numpy稀疏矩阵的实现
目录
- 1. coo存储方式
- 2. dok_matrix
- 3. csr和csc存储方式
- 4. lil_matrix
- 5. dia_matrix
- 6. 稀疏矩阵经验
1. coo存储方式
采用三元组(row, col, data)(或称为ijv format)的形式来存储矩阵中非零元素的信息。
coo_matrix的优点:有利于稀疏格式之间的快速转换(tobsr()、tocsr()、to_csc()、to_dia()、to_dok()、to_lil();允许重复项(格式转换的时候自动相加);能与CSR / CSC格式的快速转换
coo_matrix的缺点:不能直接进行算术运算,包括赋值
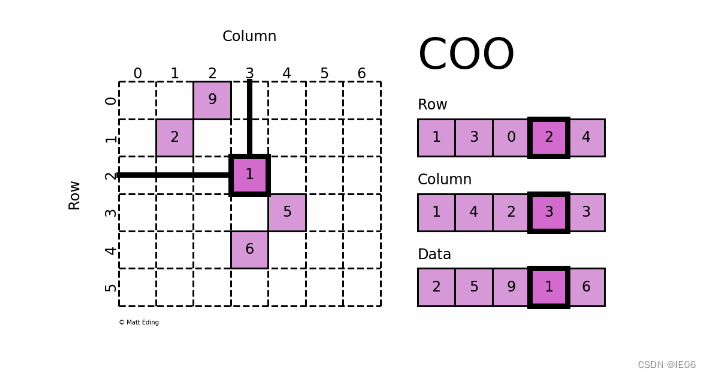
初始化方式:
coo_matrix(D), D代表密集矩阵
赋值:
>>> import numpy as np
>>> from scipy.sparse import coo_matrix
>>> _row = np.array([0, 3, 1, 0])
>>> _col = np.array([0, 3, 1, 2])
>>> _data = np.array([4, 5, 7, 9])
>>> coo = coo_matrix((_data, (_row, _col)), shape=(4, 4), dtype=np.int)
>>> coo.todense() # 通过toarray方法转化成密集矩阵(numpy.matrix)
>>> coo.toarray() # 通过toarray方法转化成密集矩阵(numpy.ndarray)
array([[4, 0, 9, 0],
[0, 7, 0, 0],
[0, 0, 0, 0],
[0, 0, 0, 5]])
2. dok_matrix
dok_matrix,即Dictionary Of Keys based sparse matrix,是一种类似于coo matrix但又基于字典的稀疏矩阵存储方式,key由非零元素的的坐标值tuple(row, column)组成,value则代表数据值。dok matrix非常适合于增量构建稀疏矩阵,并一旦构建,就可以快速地转换为coo_matrix。
>>> import numpy as np
>>> from scipy.sparse import dok_matrix
>>> np.random.seed(10)
>>> matrix = random(3, 3, format='dok', density=0.4)
>>> matrix[1, 1] = 33
>>> matrix[2, 1] = 10
>>> matrix.toarray()
array([[ 0. , 0. , 0. ],
[ 0. , 33. , 0. ],
[ 0.19806286, 10. , 0.22479665]])
>>> dict(matrix)
{(2, 0): 0.19806286475962398, (2, 1): 10.0, (2, 2): 0.22479664553084766, (1, 1): 33.0}
>>> isinstance(matrix, dict)
True
3. csr和csc存储方式
csr_matrix,全称Compressed Sparse Row matrix,即按行压缩的稀疏矩阵存储方式,由三个一维数组indptr, indices, data组成。这种格式要求矩阵元「按行顺序存储」,「每一行中的元素可以乱序存储」。那么对于每一行就只需要用一个指针表示该行元素的起始位置即可。indptr存储每一行数据元素的起始位置,indices这是存储每行中数据的列号,与data中的元素一一对应。
csr_matrix,是按列压缩,不再赘述
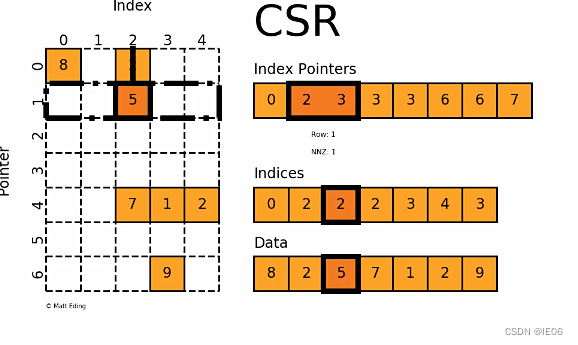
csr_matrix的优点:
高效的算术运算CSR + CSR,CSR * CSR等
高效的行切片
快速矩阵运算
csr_matrix的缺点:
列切片操作比较慢(考虑csc_matrix)
稀疏结构的转换比较慢(考虑lil_matrix或doc_matrix)
>>> import numpy as np
>>> from scipy.sparse import csr_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr = csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]])
