Python实现随机森林回归与各自变量重要性分析与排序
目录
- 1 代码分段讲解
- 1.1 模块与数据准备
- 1.2 特征与标签分离
- 1.3 RF模型构建、训练与预测
- 1.4 预测图像绘制、精度衡量指标计算与保存
- 1.5 决策树可视化
- 1.6 变量重要性分析
- 2 完整代码
本文介绍在Python环境中,实现随机森林(Random Forest,RF)回归与各自变量重要性分析与排序的过程。
其中,关于基于MATLAB实现同样过程的代码与实战,大家可以点击查看MATLAB实现随机森林(RF)回归与自变量影响程度分析这篇文章。
本文分为两部分,第一部分为代码的分段讲解,第二部分为完整代码。
1 代码分段讲解
1.1 模块与数据准备
首先,导入所需要的模块。在这里,需要pydot与graphviz这两个相对不太常用的模块,即使我用了Anaconda,也需要单独下载、安装。具体下载与安装,如果同样是在用Anaconda,大家就参考Python pydot与graphviz库在Anaconda环境的配置即可。
import pydot import numpy as np import pandas as pd import scipy.stats as stats import matplotlib.pyplot as plt from sklearn import metrics from openpyxl import load_workbook from sklearn.tree import export_graphviz from sklearn.ensemble import RandomForestRegressor
接下来,我们将代码接下来需要用的主要变量加以定义。这一部分大家先不用过于在意,浏览一下继续向下看即可;待到对应的变量需要运用时我们自然会理解其具体含义。
train_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Train.csv' test_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Test.csv' write_excel_path='G:/CropYield/03_DL/05_NewML/ParameterResult_ML.xlsx' tree_graph_dot_path='G:/CropYield/03_DL/05_NewML/tree.dot' tree_graph_png_path='G:/CropYield/03_DL/05_NewML/tree.png' random_seed=44 random_forest_seed=np.random.randint(low=1,high=230)
接下来,我们需要导入输入数据。
在这里需要注意,本文对以下两个数据处理的流程并没有详细涉及与讲解(因为在写本文时,我已经做过了同一批数据的深度学习回归,本文就直接用了当时做深度学习时处理好的输入数据,因此以下两个数据处理的基本过程就没有再涉及啦),大家直接查看下方所列出的其它几篇博客即可。
- 初始数据划分训练集与测试集
- 类别变量的独热编码(One-hot Encoding)
针对上述两个数据处理过程,首先,数据训练集与测试集的划分在机器学习、深度学习中是不可或缺的作用,这一部分大家可以查看Python TensorFlow深度学习回归代码:DNNRegressor的2.4部分,或Python TensorFlow深度神经网络回归:keras.Sequential的2.3部分;其次,关于类别变量的独热编码,对于随机森林等传统机器学习方法而言可以说同样是非常重要的,这一部分大家可以查看Python实现类别变量的独热编码(One-hot Encoding)。
在本文中,如前所述,我们直接将已经存在.csv中,已经划分好训练集与测试集且已经对类别变量做好了独热编码之后的数据加以导入。在这里,我所导入的数据第一行是表头,即每一列的名称。关于.csv数据导入的代码详解,大家可以查看多变量两两相互关系联合分布图的Python绘制的数据导入部分。
# Data import
'''
column_name=['EVI0610','EVI0626','EVI0712','EVI0728','EVI0813','EVI0829','EVI0914','EVI0930','EVI1016',
'Lrad06','Lrad07','Lrad08','Lrad09','Lrad10',
'Prec06','Prec07','Prec08','Prec09','Prec10',
'Pres06','Pres07','Pres08','Pres09','Pres10',
'SIF161','SIF177','SIF193','SIF209','SIF225','SIF241','SIF257','SIF273','SIF289',
'Shum06','Shum07','Shum08','Shum09','Shum10',
'Srad06','Srad07','Srad08','Srad09','Srad10',
'Temp06','Temp07','Temp08','Temp09','Temp10',
'Wind06','Wind07','Wind08','Wind09','Wind10',
'Yield']
'''
train_data=pd.read_csv(train_data_path,header=0)
test_data=pd.read_csv(test_data_path,header=0)
1.2 特征与标签分离
特征与标签,换句话说其实就是自变量与因变量。我们要将训练集与测试集中对应的特征与标签分别分离开来。
# Separate independent and dependent variables train_Y=np.array(train_data['Yield']) train_X=train_data.drop(['ID','Yield'],axis=1) train_X_column_name=list(train_X.columns) train_X=np.array(train_X) test_Y=np.array(test_data['Yield']) test_X=test_data.drop(['ID','Yield'],axis=1) test_X=np.array(test_X)
可以看到,直接借助drop就可以将标签'Yield'从原始的数据中剔除(同时还剔除了一个'ID',这个是初始数据的样本编号,后面就没什么用了,因此随着标签一起剔除)。同时在这里,还借助了train_X_column_name这一变量,将每一个特征值列所对应的标题(也就是特征的名称)加以保存,供后续使用。
1.3 RF模型构建、训练与预测
接下来,我们就需要对随机森林模型加以建立,并训练模型,最后再利用测试集加以预测。在这里需要注意,关于随机森林的几个重要超参数(例如下方的n_estimators)都是需要不断尝试找到最优的。关于这些超参数的寻优,在MATLAB中的实现方法大家可以查看MATLAB实现随机森林(RF)回归与自变量影响程度分析的1.1部分;而在Python中的实现方法,我们将在下一篇博客中介绍。
# Build RF regression model random_forest_model=RandomForestRegressor(n_estimators=200,random_state=random_forest_seed) random_forest_model.fit(train_X,train_Y) # Predict test set data random_forest_predict=random_forest_model.predict(test_X) random_forest_error=random_forest_predict-test_Y
其中,利用RandomForestRegressor进行模型的构建,n_estimators就是树的个数,random_state是每一个树利用Bagging策略中的Bootstrap进行抽样(即有放回的袋外随机抽样)时,随机选取样本的随机数种子;fit进行模型的训练,predict进行模型的预测,最后一句就是计算预测的误差。
1.4 预测图像绘制、精度衡量指标计算与保存
首先,进行预测图像绘制,其中包括预测结果的拟合图与误差分布直方图。关于这一部分代码的解释,大家可以查看Python TensorFlow深度学习回归代码:DNNRegressor的2.9部分。
# Draw test plot
plt.figure(1)
plt.clf()
ax=plt.axes(aspect='equal')
plt.scatter(test_Y,random_forest_predict)
plt.xlabel('True Values')
plt.ylabel('Predictions')
Lims=[0,10000]
plt.xlim(Lims)
plt.ylim(Lims)
plt.plot(Lims,Lims)
plt.grid(False)
plt.figure(2)
plt.clf()
plt.hist(random_forest_error,bins=30)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
以上两幅图的绘图结果如下所示。
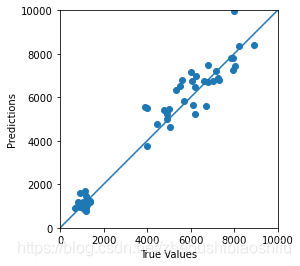

接下来,进行精度衡量指标的计算与保存。在这里,我们用皮尔逊相关系数、决定系数与RMSE作为精度的衡量指标,并将每一次模型运行的精度衡量指标结果保存在一个Excel文件中。这一部分大家同样查看Python TensorFlow深度学习回归代码:DNNRegressor的2.9部分即可。
# Verify the accuracy
random_forest_pearson_r=stats.pearsonr(test_Y,random_forest_predict)
random_forest_R2=metrics.r2_score(test_Y,random_forest_predict)
random_forest_RMSE=metrics.mean_squared_error(test_Y,random_forest_predict)**0.5
print('Pearson correlation coefficient is {0}, and RMSE is {1}.'.format(random_forest_pearson_r[0],
random_forest_RMSE))
# Save key parameters
excel_file=load_workbook(write_excel_path)
excel_all_sheet=excel_file.sheetnames
excel_write_sheet=excel_file[excel_all_sheet[0]]
excel_write_sheet=excel_file.active
max_row=excel_write_sheet.max_row
excel_write_content=[random_forest_pearson_r[0],random_forest_R2,random_forest_RMSE,random_seed,random_forest_seed]
for i in range(len(excel_write_content)):
exec("excel_write_sheet.cell(max_row+1,i+1).value=excel_write_content[i]")
excel_file.save(write_excel_path)
1.5 决策树可视化
这一部分我们借助DOT这一图像描述语言,进行随机森林算法中决策树的绘制。
# Draw decision tree visualizing plot
random_forest_tree=random_forest_model.estimators_[5]
export_graphviz(random_forest_tree,out_file=tree_graph_dot_path,
feature_names=train_X_column_name,rounded=True,precision=1)
(random_forest_graph,)=pydot.graph_from_dot_file(tree_graph_dot_path)
random_forest_graph.write_png(tree_graph_png_path)
其中,estimators_[5]是指整个随机森林算法中的第6棵树(下标是从0开始的),换句话说我们就是从很多的树(具体树的个数就是前面提到的超参数n_estimators)中抽取了找一个来画图,做一个示范。如下图所示。

可以看到,单单是这一棵树就已经非常非常庞大了。我们将上图其中最顶端(也就是最上方的节点——根节点)部分放大,就可以看见每一个节点对应的信息。如下图

在这里提一句,上图根节点中有一个samples=151,但是我的样本总数是315个,为什么这棵树的样本个数不是全部的样本个数呢?
