在java中使用dom4j解析xml(示例代码)
虽然Java中已经有了Dom和Sax这两种标准解析方式
但其操作起来并不轻松,对于我这么一个初学者来说,其中部分代码是活生生的恶心
为此,伟大的第三方开发组开发出了Jdom和Dom4j等工具
鉴于目前的趋势,我们这里来讲讲Dom4j的基本用法,不涉及递归等复杂操作
Dom4j的用法很多,官网上的示例有那么点儿晦涩,这里就不写了
首先我们需要出创建一个xml文档,然后才能对其解析
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="001">
<title>Harry Potter</title>
<author>J K. Rowling</author>
</book>
<book id="002">
<title>Learning XML</title>
<author>Erik T. Ray</author>
</book>
</books>
import java.io.File;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo {
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
File file = new File("books.xml");
Document document = reader.read(file);
Element root = document.getRootElement();
List<Element> childElements = root.elements();
for (Element child : childElements) {
//未知属性名情况下
/*List<Attribute> attributeList = child.attributes();
for (Attribute attr : attributeList) {
System.out.println(attr.getName() + ": " + attr.getValue());
}*/
//已知属性名情况下
System.out.println("id: " + child.attributeValue("id"));
//未知子元素名情况下
/*List<Element> elementList = child.elements();
for (Element ele : elementList) {
System.out.println(ele.getName() + ": " + ele.getText());
}
System.out.println();*/
//已知子元素名的情况下
System.out.println("title" + child.elementText("title"));
System.out.println("author" + child.elementText("author"));
//这行是为了格式化美观而存在
System.out.println();
}
}
}
示例二:使用Iterator迭代器的方式来解析xml
代码如下:
import java.io.File;
import java.util.Iterator;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo {
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("books.xml"));
Element root = document.getRootElement();
Iterator it = root.elementIterator();
while (it.hasNext()) {
Element element = (Element) it.next();
//未知属性名称情况下
/*Iterator attrIt = element.attributeIterator();
while (attrIt.hasNext()) {
Attribute a = (Attribute) attrIt.next();
System.out.println(a.getValue());
}*/
//已知属性名称情况下
System.out.println("id: " + element.attributeValue("id"));
//未知元素名情况下
/*Iterator eleIt = element.elementIterator();
while (eleIt.hasNext()) {
Element e = (Element) eleIt.next();
System.out.println(e.getName() + ": " + e.getText());
}
System.out.println();*/
//已知元素名情况下
System.out.println("title: " + element.elementText("title"));
System.out.println("author: " + element.elementText("author"));
System.out.println();
}
}
}
运行结果:
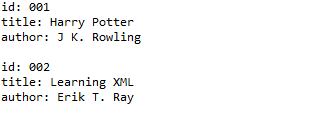
import java.io.File;
import java.io.FileOutputStream;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Demo {
public static void main(String[] args) throws Exception {
Document doc = DocumentHelper.createDocument();
//增加根节点
Element books = doc.addElement("books");
//增加子元素
Element book1 = books.addElement("book");
Element title1 = book1.addElement("title");
Element author1 = book1.addElement("author");
Element book2 = books.addElement("book");
Element title2 = book2.addElement("title");
Element author2 = book2.addElement("author");
//为子节点添加属性
book1.addAttribute("id", "001");
//为元素添加内容
title1.setText("Harry Potter");
author1.setText("J K. Rowling");
book2.addAttribute("id", "002");
title2.setText("Learning XML");
author2.setText("Erik T. Ray");
//实例化输出格式对象
OutputFormat format = OutputFormat.createPrettyPrint();