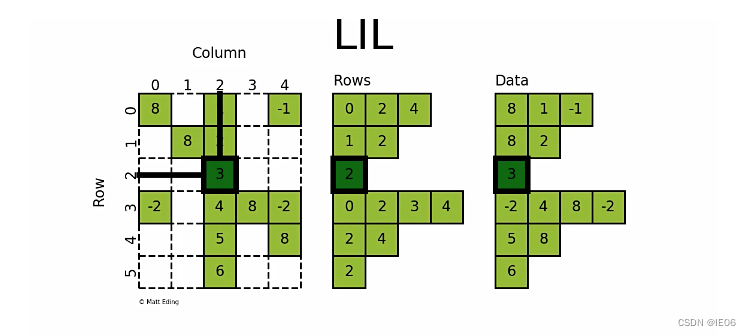
4. lil_matrix
lil_matrix,即List of Lists format,又称为Row-based linked list sparse matrix。它使用两个嵌套列表存储稀疏矩阵:data保存每行中的非零元素的值,rows保存每行非零元素所在的列号(列号是顺序排序的)。
LIL matrix本身的设计是用来方便快捷构建稀疏矩阵实例,而算术运算、矩阵运算则转化成CSC、CSR格式再进行,构建大型的稀疏矩阵还是推荐使用COO格式。
5. dia_matrix
dia_matrix,全称Sparse matrix with DIAgonal storage,是一种对角线的存储方式。如下图中,将稀疏矩阵使用offsets和data两个矩阵来表示。
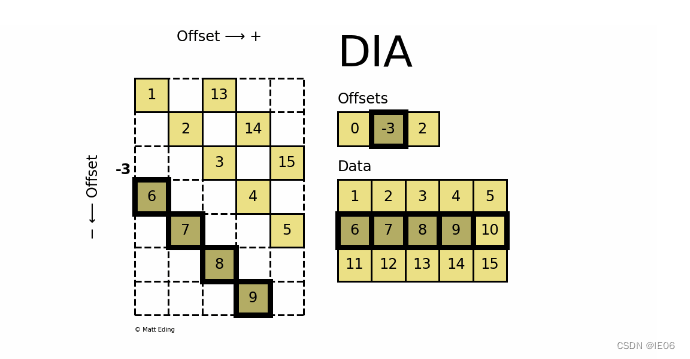
>>> data = np.arange(15).reshape(3, -1) + 1
>>> offsets = np.array([0, -3, 2])
>>> dia = sparse.dia_matrix((data, offsets), shape=(7, 5))
>>> dia.toarray()
array([[ 1, 0, 13, 0, 0],
[ 0, 2, 0, 14, 0],
[ 0, 0, 3, 0, 15],
[ 6, 0, 0, 4, 0],
[ 0, 7, 0, 0, 5],
[ 0, 0, 8, 0, 0],
[ 0, 0, 0, 9, 0]])
6. 稀疏矩阵经验
要有效地构造矩阵,请使用dok_matrix或lil_matrix
lil_matrix类支持基本切片和花式索引,其语法与NumPy Array类似;lil_matrix形式是基于row的,因此能够很高效的转为csr,但是转为csc效率相对较低。
要执行乘法或转置等操作,首先将矩阵转换为CSC或CSR格式,效率高
CSR格式特别适用于快速矩阵矢量产品
CSR,CSC和COO格式之间的所有转换都是线性复杂度。
到此这篇关于numpy稀疏矩阵的实现的文章就介绍到这了,更多相关numpy 稀疏矩阵内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python编程给numpy矩阵添加一列方法示例
首先我们有一个数据是一个mn的numpy矩阵现在我们希望能够进行给他加上一列变成一个m(n+1)的矩阵 import numpy as np a = np.array([[1,2,3],[4,5,6],[7,8,9]]) b = np.ones(3) c = np.array([[1,2,3,1],[4,5,6,1],[7,8,9,1]]) PRint(a) print(b) print(c) [[1 2 3] [4 5 6] [7 8 9]] [ 1. 1. 1.] [[1 2 3 1] [4
-
numpy创建单位矩阵和对角矩阵的实例
在学习linear regression时经常处理的数据一般多是矩阵或者n维向量的数据形式,所以必须对矩阵有一定的认识基础. numpy中创建单位矩阵借助identity()函数.更为准确的说,此函数创建的是一个n*n的单位数组,返回值的dtype=array数据形式.其中接受的参数有两个,第一个是n值大小,第二个为数据类型,一般为浮点型.单位数组的概念与单位矩阵相同,主对角线元素为1,其他元素均为零,等同于单位1.而要想得到单位矩阵,只要用mat()函数将数组转换为矩阵即可. >>>
-
Numpy 将二维图像矩阵转换为一维向量的方法
以下的例子,将32x32的二维矩阵,装换成1x1024的向量 def image2vector (filename): returnVect=zeros((1,1024)) f=open(filename) for i in range (32): lineStr =fr.readline() for j in range (32): returnVect[0,32*i*j]=int(lineStr[j]) return returnVect 以上这篇Numpy 将二维图像矩阵转换为一维向量的方
-
基于Python Numpy的数组array和矩阵matrix详解
