windows下搭建python scrapy爬虫框架步骤
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windows下搭建scrapy框架,官方文档是建议使用集成包的,以免安装太过复杂而出现问题,首先百度scrapy,就可以找到scrapy的官方文档
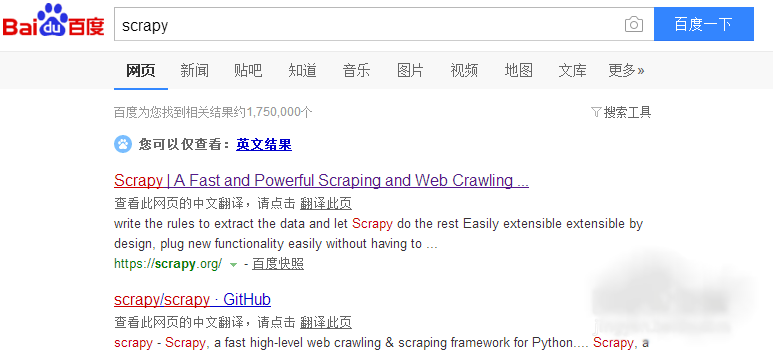
1、找到windows下的框架安装的文档教程,这里建议我们安装Anaconda或者Miniconda集成包,下面我选择安装Miniconda安装包来安装scrapy框架
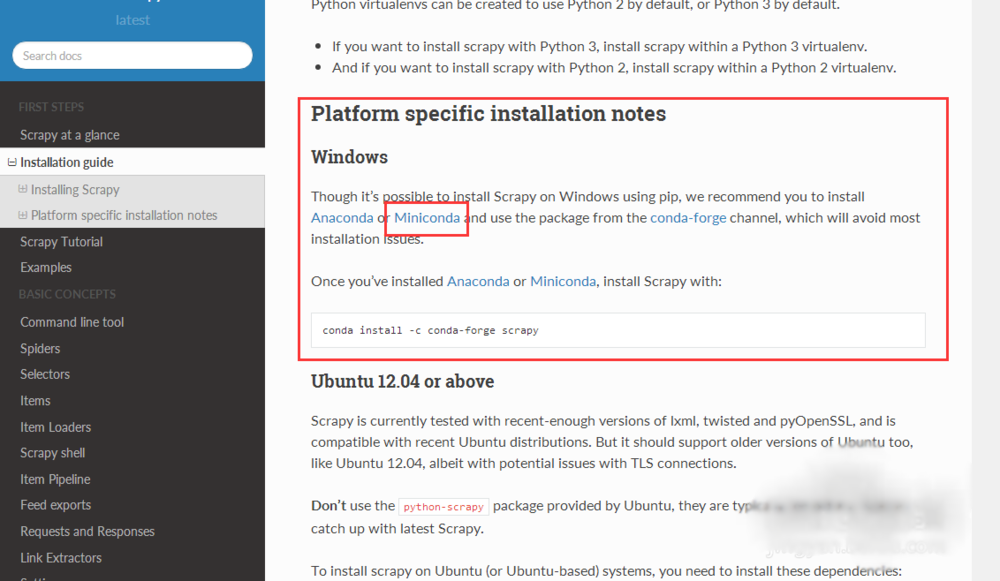
2、百度Miniconda python集成安装包,根据自己的python版本和windows版本选择对应的安装包下载即可


3、下载完成后进入安装界面,全程下一步即可

4、在cmd窗口中用conda list 命令检验conda是否安装成功
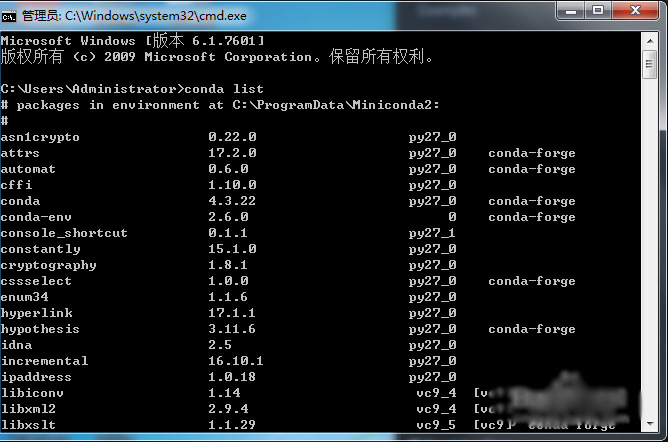
5、如果检验命令无效,检查下环境变量里是否有正确的读取路径,如果还是不行,尝试重新安装