其实这就是随机森林的内涵所在:随机森林的每一棵树的输入数据(也就是该棵树的根节点中的数据),都是随机选取的(也就是上面我们说的利用Bagging策略中的Bootstrap进行随机抽样),最后再将每一棵树的结果聚合起来(聚合这个过程就是Aggregation,我们常说的Bagging其实就是Bootstrap与Aggregation的合称),形成随机森林算法最终的结果。
1.6 变量重要性分析
在这里,我们进行变量重要性的分析,并以图的形式进行可视化。
# Calculate the importance of variables
random_forest_importance=list(random_forest_model.feature_importances_)
random_forest_feature_importance=[(feature,round(importance,8))
for feature, importance in zip(train_X_column_name,random_forest_importance)]
random_forest_feature_importance=sorted(random_forest_feature_importance,key=lambda x:x[1],reverse=True)
plt.figure(3)
plt.clf()
importance_plot_x_values=list(range(len(random_forest_importance)))
plt.bar(importance_plot_x_values,random_forest_importance,orientation='vertical')
plt.xticks(importance_plot_x_values,train_X_column_name,rotation='vertical')
plt.xlabel('Variable')
plt.ylabel('Importance')
plt.title('Variable Importances')
得到图像如下所示。这里是由于我的特征数量(自变量数量)过多,大概有150多个,导致横坐标的标签(也就是自变量的名称)都重叠了;大家一般的自变量个数都不会太多,就不会有问题~

以上就是全部的代码分段介绍~
2 完整代码
# -*- coding: utf-8 -*-
"""
Created on Sun Mar 21 22:05:37 2021
@author: fkxxgis
"""
import pydot
import numpy as np
import pandas as pd
import scipy.stats as stats
import matplotlib.pyplot as plt
from sklearn import metrics
from openpyxl import load_workbook
from sklearn.tree import export_graphviz
from sklearn.ensemble import RandomForestRegressor
# Attention! Data Partition
# Attention! One-Hot Encoding
train_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Train.csv'
test_data_path='G:/CropYield/03_DL/00_Data/AllDataAll_Test.csv'
write_excel_path='G:/CropYield/03_DL/05_NewML/ParameterResult_ML.xlsx'
tree_graph_dot_path='G:/CropYield/03_DL/05_NewML/tree.dot'
tree_graph_png_path='G:/CropYield/03_DL/05_NewML/tree.png'
random_seed=44
random_forest_seed=np.random.randint(low=1,high=230)
# Data import
'''
column_name=['EVI0610','EVI0626','EVI0712','EVI0728','EVI0813','EVI0829','EVI0914','EVI0930','EVI1016',
'Lrad06','Lrad07','Lrad08','Lrad09','Lrad10',
'Prec06','Prec07','Prec08','Prec09','Prec10',
'Pres06','Pres07','Pres08','Pres09','Pres10',
'SIF161','SIF177','SIF193','SIF209','SIF225','SIF241','SIF257','SIF273','SIF289',
'Shum06','Shum07','Shum08','Shum09','Shum10',
'Srad06','Srad07','Srad08','Srad09','Srad10',
'Temp06','Temp07','Temp08','Temp09','Temp10',
'Wind06','Wind07','Wind08','Wind09','Wind10',
'Yield']
'''
train_data=pd.read_csv(train_data_path,header=0)
test_data=pd.read_csv(test_data_path,header=0)
# Separate independent and dependent variables
train_Y=np.array(train_data['Yield'])
train_X=train_data.drop(['ID','Yield'],axis=1)
train_X_column_name=list(train_X.columns)
train_X=np.array(train_X)
test_Y=np.array(test_data['Yield'])
test_X=test_data.drop(['ID','Yield'],axis=1)
test_X=np.array(test_X)