NumPy的主要对象是同种元素的多维数组.这是一个所有的元素都是一种类型.通过一个正整数元组索引的元素表格(通常是元素是数字). 在NumPy中维度(dimensions)叫做轴(axes),轴的个数叫做秩(rank,但是和线性代数中的秩不是一样的,在用python求线代中的秩中,我们用numpy包中的linalg.matrix_rank方法计算矩阵的秩,例子如下). 结果是: 线性代数中秩的定义:设在矩阵A中有一个不等于0的r阶子式D,且所有r+1阶子式(如果存在的话)全等于0,那末D称为矩阵
-

Python使用numpy产生正态分布随机数的向量或矩阵操作示例
本文实例讲述了Python使用numpy产生正态分布随机数的向量或矩阵操作.分享给大家供大家参考,具体如下: 简单来说,正态分布(Normal distribution)又名高斯分布(Gaussian distribution),是一个在数学.物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力.一般的正态分布可以通过标准正态分布配合数学期望向量和协方差矩阵得到.如下代码,可以得到满足一维和二维正态分布的样本. 示例1(一维正态分布): # coding=utf-8 '''
-
Numpy 中的矩阵求逆实例
1. 矩阵求逆 import numpy as np a = np.array([[1, 2], [3, 4]]) # 初始化一个非奇异矩阵(数组) print(np.linalg.inv(a)) # 对应于MATLAB中 inv() 函数 # 矩阵对象可以通过 .I 更方便的求逆 A = np.matrix(a) print(A.I) 2. 矩阵求伪逆 import numpy as np # 定义一个奇异阵 A A = np.zeros((4, 4)) A[0, -1] = 1 A[-1,
-
在NumPy中创建空数组/矩阵的方法
如何在NumPy中创建空数组/矩阵? 在添加行的情况下,你最好的选择是创建一个与数据集最终一样大的数组,然后向它添加数据 row-by-row: >>> import numpy >>> a = numpy.zeros(shape=(5,2)) >>> a array([[ 0., 0.], [ 0., 0.], [ 0., 0.], [ 0., 0.], [ 0., 0.]]) >>> a[0] = [1,2] >>&g
-
Python 使用Numpy对矩阵进行转置的方法
如下所示: matrix.py #!/usr/bin/python # -*- encoding:UTF-8-*- import pprint import numpy as np matrix = [[1,2],[3,4],[5,6]] print('列表:') pprint.pprint(matrix) matrix_2 = np.matrix(matrix) print('原矩阵:') pprint.pprint(matrix_2) matrix_transpose = np.transp
-
numpy稀疏矩阵的实现
目录 1. coo存储方式 2. dok_matrix 3. csr和csc存储方式 4. lil_matrix 5. dia_matrix 6. 稀疏矩阵经验 1. coo存储方式 采用三元组(row, col, data)(或称为ijv format)的形式来存储矩阵中非零元素的信息. coo_matrix的优点:有利于稀疏格式之间的快速转换(tobsr().tocsr().to_csc().to_dia().to_dok().to_lil():允许重复项(格式转换的时候自动相加):能与CS
-
Python 稀疏矩阵-sparse 存储和转换
稀疏矩阵-sparsep from scipy import sparse 稀疏矩阵的储存形式 在科学与工程领域中求解线性模型时经常出现许多大型的矩阵,这些矩阵中大部分的元素都为0,被称为稀疏矩阵.用NumPy的ndarray数组保存这样的矩阵,将很浪费内存,由于矩阵的稀疏特性,可以通过只保存非零元素的相关信息,从而节约内存的使用.此外,针对这种特殊结构的矩阵编写运算函数,也可以提高矩阵的运算速度. scipy.sparse库中提供了多种表示稀疏矩阵的格式,每种格式都有不同的用处,其中dok_m
-
Python使用稀疏矩阵节省内存实例
推荐系统中经常需要处理类似user_id, item_id, rating这样的数据,其实就是数学里面的稀疏矩阵,scipy中提供了sparse模块来解决这个问题,但scipy.sparse有很多问题不太合用: 1.不能很好的同时支持data[i, ...].data[..., j].data[i, j]快速切片: 2.由于数据保存在内存中,不能很好的支持海量数据处理. 要支持data[i, ...].data[..., j]的快速切片,需要i或者j的数据集中存储:同时,为了保存海量的数据,也需
