详解MySQL分组链接的使用技巧
MYSQL中的分组和链接是在操作数据库和数据交互时最常用的两个在功能,把这两项处理好了,MYSQL的执行效率会非常高速。
一、group by ,分组
顾名思义,把数据按什么来分组,每一组都有什么特点。
1、我们先从最简单的开始:
select count(*) from tb1 group by tb1.sex;
查询所有数据的条数,按性别来分组。这样查询到的结果集只有一列count(*)。
2、然后我们来分析一下,这个分组,我们能在select 和 from 之间放一些什么呢?
当数据分组之后,数据的大部分字段都将失去它存在的意义,大家想想,多条数据的同一列,只显示一个值,那到底显示谁的,这个值有用吗?
通过思考,不难发现,只有by的那些列可以放进去,然后就是sql的函数操作了,比如count(),sum()……(包含在by后面作为分组的依据,包含在聚合函数中作为结果)
例:查询每个学院的学生有多少人:(学院的值是学院的id)
SELECT a.COLLEGE AS 学院,COUNT(*) AS 学生人数 FROM base_alumni a GROUP BY a.COLLEGE;

3、where,having,和group by联合使用
在最初学习group by的时候,我就陷入了一个误区,那就是group by不能和where一起使用,只能用having……
看书不认真啊,其实它们都是可以一起使用的,只不过是where只能在group by 的前面,having只能在group by 的后面。
where,过滤条件的关键字,但是它只能对group by之前的数据进行过滤筛选;
having,也是过滤条件的关键字作用和where是一样的,但是它过滤的是分组后的数据,就是对分组后得到的结果集进行过滤筛选。
出现having其实我觉得就是为了解决一条语句出现两个where的问题,把它们区分开来
例:
查询 30100学院的每个专业的学生有多少人。
SELECT a.MAJOR AS 专业, COUNT(*) AS 学生人数 FROM base_alumni a WHERE a.COLLEGE = 30100 GROUP BY a.MAJOR;
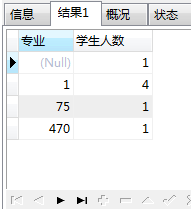
查询每个学院的学生有多少人,并且只要学生人数大于3的。
SELECT a.COLLEGE AS 学院,COUNT(*) AS 学生人数 FROM base_alumni a GROUP BY a.COLLEGE HAVING COUNT(*)>3;

滤清执行顺序:①先对*进行筛选,②对筛选的结果进行分组,③对分组的结果进行筛选
4、Group By All 的使用,哈哈哈哈,经常网上的查阅,我决定淘汰这个语法~
其实就是前面where之后,想要分组的结果显示不符合where的数据,当然,不做运算,运算结果用0或null表示,感觉这语法没啥用,想不出应用场景~
二、深入学习 连接
连接分4种,内连接,全连接,左外连接,右外连接
1、连接出现的地方
①from和where之间,做表和表的连接
②where和having之间,having是对group by的结果集进行筛选,就是把group by的结果集作为一张表,然后可以再和别的表做连接,再进一步筛选
2、连接类型解读
把表看成是一个集合,连接看成是映射,那么它们的结果
内连接:一一映射;全连接:笛卡尔乘积;左外连接:一一映射+左表对应右表的null;右外连接:一一映射+右表对应左表的null。
关键字:
内连接:inner join;全连接:cross join;左外连接:left join;右外连接:right join 。
语法:
表a left join 表b on a.列1 = b.列2
3、连接的使用
之前学习group by的例子中,结果集是存在bug的。
例:查询每个学院的学生有多少人:(学院的值是学院的id),在没有连接的时候,学院人数为0的是显示不出来的,因为当前表中就没有这个学院的信息
那么我们在这里做一下左连接(左外连接):
SELECT c.ID, a.COLLEGE, COUNT(a.COLLEGE) FROM (SELECT ID FROM dic_college) c LEFT JOIN ( SELECT COLLEGE FROM base_alumni ) a ON c.ID = a.COLLEGE GROUP BY c.ID
我这里是一个完整的语句了。我在写出这条语句之前遇到了许多的磕磕碰碰。
解读它:
我们先把学院表和校友信息表(学生表)做左连接
因为我们要的是学院,所以学院作为主表,放left join的前面 c LEFT JOIN a ON ...