6、使用 conda install -c conda-forge scrapy 命令安装scrapy框架

7、
等待框架的各个组件下载安装完成,安装界面很炫酷哦
等待框架的各个组件下载安装完成,安装界面很炫酷哦
8、最后一步,使用 scrapy startproject tutorial 命令生成scrapy爬虫模版,然后就可以根据文档对scrapy爬虫模版进行改写来完成我们自己的网络爬虫了,大功告成!!!

总结:以上就是关于在WIN下安装python爬虫框架的步骤教学,感谢大家的阅读和对我们的支持。
相关推荐
-

Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能示例
本文实例讲述了Python爬虫框架scrapy实现downloader_middleware设置proxy代理功能.分享给大家供大家参考,具体如下: 一.背景: 小编在爬虫的时候肯定会遇到被封杀的情况,昨天爬了一个网站,刚开始是可以了,在settings的设置DEFAULT_REQUEST_HEADERS伪装自己是chrome浏览器,刚开始是可以的,紧接着就被对方服务器封杀了. 代理: 代理,代理,一直觉得爬去网页把爬去速度放慢一点就能基本避免被封杀,虽然可以使用selenium,但是这个坎必须
-
Scrapy框架爬取Boss直聘网Python职位信息的源码
分析 使用CrawlSpider结合LinkExtractor和Rule爬取网页信息 LinkExtractor用于定义链接提取规则,一般使用allow参数即可 LinkExtractor(allow=(), # 使用正则定义提取规则 deny=(), # 排除规则 allow_domains=(), # 限定域名范围 deny_domains=(), # 排除域名范围 restrict_xpaths=(), # 使用xpath定义提取队则 tags=('a', 'area'), attrs=(
-
图文详解python安装Scrapy框架步骤
python书写爬虫的一个框架,它也提供了多种类型爬虫的基类,scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 首先要先安装python 安装完成以后,配置一下环境变量. 还需要安装一些组件pywin32,百度搜索下载安装 pywin32安装完成还要安转pip,百度搜索pip下载下来,解压通过cmd命令进行安装 我查看一下pip是否安装成功 执行pip install Scrapy进行安装Scrapy 测试一下Scrapy框架是否安装成功,不报错就说明安装成功了
-
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能.分享给大家供大家参考,具体如下: 使用Scrapy爬虫抓取英雄联盟高清桌面壁纸 源码地址:https://github.com/snowyme/loldesk 开始项目前需要安装python3和Scrapy,不会的自行百度,这里就不具体介绍了 首先,创建项目 scrapy startproject loldesk 生成项目的目录结构 首先需要定义抓取元素,在item.py中,我们这个项目用到了图片名和链接 import scrapy
-
详解Python网络框架Django和Scrapy安装指南
Windows 上的Django安装 如今Python使用的范围越来越广,所以学会关于它比较火的网络框架非常有必要.要安装Django,首先要知道你电脑上的python是哪个版本的,至于如何安装python的解释器环境此处不做介绍,网上的教程很多. Django 是一个 Python Web 框架,因此需要在您的机器上安装 Python.本文是基于Python3.6的环境安装介绍的. 要查看你电脑上的python版本,使用以下指令: python --version 要安装django,还要安装
-
windows7 32、64位下python爬虫框架scrapy环境的搭建方法
适用于python 2.7 64位安装 一.操作系统:WIN7 64位 二.python版本:2.7 64位(scrapy目前不支持3.x) 不确定位数的,看图 三.安装相关软件(可以从我的百度网盘下载:链接: https://pan.baidu.com/s/1MzHNALJcRePSoaEqBQvGAQ 提取码: xd5e ) 我配置环境的时候是直接pip install scrapy安装的,但是在过程中出现一些错误,发现是由于以下软件安装失败导致的.所以请先安装这4个相关软件再安装scrap
-
Python爬虫框架Scrapy实例代码
目标任务:爬取腾讯社招信息,需要爬取的内容为:职位名称,职位的详情链接,职位类别,招聘人数,工作地点,发布时间. 一.创建Scrapy项目 scrapy startproject Tencent 命令执行后,会创建一个Tencent文件夹,结构如下 二.编写item文件,根据需要爬取的内容定义爬取字段 # -*- coding: utf-8 -*- import scrapy class TencentItem(scrapy.Item): # 职位名 positionname = scrapy.
-
windows下搭建python scrapy爬虫框架步骤
网络上现有的windows下搭建scrapy教程都比较旧,一般都是咔咔咔安装一堆软件,太麻烦,这是因为scrapy框架用到好多不同的模块,其实查阅最新的官网scrapy文档,在windows下搭建scrapy框架,官方文档是建议使用集成包的,以免安装太过复杂而出现问题,首先百度scrapy,就可以找到scrapy的官方文档 1.找到windows下的框架安装的文档教程,这里建议我们安装Anaconda或者Miniconda集成包,下面我选择安装Miniconda安装包来安装scrapy框架 2.
-
Windows下搭建python开发环境详细步骤
本文为大家分享了Windows下搭建python开发环境详细步骤,供大家参考,具体内容如下 1.搭建Java环境 (1)直接从官网下载相应版本的JDK或者JRE并点击安装就可以 (2)JDK与JRE的区别: 1)JDK就是Java Development Kit.简单的说JDK是面向开发人员使用的SDK,它提供了Java的开发环境和运行环境.SDK是Software Development Kit 一般指软件开发包,可以包括函数库.编译程序等 2)JRE是Java Runtime Envirom
-
Python入门开发教程 windows下搭建开发环境vscode的步骤详解
目录 一.环境介绍 二. 搭建python开发环境 2.1 Python版本介绍 2.2 在windows下安装Python环境 2.3 windows下安装VSCode代码编辑器 一.环境介绍 操作系统: win10 64位 python版本: 3.8 IDE: 采用vscode 用到的相关安装包CSDN打包下载地址: http://xiazai.jb51.net/202107/yuanma/Pytho_jb51.rar 二. 搭建python开发环境 2.1 Python版本介绍 因为Pyt
-
python Scrapy爬虫框架的使用
导读:如何使用scrapy框架实现爬虫的4步曲?什么是CrawSpider模板?如何设置下载中间件?如何实现Scrapyd远程部署和监控?想要了解更多,下面让我们来看一下如何具体实现吧! Scrapy安装(mac) pip install scrapy 注意:不要使用commandlinetools自带的python进行安装,不然可能报架构错误:用brew下载的python进行安装. Scrapy实现爬虫 新建爬虫 scrapy startproject demoSpider,demoSpide
-
一文读懂python Scrapy爬虫框架
Scrapy是什么? 先看官网上的说明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. S
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
详解Python的爬虫框架 Scrapy
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程(注:图片来自互联网). 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎
-
Windows下搭建Redis集群的方法步骤
目录 Redis集群: 在Windows系统下搭建Redis集群: 1.下载并安装Redis 2.下载并安装ruby 3.创建Redis集群 Redis集群: 如果部署到多台电脑,就跟普通的集群一样:因为Redis是单线程处理的,多核CPU也只能使用一个核, 所以部署在同一台电脑上,通过运行多个Redis实例组成集群,然后能提高CPU的利用率. 在Windows系统下搭建Redis集群: 需要4个部件: Redis.Ruby语言运行环境.Redis的Ruby驱动redis-xxxx.gem.创建