详解MySQL中InnoDB的存储文件
从物理意义上来讲,InnoDB表由共享表空间文件(ibdata1)、独占表空间文件(ibd)、表结构文件(.frm)、以及日志文件(redo文件等)组成。
1、表结构文件
在MYSQL中建立任何一张数据表,在其数据目录对应的数据库目录下都有对应表的.frm文件,.frm文件是用来保存每个数据表的元数据(meta)信息,包括表结构的定义等,.frm文件跟数据库存储引擎无关,也就是任何存储引擎的数据表都必须有.frm文件,命名方式为数据表名.frm,如user.frm. .frm文件可以用来在数据库崩溃时恢复表结构。
2、表空间文件
(1)表空间结构分析
以下为InnoDB的表空间结构图:
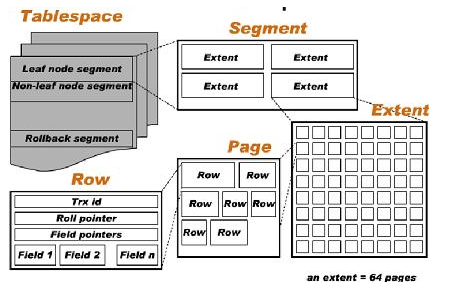
数据段即B+树的叶子节点,索引段即为B+树的非叶子节点InnoDB存储引擎的管理是由引擎本身完成的,表空间(Tablespace)是由分散的段(Segment)组成。一个段(Segment)包含多个区(Extent)。
区(Extent)由64个连续的页(Page)组成,每个页大小为16K,即每个区大小为1MB,创建新表时,先使用32页大小的碎片页存放数据,使用完后才是区的申请(InnoDB最多每次申请4个区,保证数据的顺序性能)
页类型有:数据页、Undo页、系统页、事务数据页、插入缓冲位图页、以及插入缓冲空闲列表页。
(2)独占表空间文件
若将innodb_file_per_table设置为on,则系统将为每一个表单独的生成一个table_name.ibd的文件,在此文件中,存储与该表相关的数据、索引、表的内部数据字典信息。
(3)共享表空间文件
在InnoDB存储引擎中,默认表空间文件是ibdata1(主要存储的是共享表空间数据),初始化为10M,且可以扩展,如下图所示:
实际上,InnoDB的表空间文件是可以修改的,使用以下语句就可以修改:
Innodb_data_file_path=ibdata1:370M;ibdata2:50M:autoextend
使用共享表空间存储方式时,Innodb的所有数据保存在一个单独的表空间里面,而这个表空间可以由很多个文件组成,一个表可以跨多个文件存在,所以其大小限制不再是文件大小的限制,而是其自身的限制。从Innodb的官方文档中可以看到,其表空间的最大限制为64TB,也就是说,Innodb的单表限制基本上也在64TB左右了,当然这个大小是包括这个表的所有索引等其他相关数据。
而在使用单独表空间存储方式时,每个表的数据以一个单独的文件来存放,这个时候的单表限制,又变成文件系统的大小限制了。
以下即为不同平台下,单独表空间文件最大限度。
Operating System File-size Limit
Win32 w/ FAT/FAT32 2GB/4GB
Win32 w/ NTFS 2TB (possibly larger)
Linux 2.4+ (using ext3 file system) 4TB
Solaris 9/10 16TB
MacOS X w/ HFS+ 2TB
NetWare w/NSS file system 8TB
※ 以下是MySQL文档中的内容:
Windows用户请注意: FAT和VFAT (FAT32)不适合MySQL的生产使用。应使用NTFS。
(4)共享表空间与独占表空间
共享表空间以及独占表空间都是针对数据的存储方式而言的。
共享表空间: 某一个数据库的所有的表数据,索引文件全部放在一个文件中,默认这个共享表空间的文件路径在data目录下。 默认的文件名为:ibdata1 初始化为10M。
独占表空间: 每一个表都将会生成以独立的文件方式来进行存储(.ibd文件,这个文件包括了单独一个表的数据内容以及索引内容)。
1)存储内容比较
使用独占表空间之后:
每个表对应的数据、索引和插入缓冲 存放在独占表空间(.idb文件)
每个表对应的撤销(undo)信息,系统事务信息,二次写缓冲等还是存放在了原来的共享表空间内(ibdata1文件)
2)特点比较
具体的共享表空间和独立表空间优缺点如下:
共享表空间:
优点:
可以放表空间分成多个文件存放到各个磁盘上(表空间文件大小不受表大小的限制,如一个表可以分布在不同的文件上)。
数据和文件放在一起方便管理。
缺点:
所有的数据和索引存放到一个文件中,则将有一个很常大的文件,虽然可以把一个大文件分成多个小文件,但是多个表及索引在表空间中混合存储,这样对于一个表做了大量删除操作后表空间中将会有大量的空隙,特别是对于统计分析,日志系统这类应用最不适合用共享表空间。
独立表空间:(在配置文件(my.cnf)中设置 innodb_file_per_table)
优点:
- 每个表都有自已独立的表空间。
- 每个表的数据和索引都会存在自已的表空间中。
- 可以实现单表在不同的数据库中移动。
- 空间可以回收
对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
a)Drop table操作自动回收表空间
b)如果对于统计分析或是日值表,删除大量数据后可以通过:alter table TableName engine=innodb;回缩不用的空间。
c) 对于使innodb-plugin的Innodb使用truncate table也会使空间收缩。
5、在服务器资源有限,单表数据不是特别多的情况下, 独立表空间明显比共享方式效率更高 . 但是MySQL 默认是共享表空间 。
缺点:
单表体积可能过大,如超过100个G。
3)共享表空间以及独占表空间之间的转化
修改独占空表空间配置,配置以下参数
innodb_data_home_dir = "/user/local/mysql/var" 数据库文件所存放的目录
innodb_log_group_home_dir = "/user/local/mysql/var" 日志存放目录
innodb_data_file_path=ibdata1:10M:autoextend 设置配置一个可扩展大小的尺寸为10MB的单独文件(共享数据文件),名为ibdata1。没有给出文件的位置,所以默认的是在MySQL的数据目录内。
innodb_file_per_table=1 是否使用共享还是独占表空间 (1:为使用独占表空间,0:为使用共享表空间)
查看innodb_file_per_table 变量,如果为OFF说明所使用的是共享表空间(默认情况下,所使用的表空间为共享表空间)
对innodb_file_per_table 进行修改时,对于之前使用过的共享表空间不会影响,除非手动的去进行修改
注意:
InnoDB不创建目录,所以在启动服务器之前请确认所配置的路径目录存在。
做数据的移植以及备份时,要注意数据文件的完整性.
相关推荐
-
MySQL启动时InnoDB引擎被禁用了的解决方法
发现问题 今天在工作中,从本地数据库复制表数据到虚拟机 CentOS 6.6 上的数据库时,得到提示: Unknown table engine 'InnoDB' 于是在服务器 MySQL 中查看了引擎: mysql> show engines\G 得到: *************************** 1. row *************************** Engine: MyISAM Support: DEFAULT Comment: MyISAM storage en
-

mysql innodb 异常修复经验分享
一套测试用的mysql库,之前用的centos6默认源里的mysql 5.1.71的版本 .后来想试用下Percona server 5.7,由于这套库里没有什么重要数据 .所以操作前也未进行备份,配置好源后,直接就进行了安装.数据文件也存放在默认位置,安装完成后,直接启动mysql,发现启动失败,发现无法启动正常启动. 一.回退重新装mysql 为避免再从其他地方导入这个数据的麻烦,先对当前库的数据库文件做了个备份(/var/lib/mysql/位置).接下来将Percona server 5
-
MySQL优化之InnoDB优化
学习计划很容易就被打断,坚持也不容易.最近公司里开会,要调整业务方向,建议学习NodeJS.NodeJS之前我就会一点,但是没有深入研究.Node的语法和客户端Js基本上是一样的,这半年来很少开发有客户端的东西.本来JS基础还行的我,也对这块的知识陌生了.看起来知识都是用进废退的,不常用了,过不了多久就会遗忘.所以又重新复习了JS的相关知识.学习了Node的服务器与socket知识.MySQL的计划就这样的搁浅起来,星期天的时候吃吃喝喝睡睡,早上又懒的要命,熬着熬着就熬到了下午.废话不多说了,继
-
InnoDB 类型MySql恢复表结构与数据
前提:保存了需要恢复数据库的文件 .frm 和 .ibd 文件 条件:InnoDB 类型的 恢复表结构 1.新建一个数据库--新建一个表,表名和列数和需要恢复数据库相同 2.停止mysql服务器 service mysql stop , 3.在/usr/local/mysql/my.cnf 里面添加innodb_force_recovery = 6 4.将需要恢复的表.frm格式文件 覆盖/usr/local/mysql/data/数据库 下的.frm格式文件 5.启动mysql服务器 serv
-
MySQL中Innodb的事务隔离级别和锁的关系的讲解教程
