一文带你了解Rust是如何处理错误的
目录
- 异常的演进
- 错误和异常
- 不可恢复的错误
- 可恢复的错误
- 自定义错误和问号表达式
- 小结
异常的演进
程序在运行的过程中,总是会不可避免地产生错误,而如何优雅地解决错误,也是语言的设计哲学之一。那么现有的主流语言是怎么处理错误的呢?比如调用一个函数,如果函数执行的时候出错了,那么该怎么处理呢。
C 语言
C 是一门古老的语言,通常会以指针作为参数,在函数内部进行解引用,修改指针指向的值。然后用 1 和 0 代表返回值,如果返回 1,则表示修改成功;返回 0,表示修改失败。
但这种做法有一个缺陷,就是修改失败时,无法将原因记录下来。
C++ 和 Python
引入了 Exception,通过 try catch 可以将异常捕获,相比 C 进步了一些。但它的缺陷是我们不知道被调用方会抛出什么异常。
Java
引入了 checked exception,方法的所有者可以声明自己会抛出什么异常,然后调用者对异常进行处理。在 Java 程序启动时,抛出大量异常都是司空见惯的事情,并在相应的调用堆栈中将信息完整地记录下来。至此,Java 的异常不再是异常,而是一种很普遍的结构,从良性到灾难性都有所使用,异常的严重性由调用者来决定。
而像 Go、Rust 这样的新兴语言,则采用了与之不同的方式。它们没有像传统的高级语言一样引入 try cache,因为设计者认为这会把控制流搞得非常乱。在 Go 和 Rust 里面,错误是通过返回值体现的。
比如打开一个文件,如果文件不存在,像 Python 程序就会直接报错。但 Go 不一样,Go 在打开文件的时候会同时返回一个文件句柄和 error,如果文件成功打开,那么 error 就是空;如果文件打开失败,那么 error 就是错误原因。
所以对于 Go 而言,在可能出错的时候,程序会同时返回 value 和 error。如果你要使用 value,那么必须先对 error 进行判断。
错误和异常
我们上面提到了错误(Error)和异常(Exception),有很多人分不清这两者的区别,我们来解释一下。
在 Python 里面很少会对错误和异常进行区分,甚至将它们视做同一种概念。但在 Go 和 Rust 里面,错误和异常是完全不同的,异常要比错误严重得多。
当出现错误时,开发者是有能力解决的,比如文件不存在。这时候程序并不会有异常产生,而是正常执行,只是作为返回值的 error 不为空,开发者要基于 error 进行下一步处理。
但如果出现了异常,那么一定是代码写错了,开发者无法处理了。比如索引越界,程序会直接 panic 掉,所以在 Rust 里面异常又叫做不可恢复的错误。
不可恢复的错误
如果在 Rust 里面出现了异常,也就是不可恢复的错误,那么就表示开发者希望程序立刻中止掉,不要再执行下去了。
而不可恢复的错误,除了程序在运行过程中因为某些原因自然产生之外,也可以手动引发。
fn main() {
println!("程序开始执行");
// 在 Go 里面引发异常通过 panic 函数
// Rust 则是通过 panic! 宏,还是挺相似的
panic!("发生了不可恢复的错误");
println!("程序不会执行到这里");
}
注意 panic! 和 println! 的参数一致的,都支持字符串格式化输出。下面看一下输出结果:

如果将环境变量 RUST_BACKTRACE 设置为 1,还可以显示调用栈。
然后除了 panic! 之外,assert 系列的宏也可以生成不可恢复的错误。
fn main() {
// 如果 assert! 里面的布尔值为真,无事发生
// 如果为假,那么程序会 panic 掉
assert!(1 == 2);
// assert!(1 == 2) 还可以写成
assert_eq!(1, 2);
// 除了 assert_eq! 外,还有 assert_ne!
assert_ne!(1, 2);
// 不过最常用的还是 assert!