# Build RF regression model
random_forest_model=RandomForestRegressor(n_estimators=200,random_state=random_forest_seed)
random_forest_model.fit(train_X,train_Y)
# Predict test set data
random_forest_predict=random_forest_model.predict(test_X)
random_forest_error=random_forest_predict-test_Y
# Draw test plot
plt.figure(1)
plt.clf()
ax=plt.axes(aspect='equal')
plt.scatter(test_Y,random_forest_predict)
plt.xlabel('True Values')
plt.ylabel('Predictions')
Lims=[0,10000]
plt.xlim(Lims)
plt.ylim(Lims)
plt.plot(Lims,Lims)
plt.grid(False)
plt.figure(2)
plt.clf()
plt.hist(random_forest_error,bins=30)
plt.xlabel('Prediction Error')
plt.ylabel('Count')
plt.grid(False)
# Verify the accuracy
random_forest_pearson_r=stats.pearsonr(test_Y,random_forest_predict)
random_forest_R2=metrics.r2_score(test_Y,random_forest_predict)
random_forest_RMSE=metrics.mean_squared_error(test_Y,random_forest_predict)**0.5
print('Pearson correlation coefficient is {0}, and RMSE is {1}.'.format(random_forest_pearson_r[0],
random_forest_RMSE))
# Save key parameters
excel_file=load_workbook(write_excel_path)
excel_all_sheet=excel_file.sheetnames
excel_write_sheet=excel_file[excel_all_sheet[0]]
excel_write_sheet=excel_file.active
max_row=excel_write_sheet.max_row
excel_write_content=[random_forest_pearson_r[0],random_forest_R2,random_forest_RMSE,random_seed,random_forest_seed]
for i in range(len(excel_write_content)):
exec("excel_write_sheet.cell(max_row+1,i+1).value=excel_write_content[i]")
excel_file.save(write_excel_path)
# Draw decision tree visualizing plot
random_forest_tree=random_forest_model.estimators_[5]
export_graphviz(random_forest_tree,out_file=tree_graph_dot_path,
feature_names=train_X_column_name,rounded=True,precision=1)
(random_forest_graph,)=pydot.graph_from_dot_file(tree_graph_dot_path)
random_forest_graph.write_png(tree_graph_png_path)
# Calculate the importance of variables
random_forest_importance=list(random_forest_model.feature_importances_)
random_forest_feature_importance=[(feature,round(importance,8))
for feature, importance in zip(train_X_column_name,random_forest_importance)]
random_forest_feature_importance=sorted(random_forest_feature_importance,key=lambda x:x[1],reverse=True)
plt.figure(3)
plt.clf()
importance_plot_x_values=list(range(len(random_forest_importance)))
plt.bar(importance_plot_x_values,random_forest_importance,orientation='vertical')
plt.xticks(importance_plot_x_values,train_X_column_name,rotation='vertical')
plt.xlabel('Variable')
plt.ylabel('Importance')
plt.title('Variable Importances')
以上就是Python实现随机森林回归与各自变量重要性分析与排序的详细内容,更多关于Python随机森林的资料请关注我们其它相关文章!
相关推荐
-
python人工智能算法之线性回归实例
目录 线性回归 使用场景 分析: 总结: 线性回归 是一种常见的机器学习算法,也是人工智能中常用的算法.它是一种用于预测数值型输出变量与一个或多个自变量之间线性关系的方法.例如,你可以使用线性回归模型来预测房价,根据房屋的面积.地理位置.周围环境等. 主要思想是通过构建一个线性模型,来描述自变量和输出变量之间的关系.模型可以表示为: y = a0 + a1*x1 + a2*x2 + - + an*xn 其中,y是输出变量(也称为响应变量),x1.x2.….xn是自变量(也称为特征),a0.a1.