前言: 我们都知道事务的几种性质,数据库为了维护这些性质,尤其是一致性和隔离性,一般使用加锁这种方式.同时数据库又是个高并发的应用,同一时间会有大量的并发访问,如果加锁过度,会极大的降低并发处理能力.所以对于加锁的处理,可以说就是数据库对于事务处理的精髓所在.这里通过分析MySQL中InnoDB引擎的加锁机制,来抛砖引玉,让读者更好的理解,在事务处理中数据库到底做了什么. 一次封锁or两段锁? 因为有大量的并发访问,为了预防死锁,一般应用中推荐使用一次封锁法,就是在方法的开始阶段,已经预先知道会
-
mysql执行sql文件报错Error: Unknown storage engine‘InnoDB’的解决方法
发现问题 最近在工作中遇到一个问题,在运行了一个innoDB类型的sql文件,报了Error: Unknown storage engine 'InnoDB'错误,网上查了很多方法,但是都没办法真正解决我的问题,后来解决了,在这里总结一下过程,方便有遇到类似情况的朋友们可以有的参照,下面话不多说,来一起看看详细的介绍吧. 解决过程: 我用的是MySql5.5版本的数据库.出现以上错误的时候先用命令->show engines;查看一下引擎详情: 发现并没有innodb这个条目: 然后我们查看日志
-
MySQL存储引擎中MyISAM和InnoDB区别详解
InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型,这两个表类型各有优劣,视具体应用而定.基本的差别为:MyISAM类型不支持事务处理等高级处理,而InnoDB类型支持.MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持,而InnoDB提供事务支持以及外部键等高级数据库功能. 以下是一些细节和具体实现的差别: ◆1.InnoDB不支持FULLTEXT类型的索引. ◆2.InnoDB 中不保存表的具体行数,也就是说,执行select coun
-
MySQL提示The InnoDB feature is disabled需要开启InnoDB的解决方法
本文实例分析了MySQL提示The InnoDB feature is disabled需要开启InnoDB的解决方法.分享给大家供大家参考,具体如下: 一.问题: 建立数据表报错: ERROR 1289 : The 'InnoDB' feature is disabled; you need MySQL built with 'InnoDB' to have it working 开启DOD命令行,登录(关于MySQL使用DOS命令行登录方法可查看前一篇<MySQL基于DOS命令行登录操作实例
-
Mysql更换MyISAM存储引擎为Innodb的操作记录总结
一般情况下,mysql会默认提供多种存储引擎,可以通过下面的查看: 1)查看mysql是否安装了innodb插件. 通过下面的命令结果可知,已经安装了innodb插件. mysql> show plugins; +------------+--------+----------------+---------+---------+ | Name | Status | Type | Library | License | +------------+--------+---------------
-
关于MySQL innodb_autoinc_lock_mode介绍
innodb_autoinc_lock_mode这个参数控制着在向有auto_increment 列的表插入数据时,相关锁的行为: 通过对它的设置可以达到性能与安全(主从的数据一致性)的平衡 [0]我们先对insert做一下分类 首先insert大致上可以分成三类: 1.simple insert 如insert into t(name) values('test') 2.bulk insert 如load data | insert into ... select .... from ....
-
mysql innodb的监控(系统层,数据库层)
mysql innodb的监控(系统层,数据库层) 关于MySQL 的监控,mysql提供了数据采集的命令,比如show status命令或者读取数据库informat_schema的GLOBAL_STATUS对象:也可以用一些现成的监控工具进行查询,目前用的比较多的innotop.mysqlreport.mtop.mytop,还有淘宝perl语言研发的orzdba. 就监控的指标而言,有系统层面的,数据库层面的. 1.系统层面包括系统的load.cpu.内存是否有swap.磁盘IO如何.网络.