详解JavaScript调用栈、尾递归和手动优化
调用栈(Call Stack)
调用栈(Call Stack)是一个基本的计算机概念,这里引入一个概念:栈帧。
栈帧是指为一个函数调用单独分配的那部分栈空间。
当运行的程序从当前函数调用另外一个函数时,就会为下一个函数建立一个新的栈帧,并且进入这个栈帧,这个栈帧称为当前帧。而原来的函数也有一个对应的栈帧,被称为调用帧。每一个栈帧里面都会存入当前函数的局部变量。
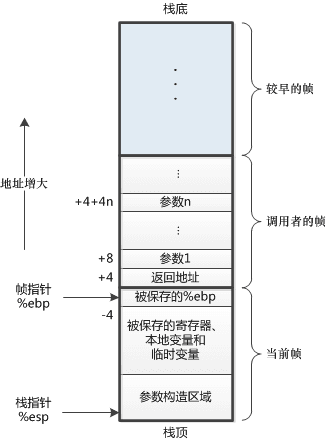
当函数被调用时,就会被加入到调用栈顶部,执行结束之后,就会从调用栈顶部移除该函数。并将程序运行权利(帧指针)交给此时栈顶的栈帧。这种后进后出的结构也就是函数的调用栈。
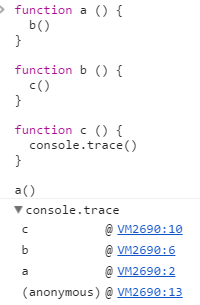
而在JavaScript里,可以很方便的通过console.trace()这个方法查看当前函数的调用帧
尾调用
说尾递归之前必须先了解一下什么是尾调用。简单的说,就是一个函数执行的最后一步是将另外一个函数调用并返回。
以下是正确示范:
// 尾调用正确示范1.0
function f(x){
return g(x);
}
// 尾调用正确示范2.0
function f(x) {
if (x > 0) {
return m(x)
}
return n(x);
}
1.0程序的最后一步即是执行函数g,同时将其返回值返回。2.0中,尾调用并不是非得写在最后一行中,只要执行时,是最后一步操作就可以了。
以下是错误示范:
// 尾调用错误示范1.0
function f(x){
let y = g(x);
return y;
}
// 尾调用错误示范2.0
function f(x){
return g(x) + 1;
}
// 尾调用错误示范3.0
function f(x) {
g(x); // 这一步相当于g(x) return undefined
}
1.0最后一步为赋值操作,2.0最后一步为加法运算操作,3.0隐式的有一句return undefined
尾调用优化
在调用栈的部分我们知道,当一个函数A调用另外一个函数B时,就会形成栈帧,在调用栈内同时存在调用帧A和当前帧B,这是因为当函数B执行完成后,还需要将执行权返回A,那么函数A内部的变量,调用函数B的位置等信息都必须保存在调用帧A中。不然,当函数B执行完继续执行函数A时,就会乱套。
那么现在,我们将函数B放到了函数A的最后一步调用(即尾调用),那还有必要保留函数A的栈帧么?当然不用,因为之后并不会再用到其调用位置、内部变量。因此直接用函数B的栈帧取代A的栈帧即可。当然,如果内层函数使用了外层函数的变量,那么就仍然需要保留函数A的栈帧,典型例子即是闭包。
在网上有很多关于讲解尾调用的博客文章,其中流传广泛的一篇中有这样一段。我不是很认同。
function f() {
let m = 1;
let n = 2;
return g(m + n);
}
f();
// 等同于
function f() {
return g(3);
}
f();
// 等同于
g(3);
以下为博客原文:上面代码中,如果函数g不是尾调用,函数f就需要保存内部变量m和n的值、g的调用位置等信息。但由于调用g之后,函数f就结束了,所以执行到最后一步,完全可以删除 f() 的调用记录,只保留 g(3) 的调用记录。
但我认为第一种中,也是先执行m+n这步操作,再调用函数g同时返回。这应当是一次尾调用。同时m+n的值也通过参数传入函数g内部,并没有直接引用,因此也不能说需要保存f内部的变量的值。
总得来说,如果所有函数的调用都是尾调用,那么调用栈的长度就会小很多,这样需要占用的内存也会大大减少。这就是尾调用优化的含义。
尾递归
递归,是指在函数的定义中使用函数自身的一种方法。函数调用自身即称为递归,那么函数在尾调用自身,即称为尾递归。
最常见的递归,斐波拉契数列,普通递归的写法:
function f(n) {
if (n === 0 || n === 1) return n
else return f(n - 1) + f(n - 2)
}
这种写法,简单粗暴,但是有个很严重的问题。调用栈随着n的增加而线性增加,当n为一个大数(我测了一下,当n为100的时候,浏览器窗口就会卡死。。)时,就会爆栈了(栈溢出,stack overflow)。这是因为这种递归操作中,同时保存了大量的栈帧,调用栈非常长,消耗了巨大的内存。
接下来,将普通递归升级为尾递归看看。
function fTail(n, a = 0, b = 1) {
if (n === 0) return a
return fTail(n - 1, b, a + b)
}
很明显,其调用栈为
fTail(5) => fTail(4, 1, 1) => fTail(3, 1, 2) => fTail(2, 2, 3) => fTail(1, 3, 5) => fTail(0, 5, 8) => return 5
被尾递归改写之后的调用栈永远都是更新当前的栈帧而已,这样就完全避免了爆栈的危险。
但是,想法是好的,从尾调用优化到尾递归优化的出发点也没错,然并卵:),让我们看看V8引擎官方团队的解释
Proper tail calls have been implemented but not yet shipped given that a change to the feature is currently under discussion at TC39.