}
还有一个宏叫 unimplemented!,当我们的代码还没有开发完毕时,为了在别人调用的时候能够提示调用者,便可以使用这个宏。
fn get_data() {
unimplemented!("还没开发完毕,by {}", "古明地觉");
}
fn main() {
get_data()
}

它和 Python 里的 raise NotImplementedError 是比较相似的。
最后在 Rust 里面还有一个常用的宏,用于表示程序不可能执行到某个地方。
fn divide_by_3(n: u32) -> u32 {
// 找到可以满足 3 * i 大于 n 的最小整数 i
for i in 0 .. {
if 3 * i > n {
return i;
}
}
// 显然程序不可能执行到这里
// 因为 for 循环是无限进行的,最终一定会 return
// 但 Rust 在编译时,从语法上是判断不出来的
// 它只知道这个函数目前不完整,因为如果 for 循环结束,
// 那么返回值就不符合 u32 类型了,尽管我们知道 for 循环不可能结束
// 为此我们可以随便 return 一个 u32,并写上注释
// "此处是为了保证函数签名合法,但程序不会执行到这里"
// 而更专业的做法是使用一个宏
unreachable!("程序不可能执行到这里");
}
如果程序真的执行到了该宏所在的地方,那么同样会触发一个不可恢复的错误。
以上就是 Rust 里面的几个用于创建不可恢复的错误的几个宏。
可恢复的错误
说完了不可恢复的错误,再来看看可恢复的错误,一般称之为错误。在 Go 里面错误是通过多返回值实现的,如果程序可能出现错误,那么会多返回一个 error,然后根据 error 是否为空来判断究竟有没有产生错误。所以开发者必须先对 error 进行处理,然后才可以执行下一步,不应该对 error 进行假设。
而 Rust 的错误机制和 Go 类似,只不过是通过枚举实现的,该枚举叫 Result,我们看一下它的定义。
pub enum Result<T, E> {
Ok(T),
Err(E),
}
如果将定义简化一下,那么就是这个样子。可以看到它就是一个简单的枚举,并且带有两个泛型。我们之前也介绍过一个枚举叫 Option,用来处理空值的,内部有两个成员,分别是 Some 和 None。
然后枚举 Result 和 Option 一样,它和内部的成员都是可以直接拿来用的,我们实际举个例子演示一下吧。
// 计算两个 i32 的商
fn divide(a: i32, b: i32) -> Result<i32, &'static str> {
let ret: Result<i32, &'static str>;
// 如果 b != 0,返回 Ok(a / b)
if b != 0 {
ret = Ok(a / b);
} else {
// 否则返回除零错误
ret = Err("ZeroDivisionError: division by zero")
}
return ret;
}
fn main() {
let a = divide(100, 20);
println!("a = {:?}", a);
let b = divide(100, 0);
println!("b = {:?}", b);
/*
a = Ok(5)
b = Err("ZeroDivisionError: division by zero")
*/
}
打印结果如我们所料,但 Rust 和 Go 一样,都要求我们提前对 error 进行处理,并且 Rust 比 Go 更加严格。对于 Go 而言,在没有发生错误的时候,即使我们不对 error 做处理(不推荐),也是没问题的。而 Rust 不管会不会发生错误,都要求对 error 进行处理。
因为 Rust 返回的是枚举,比如上面代码中的 a 是一个 Ok(i32),即便没有发生错误,这个 a 也不能直接用,必须使用 match 表达式处理一下。
fn main() {
// 将返回值和 5 相加,由于 a 是 Ok(i32)
// 显然它不能直接和 i32 相加
let a = divide(100, 20);
match a {
Ok(i) => println!("a + 5 = {}", i + 5),
Err(error) => println!("出错啦: {}", error),
}
let b = divide(100, 0);
match b {
Ok(i) => println!("b + 5 = {}", i + 5),
Err(error) => println!("出错啦: {}", error),
}
/*
a + 5 = 10
出错啦: ZeroDivisionError: division by zero
*/
}
虽然这种编码方式会让人感到有点麻烦,但它杜绝了出现运行时错误的可能。相比运行时报错,我们宁可在编译阶段多费些功夫。
自定义错误和问号表达式
我们说 Rust 为了避免控制流混乱,并没有引入 try cache 语句。但 try cache 也有它的好处,就是可以完整地记录堆栈信息,从错误的根因到出错的地方,都能完整地记录下来,举个 Python 的例子:
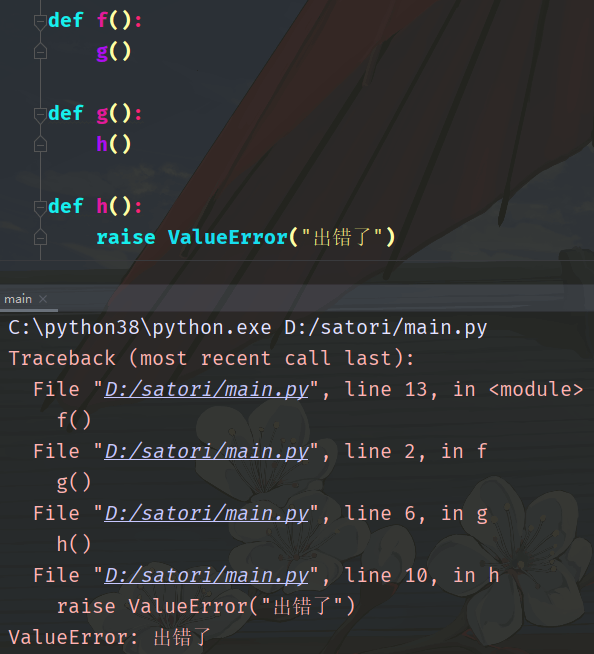
程序报错了,根因是调用了函数 f,而出错的地方是在第 10 行,我们手动 raise 了一个异常。可以看到程序将整个错误的链路全部记录下来了,只要从根因开始一层层往下定位,就能找到错误原因。
而对于 Go 和 Rust 来说就不方便了,特别是 Go,如果每返回一个 error,就打印一次,那么会将 error 打的乱七八糟的。所以我们更倾向于错误能够在上下文当中传递,对于 Rust 而言,我们可以通过问号表达式来实现这一点。
fn external_some_func() -> Result<u32, &'static str> {
// 外部的某个函数
Ok(666)
}
fn call1() -> Result<f64, &'static str> {
// 我们要调用 external_some_func
match external_some_func() {
// 类型转化在 Rust 里面通过 as 关键字
Ok(i) => Ok((i + 1) as f64),
Err(error) => Err(error)
}
}
// 但是上面这种调用方式有点繁琐
// 我们还可以使用问号表达式
fn call2() -> Result<f64, &'static str> {
// 注:使用问号表达式有一个前提
// 调用方和被调用方的返回值都要是 Result 枚举类型
// 并且它们的错误类型要相同,比如这里都是 &'static str
let ret = external_some_func()?;
Ok((ret + 1) as f64)
}
fn main() {
println!("{:?}", call1()); // Ok(667.0)
println!("{:?}", call2()); // Ok(667.0)
}
里面的 call1 和 call2 是等价的,如果在 call2 里面函数调用出错了,那么会自动将错误返回。并且注意 call2 里面的 ret,它是 u32,不是 Ok(u32)。因为函数调用出错会直接返回,不出错则会将 Ok 里面的 u32 取出来赋值给 ret。
然后我们说如果 external_some_func 函数执行出错了,那么 call2 就直接将错误返回了,程序不会再往下执行。所以这也侧面要求,call2 和 external_some_func 的返回值类型都是 Result,并且里面的错误类型也要一样,否则函数签名是不合法的。
fn external_some_func() -> Result<u32, &'static str> {
// 外部的某个函数
Err("函数执行出错")
}
fn call1() -> Result<f64, &'static str> {
match external_some_func() {
Ok(i) => Ok((i + 1) as f64),
Err(error) => Err(error)
}
}
fn call2() -> Result<f64, &'static str> {
let ret = external_some_func()?;
Ok((ret + 1) as f64)
}
fn main() {
println!("{:?}", call1()); // Err("函数执行出错")
println!("{:?}", call2()); // Err("函数执行出错")
}
此时错误就自动地在上下文当中传递了,并且还更简洁,只需要在函数调用后面加一个问号即可。
再来考虑一种更复杂的情况,我们在调用函数的时候可能会调用多个函数,而这多个函数的错误类型不一样该怎么办呢?
struct FileNotFoundError {
err: String,
filename: String,
}
struct IndexError {
err: &'static str,
index: u32,
}
fn external_some_func1() -> Result<u32, FileNotFoundError> {
Err(FileNotFoundError {
err: String::from("文件不存在"),
filename: String::from("main.py"),
})
}
fn external_some_func2() -> Result<i32, IndexError> {
Err(IndexError {
err: "索引越界了",
index: 9,
})
}
很多时候,错误并不是一个简单的字符串,因为那样能携带的信息太少。基本上都是一个结构体,文字格式的错误信息只是里面的字段之一,而其它字段则负责描述更加详细的上下文信息。
我们上面有两个函数,是一会儿我们要调用的,但问题是它们返回的错误类型不同,也就是 Result<T, E> 里面的 E 不同。而如果是这种情况的话,问号表达式就会失效,那么我们应该怎么做呢?
// 其它代码不变
#[derive(Debug)]
enum MyError {
Error1(FileNotFoundError),
Error2(IndexError)
}
// 为 MyError 实现 From trait
// 分别是 From<FileNotFoundError> 和 From<IndexError>
impl From<FileNotFoundError> for MyError {
fn from(error: FileNotFoundError) -> MyError {
MyError::Error1(error)
}
}
impl From<IndexError> for MyError {
fn from(error: IndexError) -> MyError {
MyError::Error2(error)
}
}
fn call1() -> Result<i32, MyError>{
// 调用的两个函数、和当前函数返回的错误类型都不相同
// 但是当前函数是合法的,因为 MyError 实现了 From trait
// 当错误类型是 FileNotFoundError 或 IndexError 时
// 它们会调用 MyError 实现的 from 方法
// 然后将错误统一转换为 MyError 类型
let x = external_some_func1()?;
let y = external_some_func2()?;
Ok(x as i32 + y)
}
fn call2() -> Result<i32, MyError>{
let y = external_some_func2()?;
let x = external_some_func1()?;
Ok(x as i32 + y)
}
fn main() {
println!("{:?}", call1());
/*
Err(Error1(FileNotFoundError { err: "文件不存在", filename: "main.py" }))
*/
println!("{:?}", call2());
/*
Err(Error2(IndexError { err: "索引越界了", index: 9 }))
*/
}
如果调用的多个函数返回的错误类型相同,那么只需要保证调用方也返回相同的错误类型,即可使用问号表达式。但如果调用的多个函数返回的错误类型不同,那么这个时候调用方就必须使用一个新的错误类型,其数据结构通常为枚举。
而枚举里的成员要包含所有可能发生的错误类型,比如这里的FileNotFoundError和IndexError。然后为枚举实现 From trait,该 trait 带了一个泛型,并且内部定义了一个 from 方法。
我们在实现之后,当出现 FileNotFoundError 和 IndexError 的时候,就会调用 from 方法,转成调用方的 MyError 类型,然后返回。
因此这就是 Rust 处理错误的方式,可能有一些难理解,需要私下多琢磨琢磨。最后再补充一点,我们知道 main 函数应该返回一个空元组,但除了空元组之外,它也可以返回一个 Result。
fn main() -> Result<(), MyError> {
// 如果 call1() 的后面没有加问号
// 那么在调用没有出错的时候,返回的就是 Ok(...)
// 调用出错的时候,返回的就是 Err(...)
// 但不管哪一种,都是 Result<T, E> 类型
println!("{:?}", call1());
// 如果加了 ? 那么就不一样了
// 在调用没出错的时候,会直接将 Ok(...) 里面的值取出来
// 调用出错的时候,当前函数会中止运行,
// 并将被调用方(这里是 call2)的错误作为调用方(这里是 main)的返回值返回
// 此时通过问号表达式,就实现了错误在上下文当中传递
// 所以这也要求被调用方返回的错误类型要和调用方相同
println!("{:?}", call2()?);
// 为了使函数签名合法,这里要返回一个值,直接返回 Ok(()) 即可
// 但上面的 call2()? 是会报错的,所以它下面的代码都不会执行
Ok(())
}
我们执行一下看看输出:
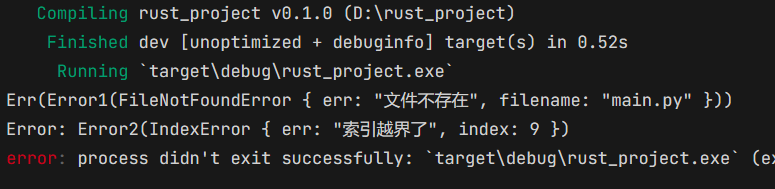
由于 main 函数已经是最顶层的调用方了,所以出错的时候,直接将错误抛出来了。
小结
以上就是 Rust 的错误处理,相比其它语言来说,确实难理解了一些。另外从该系列的开始到现在,我们介绍的都属于基础内容,而且有些地方介绍的还不够详细,后续我们会将这些内容以更深入的方式做一个补充。
到此这篇关于一文带你了解Rust是如何处理错误的的文章就介绍到这了,更多相关Rust处理错误内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
最新Rust错误处理简介
目录 Rust错误处理简介 panic! Result 传播错误 错误处理指导原则 Rust错误处理简介 以下内容总结自 <The Rust Programing Language> Rust并不像C++一样使用try catch的异常机制来进行错误处理,他将错误分为可恢复错误和不可恢复错误两类,主要使用panic!宏和Result<T,E>类型来进行错误处理. panic! panic!用于处理不可恢复的错误(例如类似c中的段错误).当出现 panic 时,程序默认会开始 展开(
-

Rust使用kind进行异常处理(错误的分类与传递|)
目录 前言 1.1.panic! 宏的使用 1.2.通过 Powershell命令行分析错误原因 2.可恢复的错误 2.1.Rustlt<T,E>枚举类的使用 2.2.Result 类的unwrap() 和 expect(message: &str) 方法 3.可恢复的错误的传递 4.结合kind方法处理异常 前言 Rust 有一套独特的处理异常情况的机制,它并不像其它语言中的 try 机制那样简单.在Rust 中的错误分为两大类:可恢复错误和不可恢复错误.大多数编程语言用 Excep
-
一文带你了解Rust是如何处理错误的
目录 异常的演进 错误和异常 不可恢复的错误 可恢复的错误 自定义错误和问号表达式 小结 异常的演进 程序在运行的过程中,总是会不可避免地产生错误,而如何优雅地解决错误,也是语言的设计哲学之一.那么现有的主流语言是怎么处理错误的呢?比如调用一个函数,如果函数执行的时候出错了,那么该怎么处理呢. C 语言 C 是一门古老的语言,通常会以指针作为参数,在函数内部进行解引用,修改指针指向的值.然后用 1 和 0 代表返回值,如果返回 1,则表示修改成功:返回 0,表示修改失败. 但这种做法有一个缺陷,
-
一文带你永久摆脱Mysql时区错误问题(idea数据库可视化插件配置)
目录 项目场景: 问题描述 原因分析 解决方案: 总结 项目场景: 今天在做项目的时候遇到一个关于mysql时区的问题,在这里汇总记录一下解决过程,希望可以帮助到有需要的人. 问题描述 在做项目的时候突然遇到以下的报错,可以看到是说 数据库的时区错误,这里使用的是Mysql 8.0.15数据库. 这里试用了idea提供的数据库可视化插件. 以下报错使得无法访问数据库. org.apache.ibatis.exceptions.PersistenceException: ### Error que
-
一文带你了解CNN(卷积神经网络)
目录 前言 一.CNN解决了什么问题? 二.CNN网络的结构 2.1 卷积层 - 提取特征 卷积运算 权重共享 稀疏连接 总结:标准的卷积操作 卷积的意义 1x1卷积的重大意义 2.2 激活函数 2.3 池化层(下采样) - 数据降维,避免过拟合 2.4 全连接层 - 分类,输出结果 三.Pytorch实现LeNet网络 3.1 模型定义 3.2 模型训练(使用GPU训练) 3.3 训练和评估模型 前言 在学计算机视觉的这段时间里整理了不少的笔记,想着就把这些笔记再重新整理出来,然后写成Bl
-
一文带你弄懂Java中线程池的原理
目录 为什么要用线程池 线程池的原理 ThreadPoolExecutor提供的构造方法 ThreadPoolExecutor的策略 线程池主要的任务处理流程 ThreadPoolExecutor如何做到线程复用的 四种常见的线程池 newCachedThreadPool newFixedThreadPool newSingleThreadExecutor newScheduledThreadPool 小结 在工作中,我们经常使用线程池,但是你真的了解线程池的原理吗?同时,线程池工作原理和底层实
-
一文带你了解 C# DLR 的世界(DLR 探秘)
在很久之前,我写了一片文章详解C# 匿名对象(匿名类型).var.动态类型 dynamic,可以借鉴.因为那时候是心中想当然的认为只有反射能够在运行时解析对象的成员信息并调用成员方法.后来也是因为其他的事一直都没有回过头来把这一节知识给补上,正所谓亡羊补牢,让我们现在来大致了解一下DLR吧. DLR 全称是 Dynamic Language Runtime(动态语言运行时).这很容易让我们想到同在C#中还有一个叫 CLR 的东西,它叫 Common Language Runtime.那这两者有什
-
做java这么久了居然还不知道JSON的使用(一文带你了解)
JSON(JavaScript Object Notation, NS对象标记)是一种轻量级的数据交换格式,目前使用特别广泛. 采用完全独立于编程语言的 文本格式 来存储和表示数据. 简洁和清晰的层次结构使得JSON成为理想的数据交换语言. 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率. 在JavaScript语言中,一切都是对象.因此,任何JavaScript 支持的类型都可以通过JSON来表示,例如字符串.数字.对象.数组等.看看他的要求和语法格式: 对象表示为键值对
-
一文带你入门JDK8新特性——Lambda表达式
Lambda简介 Lambda 表达式是 JDK8 的一个新特性,可以取代大部分的匿名内部类,写出更优雅的 Java 代码,尤其在集合的遍历和其他集合操作中,可以极大地优化代码结构. JDK 也提供了大量的内置函数式接口供我们使用,使得 Lambda 表达式的运用更加方便.高效. 对接口的要求 虽然使用 Lambda 表达式可以对某些接口进行简单的实现,但并不是所有的接口都可以使用 Lambda 表达式来实现.Lambda 规定接口中只能有一个需要被实现的方法,不是规定接口中只能有一个方法 jd
-
一文带你彻底理解Java序列化和反序列化
Java序列化是什么? Java序列化是指把Java对象转换为字节序列的过程,Java反序列化是指把字节序列恢复为Java对象的过程. 反序列化: 客户端重文件,或者网络中获取到文件以后,在内存中重构对象. 序列化: 对象序列化的最重要的作用是传递和保存对象的时候,保证对象的完整性和可传递性.方便字节可以在网络上传输以及保存在本地文件. 为什么需要序列化和反序列化 实现分布式 核心在于RMI,可以利用对象序列化运行远程主机上的服务,实现运行的时候,就像在本地上运行Java对象一样. 实现递归保存
-
一文带你彻底搞懂Lambda表达式
1. 为什么使用Lambda表达式 Lambda是一个匿名函数,我们可以把Lambda表达式理解为是一段可以传递的代码(将代码像数据一样进行传递).可以写出更简洁.更灵活的代码.作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升. 我们来看一下使用lambda之前创建匿名内部类: new Thread(new Runnable() { @Override public void run() { System.out.println("执行Runnable方法"); } });
-
一文带你了解Python 四种常见基础爬虫方法介绍
一.Urllib方法 Urllib是python内置的HTTP请求库 import urllib.request #1.定位抓取的url url='http://www.baidu.com/' #2.向目标url发送请求 response=urllib.request.urlopen(url) #3.读取数据 data=response.read() # print(data) #打印出来的数据有ASCII码 print(data.decode('utf-8')) #decode将相应编码格式的