-

Python反向传播实现线性回归步骤详细讲解
目录 1. 导入包 2. 生成数据 3. 训练数据 4. 绘制图像 5. 代码 1. 导入包 我们这次的任务是随机生成一些离散的点,然后用直线(y = w *x + b )去拟合 首先看一下我们需要导入的包有 torch 包为我们生成张量,可以使用反向传播 matplotlib.pyplot 包帮助我们绘制曲线,实现可视化 2. 生成数据 这里我们通过rand随机生成数据,因为生成的数据在0~1之间,这里我们扩大10倍. 我们设置的batch_size,也就是数据的个数为20个,所以这里会产生维
-
如何用Python进行回归分析与相关分析
目录 一.前言 1.1 回归分析 1.2 相关分析 二.代码的编写 2.1 前期准备 2.2 编写代码 2.2.1 相关分析 2.2.2 一元线性回归分析 2.2.3 多元线性回归分析 2.2.4 广义线性回归分析 2.2.5 logistic回归分析 三.代码集合 一.前言 1.1 回归分析 是用于研究分析某一变量受其他变量影响的分析方法,其基本思想是以被影响变量为因变量,以影响变量为自变量,研究因变量与自变量之间的因果关系. 1.2 相关分析 不考虑变量之间的因果关系而只研究变量之间的相关关
-
Python数据分析之双色球基于线性回归算法预测下期中奖结果示例
本文实例讲述了Python数据分析之双色球基于线性回归算法预测下期中奖结果.分享给大家供大家参考,具体如下: 前面讲述了关于双色球的各种算法,这里将进行下期双色球号码的预测,想想有些小激动啊. 代码中使用了线性回归算法,这个场景使用这个算法,预测效果一般,各位可以考虑使用其他算法尝试结果. 发现之前有很多代码都是重复的工作,为了让代码看的更优雅,定义了函数,去调用,顿时高大上了 #!/usr/bin/python # -*- coding:UTF-8 -*- #导入需要的包 import pan
-
Python利用keras接口实现深度神经网络回归
目录 1 写在前面 2 代码分解介绍 2.1 准备工作 2.2 参数配置 2.3 数据导入与数据划分 2.4 联合分布图绘制 2.5 因变量分离与数据标准化 2.6 原有模型删除 2.7 最优Epoch保存与读取 2.8 模型构建 2.9 训练图像绘制 2.10 最优Epoch选取 2.11 模型测试.拟合图像绘制.精度验证与模型参数与结果保存 3 完整代码 1 写在前面 前期一篇文章Python TensorFlow深度学习回归代码:DNNRegressor详细介绍了基于TensorFlow
-
Python基于TensorFlow接口实现深度学习神经网络回归
目录 1 写在前面 2 代码分解介绍 2.1 准备工作 2.2 参数配置 2.3 原有模型删除 2.4 数据导入与数据划分 2.5 Feature Columns定义 2.6 模型优化方法构建与模型结构构建 2.7 模型训练 2.8 模型验证与测试 2.9 精度评定.拟合图像绘制与模型参数与精度结果保存 3 详细代码 1 写在前面 1. 本文介绍的是基于TensorFlow tf.estimator接口的深度学习网络,而非TensorFlow 2.0中常用的Keras接口:关于Keras接口实现
-
python数据分析之线性回归选择基金
目录 1 前言 2 基金趋势分析 3 数据抓取与分析 3.1 基金数据抓取 3.2 数据分析 4 总结 1 前言 在前面的章节中我们牛刀小试,一直在使用python爬虫去抓取数据,然后把数据信息存放在数据库中,至此已经完成了基本的基本信息的处理,接下来就来处理高级一点儿的内容,今天就从基金的趋势分析开始. 2 基金趋势分析 基金的趋势,就是选择一些表现强势的基金,什么样的才是强势呢?那就是要稳定的,逐步的一路北上.通常情况下,基金都会沿着一条趋势线向上或者向下,基金的趋势形成比股票的趋势更加确定
-
用Python实现随机森林算法的示例
拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩写)算法从训练数据的样本中建立复合模型,可以有效降低决策树的方差,但树与树之间有高度关联(并不是理想的树的状态). 随机森林算法(Random forest algorithm)是对 bagging 算法的扩展.除了仍然根据从训练数据样本建立复合模型之外,随机森林对用做构建树(tree)的数据特征做了一定限制,使得生成的决策树之间没有关联,
-
Python实现随机森林RF模型超参数的优化详解
目录 1 代码分段讲解 1.1 数据与模型准备 1.2 超参数范围给定 1.3 超参数随机匹配择优 1.4 超参数遍历匹配择优 1.5 模型运行与精度评定 2 完整代码 本文介绍基于Python的随机森林(Random Forest,RF)回归代码,以及模型超参数(包括决策树个数与最大深度.最小分离样本数.最小叶子节点样本数.最大分离特征数等)自动优化的代码. 本文是在上一篇文章Python实现随机森林RF并对比自变量的重要性的基础上完成的,因此本次仅对随机森林模型超参数自动择优部分的代码加以详
-
python实现随机森林random forest的原理及方法
引言 想通过随机森林来获取数据的主要特征 1.理论 随机森林是一个高度灵活的机器学习方法,拥有广泛的应用前景,从市场营销到医疗保健保险. 既可以用来做市场营销模拟的建模,统计客户来源,保留和流失.也可用来预测疾病的风险和病患者的易感性. 根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系,可同时生成的并行化方法: 前者的代表是Boosting,后者的代表是Bagging和"随机森林"(
-
python实现决策树、随机森林的简单原理
本文申明:此文为学习记录过程,中间多处引用大师讲义和内容. 一.概念 决策树(Decision Tree)是一种简单但是广泛使用的分类器.通过训练数据构建决策树,可以高效的对未知的数据进行分类.决策数有两大优点:1)决策树模型可以读性好,具有描述性,有助于人工分析:2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度. 看了一遍概念后,我们先从一个简单的案例开始,如下图我们样本: 对于上面的样本数据,根据不同特征值我们最后是选择是否约会,我们先自定义的一个决策树
-
Python决策树和随机森林算法实例详解
本文实例讲述了Python决策树和随机森林算法.分享给大家供大家参考,具体如下: 决策树和随机森林都是常用的分类算法,它们的判断逻辑和人的思维方式非常类似,人们常常在遇到多个条件组合问题的时候,也通常可以画出一颗决策树来帮助决策判断.本文简要介绍了决策树和随机森林的算法以及实现,并使用随机森林算法和决策树算法来检测FTP暴力破解和POP3暴力破解,详细代码可以参考: https://github.com/traviszeng/MLWithWebSecurity 决策树算法 决策树表现了对象属性和
-
Python实现孤立随机森林算法的示例代码
目录 1 简介 2 孤立随机森林算法 2.1 算法概述 2.2 原理介绍 2.3 算法步骤 3 参数讲解 4 Python代码实现 5 结果 1 简介 孤立森林(isolation Forest)是一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或基尼指数来选择. 2 孤立随机森林算法 2.1 算法概述 Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好
-
java实现随机森林RandomForest的示例代码
随机森林是由多棵树组成的分类或回归方法.主要思想来源于Bagging算法,Bagging技术思想主要是给定一弱分类器及训练集,让该学习算法训练多轮,每轮的训练集由原始训练集中有放回的随机抽取,大小一般跟原始训练集相当,这样依次训练多个弱分类器,最终的分类由这些弱分类器组合,对于分类问题一般采用多数投票法,对于回归问题一般采用简单平均法.随机森林在bagging的基础上,每个弱分类器都是决策树,决策树的生成过程中中,在属性的选择上增加了依一定概率选择属性,在这些属性中选择最佳属性及分割点,传统做法
-
Python模拟随机游走图形效果示例
本文实例讲述了Python模拟随机游走图形效果.分享给大家供大家参考,具体如下: 在python中,可以利用数组操作来模拟随机游走. 下面是一个单一的200步随机游走的例子,从0开始,步长为1和-1,且以相等的概率出现.纯Python方式实现,使用了内建的 random 模块: # 随机游走 import matplotlib.pyplot as plt import random position = 0 walk = [position] steps = 200 for i in range
-
Python实现的随机森林算法与简单总结
本文实例讲述了Python实现的随机森林算法.分享给大家供大家参考,具体如下: 随机森林是数据挖掘中非常常用的分类预测算法,以分类或回归的决策树为基分类器.算法的一些基本要点: *对大小为m的数据集进行样本量同样为m的有放回抽样: *对K个特征进行随机抽样,形成特征的子集,样本量的确定方法可以有平方根.自然对数等: *每棵树完全生成,不进行剪枝: *每个样本的预测结果由每棵树的预测投票生成(回归的时候,即各棵树的叶节点的平均) 著名的python机器学习包scikit learn的文档对此算法有
-
python机器学习之随机森林(七)
机器学习之随机森林,供大家参考,具体内容如下 1.Bootstraping(自助法) 名字来自成语"pull up by your own bootstraps",意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法.其核心思想和基本步骤如下: (1) 采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样. (2) 根据抽出的样本计算给定的统计量T. (3) 重复上述N次(一般大于100