意思就是人家已经做好了,但是就是还不能不给你用:)嗨呀,好气喔。
当然,人家肯定是有他的正当理由的:
- 在引擎层面消除尾递归是一个隐式的行为,程序员写代码时可能意识不到自己写了死循环的尾递归,而出现死循环后又不会报出stack overflow的错误,难以辨别。
- 堆栈信息会在优化的过程中丢失,开发者调试非常困难。
道理我都懂,但是不信邪的我拿nodeJs(v6.9.5)手动测试了一下:
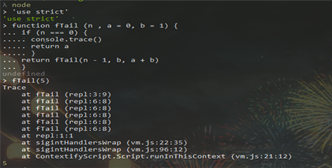
好的,我服了
手动优化
虽然我们暂时用不上ES6的尾递归高端优化,但递归优化的本质还是为了减少调用栈,避免内存占用过多,爆栈的危险。而俗话说的好,一切能用递归写的函数,都能用循环写——尼克拉斯·夏,如果将递归改成循环的话,不就解决了这种调用栈的问题么。
方案一:直接改函数内部,循环执行
function fLoop(n, a = 0, b = 1) {
while (n--) {
[a, b] = [b, a + b]
}
return a
}
这种方案简单粗暴,缺点就是没有递归的那种写法比较容易理解。
方案二:Trampolining(蹦床函数)
function trampoline(f) {
while (f && f instanceof Function) {
f = f()
}
return f
}
function f(n, a = 0, b = 1) {
if (n > 0) {
[a, b] = [b, a + b]
return f.bind(null, n - 1, a, b)
} else {
return a
}
}
trampoline(f(5)) // return 5
这种写法算是容易理解一些了,就是蹦床函数的作用需要仔细看看。缺点还有就是需要修改原函数内部的写法。
方案三:尾递归函数转循环方法
function tailCallOptimize(f) {
let value
let active = false
const accumulated = []
return function accumulator() {
accumulated.push(arguments)
if (!active) {
active = true
while (accumulated.length) {
value = f.apply(this, accumulated.shift())
}
active = false
return value
}
}
}
const f = tailCallOptimize(function(n, a = 0, b = 1) {
if (n === 0) return a
return f(n - 1, b, a + b)
})
f(5) // return 5
经过 tailCallOptimize 包装后返回的是一个新函数 accumulator,执行 f时实际执行的是这个函数。这种方法可以不用修改原递归函数,当调用递归时只用使用该方法转置一下便可解决递归调用的问题。
总结
尾递归优化是个好东西,但既然暂时用不上,那我们就该在平时编码的过程中,对使用到了递归的地方特别敏感,时刻避免出现死循环,爆栈等危险。毕竟,好的工具不如好的习惯。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

JavaScript中数据结构与算法(一):栈
序 数据结构与算法JavaScript这本书算是讲解得比较浅显的,优点就是用javascript语言把常用的数据结构给描述了下,书中很多例子来源于常见的一些面试题目,算是与时俱进,业余看了下就顺便记录下来吧 git代码下载:https://github.com/JsAaron/data_structure.git 栈结构 特殊的列表,栈内的元素只能通过列表的一端访问,栈顶 后入先出(LIFO,last-in-first-out)的数据结构 javascript提供可操作的方法, 入栈 push,
-
JavaScript 栈的详解及实例代码
JavaScript 栈 栈是一种遵从先进后出(LIFO)原则的有序集合. 新添加或待删除的元素都保存在栈的末尾,称作栈顶,另一端就叫栈底. 在栈里,新元素都靠近栈顶,旧元素都接近栈底 昨天因为有点事没有更新,今天打算给大家讲讲JavaScript实现的数据结构 数据结构与算法是程序语言的灵魂,是解决一切编程问题的基础 以前学C/C++的时候,感觉算法还是非常重要的,但是前端涉及的并不多 不管怎样,作为技术人员,理解一些基本数据结构和算法应该是必须的 而且我们的JavaScript实现数据结构和
-
JavaScript数据结构与算法之栈详解