-
python实现稀疏矩阵示例代码
工程实践中,多数情况下,大矩阵一般都为稀疏矩阵,所以如何处理稀疏矩阵在实际中就非常重要.本文以Python里中的实现为例,首先来探讨一下稀疏矩阵是如何存储表示的. 1.sparse模块初探 python中scipy模块中,有一个模块叫sparse模块,就是专门为了解决稀疏矩阵而生.本文的大部分内容,其实就是基于sparse模块而来的. 第一步自然就是导入sparse模块 >>> from scipy import sparse 然后help一把,先来看个大概 >>> h
-
numpy中的meshgrid函数的使用
numpy官方文档meshgrid函数帮助文档https://docs.scipy.org/doc/numpy/reference/generated/numpy.meshgrid.html meshgrid(*xi, **kwargs) 功能:从一个坐标向量中返回一个坐标矩阵 参数: x1,x2...,xn:数组,一维的数组代表网格的坐标. indexing:{'xy','ij'},笛卡尔坐标'xy'或矩阵'ij'下标作为输出,默认的是笛卡尔坐标. sparse:bool类型,如果为True,
-
Numpy中对向量、矩阵的使用详解
在下面的代码里面,我们利用numpy和scipy做了很多工作,每一行都有注释,讲解了对应的向量/矩阵操作. 归纳一下,下面的代码主要做了这些事: 创建一个向量 创建一个矩阵 创建一个稀疏矩阵 选择元素 展示一个矩阵的属性 对多个元素同时应用某种操作 找到最大值和最小值 计算平均值.方差和标准差 矩阵变形 转置向量或矩阵 展开一个矩阵 计算矩阵的秩 计算行列式 获取矩阵的对角线元素 计算矩阵的迹 计算特征值和特征向量 计算点积 矩阵的相加相减 矩阵的乘法 计算矩阵的逆 一起来看代码吧: # 加载n
-
Python稀疏矩阵及参数保存代码实现
1. 稀疏矩阵的建立:coo_matrix() from scipy.sparse import coo_matrix # 建立稀疏矩阵 data = [1,2,3,4] row = [3,6,8,2] col = [0,7,4,9] c = coo_matrix((data,(row,col)),shape=(10,10)) #构建10*10的稀疏矩阵,其中不为0的值和位置在第一个参数 print(c) 2. 稀疏矩阵转化为密集矩阵:todense() d = c.todense() prin
-
python scipy 稀疏矩阵的使用说明
稀疏矩阵格式 coo_matrix coo_matrix 是最简单的稀疏矩阵存储方式,采用三元组(row, col, data)(或称为ijv format)的形式来存储矩阵中非零元素的信息. 在实际使用中,一般coo_matrix用来创建矩阵,因为coo_matrix无法对矩阵的元素进行增删改操作:创建成功之后可以转化成其他格式的稀疏矩阵(如csr_matrix.csc_matrix)进行转置.矩阵乘法等操作. coo_matrix可以通过四种方式实例化,除了可以通过coo_matrix(D)
-
Python中Numpy和Matplotlib的基本使用指南
目录 1. Jupyter Notebooks 2. NumPy 数组 3. SciPy 稀疏数组 4. Matplotlib 总结 1. Jupyter Notebooks 作为小白,我现在使用的python编辑器是Jupyter Notebook,非常的好用,推荐!!! 你可以按[Ctrl] + [Enter]快捷键或按菜单中的运行按钮来运行单元格. 在function(后面按[shift] + [tab],可以获得函数或对象的帮助. 你还可以通过执行function?获得帮助. 2. Nu
-
python数学建模(SciPy+ Numpy+Pandas)
目录 前言 SciPy 学习 SciPy基本操作 1-求解非线性方程(组) 2-积分 3-最小二乘解 4-最大模特征值及对应的特征向量 Numpy学习(续) 1 Numpy 数学函数 1-1三角函数 2-舍入函数 2-1 numpy.around() 2-2 numpy.floor() 2-3 numpy.ceil() 3 Numpy算术函数 Pandas学习(续) Pandas 数据排序 DataFrame的排序 Pandas字符串处理 前言 SciPy 是一个开源的 Python 算法库和数