然后我们发现有很多字段,于是我们去掉多余的字段,这样既方便我们观察,也提高了sql的执行效率
①把学院表变成只有一个字段(SELECT ID FROM dic_college) c
②把学生表变成只有一个字段( SELECT COLLEGE FROM base_alumni ) a
这时,查询结果是这样的
SELECT * FROM (SELECT ID FROM dic_college) c LEFT JOIN ( SELECT COLLEGE FROM base_alumni ) a ON c.ID = a.COLLEGE

这时候,对这个结果集进行分组:GROUP BY c.ID,并且查询字段要做更改
在上边那个结果集中,c.ID和a.COLLEGE是一一对应的,此时,count(*)的数据是总行数,因为我们的主表是学院表,所以这个数据和count(c.ID)的数据是一样的。
但是a.COLLEGE为空的行的数据中值都是1,这不是我们想要的,所以我们把count(*)改成count(a.COLLEGE),这样数据就出来了。
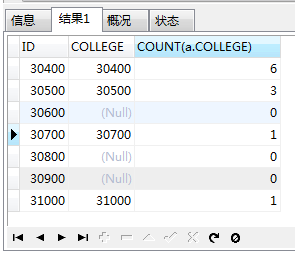
这才是查询所有学院中每个学院的学生人数的正确答案!当然,上边的截图只是数据的前几行,后面还有数据的
4、经过我测试了一下
左连接和右连接……
SELECT * FROM a LEFT JOIN b ON b.ID = a.FK_ID;
SELECT * FROM b RIGHT JOIN a ON b.ID = a.FK_ID;
这两个语句的结果相同,它两并没有发现别的区别。
全连接就是交叉连接,和不使用连接……
SELECT * FROM c,a WHERE c.ID = a.FK_ID;
SELECT * FROM c CROSS JOIN a ON c.ID = a.FK_ID;
这两个语句也没有区别。
以上就是本篇关于MYSQL分组和链接深入详解的全部内容,如果大家还有任何不明白的地方可以在下方留言区讨论。
相关推荐
-

MySQL多表链接查询核心优化
概述 在一般的项目开发中,对数据表的多表查询是必不可少的.而对于存在大量数据量的情况时(例如百万级数据量),我们就需要从数据库的各个方面来进行优化,本文就先从多表查询开始.其他优化操作,后续另外更新,敬请关注. 数据背景 现假设有一个中学学校,学校中的年级有一年级.二年级.三年级,每个年级有两个班级.分别为101.102.201.202.301.302. 现在我们要为这个学校建立一个考试成绩统计系统.为此,我们对数据库的设计画了如下ER图: 根据ER图,我们设计了数据表,结构如下: class
-
实例操作MySQL短链接
MySQL短链接怎么设置 1.查看mysql连接数语句命令: 2.首先作为超级用户登录到MYSQL,注意必须是超级用户,否则后面会提示没有修改权限. 3.按回车键执行后显示目前的超时时间: 4.显示的是默认的超时时间,即8个小时(单位是秒).现在重新设置该参数,例如我们要将超时时间设置成10个小时. 5.按回车键执行显示的结果: 6.可以重新使用show global variables like 'wait_timeout'来验证. 这种方法比较直观,而且设置的参数立即生效. 以上步骤很简单,
-
关于MySql链接url参数的设置
最近整理了一下网上关于MySql 链接url 参数的设置,有不正确的地方希望大家多多指教: mysql JDBC URL格式如下: jdbc:mysql://[host:port],[host:port].../[database][?参数名1][=参数值1][&参数名2][=参数值2]... 常用的几个较为重要的参数: 参数名称 参数说明 缺省值 最低版本要求 user 数据库用户名(用于连接数据库) 所有版本 passWord 用户密码(用于连接数据库) 所有版本 useUnicode 是否
-
MySql使用skip-name-resolve解决外网链接客户端过慢问题
在腾讯云上面搭建的mysql使用开发的电脑上navicat进行访问时总是特别的慢,原来是Mysql会对请求的地址进行域名解析,开发的电脑并没有域名,所以会导致特别的慢,使用以下进行解决 [mysqld] skip-name-resolve skip-grant-tables 官方的解释 How MySQL uses DNS When a new thread connects to mysqld, mysqld will spawn a new thread to handle the requ
-
mysql 之通过配置文件链接数据库
mysql 之通过配置文件链接数据库 配置文件jdbc.properties ##MySQL driver=com.mysql.jdbc.Driver url=jdbc\:mysql\:///ake?useUnicode\=true&characterEncoding\=UTF-8 username=root password=1234 ##Oracle #driver=oracle.jdbc.driver.OracleDriver #url=jdbc:oracle:thin:@127.0.0.