在上一篇博客介绍了下列表,列表是最简单的一种结构,但是如果要处理一些比较复杂的结构,列表显得太简陋了,所以我们需要某种和列表类似但是更复杂的数据结构---栈.栈是一种高效的数据结构,因为数据只能在栈顶添加或删除,所以这样操作很快,而且容易实现. 一:对栈的操作. 栈是一种特殊的列表,栈内的元素只能通过列表的一端访问,这一端陈为栈顶.比如餐馆里面洗盘子,只能先洗最上面的盘子,盘子洗完后,也只能螺到这一摞盘子的最上面.栈被称为 "后入先出"(LIFO)的数据结构. 由于栈具有后入先出的特点
-
JavaScript数组实现数据结构中的队列与堆栈
一.队列和堆栈的简单介绍 1.1.队列的基本概念 队列:是一种支持先进先出(FIFO)的集合,即先被插入的数据,先被取出! 如下图所示: 1.2.堆栈的基本概念 堆栈:是一种支持后进先出(LIFO)的集合,即后被插入的数据,先被取出! 如下图所示: 二. 在JavaScript中实现队列和堆栈 在JavaScript中实现队列和数组主要是通过数组,js数组中提供了以下几个方法可以让我们很方便实现队列和堆栈: •shift:从数组中把第一个元素删除,并返回这个元素的值. •unshift: 在数组
-
JS实现队列与堆栈的方法
本文实例讲述了JS实现队列与堆栈的方法.分享给大家供大家参考,具体如下: 在面向对象的程序设计里,一般都提供了实现队列(queue)和堆栈(stack)的方法,而对于JS来说,我们可以实现数组的相关操作,来实现队列和堆栈的功能,看下面的相关介绍. 一.看一下它们的性质,这种性质决定了它们的使用场合 队列:是一种支持先进先出(FIFO)的集合,即先被插入的数据,先被取出! 堆栈:是一种支持后进先出(LIFO)的集合,即后被插入的数据,先被取出! 二.看一下实现的代码(JS代码) var a=new
-
JavaScript数组的栈方法与队列方法详解
数组(Array)和对象(Object)应该是JavaScript中使用最多也是最频繁的两种类型了,Array提供了很多常用的方法:栈方法.队列方法.重排序方法.操作方法.位置方法.迭代方法等等. 1.Array的栈方法 栈是一种LIFO(Last-In-First-Out,后进先出)的数据结构,也就是最新添加的项最早被移除.栈中项的插入(push)和移除,只发生在一个位置--栈的顶部.ECMAScript为数组提供了push()和pop()方法,可以实现类似栈的行为.下面两图分别演示了入栈与出
-
JavaScript实现显示函数调用堆栈的方法
本文实例讲述了JavaScript实现显示函数调用堆栈的方法.分享给大家供大家参考,具体如下: 许多大型的JavaScript应用程序间的函数调用关系是非常复杂的,在开发或者调试过程中,经常需要跟踪某个函数是由哪些函数调用后才触发执行的,弄清楚这些函数的调用顺序对我们理解代码的数据流向是非常重要的. Firebug提供了console.trace()来显示函数堆栈,在需要调试的地方加上下面的一行代码就能显示该函数调用时的上下文关系.IE6就没有这么方便了,它没有提供显示函数堆栈的工具,当不可避免
-
JavaScript把数组作为堆栈使用的方法
本文实例讲述了JavaScript把数组作为堆栈使用的方法.分享给大家供大家参考.具体如下: JavaScript把数组作为堆栈使用的代码范例,支持堆栈常用的push和pop方法 <script type="text/javascript"> var numbers = ["one", "two", "three", "four"]; numbers.push("five")
-
详解JavaScript调用栈、尾递归和手动优化
调用栈(Call Stack) 调用栈(Call Stack)是一个基本的计算机概念,这里引入一个概念:栈帧. 栈帧是指为一个函数调用单独分配的那部分栈空间. 当运行的程序从当前函数调用另外一个函数时,就会为下一个函数建立一个新的栈帧,并且进入这个栈帧,这个栈帧称为当前帧.而原来的函数也有一个对应的栈帧,被称为调用帧.每一个栈帧里面都会存入当前函数的局部变量. 当函数被调用时,就会被加入到调用栈顶部,执行结束之后,就会从调用栈顶部移除该函数.并将程序运行权利(帧指针)交给此时栈顶的栈帧.这种后进
-
详解JavaScript中的执行上下文及调用堆栈
一.执行上下文是什么 代码运行是在一定的环境之中运行的,这个运行环境我们就成为执行环境,也就是执行上下文,按照执行环境不同,我们可以分为三类: 全局执行环境:代码首次执行时候的默认环境 函数执行环境:每当执行流程进入到一个函数体内部的时候 Eval执行环境:当eval函数内部的文本执行的时候 二.执行上下文栈是什么 既然是'栈',那就得符合'栈'的特性,即数据结构是先进后出.下面我们看一段代码: function cat(a){ if(a<0){ return false; } console.