//设置输出编码
format.setEncoding("UTF-8");
//创建需要写入的File对象
File file = new File("D:" + File.separator + "books.xml");
//生成XMLWriter对象,构造函数中的参数为需要输出的文件流和格式
XMLWriter writer = new XMLWriter(new FileOutputStream(file), format);
//开始写入,write方法中包含上面创建的Document对象
writer.write(doc);
}
}
运行结果:

相关推荐
-

java中使用sax解析xml的解决方法
在java中,原生解析xml文档的方式有两种,分别是:Dom解析和Sax解析 Dom解析功能强大,可增删改查,操作时会将xml文档以文档对象的方式读取到内存中,因此适用于小文档 Sax解析是从头到尾逐行逐个元素读取内容,修改较为不便,但适用于只读的大文档 本文主要讲解Sax解析,其余放在后面 Sax采用事件驱动的方式解析文档.简单点说,如同在电影院看电影一样,从头到尾看一遍就完了,不能回退(Dom可来来回回读取) 在看电影的过程中,每遇到一个情节,一段泪水,一次擦肩,你都会调动大脑和神经去接收或
-
java dom4j解析xml用到的几个方法
1. 读取并解析XML文档: 复制代码 代码如下: SAXReader reader = new SAXReader(); Document document = reader.read(new File(fileName)); reader的read方法是重载的,可以从InputStream, File, Url等多种不同的源来读取.得到的Document对象就带表了整个XML. 读取的字符编码是按照XML文件头定义的编码来转换.如果遇到乱码问题,注意要把各处的编码名称保持一致即可. 2. 取
-
java解析XML几种方式小结
java解析XML几种方式小结 第一种:DOM. DOM的全称是Document Object Model,也即文档对象模型.在应用程序中,基于DOM的XML分析器将一个XML文档转换成一个对象模型的集合(通常称DOM树),应用程序正是通过对这个对象模型的操作,来实现对XML文档数据的操作.通过DOM接口,应用程序可以在任何时候访问XML文档中的任何一部分数据,因此,这种利用DOM接口的机制也被称作随机访问机制. DOM接口提供了一种通过分层对象模型来访问XML文档信息的方式,这些分层对象模型依
-
java解析xml常用的几种方式总结
各种方法都用过.现在总结一下. 经常记不住,要找资料.现在总结一下. xml 文件如下: 复制代码 代码如下: <?xml version="1.0" encoding="ISO-8859-1"?><bookstore><book category="COOKING"> <title lang="en">Everyday Italian</title> <a
-
Java中对XML的解析详解
先简单说下前三种方式: DOM方式:个人理解类似.net的XmlDocument,解析的时候效率不高,占用内存,不适合大XML的解析: SAX方式:基于事件的解析,当解析到xml的某个部分的时候,会触发特定事件,可以在自定义的解析类中定义当事件触发时要做得事情:个人感觉一种很另类的方式,不知道.Net体系下是否有没有类似的方式? StAX方式:个人理解类似.net的XmlReader方式,效率高,占用内存少,适用大XML的解析: 不过SAX方式之前也用过,本文主要介绍JAXB,这里只贴下主要代码
-
Java生成和解析XML格式文件和字符串的实例代码
1.基础知识: Java解析XML一般有四种方法:DOM.SAX.JDOM.DOM4J. 2.使用介绍 1).DOM (1)简介 由W3C(org.w3c.dom)提供的接口,它将整个XML文档读入内存,构建一个DOM树来对各个节点(Node)进行操作.优点就是整个文档都一直在内存中,我们可以随时访问任何节点,并且对树的遍历也是比较熟悉的操作:缺点则是耗内存,并且必须等到所有的文档都读入内存才能进行处理. (2)示例代码: 复制代码 代码如下: <?xml version="1.0&quo
-
java使用xpath和dom4j解析xml
1 XML文件解析的4种方法 通常解析XML文件有四种经典的方法.基本的解析方式有两种,一种叫SAX,另一种叫DOM.SAX是基于事件流的解析,DOM是基于XML文档树结构的解析.在此基础上,为了减少DOM.SAX的编码量,出现了JDOM,其优点是,20-80原则(帕累托法则),极大减少了代码量.通常情况下JDOM使用时满足要实现的功能简单,如解析.创建等要求.但在底层,JDOM还是使用SAX(最常用).DOM.Xanan文档.另外一种是DOM4J,是一个非常非常优秀的Java XML API,
-
java使用xpath解析xml示例分享
XPath即为XML路径语言(XML Path Language),它是一种用来确定XML文档中某部分位置的语言.XPath基于XML的树状结构,提供在数据结构树中找寻节点的能力.起初 XPath 的提出的初衷是将其作为一个通用的.介于XPointer与XSL间的语法模型.但是 XPath 很快的被开发者采用来当作小型查询语言. XPathTest.java 复制代码 代码如下: package com.hongyuan.test; import java.io.File;import java
-
java 使用JDOM解析xml文件
JDOM是一个开源项目,它基于树型结构,利用纯JAVA的技术对XML文档实现解析.生成.序列化以及多种操作.JDOM直接为JAVA编程服务.它利用更为强有力的JAVA语言的诸多特性(方法重载.集合概念以及映射),把SAX和DOM的功能有效地结合起来.JDOM的官方地址:http://www.jdom.org/1.首先新建一个接口和2个类,为后续做准备[Moveable.java] 复制代码 代码如下: package com.njupt.zhb.test;public interface Mov
-
Java解析XML的四种方法详解
XML现在已经成为一种通用的数据交换格式,它的平台无关性,语言无关性,系统无关性,给数据集成与交互带来了极大的方便.对于XML本身的语法知识与技术细节,需要阅读相关的技术文献,这里面包括的内容有DOM(Document Object Model),DTD(Document Type Definition),SAX(Simple API for XML),XSD(Xml Schema Definition),XSLT(Extensible Stylesheet Language Transform
-
java实现简单解析XML文件功能示例
本文实例讲述了java实现简单解析XML文件功能.分享给大家供大家参考,具体如下: package demo; import java.io.File; import java.io.IOException; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException;