Python操作Excel神器openpyxl使用教程(超详细!)
目录
- 前言
- 新建并写入文件
- 打开并读取文件
- 工作簿对象
- 工作表对象
- 单元格读取
- 单元格对象
- 单元格样式
- 列宽与行高
- 插入和删除行和列
- 综合写入实践
- 合并表格
- 拆分表格
- 作业提交情况检测
- 总结
前言
openpyxl是Python下的Excel库,它能够很容易的对Excel数据进行读取、写入以及样式的设置,能够帮助我们实现大量的、重复的Excel操作,提高我们的办公效率,实现Excel办公自动化。
- 安装方法:pip install openpyxl
- 中文文档:https://www.osgeo.cn/openpyxl/index.html#usage-examples
- 工作簿、工作表、单元格之间的关系:
- 一个工作簿(workbook)由多个工作表(worksheet)组成;
- 一个工作表有多个单元格(cell)组成;
- 通过行(row)和列(column)可以定位到单元格。
新建并写入文件
Workbook():新建excel文件,新建文件时默认有一个名为Sheet工作表
# coding=utf-8 from openpyxl import Workbook wb = Workbook() # 新建工作簿 ws = wb.active # 获取工作表 ws.append(['姓名', '学号', '年龄']) # 追加一行数据 ws.append(['张三', "1101", 17]) # 追加一行数据 ws.append(['李四', "1102", 18]) # 追加一行数据 wb.save(r'测试1.xlsx') # 保存到指定路径,保存的文件必须不能处于打开状态,因为文件打开后文件只读
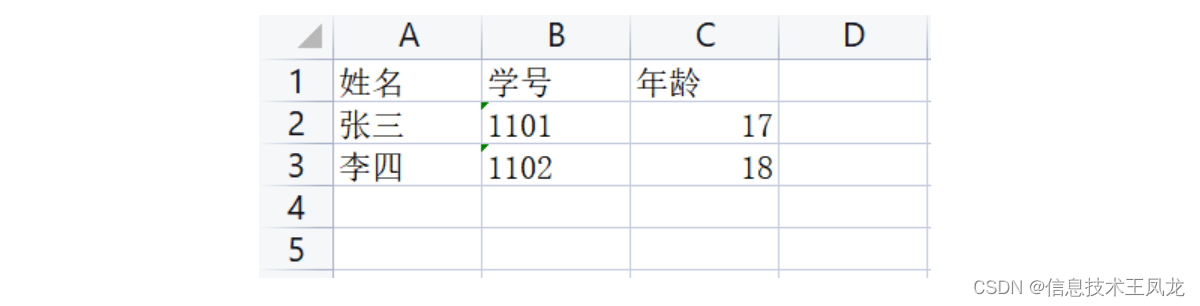
打开并读取文件
load_workbook(path):加载指定路径的excel文件
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active # 获取工作表
for row in ws.values: # 输出所有数据
print(row)

工作簿对象
- wb.active :获取第一张工作表对象
- wb[sheet_name] :获取指定名称的工作表对象
- wb.sheetnames :获取所有工作表名称
- wb.worksheets:获取所有工作表对象,wb.worksheets[0]可以根据索引获取工作表,0代表第一个
- wb.create_sheet(sheet_name,index=“end”):创建并返回一个工作表对象,默认位置最后,0代表第一个
- wb.copy_worksheet(sheet):在当前工作簿复制指定的工作表并返回复制后的工作表对象
- wb.remove(sheet):删除指定的工作表
- ws.save(path):保存到指定路径path的Excel文件中,若文件不存在会新建,若文件存在会覆盖
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r"测试1.xlsx")
"""获取工作表"""
active_sheet = wb.active # 获取第一个工作表
print(active_sheet) # 输出工作表:<Worksheet "Sheet">
by_name_sheet = wb["Sheet"] # 根据工作表名称获取工作表
by_index_sheet = wb.worksheets[0] # 根据工作表索引获取工作表
"""获取所有工作表"""
print("获取所有",wb.sheetnames)
"""新建工作表"""
New_Sheet = wb.create_sheet("New") # 在最后新建工作表
First_Sheet = wb.create_sheet("First",index=0) # 在开头新建工作表
print("新建后",wb.sheetnames)
"""复制工作表"""
Copy_Sheet = wb.copy_worksheet(active_sheet) # 复制第一个工作表
Copy_Sheet.title = "Copy"
print("复制后",wb.sheetnames)
"""删除工作表"""
wb.remove(First_Sheet) # 根据指定的工作表对象删除工作表
wb.remove(New_Sheet)
print("删除后",wb.sheetnames)
wb.save(r"测试2.xlsx")

工作表对象
- ws.title:获取或设置工作表名
- ws.max_row:工作表最大行数
- ws.max_column:工作表最大列数
- ws.append(list):表格末尾追加数据
- ws.merge_cells(‘A2:D2’):合并单元格
- ws.unmerge_cells(‘A2:D2’):解除合并单元格。
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active
print("工作表名",ws.title)
ws.title = "学生信息表"
print("修改后工作表名",ws.title)
print("最大行数",ws.max_row)
print("最大列数",ws.max_column)
ws.append(["王五","1103",17])
print("最大行数",ws.max_row)
wb.save(r"测试3.xlsx")

单元格读取
- ws[‘A1’]:根据坐标获取单个单元格对象
- ws.cell(row, column, value=None):根据行列获取单个单元格对象
- ws[1]:获取第一行所有单元格对象,ws[“1”]也可
- ws[“A”]:获取第A列所有单元格对象
- ws[“A”:“B”]:获取A到B列所有单元格对象,ws[“A:B”]也可
- ws[1:2]:获取1到2行所有单元格对象,ws[“1:2”]也可
- ws[“A1”:“B2”]:获取A1到B2范围所有单元格对象,ws[“A1:B2”]也可。
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx')
ws = wb.active
A1 = ws["A1"] # 根据坐标获取单个单元格
print("第一行第一列",ws.cell(1,1)) # 根据行列获取单个单元格
print("第一行",ws[1])
print("第A列",ws["A"])
print("A到B列",ws["A":"B"])
print("1到2行",ws["1":"2"])
print("A1到B2范围",ws["A1":"B2"])

ws.values:获取所有单元格数据的可迭代对象,可以通过for循环迭代或通过list(ws.values)转换为数据列表
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx') # 获取已存在的工作簿
ws = wb.active # 获取工作表
for row in ws.values: # for循环迭代
print(row)
print(list(ws.values)) # 转换为数据列表

ws.rows:获取所有数据以行的格式组成的可迭代对象
ws.columns:获取所有数据以列的格式组成的可迭代对象
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx')
ws = wb.active
for row in ws.rows: # 以行的形式迭代
print(row)
print("-"*55)
for col in ws.columns: # 以列的形式迭代
print(col)
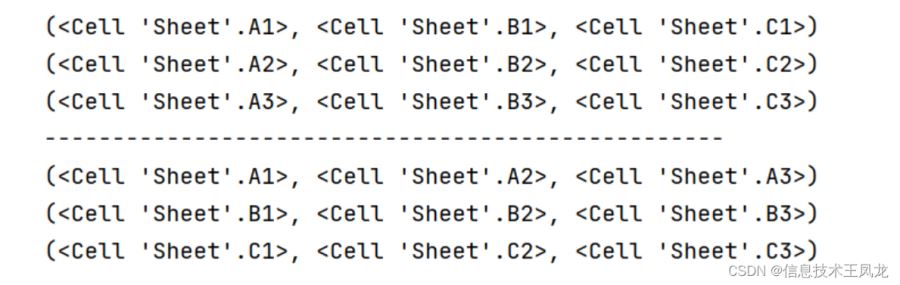
ws.iter_rows(min_row=None, max_row=None, min_col=None, max_col=None):获取指定边界范围并以行的格式组成的可迭代对象,默认所有行
ws.iter_cols(min_col=None, max_col=None, min_row=None, max_row=None): 获取指定边界范围并以列的格式组成的可迭代对象,默认所有列
# coding=utf-8
from openpyxl import load_workbook
wb = load_workbook(r'测试1.xlsx')
ws = wb.active
for row in ws.iter_rows(max_row=2,max_col=2): # 指定边界范围并以行的形式可迭代
print(row)
print("-"*35)
for column in ws.iter_cols(max_row=2,max_col=2): # 指定边界范围并以行的形式可迭代
print(column)

单元格对象
- cell.value :获取或设置值
- cell.column : 数字列标
- cell.column_letter : 字母列标
- cell.row : 行号
- cell.coordinate : 坐标,例如’A1’
- cell.data_type : 数据类型, ’s‘ = string字符串,‘n’ = number数值,会根据单元格值自动判断
- cell.number_format :单元格格式,默认”General“常规,详见excel自定义数据类型
# coding=utf-8
from openpyxl import Workbook
wb = Workbook() # 新建工作簿
ws = wb.active
"""获取与设置单元格值的两种方式"""
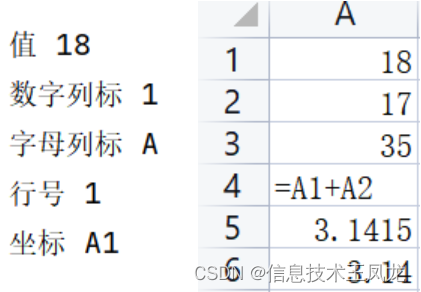
cell1 = ws.cell(1,1) # 先获取第一行第一列的单元格对象
cell1.value = 18 # 再设置单元格对象的值
print("值",cell1.value)
print("数字列标",cell1.column)
print("字母列标",cell1.column_letter)
print("行号",cell1.row)
print("坐标",cell1.coordinate)
cell2 = ws.cell(2,1,17) # 直接在获取单元格的时候设置值
"""使用公式和不适用公式"""
cell3 = ws.cell(3,1,"=A1+A2") # 直接输入公式具有计算功能
cell4 = ws.cell(4,1,"=A1+A2")
cell4.data_type = 's' # 指定单元格数据类型为文本可以避免公式被计算
"""设置格式和不设置格式"""
cell5 = ws.cell(5,1,3.1415) # 默认常规格式
cell6 = ws.cell(6,1,3.1415)
cell6.number_format = "0.00" # 设置格式为保留两位小数
wb.save(r'测试4.xlsx') # 保存到指定路径
单元格样式
- cell.font :获取或设置单元格Font对象 (字体名称,字体大小,是否加粗,字体颜色等)
- cell.border : 获取或设置单元格边框
- cell.alignment : 获取或设置单元格水平/垂直对齐方式
- cell.fill:获取或设置单元格填充颜色
from openpyxl import Workbook
from openpyxl.styles import Font, Border, Side, Alignment,PatternFill
from copy import copy
wb = Workbook()
ws = wb.active
"""获取单元格并设置单元格值为 姓名 """
cell = ws.cell(1,1,"姓名")
"""设置单元格文字样式"""
cell.font = Font(bold=True, # 加粗
italic=True, # 倾斜
name="楷体", # 字体
size=13, # 文字大小
color="FF0000" # 字体颜色为红色
)
"""复制单元格样式"""
cell2 = ws.cell(1,2,"学号")
cell2.font = copy(cell.font)
"""设置单元格边框为黑色边框"""
cell.border = Border(bottom=Side(style='thin', color='000000'),
right=Side(style='thin', color='000000'),
left=Side(style='thin', color='000000'),
top=Side(style='thin', color='000000'))
"""设置单元格对齐方式为水平垂直居中"""
cell.alignment = Alignment(horizontal='center',vertical='center')
"""设置单元格底纹颜色为黄色"""
cell.fill = PatternFill(fill_type='solid', start_color='FFFF00')
"""
白色:FFFFFF,黑色:000000,红色:FF0000,黄色:FFFF00
绿色:00FF00,蓝色:0000FF,橙色:FF9900,灰色:C0C0C0
常见颜色代码表:https://www.osgeo.cn/openpyxl/styles.html#indexed-colours
"""
wb.save(r"测试5.xlsx")

列宽与行高
- ws.row_dimensions[行号]:获取行对象(非行数据,包括行的相关属性、行高等)
- ws.column_dimensions[字母列标]:获取列对象(非行数据,包括行的相关属性、列宽等)
- get_column_letter(index):根据列的索引返回字母
- column_index_from_string(string):根据字母返回列的索引
- row.height:获取或设置行高
- column.width:获取或设置列宽
from openpyxl import Workbook
from openpyxl.utils import get_column_letter,column_index_from_string
wb = Workbook()
ws = wb.active
"""行"""
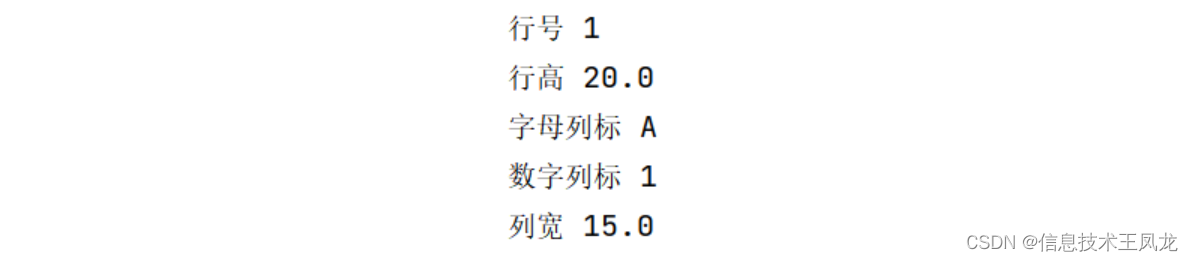
row = ws.row_dimensions[1] # 获取第一行行对象
print("行号",row.index)
row.height = 20 # 设置行高
print("行高",row.height)
"""列"""
column = ws.column_dimensions["A"] # 根据字母列标获取第一列列对象
column = ws.column_dimensions[get_column_letter(1)] # 根据数字列标获取第一列列对象
print("字母列标",column.index)
print("数字列标",column_index_from_string(column.index))
column.width = 15 # 设置列宽
print("列宽",column.width)
wb.save(r'测试6.xlsx')
如何根据输入内容计算其在excel的列宽是多少?
利用GBK编码方式,非汉字字符占1个长度,汉字字符占2个长度
from openpyxl import Workbook
from openpyxl.utils import get_column_letter,column_index_from_string
wb = Workbook()
ws = wb.active
column = ws.column_dimensions[get_column_letter(1)] # 根据数字列标获取第一列列对象
value = "我爱中国ILoveChain" # 4*2+10*1+1=19
column.width = len(str(value).encode("GBK"))+1 # 根据内容设置列宽,+1既可以补充误差又可以让两边留有一定的空白,美观
print("列宽",column.width) # 输出:19
ws.cell(1,1,value)
wb.save(r'测试6.xlsx')

插入和删除行和列
插入和删除行、列均使用数字指定
- ws.insert_rows(row_index,amount=1):在第row_index行上方插入amount列,默认插入1列
- ws.insert_cols(col_index,amount=1):在第col_index列左侧插入amount列,默认插入1列
- ws.delete_rows(row_index,amount=1):从row_index行开始向下删除amount行,默认删除1行
- ws.delete_cols(col_index,amount=1):从col_index列开始向右删除amount行,默认删除1列
from openpyxl import Workbook,load_workbook
wb = load_workbook("测试1.xlsx")
ws = wb.active
ws.insert_rows(1,2) # 在第一行前插入两行
delete_col_index = [1,3] # 删除1、3两列
"""为避免删除多列时前面列对后面列产生影响,采取从后面列往前面列删的策略,行同理"""
delete_col_index.sort(reverse=True) # 从大到小排序
for col_index in delete_col_index:
ws.delete_cols(col_index)
wb.save(r'测试7.xlsx')
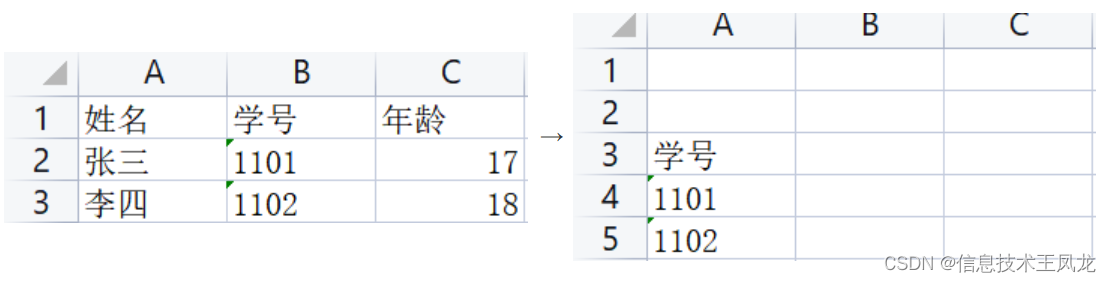
综合写入实践
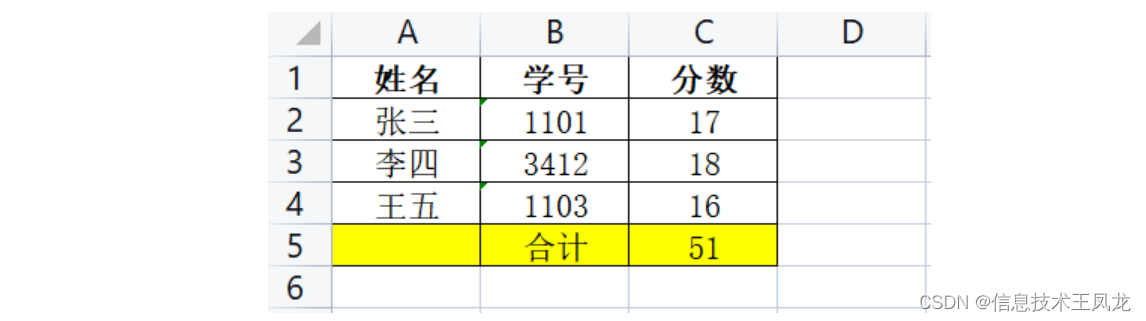
写入后的效果如下:
# coding=utf-8
from openpyxl import Workbook
from openpyxl.styles import Font, Border, Side, Alignment, PatternFill
wb = Workbook()
ws = wb.active
"""设置全局样式"""
border = Border(bottom=Side(style='thin', color='000000'),
right=Side(style='thin', color='000000'),
left=Side(style='thin', color='000000'),
top=Side(style='thin', color='000000'))
alignment = Alignment(horizontal='center', vertical='center')
row_index = 1 # 写入的行索引,每写入一行后+1
"""写入标题"""
title = ['姓名', '学号', '分数']
for index,item in enumerate(title):
cell = ws.cell(row_index,index+1,item)
cell.border = border
cell.alignment = alignment
cell.font = Font(bold=True)
row_index += 1
data = [['张三', "1101", 17],['李四', "3412", 18],['王五', "1103", 16]]
"""写入正文"""
for row in data:
for index,item in enumerate(row):
cell = ws.cell(row_index, index + 1, item)
cell.border = border
cell.alignment = alignment
row_index += 1
"""写入结果"""
result = ["", "合计", 17+18+16]
for index,item in enumerate(result):
cell = ws.cell(row_index,index+1,item)
cell.border = border
cell.alignment = alignment
cell.fill = PatternFill(fill_type='solid', start_color="FFFF00")
wb.save(r"学生信息表.xlsx")
合并表格

# coding=utf-8
from openpyxl import Workbook,load_workbook
import os
dir_path = "学生名单" # 要合并文件的文件夹地址
"""读取文件夹下的所有excel文件"""
files = []
for file in os.listdir(dir_path): # 获取当前目录下的所有文件
files.append(os.path.join(dir_path,file)) # 获取文件夹+文件名的完整路径
"""以第一个文件为基本表"""
merge_excel = load_workbook(files[0])
merge_sheet = merge_excel.active
"""遍历剩余文件,追加到基本表"""
for file in files[1:]:
wb = load_workbook(file)
ws = wb.active
for row in list(ws.values)[1:]: # 从第二行开始读取每一行并追加到基本表
merge_sheet.append(row)
merge_excel.save("高一学生汇总.xlsx")
拆分表格
# coding=utf-8
from openpyxl import Workbook,load_workbook
import os
file_path = "高一学生汇总.xlsx" # 要拆分的文件地址
split_dir = "拆分结果" # 拆分文件后保存的文件夹
group_item = "班级" # 拆分的依据字段
"""打开拆分的excel文件并读取标题"""
wb = load_workbook(file_path)
ws = wb.active
title = []
for cell in ws[1]:
title.append(cell.value)
"""开始分组,分组结果保存到字典,键为班级名,值为班级学生列表"""
group_result = {} # 存储分组结果
group_index = title.index(group_item) # 获取拆分依据字段的索引
for row in list(ws.values)[1:]:
class_name = row[group_index] # 获取分组依据数据,即班级名
if class_name in group_result: # 如果分组存在就追加,不存在就新建
group_result[class_name].append(row)
else:
group_result[class_name] = [row]
"""创建输出文件夹"""
if not os.path.exists(split_dir): # 如果不存在文件夹就新建
os.mkdir(split_dir)
os.chdir(split_dir) # 进入拆分文件夹
"""打印并输出分组后的数据"""
for class_name,students in group_result.items():
new_wb = Workbook() # 新建excel
new_ws = new_wb.active
new_ws.append(title) # 追加标题
for student in students:
new_ws.append(student) # 讲分组数组追加到新excel中
new_wb.save("{}.xlsx".format(class_name))
作业提交情况检测
# encoding: utf-8
import os
from openpyxl import Workbook, load_workbook
excel_path = r"学生名单/高一1班.xlsx" # excel文件路径
job_path = r"作业" # 作业文件夹路径
"""获取姓名列表"""
wb = load_workbook(excel_path)
ws = wb.active
names = []
for cell in ws["C"][1:]: # 获取第C列第2行开始的数据
names.append(cell.value)
"""获取作业列表"""
os.chdir(job_path) # 切换到作业目录
files = [] # 获取文件列表
for file in os.listdir():
files.append(os.path.splitext(file)[0])
"""作业检测"""
yes,no = [],[]
for name in names: # 逐个姓名判断
if name in files: # 判断姓名是否在文件列表中
yes.append(name) # 如果在,添加到已完成名单
else:
no.append(name) # 否则,添加到未完成名单
print("已完成人数:{},已完成名单:{}".format(len(yes),yes))
print("未完成人数:{},未完成名单:{}".format(len(no),no))
总结
到此这篇关于Python操作Excel神器openpyxl使用的文章就介绍到这了,更多相关Python openpyxl使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python操作excel的包(openpyxl、xlsxwriter)
本文为大家分享了python操作excel的包,供大家参考,具体内容如下 现在支持python操作excel的包有下列这些 官网上最推荐的是openpyxl,其他包支持较老的excel版本. xlsxwriter无法对打开的excel进行写操作,excel必须处于关闭状态才能写成功. xlswriter 基本代码: import xlsxwriter workbook = xlsxwriter.Workbook('hello.xlsx') worksheet = workbook.add_wor
-
Python Excel处理库openpyxl使用详解
openpyxl是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装. 读取Excel文件 需要导入相关函数 from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('pythontab.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取工作表--Sheet # 获得所有s
-

python 使用openpyxl读取excel数据
openpyxl介绍 openpyxl是一个开源项目,它是一个用于读取/写入Excel 2010文档(如xlsx .xlsm .xltx .xltm文件 )的Python库,如果要处理更早格式的Excel文档(xls),需要用到其它库(如:xlrd.xlwt等),这是openpyxl比较其他模块的不足之处.openpyxl是一款比较综合的工具,不仅能够同时读取和修改Excel文档,而且可以对Excel文件内单元格进行详细设置,包括单元格样式等内容,甚至还支持图表插入.打印设置等内容. p
-
Python如何实现Excel的最合适列宽(openpyxl)
目录 Excel的最合适列宽(openpyxl) 这是最简单的实现 Python写Excel列宽,行高的一些方法 使用第三方库 xlsxwriter,结果文件格式为xlsx 使用第三方库 xlwt,结果文件格式为xls Excel的最合适列宽(openpyxl) Python的Pandas模块是处理Excel的利器,尤其是加工保存Excel非常方便,但是唯独想让导出的Excel自动调整列宽或者行高,确实做不到啊,尤其是加工后还需要使用者自己调整列宽,非常不便. 所以必须openpyxl模块助力.
-
python使用openpyxl操作excel的方法步骤
一 前言 知识追寻者又要放大招了,学完这篇openpyxl第三方库,读者将会懂得如何灵活的读取excel数据,如何创建excel工作表:更新工作表,删除工作表:是不是感觉很强大,留下赞赞吧!! 二 openpyxl常用属性函数 常用函数或者属性 说明 openpyxl.load_workbook() 加载excel工作本 Workbook.active 获得默认sheet Workbook.create_sheet() 创建sheet Workbook.get_sheet_names() 已过时
-
Python使用openpyxl读写excel文件的方法
这是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装.如果使用Aanconda,应该自带了. 读取Excel文件 需要导入相关函数. from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('mainbuilding33.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取
-
python通过openpyxl生成Excel文件的方法
本文实例讲述了python通过openpyxl生成Excel文件的方法.分享给大家供大家参考.具体如下: 使用前请先安装openpyxl: easy_install openpyxl 通过这个模块可以很方便的导出数据到Excel from openpyxl.workbook import Workbook from openpyxl.writer.excel import ExcelWriter from openpyxl.cell import get_column_letter from o
-
python使用openpyxl库修改excel表格数据方法
1.openpyxl库可以读写xlsx格式的文件,对于xls旧格式的文件只能用xlrd读,xlwt写来完成了. 简单封装类: from openpyxl import load_workbook from openpyxl import Workbook from openpyxl.chart import BarChart, Series, Reference, BarChart3D from openpyxl.styles import Color, Font, Alignment from
-
Python操作Excel神器openpyxl使用教程(超详细!)
目录 前言 新建并写入文件 打开并读取文件 工作簿对象 工作表对象 单元格读取 单元格对象 单元格样式 列宽与行高 插入和删除行和列 综合写入实践 合并表格 拆分表格 作业提交情况检测 总结 前言 openpyxl是Python下的Excel库,它能够很容易的对Excel数据进行读取.写入以及样式的设置,能够帮助我们实现大量的.重复的Excel操作,提高我们的办公效率,实现Excel办公自动化. 安装方法:pip install openpyxl 中文文档:https://www.osgeo.c
-
python操作Excel神器openpyxl看这一篇就够了
目录 Excel xlsx Openpyxl 创建新文件 Openpyxl 写入单元格 Openpyxl 附加值 OpenPyXL 读取单元格 OpenPyXL 读取多个单元格 Openpyxl 按行迭代 Openpyxl 按列迭代 统计 Openpyxl 过滤器&排序数据 Openpyxl 维度 工作表 合并单元格 Openpyxl 冻结窗格 Openpyxl 公式 OpenPyXL 图像 Openpyxl 图表 总结 Excel xlsx 在本教程中,我们使用 xlsx 文件. xlsx 是
-
详解Python操作Excel之openpyxl
目录 Python操作Excel之openpyxl 前提 创建 读取 总结 Python操作Excel之openpyxl openpyxl是一个Python库,用来读写Excel2010 xlsx/xlsm/xltx/xltm类型文件. openpyxl不能操作早期的xls格式的Excel文件,可以使用xlwings等其他库. openpyxl是一个非标准的库,需要自行安装:pip install openpyxl 前提 既然要操作Excel,那么前提我们对Excel要有一个基本的了解,比如:
-
Python 操作 Excel 之 openpyxl 模块
目录 1.打开已有 Excel 文件 2.创建一个 Excel 文件,并修改 sheet 3.选择 sheet 的不同方式 4.Worksheet对象 5.Cell 对象 6.单元格插入图像 7.设置单元格样式 正式开始前依旧是模块的安装,使用如下命令即可实现: pip install openpyxl 官方对于该库的描述是: A Python library to read/write Excel 2010 xlsx/xlsm files 一款用于读写 Excel 2010 xlsx/xlsm
-
C/C++ 开发神器CLion使用入门超详细教程
CLion是Jetbrains公司旗下新推出的一款专为开发C/C++所设计的跨平台IDE,它是以IntelliJ为基础设计的,同时还包含了许多智能功能来提高开发人员的生产力. Clion2020.2.x最新激活码破解版附安装教程(Mac Linux Windows) https://www.jb51.net/article/200548.htm 同样支持python哦,相信使用过IntelliJ idea开发过java的盆友都很清楚该IDE的强大,所以做为Jetbrains旗下的c/c++开发工
-
使用Python操作excel文件的实例代码
使用的类库 pip install openpyxl 操作实现 •工作簿操作 # coding: utf-8 from openpyxl import Workbook # 创建一个excel工作簿 wb = Workbook() # 打开一个工作簿 wb = load_workbook('test.xlsx') # 保存工作簿到文件 wb.save('save.xlsx') •工作表操作 # 获得当前的工作表对象 ws = wb.active # 通过工作表名称得到工作表对象 ws = wb.
-
Python操作Excel插入删除行的方法
1. 前言 由于近期有任务需要,要写一个能够处理Excel的脚本,实现的功能是,在A表格上其中一列,对字符串进行分组和排序,然后根据排序好的A表格以固定格式自动填写到B表格上. 开始写脚本之前查了很多资料,最开始采用了openpyxl这个模块,用起来很顺手,使用这个对A表格其中一列进行了重新填写,但是后来发现,需要用到删除和插入空白行的操作,使用openpyxl比较困难,这个模块仅支持在表格的最后一行继续添加新行,不支持在中间插入和删除行. 在查找的过程中发现,网上流传了一些使用openpyxl
-
python操作excel的方法
摘要: Openpyxl是一个常用的python库,用于对Excel的常用格式及其模板进行数据读写等操作. 简介与安装openpyxl库 Openpyxl is a Python library for reading and writing Excel 2010 xlsx/xlsm/xltx/xltm files. 安装 pip install openpyxl pillow:在文件中需要使用images (jpeg, png, bmp,...)时,需要安装pillow库. 注意:写操作时请关
-
Python操作Excel工作簿的示例代码(\*.xlsx)
前言 Excel 作为流行的个人计算机数据处理软件,混迹于各个领域,在程序员这里也是常常被处理的对象,可以处理 Excel 格式文件的 Python 库还是挺多的,比如 xlrd.xlwt.xlutils.openpyxl.xlwings 等等,但是每个库处理 Excel 的方式不同,有些库在处理时还会有一些局限性. 接下来对比一下几个库的不同,然后主要记录一下 xlwings 这个库的使用,目前这是个人感觉使用起来比较方便的一个库了,其他的几个库在使用过程中总是有这样或那样的问题,不过在特定情