-
详解JavaScript中的链式调用
链模式 链模式是一种链式调用的方式,准确来说不属于通常定义的设计模式范畴,但链式调用是一种非常有用的代码构建技巧. 描述 链式调用在JavaScript语言中很常见,如jQuery.Promise等,都是使用的链式调用,当我们在调用同一对象多次其属性或方法的时候,我们需要多次书写对象进行.或()操作,链式调用是一种简化此过程的一种编码方式,使代码简洁.易读. 链式调用通常有以下几种实现方式,但是本质上相似,都是通过返回对象供之后进行调用. this的作用域链,jQuery的实现方式,通常链式调用
-
详解Python如何实现尾递归优化
目录 一般递归与尾递归 一般递归 尾递归 C中尾递归的优化 Python开启尾递归优化 一般递归与尾递归 一般递归 def normal_recursion(n): if n == 1: return 1 else: return n + normal_recursion(n-1) 执行: normal_recursion(5)5 + normal_recursion(4)5 + 4 + normal_recursion(3)5 + 4 + 3 + normal_recursion(2)5 +
-
详解JavaScript基本类型和引用类型
一.值的类型 早在介绍JS的数据类型的时候就提到过基本类型和引用类型,不过在说两种类型之前,我们先来了解一下变量的值的类型.在ECMAScript中,变量可以存在两种类型的值,即原始值和引用值. (1)原始值 存储在栈中的简单数据段,也就是说,它们的值直接存储在变量访问的位置. (2)引用值 存储在堆中的对象,也就是说,存储在变量处的值是一个指针,指向存储对象的内存处. 为变量赋值时,ECMAScript的解释程序必须判断该值是原始类型,还
-
详解JavaScript匿名函数和闭包
概述 在JavaScript前端开发中,函数与对其状态即词法环境(lexical environment)的引用共同构成闭包(closure).也就是说,闭包可以让你从内部函数访问外部函数作用域.在JavaScript,函数在每次创建时生成闭包.匿名函数和闭包可以放在一起学习,可以加深理解.本文主要通过一些简单的小例子,简述匿名函数和闭包的常见用法,仅供学习分享使用,如有不足之处,还请指正. 普通函数 普通函数由fucntion关键字,函数名,() 和一对{} 组成,如下所示: function
-
详解JavaScript 的执行机制
一.关于javascript javascript是一门单线程语言,在最新的HTML5中提出了Web Worker,但javascript是单线程这一核心仍未改变. 为什么js是单线程的语言?因为最初的js是用来在浏览器验证表单操纵DOM元素的.如果js是多线程的话,两个线程同时对一个DOM进行了相互冲突的操作,那么浏览器的解析是无法执行的. Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行.在主线程运行的同
-
详解JavaScript执行模型
JavaScript执行模型 引言 JavaScript是一个单线程(Single-threaded)异步(Asynchronous)非阻塞(Non-blocking)并发(Concurrent)语言,这些语言效果通过一个调用栈(Call Stack).一个事件循环(Event Loop).一个回调队列(Callback Queue)有些时候也叫任务队列(Task Queue)与跟运行环境相关的API组成. 概念 调用栈 Call Stack 调用栈是一个LIFO后进先出数据结构的函数运行栈,它
-
详解JavaScript的this指向和绑定
注意: 本文属于基础篇,请大神绕路.如果你不够了解,或者了解的还不完整,那么可以通过本文来复习一下. this 指向的类型 刚开始学习 JavaScript 的时候,this 总是最能让人迷惑,下面我们一起看一下在 JavaScript 中应该如何确定 this 的指向. this 是在函数被调用时确定的,它的指向完全取决于函数调用的地方,而不是它被声明的地方(除箭头函数外).当一个函数被调用时,会创建一个执行上下文,它包含函数在哪里被调用(调用栈).函数的调用方式.传入的参数等信息,this
-
详解JavaScript错误捕获
目录 一.基本使用与逻辑 二.特性 三.错误对象 四.较好的catch和throw策略 五.Promise的错误处理 六.性能损耗 一.基本使用与逻辑 使用 try{ //code.... }catch(err){ //error handling }finally{ //no matter what happens in the try/catch (error or no error), this code in the finally statement should run. } 逻辑