2--1 2 3--1 2 3 3--1 2 3 交错的层级关系,刚开始感觉很乱没有想明白,后来终于抓住了关键.只要算出每个层次的深度,就好办了. 我定义了一个rank,进入一个子文件夹时,让rank+1,遍历完子文件夹rank就-1. 如图充分说明了递归.遍历的顺序以及rank值变化:(丑了点...) 下面放代码: 复制代码 代码如下: ''' Created on Jul 22, 2009 @author: dirful ''' import os class dir(obj
-
Python获取远程文件大小的函数代码分享
复制代码 代码如下: def getRemoteFileSize(url, proxy=None): """ 通过content-length头获取远程文件大小 url - 目标文件URL proxy - 代理 """ opener = urllib2.build_opener() if proxy: if url.lower().startswith('https://'):
-
python re正则匹配网页中图片url地址的方法
最近写了个python抓取必应搜索首页http://cn.bing.com/的背景图片并将此图片更换为我的电脑桌面的程序,在正则匹配图片url时遇到了匹配失败问题. 要抓取的图片地址如图所示: 首先,使用这个pattern reg = re.compile('.*g_img={url: "(http.*?jpg)"') 无论怎么匹配都匹配不到,后来把网页源码抓下来放在notepad++中查看,并用notepad++的正则匹配查找,很轻易就匹配到了,如图: 后来我写了个测试代码,把图片地
-
python 获取url中的参数列表实例
Python的urlparse有对url的解析,从而获得url中的参数列表 import urlparse urldata = "http://en.wikipedia.org/w/api.php?action=query&ctitle=FA" result = urlparse.urlparse(urldata) print result print urlparse.parse_qs(result.query) 输出: ParseResult(scheme='http',
-
python实现从网络下载文件并获得文件大小及类型的方法
本文实例讲述了python实现从网络下载文件并获得文件大小及类型的方法.分享给大家供大家参考.具体实现方法如下: import urllib2 from settings import COOKIES opener = urllib2.build_opener() cookies = ";".join("%s=%s" % (k, v) for k, v in COOKIES.items()) opener.addheaders.append(('Cookie', c
-
对Python正则匹配IP、Url、Mail的方法详解
如下所示: """ Created on Thu Nov 10 14:07:36 2016 @author: qianzhewoniuqusanbu """ import re def RegularMatchIP(ip): '''进行正则匹配ip,加re.IGNORECASE是让结果返回bool型''' pattern=re.match(r'\b(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?
-
基于Python实现文件大小输出
在数据库中存储时,使用 Bytes 更精确,可扩展性和灵活性都很高. 输出时,需要做一些适配. 1. 注意事项与测试代码 1.需要考虑 sizeInBytes 为 None 的场景. 2.除以 1024.0 而非 1024,避免丢失精度. 实现的函数为 getSizeInMb(sizeInBytes),通用的测试代码为 def getSizeInMb(sizeInBytes): return 0 def test(sizeInBytes): print '%s -> %s' % (sizeInB
-
python爬虫之urllib库常用方法用法总结大全
Urllib 官方文档地址:https://docs.python.org/3/library/urllib.html urllib提供了一系列用于操作URL的功能. 本文主要介绍的是关于python urllib库常用方法用法的相关内容,下面话不多说了,来一起看看详细的介绍吧 1.读取cookies import http.cookiejar as cj,urllib.request as request cookie = cj.CookieJar() handler = request.HT
-
Python2和Python3中urllib库中urlencode的使用注意事项
前言 在Python中,我们通常使用urllib中的urlencode方法将字典编码,用于提交数据给url等操作,但是在Python2和Python3中urllib模块中所提供的urlencode的包位置有些不同. 对于Python2 Python2中提供了urllib和urllib2两个模块. urlencode方法所在位置为: urllib.urlencode(values) # 其中values为所需要编码的数据,并且只能为字典 例如模拟登陆CSDN网站,示例程序如下 import url