-
详解MySQL分组链接的使用技巧
MYSQL中的分组和链接是在操作数据库和数据交互时最常用的两个在功能,把这两项处理好了,MYSQL的执行效率会非常高速. 一.group by ,分组 顾名思义,把数据按什么来分组,每一组都有什么特点. 1.我们先从最简单的开始: select count(*) from tb1 group by tb1.sex; 查询所有数据的条数,按性别来分组.这样查询到的结果集只有一列count(*). 2.然后我们来分析一下,这个分组,我们能在select 和 from 之间放一些什么呢? 当数据分组之
-
详解MySQL分组排序求Top N
MySQL分组排序求Top N 表结构 按照grp分组,按照num排序,每组取Top 3,输出结果如下: 源代码: SELECT * FROM score AS t3 WHERE ( SELECT COUNT(*) FROM score AS t1 LEFT JOIN score AS t2 ON t1.grp = t2.grp AND t1.num < t2.num WHERE t1.id = t3.id ) < 3 ORDER BY t3.grp ASC, num DESC 在where中
-
详解MySQL 数据分组
创建分组 分组是在SELECT语句中的GROUP BY 子句中建立的. 例: SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id; GROUP BY GROUP BY子句可以包含任意数目的列,这使得能对分组进行嵌套,为数据分组提供更细致的控制. 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组商家进行汇总.换句话说,在建立分组时,指定的所有列都一起计算.(所有不能从个别的列取回数据). GROUP
-
详解mysql中的存储引擎
mysql存储引擎概述 什么是存储引擎? MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力.通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能. 例如,如果你在研究大量的临时数据,你也许需要使用内存存储引擎.内存存储引擎能够在内存中存储所有的表格数据.又或者,你也许需要一个支持事务处理的数据库(以确保事务处理不成功时数据的回退能力). 这些不同的技术以及配套的相关
-
一文详解MySQL中数据表的外连接
目录 为什么要使用外连接 外连接简介 左连接与右连接 外连接练习① 外连接练习② 该章节的内容为多表连接查询的外连接,因为 MySQL 是关系型数据库,数据是拆分重组在多个数据表里面的.所以我们势必要从多个数据表中提取数据,通过 SQL 语句的内连接与外连接就能够实现多表查询了.这部分内容是需要我们重点学习的,学习的过程中会穿插多种的案例来强化对表连接的语法的运用. 为什么要使用外连接 在解释为什么使用 “外连接” 之前,先来看一个记录.(如下:) 针对表中的张三没有所属的部门编号,我们暂且将他
-
详解JDBC数据库链接及相关方法的封装
详解JDBC数据库链接及相关方法的封装 使用的是MySQL数据库,首先导入驱动类,然后根据数据库URL和用户名密码获得数据的链接.由于使用的是MySQL数据库,它的URL一般为,jdbc:mysql://主机地址:端口号/库名. 下面是封装的具体类,用到了泛型和反射,不过还存在些问题,就是对使用的泛型对象有些限制,只能用于泛型类对象属性名与数据库表中列名相同的对象,而且初始化对象的方法必须为set+属性名的方法.本来想通过返回值类型,参数列表来确定该属性初始化方法的,然而可能是目前学到的还是太少
-
详解mysql权限和索引
mysql权限和索引 mysql的最高用户是root, 我们可以在数据库中创建用户,语句为CREATE USER 用户名 IDENTIFIED BY '密码',也可以执行CREATE USER 用户名 语句来创建用户,不过此用户没有密码,可以将用户登录后进行密码设置:删除用户语句为DROP USER 用户:更改用户名的语句为RENAME USER 老用户名 to 新用户名: 修改密码语句为set password=password('密码'): 高级用户修改别的用户密码的语句为SET PASSW
-
详解MySQL 慢查询
查询mysql的操作信息 show status -- 显示全部mysql操作信息 show status like "com_insert%"; -- 获得mysql的插入次数; show status like "com_delete%"; -- 获得mysql的删除次数; show status like "com_select%"; -- 获得mysql的查询次数; show status like "uptime";
-
详解MySQL 聚簇索引与非聚簇索引
1.聚集索引 表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致.对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页. 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种. 从物理文件也可以看出 InnoDB(聚集索引)的数据文件只有数据结构文件.frm和数据文件.idb 其中.idb中存放的是数据和索引信息 是存放在一起的. 2.非聚集索引 表数据存储顺序与索引顺序无关.对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,
-
详解MySQL中的数据类型和schema优化
最近在学习MySQL优化方面的知识.本文就数据类型和schema方面的优化进行介绍. 1. 选择优化的数据类型 MySQL支持的数据类型有很多,而如何选择出正确的数据类型,对于性能是至关重要的.以下几个原则能够帮助确定数据类型: 更小的通常更好 应尽可能使用可以正确存储数据的最小数据类型,够用就好.这样将占用更少的磁盘.内存和缓存,而在处理时也会耗时更少. 简单就好 当两种数据类型都能胜任一个字段的存储工作时,选择简单的那一方,往往是最好的选择.例如整型和字符串,由于整型的操作代价要小于字符,所